基于图数据降维处理的链接预测算法研究毕业论文
2020-04-04 10:49:59
摘 要
图数据已经成为一类重要的数据,它用来描述丰富的信息及信息之间的依赖关系,已经成为数据挖掘领域中一种经典的数据建模方法。链接预测作为复杂网络研究中的一个新兴的研究方向,是利用复杂网络中的各种已知信息来预测网络中节点之间存在链接的可能性,这种预测包含了两个方面预测:包括网络中未知链接的预测和未来链接的预测。随着数据规模的飞速增长,大规模图数据在计算机中的存储也成为了当前一个亟待解决的问题,传统的链接预测算法主要基于网络的拓扑结构设计计算模型,通常将图数据存储为邻接矩阵,将邻接矩阵作为链接预测的输入数据,通过简单的链接预测算法的计算便可以得到链接预测的结果,即结果的邻接矩阵。但是通过研究与观察发现,当今的大规模真实的复杂网络数据集的邻接矩阵都为稀疏矩阵,存储每一个复杂网络时所需要的存储空间为O(n2),其大部分空间是存储邻接矩阵中为0的值,这显然浪费了很大一部分的存储空间。同时大规模的复杂网络一般都具有无标度特性,即网络中少数的节点往往拥有大量的链接,而大部分节点却拥有很少的链接,这反映了各节点之间的连接状况(度数)具有严重的不均匀分布性,即网络的每个节点在网络中的重要性不同。
针对以上问题,本研究通过采用行压缩(CSR)的稀疏矩阵存储方式来存储图数据,并在此基础上实现对图数据的降维预处理,通过降维预处理既可以保存下来网络中的关键信息又可以减少大规模复杂网络所需的存储开销,降维以后再使用链接预测算法对降维后的数据进行链接预测可以得到预测结果仍能保持较高的准确性。
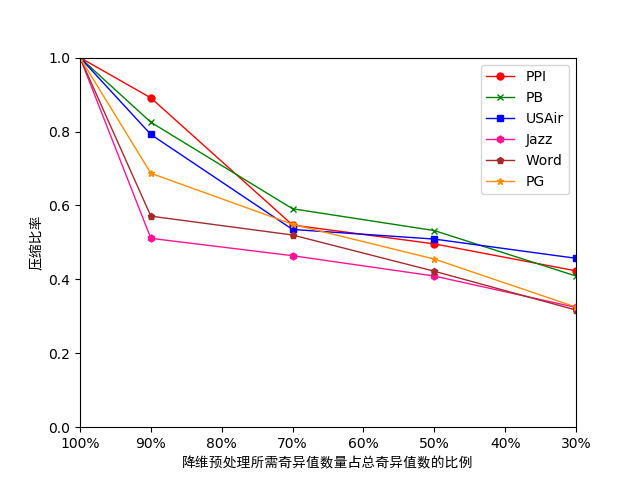
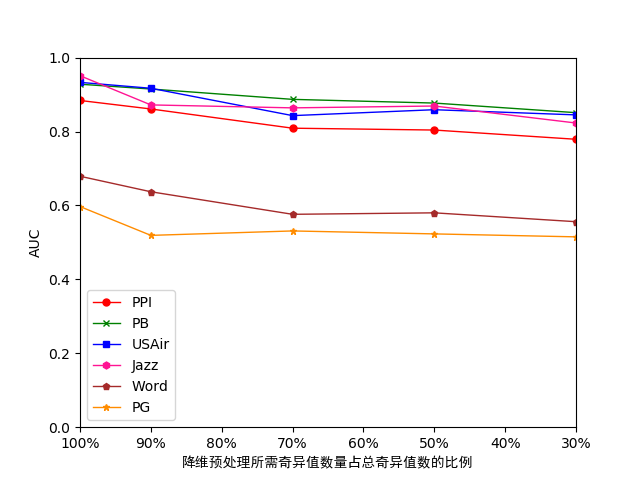
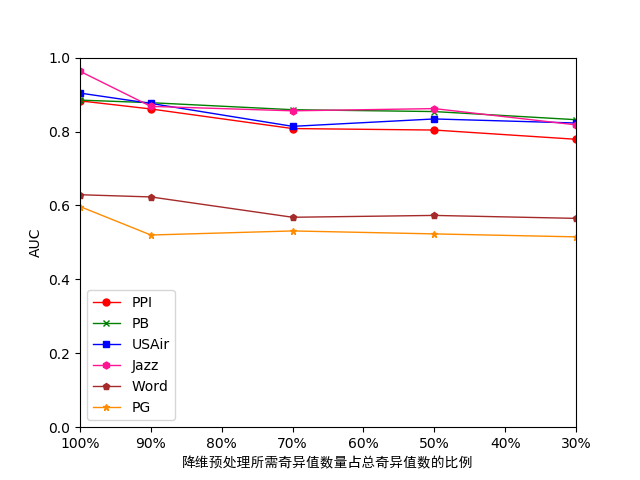
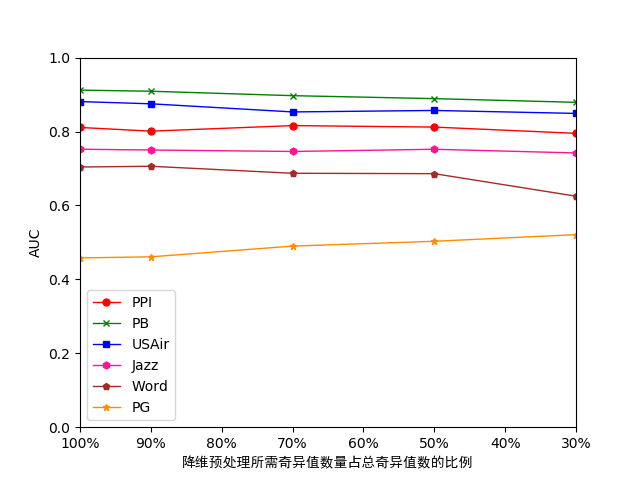
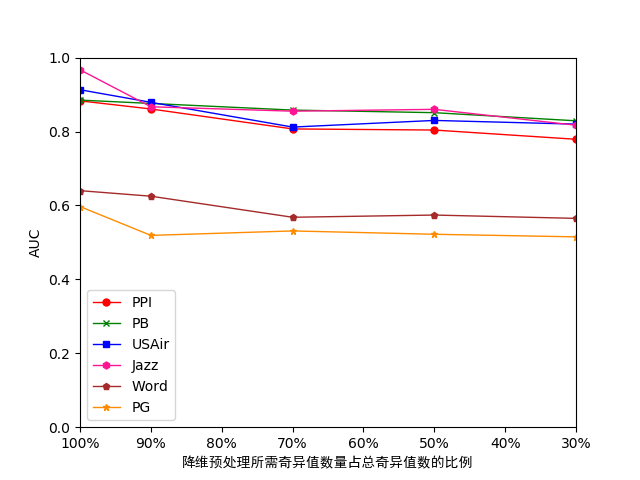
经过在多组真实数据集上利用多种预测算法对降维前后的数据进行测试,当选取的奇异值数量为总奇异值数量的30%时,原数据集所需的存储开销约为降维前的30%,但其预测准确性最多只下降了0.1左右,可见在对数据进行降维后可以在不影响预测准确度的情况下充分减少存储开销,帮助预测算法实现处理规模的扩展。
关键词:链接预测;降维;行压缩的稀疏矩阵存储方式;复杂网络
Abstract
Graph data has become an important type of data. It is used to describe the rich information and the dependencies between information. It has become a classic data modeling method in the field of data mining. As an emerging research direction in the research of complex networks, link prediction is the use of various known information in complex networks to predict the possibility of links between nodes in the network. This prediction includes two aspects of prediction: including the network Unknown link forecast and future link forecast. With the rapid growth of data size, the storage of large-scale graph data in computers has become a current problem to be solved. The traditional link prediction algorithm is mainly based on the topology design of the network to design the calculation model. Usually, the graph data is stored as an adjacency matrix. The adjacency matrix is used as the input data for link prediction. The result of link prediction can be obtained through the calculation of a simple link prediction algorithm, that is, the adjacency matrix of the result. However, through research and observation, it is found that the adjacency matrix of today's large-scale real complex network datasets is a sparse matrix, and the storage space required for storing each complex network is O(n2), and most of the space is the storage adjacency matrix. A value of 0 in the middle, which obviously wastes a large part of the storage space. At the same time, large-scale complex networks generally have scale-free characteristics. That is, a small number of nodes in a network often have a large number of links, and most nodes have few links. This reflects the connection status (degrees) between nodes. There is a serious uneven distribution, that is, each node of the network has different importance in the network.
In view of the above problems, this study uses row compression (CSR) sparse matrix storage to store map data, and on this basis, it can reduce the dimensionality of the map data, and can save the network's The key information can also reduce the storage cost required for a large-scale complex network. After the dimensionality reduction, the link prediction algorithm is used to predict the reduced-dimensional data, and the prediction result can still maintain high accuracy.
After testing the data before and after dimension reduction by using multiple prediction algorithms on multiple sets of real data sets, when the number of singular values selected is 30% of the total number of singular values, the storage cost required for the original data set is reduced. The former 30%, but its prediction accuracy only dropped by about 0.1. It can be seen that after reducing the dimension of the data, the storage cost can be fully reduced without affecting the accuracy of the prediction, and the prediction algorithm can help realize the expansion of the processing scale.
Key Words: Link prediction; dimensionality reduction; sparse matrix storage for row compression; complex networks
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1研究背景 1
1.2国内外研究现状 1
1.3主要工作内容和意义 2
1.4论文的组织结构 3
第2章 经典的链接预测方法的分析与研究 4
2.1问题描述 4
2.2评价方法 4
2.3链接预测的经典算法 4
2.3.1基于局部信息的相似性算法 5
2.3.2基于节点路径的相似性算法 6
2.3.3基于随机游走的相似性算法 7
2.4 经典的链接预测算法的分析 7
2.5本章小结 8
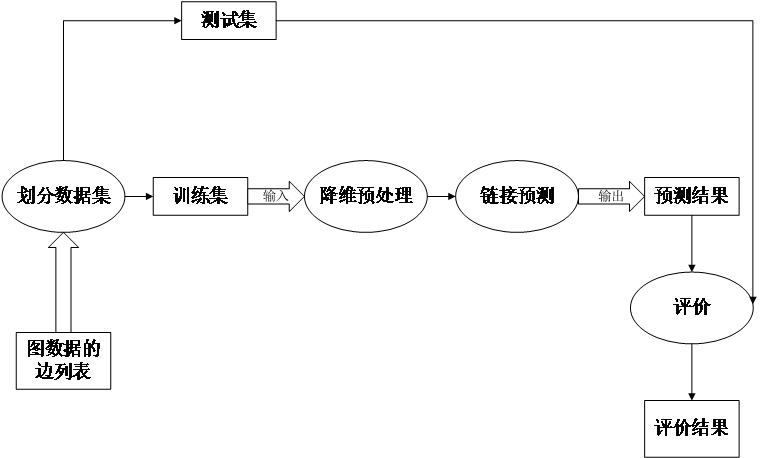
第3章 基于图数据降维处理的链接预测算法 10
3.1引言 10
3.2相关概念 12
3.3基于图数据降维预处理的链接预测算法的设计与实现 14
3.3.1总体设计方案 14
3.3.2算法的编码实现 14
3.4 基于图数据降维预处理的链接预测算法的分析与对比 21
3.4.1算法的空间复杂度分析 21
3.4.2算法的时间复杂度分析 22
3.5 本章小结 22
第4章 实验与分析 23
4.1实验环境搭建 23
4.1.1硬件环境 23
4.1.2软件环境 23
4.2实验来源和数据集 23
4.2.1数据介绍 23
4.2.2数据处理 24
4.2.3数据分析 24
4.3 实验设计 25
4.4 实验结果与分析 26
4.4.1存储开销测试 26
4.4.2准确性测试 27
4.5 本章小结 32
第5章 总结与展望 33
5.1总结 33
5.2展望 33
参考文献 34
附录A 35
附A1降维预处理算法 35
附A2链接预测算法 36
附A3链接预测结果 40
致 谢 41
第1章 绪论
1.1研究背景
图数据作为一种表达现实世界中对象与对象之间依赖关系的经典的数据模型,其应用非常广泛,其在Facebook、Twitter和微博这样的社交网络中表示用户与用户之间关系的模型,在Web数据超链接中表示网页与网页之间的跳转关系模型,在蛋白质网络中表示蛋白质与蛋白质之间的交互关系模型,在爵士音乐家交互网络中表示两个音乐家之间是否存在联系等。链接预测(Link Prediction)问题是网络中的一个基本问题,在计算机应用方面已经有了相当长时间的研究。链接预测是复杂网络研究中的一个新兴的研究方向,它通过利用网络中已知的网络节点信息和网络拓扑结构等信息对未知的或者未来一段时间的链接进行预测[1]。链接预测主要包括两方面的预测:(1)预测已经存在于图中但是尚未被发现的链接,即网络中未知链接(Missing Links)的预测;(2)预测现在未存在但是未来有可能产生的新的链接,即网络中未来链接(Future Links)的预测[2]。链接预测可以用来预测社交网络中用户之间潜在友谊关系的存在,在生物交互网络中,链接预测提供了一种低成本的蛋白质交互关系的预测,除此之外链接预测方法还可以应用于电商网络中针对特定用户的商品推荐。
随着现代互联网技术的飞速发展,网络已经成为传播信息的主要载体,人们可以通过网络获取各种想要的信息和交流沟通分享各种信息。近些年来互联网用户数量和信息数量急剧增长,Internet为用户提供越来越多信息和服务的同时,其自身结构也变得更加复杂,在海量的信息中,对图中的两个节点进行链接预测变得越来越困难。因此如何从一个具有大量节点和边的网络图中挖掘用户之间的链接关系已经成为一个重要问题。
随着网络节点数量的迅速增长,图数据规模急剧增长,图数据变得越来越复杂,链接预测问题变得更具有挑战性。当把复杂网络抽象为图时,节点表示对象,边表示对象之间的交互事件,那么建模之后得到的图的邻接矩阵将会很大。与此同时,真正的复杂网络是非常稀疏的,即节点只连接到网络中所有节点的一小部分。例如,在Facebook的情况下,典型的用户链接到网络的超过5亿个节点中的大约100个,可见当对整个图进行存储时,通常需要大量的存储空间。例如存储一个节点数量为n的复杂网络,存储每一个复杂网络时所需要的存储空间为O(n2),在邻接矩阵中,若两个节点之间存在边则Aij=1,若两个节点之间不存在边则Aij=0,伴随着图数据规模的增大,网络中节点数量越来越多,网络中点与点之间的边相对于整个复杂网络图来说就变得非常稀疏了,这是因为在稀疏的网络的邻接矩阵中大部分空间是存储邻接矩阵中为0的值,只有少部分空间存储的是复杂网络中的边即存储的值为1,这显然浪费了很大一部分的存储空间。
1.2国内外研究现状
近些年来链接预测问题作为数据挖掘中的一个重要问题,其因具有重要的学术价值和应用价值吸引了大量的的科研工作者的关注。链接预测问题一直是一个长期的挑战,它在跨学科领域有着广泛的应用,包括发现社交网络的缺失部分并分别在在线社交网络和电子商务网站上推荐朋友和产品。已经提出了各种链接预测算法来解决链接预测问题。链接预测算法的主要过程是给每个链接分配一个相似值,然后对它们进行排序,相似性分数越高的链接存在的可能性越大。与传统的数据挖掘算法关注对像本身的特征不一样,链接预测算法关注的是对象与对象之间的关系,目前的链接预测算法更多的关注于未来链接的预测,其算法由过去的基于马尔科夫链进行的路径分析和链接预测发展到现在的以网络拓扑结构预测为主的预测算法。复杂网络作为一种对于真实数据的一种抽象描述其拓扑结构可以充分反应复杂网络的链接性质。在无数科研工作者的共同努力下,链接预测的研究取得了巨大的发展[3]。此外,目前已经提出了相当多的统计参数来揭示社交网络的结构特征。如度分布、网络直径、平均聚类系数和平均路径长度等。目前已有的大量研究从不同角度切入链接预测这一课题,常见的有主要链接预测技术和方法可以概括为以下几种:基于局部信息的链接预测算法主要包括节点共同邻居相似度算法(CN)、余弦相似度算法Salton算法、大度节点有利指标(HPI)、大度节点不利指标(HDI)、Jaccard系数相似度算法、Adamic/Adar(AA)[4]算法、优先增量法(PA)、Sorenson算法、LHN-I算法和资源分配算法(Resource Allocation)[5]等,其中CN算法是最简单的基于局部信息的相似性算法,每个节点对之间的相似度被定义为两个节点之间的共同邻居数量。基于路径相似性的算法主要包括Lu等人提出的局部路径(LP)相似性度量方法和基于全局信息的Katz算法指标[6]。基于随机游走的相似性算法主要包括平均通勤时间指标(ACT)、随机游走的余弦相似性指标(Cos )和有重启的随机游走算法(RWR),此后Liu等人提出了一种基于叠加的局部随机游走相似性度量方法(LRW)[7]。
1.3主要工作内容和意义
(1)主要工作
本文所研究的是基于图数据降维的链接预测算法的研究,分析当前经典的链接预测算法及其预测时图数据的输入输出格式,分析图数据所占的存储空间大小,提出了一种基于行压缩存储格式的图数据降维的链接预测算法。本文的研究内容主要分为两部分:
第一部分是对经典的链接预测算法进行综合调研评测,对比和评估当前算法的准确性和开销,主要是评估图数据在不同的链接预测算法情况下的AUC值。
第二部分是基于CSR(Compressed Sparse Row)存储方式的图数据,设计并实现基于图数据降维的与处理技术,以尽可能保证预测准确性为前提,充分减少内存空间的消耗,帮助链接预测算法实现处理规模的扩展。
(2)意义
本研究采用行压缩的图数据存储方式,其意义主要体现在两方面:一方面是改变了传统链接预测算法中所用的图数据的存储格式,其大大减少了内存中用来存储邻接矩阵所需要的内存空间,使其在相同的存储空间大小下可以存储更大的复杂网络。另一方面是利用奇异值分解技术(Singular Value Decomposition)来对图数据进行降维,该降维方法能够去除网络中那些不重要的信息而保留网络中的关键信息,利用降维之后的数据进行链接预测。显然,降维以后的图数据再进行链接预测时,预测的准确性有所下降,但是AUC的值在可接受的范围内实现了图数据处理规模的扩展。其主要体现在进行降维以后,用CSR格式存储降维之后的图数据相对于邻接矩阵存储的图数据又进一步的减少,在这种只存储一少部分信息却能够得到较高准确率的情况下可以对更大规模的网络进行预测。
1.4论文的组织结构
本文共分5个章节,各章节主要内容如下:
第一章是绪论。本章介绍了选题的背景和研究现状,说明了本文研究的内容和意义,阐述了链接预测的应用领域及意义,随着图数据的急剧增长,存储图数据所需要的存储空间数量也急剧增长,通过对图数据进行降维预处理可以解决存储空间的问题,证明了研究的意义。
第二章是对链接预测的一些链接预测相关的基础知识进行介绍和分析。首先对链接预测的定义和评价方法进行了具体的描述。然后,对当前被广泛研究的经典的基于网络拓扑结构的链接预测算法进行了具体的介绍,最后分析了链接预测方法中常用的的输入输出数据的存储方式,提出了基于行压缩存储方式的图数据降维的链接预测方法。
第三章是本文的核心部分,详细介绍了基于图数据降维预处理的链接预测算法的设计与实现。本章先引出使用CSR格式存储数据并对其进行降维的好处,明确了本文研究的意义。然后,介绍了本研究所要用到的相关概念,最后对本算法的总体设计及编码实现进行了详细的描述并对本文实现的代码进行了时空复杂度的分析。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: