基于卷积神经网络的行人目标检测毕业论文
2020-02-19 07:56:30
摘 要
本文首先从计算机视觉技术的发展和应用切入课题,分析了行人目标检测在计算机视觉领域中的重要性,对行人目标检测技术的发展过程做了系统的梳理。通过分析基于深度学习的行人目标检测方法相对于传统行人检测目标检测方法的优势,理解卷积神经网络对于当下计算机视觉技术的重要性。
论文通过研究几种经典深度卷积神经网络模型,介绍了每个模型提出的改进,并就该改进能够给卷积神经网络目标检测系统提供什么样的增益做简要说明。通过研究卷积神经网络的发展历程,得出了以下结论:
- 基于卷积神经网络的目标检测方法是当下最好的行人目标检测方法。
- 已经有大量的应用场景使用了基于卷积神经网络的行人检测方法。
- 未来卷积神经网络检测的方向是朝着模块化、深层化和one stage发展的。
关键词:卷积神经网络;行人检测;目标检测;深度学习
Abstract
Firstly, from the development and application of computer vision technology, this paper analyses the importance of pedestrian target detection in the field of computer vision, and systematically combs the development process of pedestrian target detection technology. By analyzing the advantages of pedestrian detection method based on deep learning compared with traditional pedestrian detection method, we understand the importance of convolutional neural network for current computer vision technology.
By studying several classical deep convolution neural network models, this paper introduces the improvement of each model, and gives a brief description of what kind of gain this improvement can provide for convolution neural network target detection system. By studying the development of convolutional neural networks, the following conclusions are drawn:
(1) Target detection method based on convolution neural network is the best pedestrian target detection method at present.
(2) A large number of application scenarios have used pedestrian detection methods based on convolution neural network.
(3) In the future, the direction of convolutional neural network detection will be modularization, deep-seated and one stage.
Key Words:Convolutional Neural Network; Pedestrian Detection; Target Detection; Deep Learning
目 录
第一章 绪论 1
1.1 引言 1
1.2 行人检测研究的背景及意义 1
1.3 卷积神经网络的历史背景及研究意义 2
1.4 行人检测数据集 3
1.4.1 MIT行人数据库 3
1.4.2 PASCAL VOC数据集 3
1.4.3 ImageNet数据集 4
1.4.4 COCO数据集 4
1.5 深度学习目标检测的性能指标 4
1.5.1 定位精度 4
1.5.2 分类精度 4
1.5.3 检测速度 5
1.6 本文的内容结构 5
第二章 行人检测技术发展概述 6
2.1 确定行人候选区域的方法 6
2.1.1 基于运动信息的行人候选区域确定 6
2.1.2 静止图像下的行人候选区域确定 7
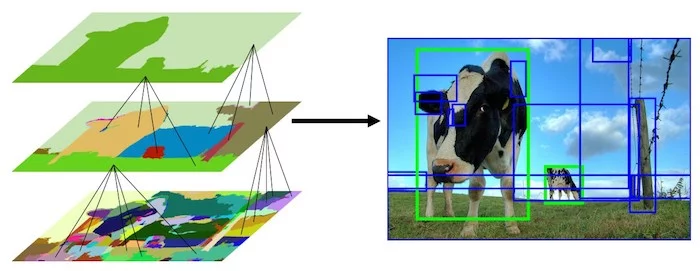
2.2 提取行人特征技术发展 9
2.2.1底层特征 9
2.2.2学习的特征 11
2.3 分类方法的发展 12
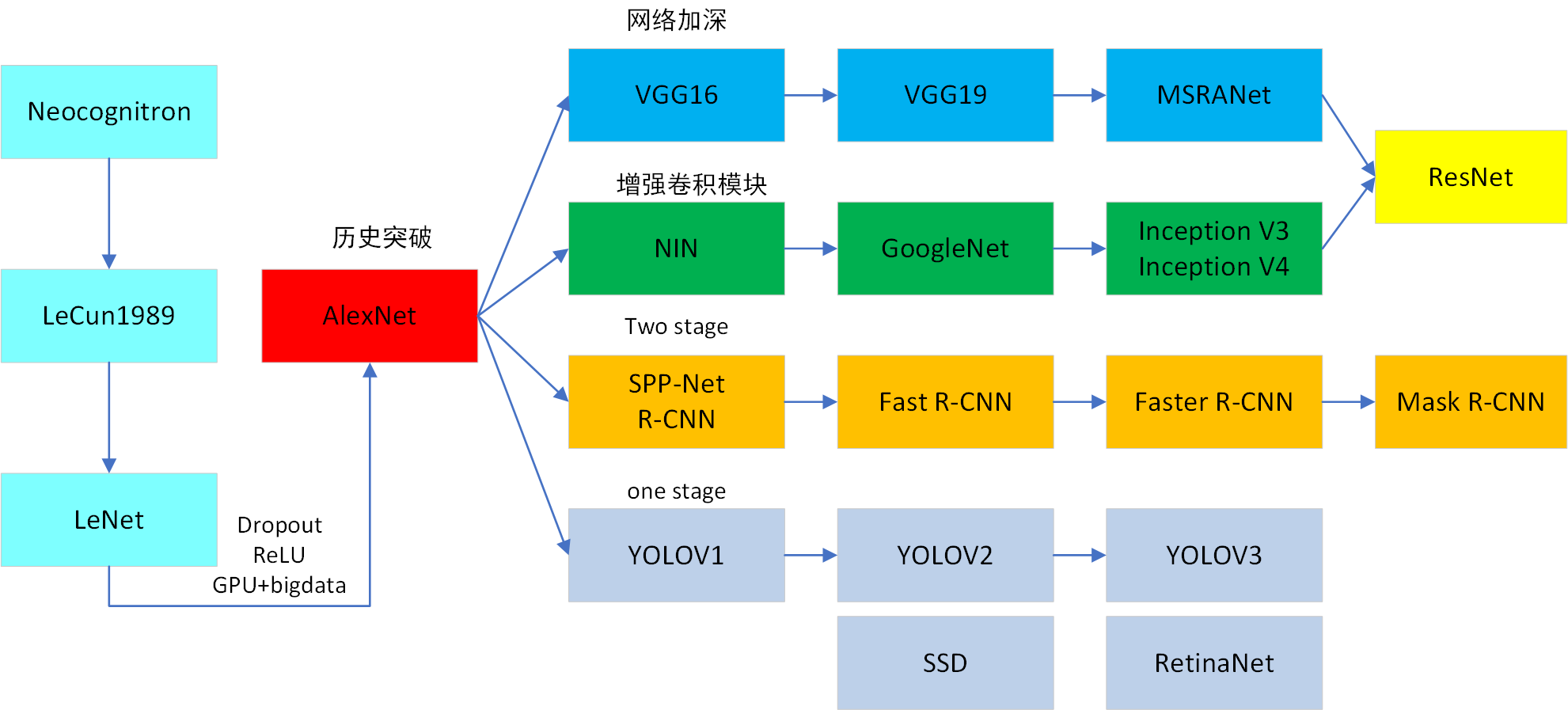
第三章 卷积神经网络 13
3.1 经典卷积神经网络模型 13
3.1.1 LetNet-5模型 14
3.1.2 AlexNet模型 14
3.1.3 VGG 模型 15
3.1.4 GoogLeNet 模型 16
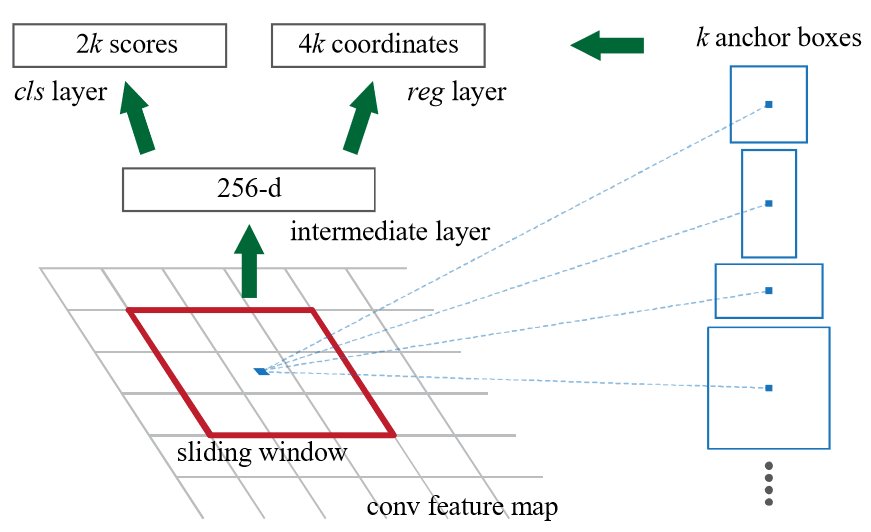
3.2 候选区域的卷积神经网络模型 17
3.2.1 R-CNN模型 17
3.2.2 Fast R-CNN模型 17
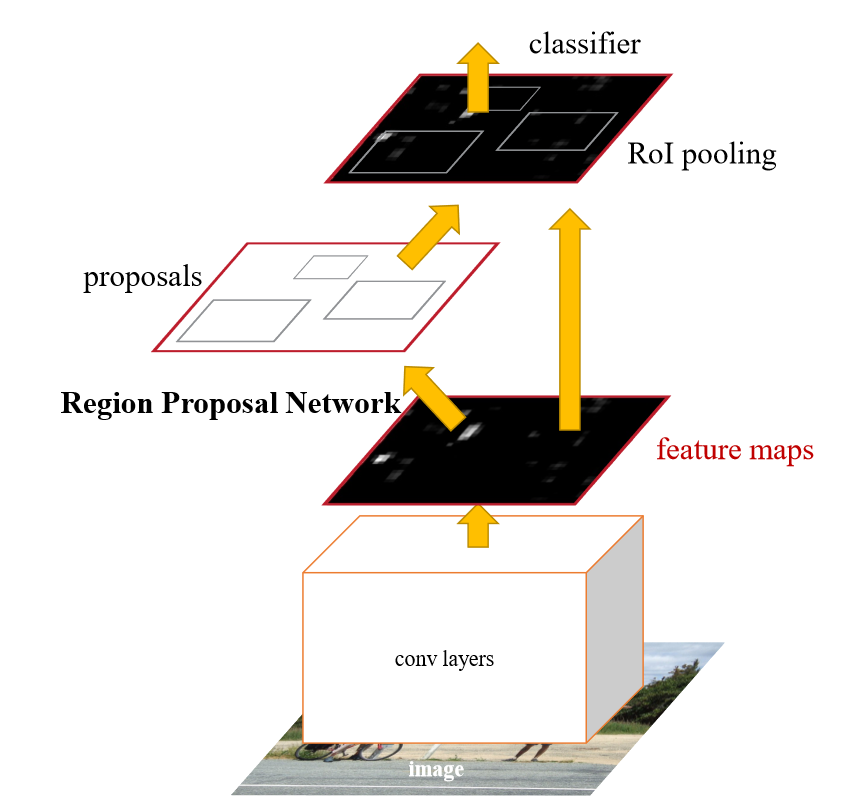
3.2.3 Faster R-CNN模型 18
3.2.4 Mask R-CNN模型 18
3.3 回归的卷积神经网络模型 19
3.3.1 YOLOv1模型 19
3.3.2 YOLOv2模型 22
3.3.3 YOLOv3模型 23
3.3.4 SSD模型 23
3.4 卷积神经网络行人检测方法的对比 25
第四章 YOLOv3的实现 27
4.1 YOLOv3网络模型 27
4.2 预测边界框 27
4.3 损失函数 28
4.4 结果分析 29
第五章 总结与展望 30
参考文献 31
致 谢 33
第一章 绪论
1.1 引言
 行人检测是计算机视觉技术的经典应用,计算机视觉是采用摄像机获取图片或视频信息并使用计算机对其进行处理的一门新兴学科。让机器具有主动感知认知的能力是人类多年的梦想。计算机视觉不仅要达到感知物体的形状 、位置、姿态等几何信息,还要对它们进行描述、存储、识别和理解。计算机视觉是多学科的交叉与结合,如图1.1所示。
行人检测是计算机视觉技术的经典应用,计算机视觉是采用摄像机获取图片或视频信息并使用计算机对其进行处理的一门新兴学科。让机器具有主动感知认知的能力是人类多年的梦想。计算机视觉不仅要达到感知物体的形状 、位置、姿态等几何信息,还要对它们进行描述、存储、识别和理解。计算机视觉是多学科的交叉与结合,如图1.1所示。
图1.1 计算机视觉涉及的相关学科
行人目标检测是判断图像或视频中有没有行人,并确定行人确切位置的一类目标检测,目标检测与识别技术是计算机视觉中的经典难题。很多研究者研究的目标包括车辆、人脸、行人等,其中,车辆和人脸属于刚性物体,行人既有刚性物体特性又有柔性物体特性。所以人脸和车辆等刚性目标的研究起步较早,相应的目标检测技术也发展的较为成熟,因此与其相关的产品已经得到大量应用,例如车牌识别和人脸考勤等。由于目标检测涉及多学科知识,例如模式识别、图像处理、计算机视觉和机器学习等,同时,行人检测还受到行人衣着、环境光照、人体姿势、尺度变化、视角不同和复杂的背景等的影响,而行人与车辆和人脸相比,姿态和表观变化更加多样化,导致检测难度也更大,行人检测极具挑战性。但由于行人检测具有极为广泛的应用场景,对行人检测技术的研究能带来极大的应用价值,能够大大提高人类的生活品质,所以,在对行人检测技术的研究路上并不乏研究者,越来越多的研究人员投身其中,取得了非常不错的成就。
1.2 行人检测研究的背景及意义
首先,关于人体运动分析的研究最早可追溯到20世纪80年代[7],但该时期是假设目标已经被检测出来了,重点研究在运动目标的识别、分类以及长序列运动模式的分析。在2000年前后,行人检测也只是被视为视频监控系统中的预处理步骤,并未得到业界研究者的重视。
直到2015年左右,随着车辆辅助驾驶、自动驾驶、智能视频监控、人体行为分析等领域的快速发展,以及行人检测在一些新的应用领域,如服务机器人,基于航拍图像的行人及受害人检测、街景图的行人消除等领域应用,早期简单的预处理或者手动标注人 体位置的方法不能满足工业需求,迫切需要程序自动地给出人体在图像或视频中的位置,行人检测技术越来越受到研究者的重视,尤其是卷积神经网络运用于行人检测之后大大提高了检测性能。
车辆辅助驾驶或者自动驾驶是行人检测的一个重要领域,如果这一技术发展成熟,对减少路上车辆、降低事故和死亡率、减少压力、减少停车占地、并且对改善环境也大有作用。国外的研究起步较早,早在2000年到2005年之间,Gavrila领导的团队就开发了实时的行人检测与保护系统,并成功运用于智能车辆辅助驾驶系统中。近年来,以谷歌为首的自动驾驶技术的研究正在如火如荼的进行中,很多实验证明自动驾驶技术已经取得非常大的进步,但也还存在许多问题诚待解决。
智能视频监控也是行人目标检测技术的一大应用场景,安检、银行、电力、交通以及军事设施等领域对现场记录报警系统和安全防范的需求愿望随着逐渐增强的国力和社会的发展逐渐加强,要求越来越高,视频监控被普遍应用在生产生活方方面面。虽然现在的车站、商场、街道上已经广泛地设置了监控,但是实际的监控任务还是由人工完成,现在的监控大多只是简单地录制视频图像,想要从视频中得到有用信息还是的由大量的人力去判断。视频监控的“智能化”非常重要,智能化的视频监控系统能实时分析、跟踪、判别监控对象,并根据监控提取到的信息判断是否存在异常,一旦出现异常,能够采取相应决策去处理,例如进行提醒或者上报。我国最新监控技术可以实现无人看守监控,对拍到的图像自动分析,如果遇到险情瞬间能与110、手机连接,以各种方式报警,同时对警情拍照和录像,以便调看和处理。
1.3 卷积神经网络的历史背景及研究意义
卷积神经网络(Convolutional Neural Network,CNN)是一类具有深度结构且包含卷积计算的神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
1979和1980年日本学者福岛邦彦(Kunihiko Fukushima)提出的neocognitron模型被认为是启发了卷积神经网络的开创性研究。二十世纪80年代,人工智能领域取得了突破性进展。1987年Alexander Waibel等提出基于BP框架的时间延迟网络(Time Delay Neural Network, TDNN),这是第一个卷积神经网络,同等条件下,TDNN的表现超过了当时语音识别的主流算法—隐马尔可夫模型(Hidden Markov Model, HMM)。
1988年,Wei Zhang提出平移不变人工神经网络(SIANN)应用于检测医学影像,这是第一个二维的卷积神经网络。1989年,Yann LeCun构建的LeNet也是应用于图像分类的卷积神经网络,他在论述首次使用了“卷积”一词,“卷积神经网络”也因此得名。。LeNet包含两个卷积层,2个全连接层,共计6万个学习参数,规模远超TDNN和SIANN,且在结构上与现代的卷积神经网络十分接近。LeCun对权重进行随机初始化后使用了随机梯度下降(Stochastic Gradient Descent, SGD)进行学习,这一策略被其后的深度学习研究广泛采用。
1993年贝尔实验室(ATamp;T Bell Laboratories)完成LeNet的代码开发并被大量部署于NCR(National Cash Register Coporation)的支票读取系统。但总体而言,由于数值计算能力有限和学习样本不足,这一时期为各类图像处理问题设计的卷积神经网络停留在了研究阶段,没有得到广泛应用。
1998年Yann LeCun及其合作者在LeNet的基础上构建了更加完备的卷积神经网络LeNet-5并在手写数字的识别问题中取得成功。LeNet-5的成功使卷积神经网络得到广泛关注, 2003微软年基于卷积神经网络开发了OCR系统。基于卷积神经网络的人像识别、手势识别的研究也得到展开。
2006年后,随着深度学习理论的完善,尤其是逐层学习和参数微调(fine-tuning)技术的出现,卷积神经网络在结构上不断加深,引入各类学习和优化理论,被大量应用于计算机视觉、自然语言处理等领域。
自2012年的AlexNet开始,各类卷积神经网络多次成为ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的优胜算法,包括2013年的ZFNet、2014年的VGGNet、GoogLeNet和2015年的ResNet。近年来,深度卷积神经网络的目标检测算法表现越来越出色,检测精度和检测速度跨越式增长。逐渐发展成为两大分支,一是基于区域推荐(Region Proposal)的以R-CNN为代表的深度学习目标检测算法(R-CNN、SPP-NET、Fast R-CNN、Faster R-CNN和Mask R-CNN等),这种方法是分两步实现检测定位的;二是基于回归方法的以YOLO为代表的深度学习目标检测算法(YOLO、SSD等),这种方法是一步完成检测定位的。
卷积神经网络在不仅在本文要研究的行人目标检测领域表现出色,它已经被应用于各个领域。例如卷积神经网络在行为认知,姿态估计等领域同样表现出良好效果,还被用于神经风格转换来进行艺术创作,也可也用来做照片的后处理。同时,卷积神经网络在物理学、遥感科学、大气科学等领域都有举足轻重的作用。
1.4 行人检测数据集
1.4.1 MIT行人数据库
MIT行人数据库共有924张规格为的ppm格式的行人图片,是较早公开的行人数据库,该数据库只含正面和背面两个视角,无负样本,未区分训练集和测试集。Dalal等在该数据库上采用“HOG SVM”检测方法的使得检测准确率达到100%。
1.4.2 PASCAL VOC数据集
PASCAL VOC数据集是目标检测,分类,分割等邻域一个有名的数据集,该数据集一共包含约10000张带有边界框的图片用于训练和验证,包含20个类别,从2005年到2012年,共举办了8个不同的挑战赛。为计算机视觉的发展起到了极大的促进作用。
1.4.3 ImageNet数据集
ImageNet数据集有超过1500万的标注高分辨率图像,大约2.2万个类别。这些图像是从网上收集,使用Amazon’s Mechanical Turk的众包工具通过人工标注。从2010年起,作为Pascal视觉对象挑战赛的一部分,每年都会举办ImageNet大规模视觉识别挑战赛(ILSVRC)。ILSVRC使用ImageNet的一个子集,1000个类别每个类别大约1000张图像。总计,大约120万训练图像,50000张验证图像和15万测试图像。
1.4.4 COCO数据集
COCO数据集用常于图像标题生成,目标检测,关键点检测和物体分割多种竞赛。对于目标检测任务,包含80个类别,每年大赛的训练和验证数据集包含超过12万个图片,超过4万个测试图片。在COCO 2017 Detection Challenge中,旷视科技团队凭借提出的Light-Head R-CNN模型夺得冠军。
- 深度学习目标检测的性能指标
1.5.1 定位精度
为了评估定位精度,需要计算IOU(intersection over Union,介于0到1之间),表示的是预测框与真实框(ground-truth box)之间的重叠程度。IOU越高,表示预测框的位置越接近真实框。在评估预测框时,通常会设置给IOU设置一个阈值(如0.5),只有当预测框与真实框的IOU值大于这个阈值时,该预测框才被认定为真阳性(True Positive,TP),反之就是假阳性(False Positive,FP)。
1.5.2 分类精度
对于二分类,AP(Average Precision)时一个重要的指标,只是信息检索中的一个概念,基于precision-recall曲线计算出来,是评估检测效果的重要指标,对于目标检测,要单独计算各个类别的AP值。取各个类别的AP的平均值,就得到一个综合指标mAP(Mean Average Precision),mAP指标可以避免某些类别比较极端化而弱化其它类别的性能这个问题。
1.5.3 检测速度
每秒的帧率(Frame Per Second,FPS)是评估速度的常用指标,即每秒内可以处理的图片数量。检测速度对于一些需要实时检测的场景及其重要。另外也可以使用处理一张图片所需的时间来评估检测速度,时间越短,速度越快。
1.6 本文的内容结构
第1章,介绍了行人检测和卷积神经网络的发展状况以及研究意义,列出一些常用目标检测数据集,介绍深度学习目标检测的性能指标,最后说明本文结构。
第2章,将实现行人检测的过程分为几个模块,并分别对各个模块的发展做简要概述。
第3章,介绍了几种经典的卷积神经网络架构和近年来基于这几种经典网络改进的卷积神经网络。并对这些卷积神经网络行人目标检测技术的对比分析。
第4章,基于Tensorflow框架实现YOLOv3目标检测。
第5章,总结与展望。
第二章 行人检测技术发展概述
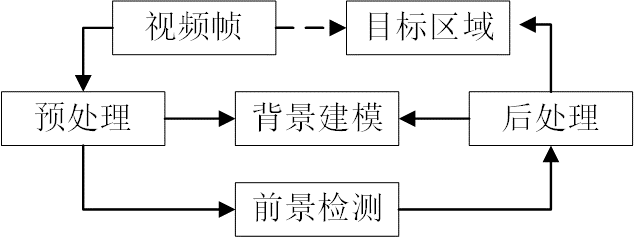
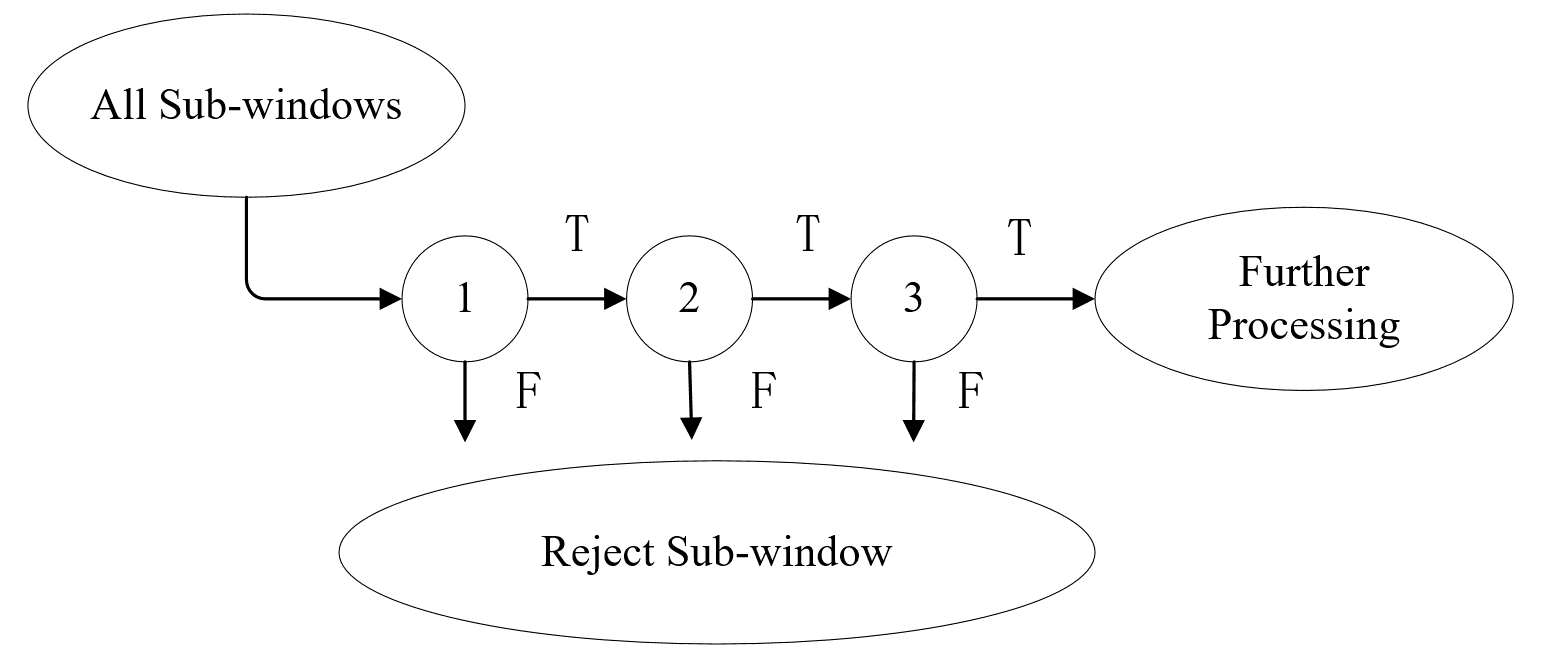
一般 行人检测技术可分为以下几个模块,分别是行人候选区域、行人特征提取、分类与定位、验证,如图2.1所示。各个模块在不同的应用邻域都有着其相应的方法和技术,目前国内外已经有很多关于行人检测的综述,但大部分都是局限在某个特定领域内,不同的应用领域的假设条件和处理的方法差别很大。例如,在智能视频监控中,一般摄像头是静止不动的,因此可以通过减背景技术获取感兴趣的区域(即运动目标区域),然后利用人体的分散度、高宽比、轮廓特性等先验特性对运动目标进行分类。而在摄像机是在运动的系统中,例如车辆辅助驾驶中摄像机随着车辆一起运动,背景在不断变化,因此不能利用背景信息,在这种情况下一般建模为单张图片的检测,从大量的行人样本和非行人样本中学习行人特征,结合模式识别和机器学习的发展,构建分类器。本章对各模块的研究发展现状做简要回顾。
行人检测技术可分为以下几个模块,分别是行人候选区域、行人特征提取、分类与定位、验证,如图2.1所示。各个模块在不同的应用邻域都有着其相应的方法和技术,目前国内外已经有很多关于行人检测的综述,但大部分都是局限在某个特定领域内,不同的应用领域的假设条件和处理的方法差别很大。例如,在智能视频监控中,一般摄像头是静止不动的,因此可以通过减背景技术获取感兴趣的区域(即运动目标区域),然后利用人体的分散度、高宽比、轮廓特性等先验特性对运动目标进行分类。而在摄像机是在运动的系统中,例如车辆辅助驾驶中摄像机随着车辆一起运动,背景在不断变化,因此不能利用背景信息,在这种情况下一般建模为单张图片的检测,从大量的行人样本和非行人样本中学习行人特征,结合模式识别和机器学习的发展,构建分类器。本章对各模块的研究发展现状做简要回顾。
图2.1 行人检测技术的相关模块
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: