基于网络爬虫的搜索引擎设计与实现毕业论文
2020-02-16 18:06:18
摘 要
自20世纪90年代Web技术兴起以来,各种各样的网站层出不穷,逐渐丰富和改变了人们的生活。
新浪微博诞生于2009年,是国内一个基于用户关系的媒体平台。用户可以通过PC、手机或平板电脑等终端以文本、图片、视频等多种形式分享内容,实现实时的信息传播和交互。由于其功能强大且使用简易,现已成为国内最知名的社交网站之一。随着多年的发展,新浪微博有着数以亿计的注册用户和广泛的微博大V,因此如何有效地获取到用户的微博信息成了一个炙手可热的话题。
本文探究了以Python语言为基础的多种爬虫技术,实现了一个搜索微博用户信息的系统,目的是获取微博用户的相关信息,并具有保存到本地和数据可视化等功能。主要的开发工具是PyCharm和Chrome,运行环境是windows操作系统,Python版本为Python 3.6。
关键词:Web;新浪微博;网络爬虫;Python
Abstract
Since the rise of Web technology in the 1990s, a variety of websites have emerged, gradually enriching and changing people#39;s lives.
Sina Weibo was born in 2009 and is a domestic media platform based on user relations. Users can share content in various forms such as text, pictures, and videos through terminals such as PCs, mobile phones, or tablets to realize real-time information dissemination and interaction. Due to its power and ease of use, it has become one of the most well-known social networking sites in the country. With years of development, Sina Weibo has hundreds of millions of registered users and a wide range of Weibo V, so how to effectively obtain the user#39;s Weibo information has become a hot topic.
This thesis explores a variety of crawler technologies based on the Python language, and implements a system for searching Weibo user information. The purpose is to obtain relevant information of Weibo users, and has functions such as saving to local and data visualization. The main development tools are PyCharm and Chrome, the operating environment is Windows, and the Python version is Python 3.6.
Key Words:Web; Sina Weibo; Web Spider; Python;
目 录
第1章 绪论 1
1.1背景 1
1.2国内外研究现状 1
1.3 研究目的及意义 2
1.4 各章节的安排及概述 2
第2章 相关技术介绍 3
2.1 Python语言 3
2.1.2 Python语言的产生和发展 3
2.1.2 Python语言的特点 4
2.2 HTTP协议 5
2.2.1 HTTP简介 5
2.2.2 HTTP特点 5
2.3 Web页面的构成 5
2.4 URL 6
第3章 系统设计 8
3.1总体框架设计 8
3.2 数据库设计 9
第4章 系统实现 11
4.1爬虫模块的实现 11
4.1.1 请求网页 11
4.1.2 解析网页 12
4.1.3 数据库操作 13
4.2 网页模块的实现 13
4.2.1 前端部分 14
4.2.2 后台部分 14
4.2.3 数据可视化部分 14
4.3 系统实现中的一些问题探讨 15
4.3.1 爬虫的效率 15
4.3.2 页面的反爬 15
4.3.3 JavaScript动态渲染的页面 16
4.3.4网络爬虫合法性的探讨 16
第5章 系统测试及结果展示 17
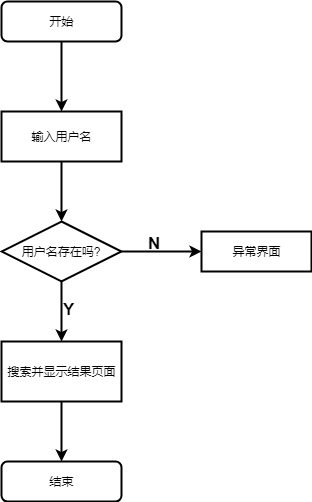
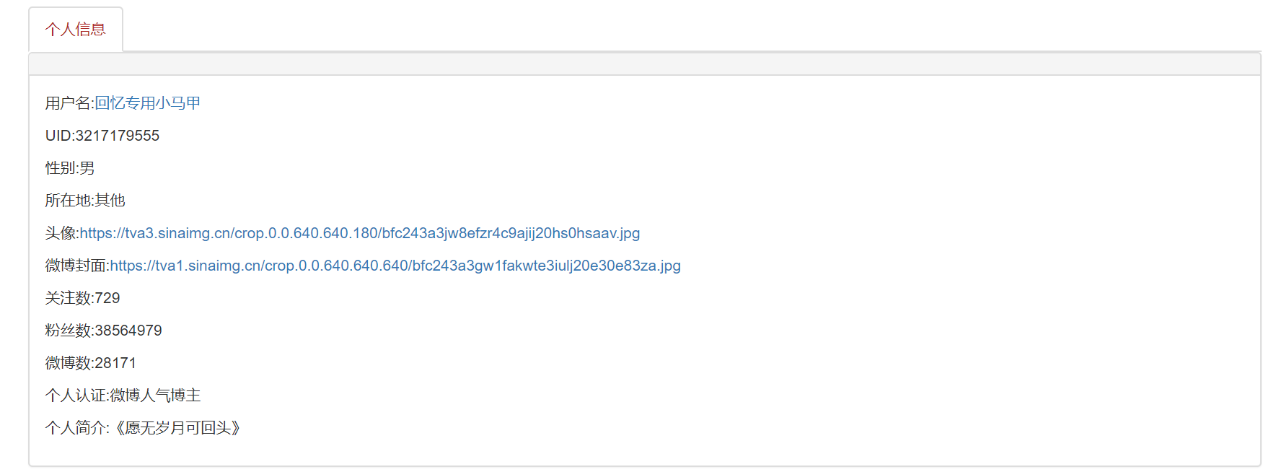
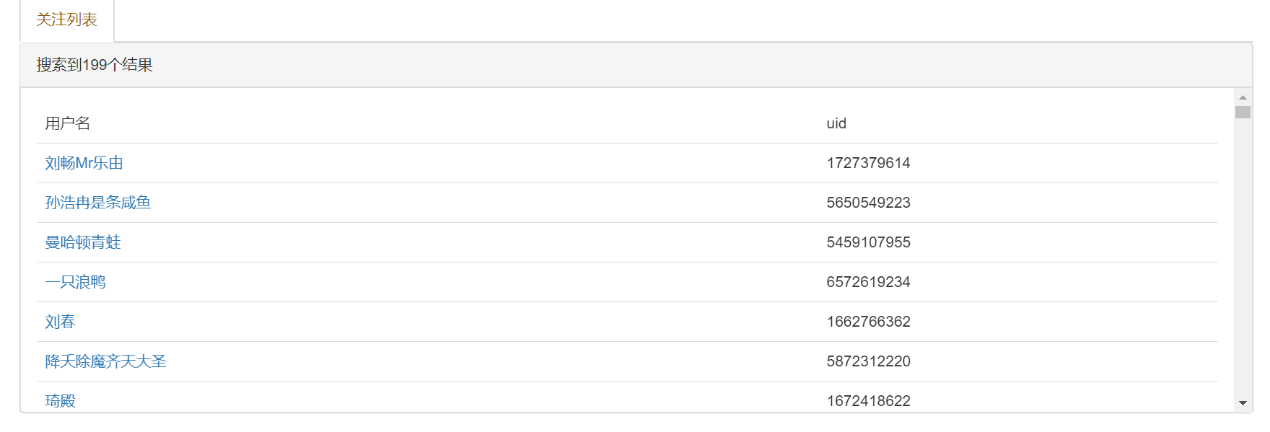
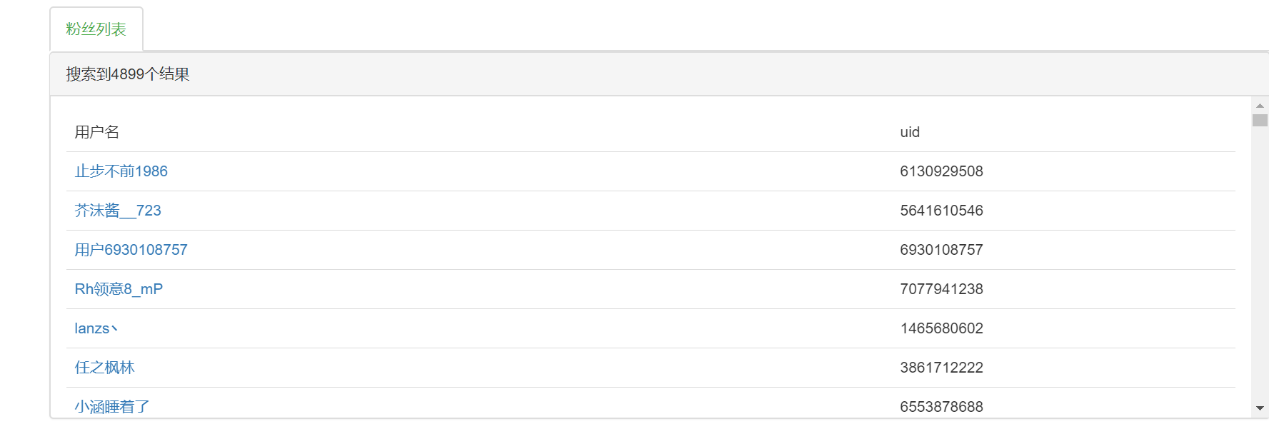
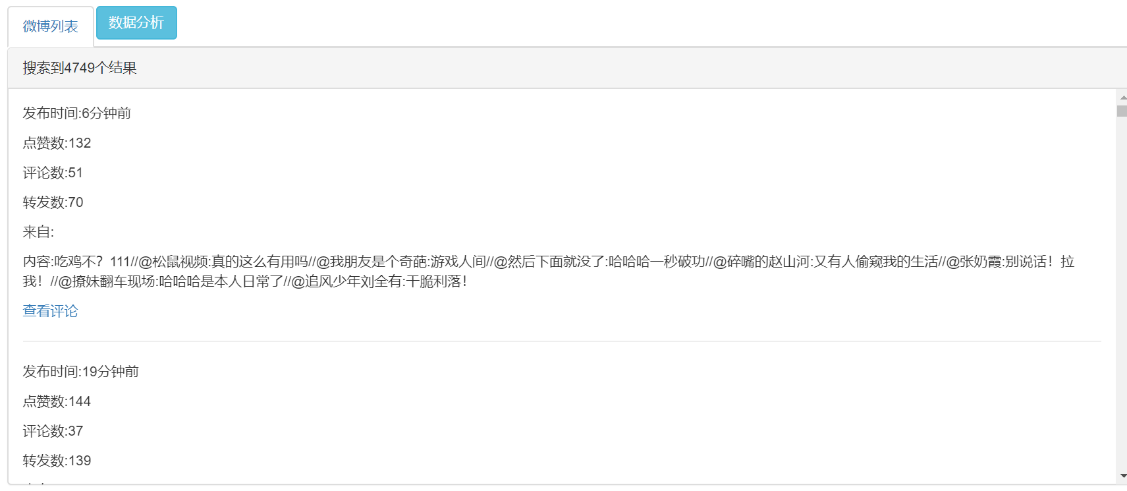
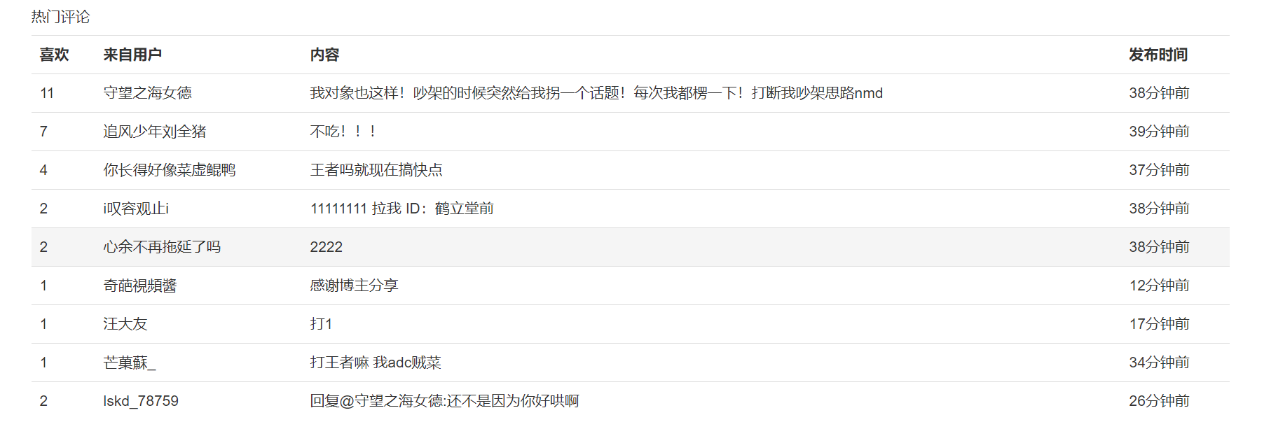
5.1 正确结果页面 17
5.2 错误结果页面 19
5.3 保存页面 19
5.4 数据可视化页面 20
第6章 结论 21
6.1收获 21
6.2不足与展望 21
参考文献 22
致 谢 23
第1章 绪论
1.1背景
现在人类社会处在一个信息量爆炸的时代,有人说21世纪是大数据的时代,我想也是。据统计,现在的互联网已经存在超过140亿个网页,其中也包含了大量重复和无效的网页。搜索引擎是指根据某种特定的策略,运行设计好的计算机程序从互联网上搜集信息,在集中对信息进行组织和处理后,为用户提供信息检索服务,并将检索相关的信息展示出来的系统。过去,一种称为“通用搜索引擎”的搜索技术在很大程度上帮助人们在互联网上寻找信息。然而,这种搜索方法逐渐暴露了它的缺点:在大多数情况下,它无法提供个性化和专业化的信息搜索,查准率偏低、内容陈旧等。正是这些种种原因导致了面向主题搜索引擎的产生。主题搜索引擎的优点是可以针对特定的对象,能够满足特定领域和人员的需求,更适合社会形势的需要。
现在比较知名的搜索引擎有Google,Firefox,IE等。这些搜索引擎的核心技术正是网络爬虫。网络爬虫是一个从网页自动获取信息的程序。随着互联网技术的发展,目前诞生了很多主流的爬虫技术,但与此同时网站为了防止信息泄露各种“反爬”措施也层出不穷,就这样在不断的“爬”和“反爬”之中爬虫技术变的越来越完善。
1.2国内外研究现状
网络爬虫分为四类:通用爬虫、主题(聚焦)爬虫、增量爬虫、deep web爬虫。在国内,主题爬虫方面的研究比较多,实现网络爬虫的程序设计语言以Python和Java居多。目前常用的网络爬虫的框架有Scrapy和PySpider。国内爬虫相关技术的研究从1998就开始了,但直到2006年开始才有较大规模的发展,近几年爬虫相关的研究文献都在400篇左右,保持了稳定的发展趋势,研究的机构则以北京邮电大学和电子科技大学为主。
在国外,自从1993年在MIT诞生了第一个爬虫程序,至今已有20多年的发展。比较知名的有Google公司的通用爬虫Google crawl,IBM的增量爬虫webFountain。近年来IBM还和印度理工大学开发了一款基于分类器的主题爬虫,效果显著。
1.3 研究目的及意义
对于有些用户来说,他们并不需要互联网上海量的信息,他们只希望获取一些特定的内容。比如淘宝网某个商品的买家评论,知乎某个问题的回答,微博某个用户的个人信息等。如果用传统的方式,用户需要登陆账号,搜索内容,筛选信息,过程比较繁琐。所以我希望设计一个自动的程序,用户可以一键获取这些信息。这样的好处不止是方便快捷,还避免了一些诸如网页广告,网页病毒的问题。网络爬虫正发挥着越来越显著的作用,综上所述,研究爬虫的原理,改进爬虫的效率是很有必要的。
1.4 各章节的安排及概述
第一章阐述了本论文研究的背景,意义、目的等,是本文研究的前提。第二章详细介绍了本文研究中所设计的一些技术,第三章是描述了程序的大体设计,包括框架设计和数据库设计,第四章详细描述了本文的研究过程、程序的实现过程以及一些技术的探讨。第五章是结果展示,第六章是本次论文的结论。
第2章 相关技术介绍
2.1 Python语言
2.1.2 Python语言的产生和发展
Python 是由荷兰科学家 Guido van Rossum 在1980年至1990年间在荷兰国家数学和计算机科学研究所设计出来的。Guido研制这门的语言的目的是希望能开发出一种简易的像英语一样的语言供人们使用。在Python语言之前已有诸如C、C 等优秀语言,而事实上Python也是一门类C语言,它的官方解释器就是用C写的。直至今日Guido仍在Python的标准制定中起着关键作用,被人们称为“仁慈的独裁者”。
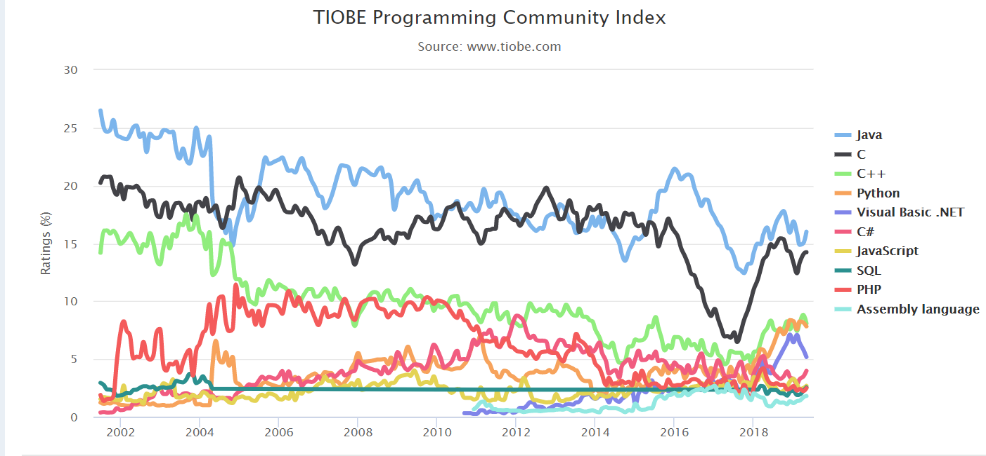 Python的真正流行是从Python 2.7开始的,现在最新的Python的版本是3.7,经过20余年的发展Python俨然成为了最受程序员欢迎的语言之一,在Web开发,数据科学,人工智能等多个领域发挥着重要作用。Python先后被TIOBE评选为2007、2010、2018年度编程语言,成为极少数获得三次奖项的语言。由于Python语言的简洁易读,目前国外的一些科研机构或大学已经把Python语言作为主要的教学语言,因此Python在教育市场也发挥着积极作用。这让更多的人热爱编程,热爱计算机,毫无疑问促进了计算机学科的发展。而在国内,尽管Python的起步比较晚,但随着十年左右的发展,现在Python语言已经得到了较大规模的应用,例如知名影评网站豆瓣的后台主要就是Python写的,国内的Python相关岗位也越来越多,在互联网上Python相关的资料相比几年前年有了铺天盖地的增长。以下是TIOBE历年编程语言排行:
Python的真正流行是从Python 2.7开始的,现在最新的Python的版本是3.7,经过20余年的发展Python俨然成为了最受程序员欢迎的语言之一,在Web开发,数据科学,人工智能等多个领域发挥着重要作用。Python先后被TIOBE评选为2007、2010、2018年度编程语言,成为极少数获得三次奖项的语言。由于Python语言的简洁易读,目前国外的一些科研机构或大学已经把Python语言作为主要的教学语言,因此Python在教育市场也发挥着积极作用。这让更多的人热爱编程,热爱计算机,毫无疑问促进了计算机学科的发展。而在国内,尽管Python的起步比较晚,但随着十年左右的发展,现在Python语言已经得到了较大规模的应用,例如知名影评网站豆瓣的后台主要就是Python写的,国内的Python相关岗位也越来越多,在互联网上Python相关的资料相比几年前年有了铺天盖地的增长。以下是TIOBE历年编程语言排行:
图2.1 编程语言排行
2.1.2 Python语言的特点
Python语言具有如下特点:
(1)简单易学。Python的语法十分简洁,通常100的C 代码Python只需要10行就能实现。与此同时Python在设计时抛弃了一些在C或C 中一些诸如指针和引用等晦涩难懂的概念,这让程序的设计变得清晰和简单。Python 的这种类似自然语言的语法是它最大的优点之一,它能让你专注于做什么而不是怎么做。
(2)免费、开源。Python从语言规范到解释器都是开源的,同时也是 FLOSS(自由/开放源码软件)之一。简单来说,你可以自由地阅读Python的官方解释器并做出修改,甚至发布你地Python解释器。事实上现在市面存在着多种不同的解释器,它们都有各自的用途。
(3)可移植性。由于Python是开源的,因此它可以被各种开发者移植到不同的平台上。在这一点上它与Java有一些类似,他们都存在一个称为“虚拟机”的东西,可以执行编译过后的字节码,因此只要对应机器上有Python的虚拟机就能执行Python程序。
(4)解释性。Python是一门解释型的语言,与编译型语言不同,Python在运行程序的时候不会事先编译成机器码,而是编译成字节码,再通过解释的方式一行一行的执行字节码,也因为这个特点,Python的动态性很高,可以实现各种在静态语言中不能执行的操作,增加了其灵活性。
(5)面向对象编程。Python支持多种编程方式,例如面向过程编程,面向对象编程,函数式编程等,但基于目前的主流编程方式,用的最多的还是面向对象编程。面向对象的编程方式以数据为中心,它的核心的是类。采用面向对象的程序设计方法,程序的可维护性和复用率都比较高。
(6)可扩展性。通常可以在C或C 语言中调用Python脚本,也可以在Python代码中调用C、C ,这极大扩充的Python的适用范围,而在现实中有很多程序确实是这么做的。
(7)丰富的库及框架。Python有着好用的标准库及其丰富的第三库,这是Python流行的重要原因之一。几乎在计算机的大部分领域中,我们都能找到合适的Python库。常用的标准库有OS、Time、Json等,第三方库有用于图像处理的OpenCV,用于机器学习的TensorFlow、PyTorch以及Web框架Flask等。
(8)规范的代码。Python 采用强制缩进的方式使得代码的可读性很高,而且看起来很整洁。
当然Python还是存在缺点的。最主要的有(1)运行速度相比于C和C 等编译型语言速度较慢;(2)发布程序时必须发布源代码,容易造成代码泄密;(3)动态性过高容易产生一些隐藏很深的错误,不利于代码调试。
2.2 HTTP协议
2.2.1 HTTP简介
HTTP协议是Hyper Text Transfer Protocol的缩写,中文名称为超文本传输协议。它是一种用于从万维网服务器向本地浏览器传输超文本信息的规范,任何在互联上传播的超文本信息都必须满足这个规范的要求,否则无法传送数据。常有的请求方式有GET和POST等。
HTTP是互联网上最常用的协议之一,但现在普遍流行的其实是基于HTTP的HTTPS协议。HTTPS与HTTP的主要差别在于加了一个SSL(安全套接层),
增加了数据传输时的安全性。
2.2.2 HTTP特点
(1)简单快速:当需要客户端从服务器请求服务时,只需要输入一个URL。GET和POST是最常用的请求方法。每个方法指定了客户与服务器之间通信的类型,通常GET请求的信息会包含在URL中,而POST请求的信息会隐藏在请求体中,因此当传输的信息包括密码等敏感内容时应采用POST请求,以免密码泄露。由于HTTP协议的简单性,相对于的服务器的程序规模较小,通信速度非常快。
(2)灵活性:HTTP允许传输任何类型的数据对象。正在传输的类型由内容类型标记。
(3)无连接:无连接的意思是将每个连接限制为仅一个请求。服务器在处理客户端的请求并收到来自客户端的回复后立即断开连接。通过这种方式可以节省传输时间。
(4)无状态:HTTP是无状态协议。无状态意味着协议没有用于事务处理的内存。缺少状态意味着如果后续需要处理先前的信息,则必须重新传输该信息,这可能导致每个连接传输的数据量增加。另一方面,当服务器不需要以前的信息时,它的响应速度更快。
(5)支持B/S及C/S模式。
2.3 Web页面的构成
一个WEB页面通常由HTML,CSS,JavaScript三部分构成。HTML和CSS是万维网的根基。若干年前,人们开始意识到Web标准的重要性,网页的结构与表现分离成为共识,网站开发人员普遍开始采用渐进增强式的开发方式,也就是HTML,CSS,JavaScript的分离开发。近年来随着Web技术的不断发展,网页的内容越来丰富,可交互性越来越强,网站承载的功能和用途也越来越多。而且越来越来的网页支持了响应式布局,可以适应PC、手机、平板等多种终端。
HTML,全称为Hyper Text Markup Language,中文名称超文本标记语言。HTML诞生于20世纪90年代初,那时只是用于规定少量构建网页的元素。其中大部分元素中都是为了描述网页的文本,如标题、段落、列表、指向其他网页的链接等,看起来十分的粗糙。HTML另一个特点是指明了网页内容的含义,即语义。语义化的HTML是指用最恰当的HTML元素来标记内容。语义化的目的有:(1)提升可访问性和互操作性(2)提升搜索引擎优化(SEO)的效果(3)使得维护代码和添加样式变得容易(4)使得代码更少,页面加载速度变快。现在编写语义化的HTML已经成为共识。随着更多元素的引入以及对语法规则本身的调整,HTML这门语言的版本号也在更新。最新的版本是HTML5,HTML5新增了大量功能,比如原生的视频和音频功能,使网页彻底摒弃了繁重的Flash,性能进一步提高。现在流行的“微信小程序”也是基于H5开发的。
CSS,全称为Cascading Style Sheets,中文名称层叠样式表。CSS是一种文本文件,包含了一个或多个决定网页中某些特定元素如何显示的规则。CSS里有控制基本格式的属性(如font-size和color),有控制布局的属性(如position和float), 网页的布局通常由“div CSS”完成,有控制元素显示或消失的属性,还有决定访问者打印时在哪里换页的打印控制属性。在使用CSS一定要分清哪些内容是由CSS决定的,这样可以最大程度发挥出页面的性能。目前CSS最新的规范是CSS3。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: