基于生成对抗网络的卡通图像生成模型毕业论文
2020-02-19 09:57:02
摘 要
近年来,随着互联网的飞速发展,数字娱乐开始出现在每个人的身边并凭借着其独特的优势成为了人们生活中不可或缺的一部分。而数字娱乐产业中则是以动画产业尤为核心,正因此,动画产业近年来迅速发展,在影视市场方面占据了举足轻重的地位。而如何生成卡通图像则成为了一门非常值得研究的技术。
论文从卡通图像的研究现状开始,介绍了生成对抗网络,深度卷积生成对抗网络,以及人脸截取等概念,最后基于深度卷积对抗网络对于原数据集进行了卡通图像生成模型,并得到了较为满意的结果。
实验结果表明了,通过深度卷积对抗网络能够成功的对图像进行处理并得到令人满意的卡通图像。但是需要注意的是要根据情况对实验代码进行处理,以免出现失败的局面。
关键词:卡通图像生成;卷积;GAN;DCGAN
Abstract
In recent years, with the rapid development of the Internet, digital entertainment began to appear around everyone and become an indispensable part of people's life with its unique advantages. In the digital entertainment industry, animation industry is especially the core industry. Therefore, animation industry has been developing rapidly in recent years and occupies a decisive position in the film and television market. And how to generate cartoon image has become a very worthy research technology.
Starting from the research status of cartoon images, this paper introduces the concepts of generation adr, deep convolution generation adr, and face interception, etc. At last, based on the deep convolution adr, a cartoon image generation model is developed for the original data set, and satisfactory results are obtained.
The experimental results show that the images can be processed successfully by deep convolution counter network and satisfactory cartoon images can be obtained. However, it is important to treat the experimental code according to the situation, so as to avoid failure.
Keywords: cartoon image generation; convolution; GAN;DCGAN
目录
第一章 绪论 6
1.1卡通图像生成技术的现状 6
1.2本课题研究内容 6
第二章 生成对抗网络的原理及结构 7
2.1生成对抗网络的介绍及发展 7
2.2GAN的结构及原理 7
2.3GAN的优势与缺陷 9
2.3.1GAN的优势 9
2.3.2GAN目前存在的主要问题 10
2.难以训练:崩溃问题(collapse problem) 10
3.在没有预先建模的情况下,模型太自由,无法控制。 10
2.4.1 Generative networks的架构 11
2.4.2“反卷积”—上采样卷积 12
2.5本章小结 13
第三章 卡通图像生成 14
3.1卡通图像生成框架 14
3.2人脸截取 14
3.3 对DCGAN的改进 15
3.3.1对于生成网络 16
3.3.2对于判别器 16
3.4本章小结 17
第四章 实验结果及分析 18
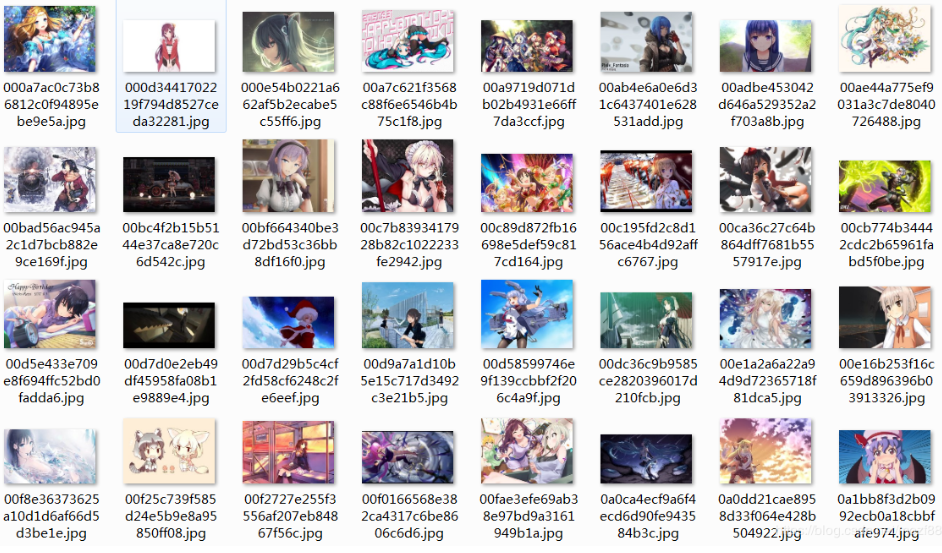
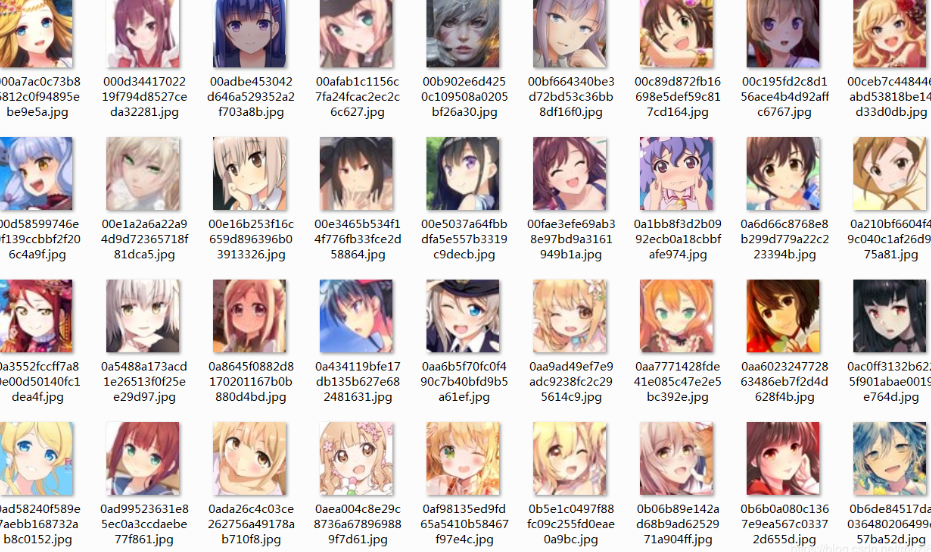
4.1原始数据集 18
4.2人脸截取 18
4.3对图像的代码运行 19
第五章 总结与展望 21
参考文献 22
附录 24
致谢 34
第一章 绪论
1.1卡通图像生成技术的现状
1.1卡通图像生成技术的现状
近年来,随着人们生活水平的稳步提高,人们已经做出了从满足自己的物质条件到丰富自己的精神生活的转变,也正因此,文化娱乐产业的增长率稳步上升。随之相应的则是移动网络的发展,尤其是在互联网产业方面,基本上做到了普及到家家户户。而数字娱乐产业也在这种情形下飞快发展,成为了人们生活中不可或缺的一部分。
卡通产业作为数字娱乐产业中的中流砥柱,其在影视动画、娱乐游戏、视频会议、手机彩信、个性化贺卡、手机通讯等方面都有着很广泛的应用空间。而这一情况这也使得卡通图像的制作得到了广泛的发展。虽然随着计算机技术的进步,人们已经可以通过计算机来实现自己制作卡通,但是,由于人们在卡通方面的算法目前来说较为的复杂且效果较差,所以对于普通大众来说,很难获得效果令人满意的卡通图像。为了改善这个问题,人们发现,如果在卡通生成时加入控制和干预,即采用交互的方式来完成,这将使得获得的结果更加符合人们的心意。
具体的来说是通过生成对抗网络的博弈思想来不断的进行训练从而使得得到的结果更加令人满意、但是由于处理的是图片,而深度学习中对图像处理应用最好的模型是卷积神经网络,所以,结合了两者的深度卷积神经对抗网络就成为了我们实现目的的最好的手段。
1.2本课题研究内容
本文的主要研究内容如下
提出了一种基于GAN 的卡通图像生成方法,即利用经过初步处理的图像通过GAN来实现卡通图像的最终生成。
具体来说,先对我们得到的图像进行人脸截取,再对得到的人脸图像进行GAN处理,通过多次的迭代来的到相对而言更加清晰的卡通图像。并根据在实验的具体过程中遇到的问题进行一定的修改。
第二章 生成对抗网络的原理及结构
2.1生成对抗网络的介绍及发展
机器学习方法分为生成方法和判别方法两种,所学到的模型分别称为生成式模型和判别式模型。由于所生成模型的参数要比训练数据的量小得多,因此该模型能够发现并有效内化数据的本质,从而实现这些数据的生成。生成模型在无监督的深入学习中起着不可替代的作用。它可以用来捕获观察或可见数据的高阶相关性,而不需要目标类标签信息。深度生成模型可以通过从网络中采样有效地生成样本,如限制性玻尔兹曼机(rbm)、Deep BeliefNetwork(dbn)、深玻尔兹曼机(dbm)和广义噪声去活化自动编码器。
生成对抗网络是一种受博弈论启发的两人零和一的博弈。最初由Goodfellow等人(NIPS 2014)提出,其中包括生成模型G和判别模型D。生成的模型捕获了样本数据的分布,判别模型是分类器,用来确定输入的数据是真实数据还是生成的样本。该模型的优化过程本质上是一个“极大极小二人博弈”问题,在训练过程中,一边固定的同时一边不断更新另一个模型的参数。当双方的误差值达到最大的时候停止迭代,此时,G可以估计样本数据的分布。
2.2GAN的结构及原理
GAN最基本的原理其实就是Generator和Discriminator相互对抗,共同进步的过程,有点类似于回合制游戏。一般的生成模型在实现新输出时一般是基于现有数据的综合,因此非常模糊,而gan则不是。在每一轮训练中,d(鉴别器)将生成器的输出标记为0,原始数据集标记为1。而G(Generator)都尽量使得上一轮的D输出为1,因此在训练其中一个网络时另一个要保持参数不变。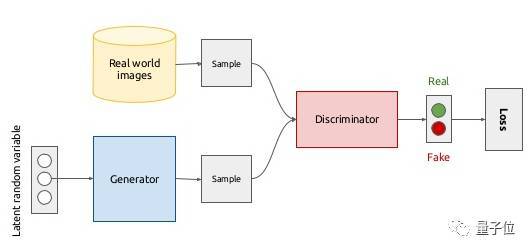
图2.1 GAN的整体结构生成器和判别器
在训练的每一步,判别器都 需要对训练中心的图像进行判别,因此判别者的判断会随著训练而变得越来越强。也正因此,当生成器足够好产生假图像时,它可以欺骗判别器,从而得到我们理想中的结果。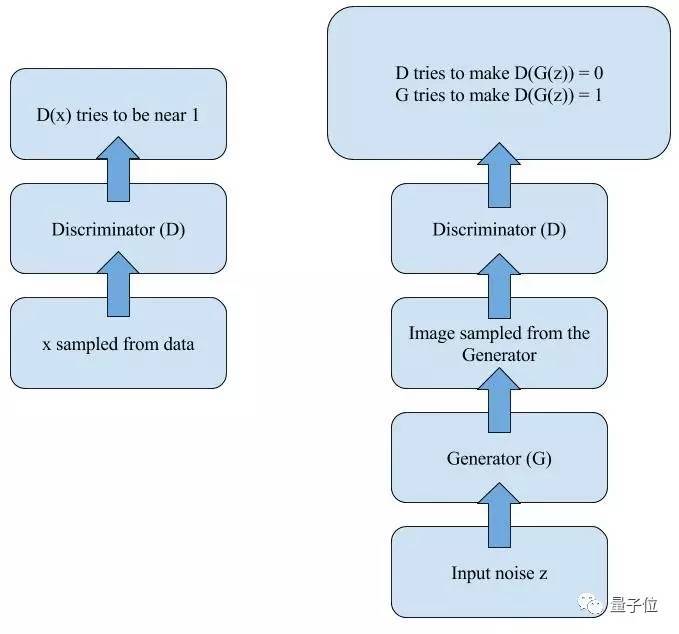
图2.2 GAN的实现示意图
对于这个神经网络,假设我们训练足够长的时间,生成器将学习样本的实际“分布”,并逐渐生成真实图像,直到鉴别器无法区分真假图像。这样我们也就得到了希望的结果
训练过程
判别器D的训练:固定生成器G,只需要考虑优化D, 因为要让D能够区分真实的图片和虚假的图片,所以要让D(x)的值越接近1越好,D(G(z) )的值越凑近0 越好,即1-D(G(z) )越大越好,只要D越强,那么V(D,G)就越大,所以需要max_D,训练D让V最大。
生成器G的训练:固定判别器D,只要考虑优化G, G的作用是要产生能以假乱真的图片,G越强,则D(G(z) ) 越大,这个时候1-D(G(z) )会变小 ,这个时候V(D,G)会变小。所以需要min_G,训练G让V最小。
2.3GAN的优势与缺陷
2.3.1GAN的优势
与其他生成式模型相比较,生成式对抗网络有以下四个优势
1.能够得到比其他模型更加清晰的图像
2.生成的网络构架可以对抗任何的其他的放电机网络。对于其他的网络构架来说,它们普遍要求发电机网络有某些特定的功能。GAN可以在和其数据相近的细流点上生成点,而不像其他的架构一样要求生成器网络遍布非零质量。
3.GAN可以不用特地设计一个能够遵循每一种因式分解的模型。它能够对于任何的一种生成器和判别器都产生作用。
4.可以回避近似计算困难的难题。由于GAN 的特殊性,导致它不需要应用到马尔科夫链来进行重复采样,也就避免了因为重复采样而产生的近似计算的问题。
2.3.2GAN目前存在的主要问题
1。解决不收敛问题。
目前所面临的根本问题是,所有理论都认为gan在nash均衡上应有优异的表现,但梯度下降只会保证在凸函数的情况下可以完成nash均衡。当博弈双方都被神经网络所体现时,就有可能让他们永远调整策略而不真正达到平衡。
2.难以训练:崩溃问题(collapse problem)
由于干模型的本质是最大最小问题,从而导致了GAN没有损失函数,使得我们无法确定在训练过程中的具体情况。也就是说,当生成模型崩溃时,可能会出现判别模型会指向其他方向的问题从而导致训练无法继续进行的情况。
3.在没有预先建模的情况下,模型太自由,无法控制。
由于GAN是不需要进行假设模型分布的,使得其能够在理论上达到完全近似。然而,对于以些较大的图像,基于简单GaN的方法不是很容易控制的。也正是因此在进行更新的过程中,一般需要对d进行k次更新才对g进行一次更新。2.4深度卷积生成式对抗网(DCGAN)
Goodfellow的首篇GAN论文发表一年后,大家发现GAN模型不稳定,并且需要大量的技巧。2016年,Radford等人发表了一篇名为《无监督代表性学习与深度卷积生成式对抗性网络》的论文,文中提出了GAN架构的升级版,命名为深度卷积对抗生成网络(Deep Convolutional Generative Adversarial Networks,DCGAN)模型。
dcgan的原理与gan的原理基本相同。不同的地方在于DCGAN使用了两个卷积神经网络(cnn)代替了上面的g和d。然而,DCGAN并不是简单的进行了替代,而是对卷积神经网络的结构方面进行了调整,从而还同时提高了样本的质量以及收敛的速度。这些变化包括:
1.取消所有的集合层。g网络使用转置卷积层进行向上采样,d网络使用增加到步幅上的卷积而不是制作。
2.在D和G中均使用batch normalization
3.去掉FC层,使网络变为全卷积网络
4.G网络中使用ReLU作为激活函数,最后一层使用tanh
5.D网络中使用LeakyReLU作为激活函数
2.4.1 Generative networks的架构
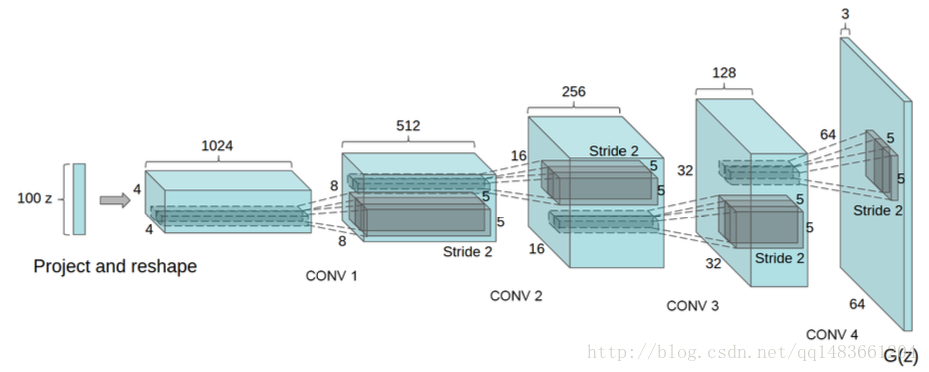
图2.3 DCGAN的生成网络模型的架构
对于一般的数据集,这个结构体系都是可以适用的,但是对于某些特殊的数据集,例如,较大或较小的数据集,则会出现问题导致结果不明。因此,需要对卷积体系结构进行相应的修改才能得到明确详实的结果。
对于判别模型,他在本质上是一个由五层卷积组成的一个卷积网络。对于生成的模型,可以看到,从最开始的采样维度开始,经过一步步判别,直至最后的64*64*3层的图像,经过“去概念”层,本质是传输概念或上分辨率。
2.4.2“反卷积”—上采样卷积
反褶积根据维基百科的定义,它实际上是卷积上的反向操作,即卷积输出信号可以通过卷积恢复。然而,在深度学习中,反褶积的实质是传输卷积。
下图为卷积的可视化 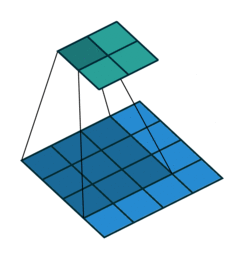
图2.4 卷积可视图
4x4的输入信号,经过3x3 的filters,产生了2x2的feature map。
可视化:
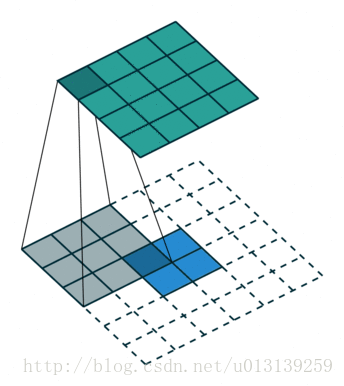
图2.5 反卷积可视图
2x2的输入信号通过3x3滤波器生成4x4特征图。大尺寸是从小尺寸得到的,因此运输合作也被称为上层样品卷积。因为“反褶积”存在于卷积的反向传播中。反向传播滤波器矩阵是正向传播(卷积)的转置,因此这是其名称的由来。反褶积理论是在正向传播的作用下产生的。但是,传输连接只能恢复信号的大小。因此,它不能称为反褶积,所以它不是一个真正的逆运算。
2.5本章小结
本章主要介绍了本文拟采用的GAN技术以及它的优劣点并且依据实际要求选择了更加适合本论文的深度卷积GAN,由于深度卷积GAN所选取的卷积和反卷积使得结果能够更加的精确,所以最终确定了我们实验所用的方法。
第三章 卡通图像生成
3.1卡通图像生成框架
本文通过DCGAN生成卡通,因此需要有卡通人脸来实现接下来的生成步骤,但是由于所能找到的大部分卡通图像都并非是直接的卡通人脸,所以我们需要先进行卡通人脸的截取。
本文框架主要分以下2个主要部分:
1.人脸截取。根据原始数据集中的卡通图像进行人脸截取以得到所需要的人脸形象。
2.对所获取到的卡通人脸形象进行DCGAN处理,以得到预期中的结果。
3.2人脸截取
在网上爬取了图像之后,,还需要将人脸部分截取出来。
在进行人脸截取的选择上,使用OpenCV进行漫画的人脸探测器。
为确保代码的准确运行,先对代码进行测试。效果图如下;
图3.1 原始图像
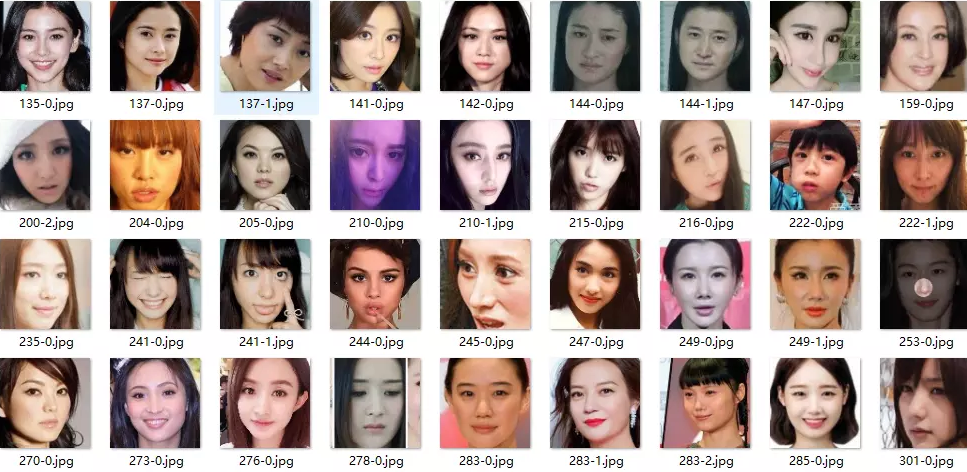
图3.2 处理之后的图像
3.3 对DCGAN的改进
由于对于不同的数据集需要对DCGAN进行一定程度的原始模型进行一定程度的修改,这一点前文已经提过。所以,对于本文中所将要面对的情况对于DCGAN进行了一些处理。
3.3.1对于生成网络
首先是生成网络:
第一层:全连接层,输出神经元个数64×8×图像长×图像宽,这个地方的长和宽是要原始图片反推过来的,然后reshape成[batch_size,图像长,图像宽,64×8],然后接着relu激活函数
第二层:反卷积层(deconv),卷积核大小[5,5],步长2,权重使用高斯分布,同时权重的初始化标准差stddev=0.02,输出通道数64×4,后面接BN层,然后使用relu作为激活函数
第三层:也是反卷积层,参数和上面的一样,输出通道数是64×2,也是BN加relu
第四层:也是反卷积层,参数和上面的一样,输出通道数是64×1,也是BN加relu
第五层:反卷积层,输出通道数为3,后面接relu(没有BN层)
3.3.2对于判别器
判别器:
第一层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,输出的通道数为64,然后接LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2,没有BN层
第二层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,输出的通道数为64×2,然后接BN层,然后是LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2
第三层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,输出的通道数为64×4,然后接BN层,BN层后面是LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: