高校学生学业预警系统设计与实施毕业论文
2020-04-08 14:24:07
摘 要
本论文利用高校学生的基本信息和课程成绩数据,运用数据挖掘及相关专业技术,分析影响本科学生学业失败风险的关键因素。作者运用统计分析、多维分析方法观察学生成绩数据,进行了数据清洗、数据衍生变量生成、数据汇总合并等数据预处理,运用决策树算法、Logistic回归分析和神经网络算法建立了学生挂科预测模型。该模型准确率可达92.6%,查准率为16.9%,查全率达到95.7%。另外,研究结果表明学生在某门课程的学业失败风险,与该学生以往的综合成绩表现,以及该课程的历史挂科率、开课学期存在明显的相关关系。
在学生挂科预测模型的基础上,设计与开发了高校学生学业预警系统。该系统对学生各门课程的学业失败风险进行预测,为其学业警示提供预先的参考。该系统从学生、教师、辅导员三个角度,实现了学业挂科风险管理;系统提供的预测挂科信息,能方便不同用户采取更有效的干预措施。系统有助于高校学生成绩分析和教务管理水平的提高。
关键词:成绩分析;学业预警;教务管理;数据挖掘
Abstract
This paper makes use of the basic information and course achievement data of college students, and uses data mining and relevant professional techniques to analyze the key factors affecting the risk of academic failure of undergraduates. The author used statistical analysis and multidimensional analysis methods to observe student achievement data, performed data preprocessing such as data cleansing, data derived variable generation, and data aggregation and merger, and established a student exam failure prediction model using decision tree algorithm, logistic regression analysis, and neural network algorithm. The accuracy rate of the model is 92.6%, the precision rate is 16.9%, and the recall rate reaches 95.7%. In addition, the results show that students' failure risk in a certain course has a significant relationship with the students' previous comprehensive performance, the historical failure rate and the commencement semester of the course.
Based on the students' exam failure prediction model, the university students' early warning system was designed and developed. The system predicts the risk of academic failure for each student's course and provides a preliminary reference for academic warnings. The system realizes the risk management of academics exam failure from three perspectives: students, teachers, and counselors; the system provides predictive information to facilitate different users to adopt more effective intervention measures. The system is conducive to the analysis of college students' academic performance and the improvement of educational management.
Key Words: Grades Analysis; Academic Warning; Educational Administration; Data Mining
目录
1 绪论 1
1.1 背景及意义 1
1.1.1 研究的背景 1
1.1.2 研究的意义 1
1.2 研究现状 2
1.2.1 国外研究现状 2
1.2.2 国内研究现状 2
1.3 研究思路与研究方法 3
1.3.1 研究思路 3
1.3.2 研究方法 4
2 数据理解与准备 5
2.1 样本选择与变量定义 5
2.2 数据预处理 5
3 模型建立与评估 8
3.1 研究模型建立 8
3.1.1 C5.0决策树算法 8
3.1.2 Logistic回归 8
3.1.3 人工神经网络 9
3.2 模型评估 10
3.2.1 实验结果分析 10
3.2.2 评估指标 13
3.2.3 模型的优选与综合 13
4 系统设计与实施 16
4.1 系统概要设计 16
4.1.1 系统设计目标 16
4.1.2 用户角色描述 16
4.1.3 系统架构 16
4.1.4 功能结构设计 17
4.1.5 接口设计 17
4.2 系统详细设计 17
4.2.1 系统权限管理 17
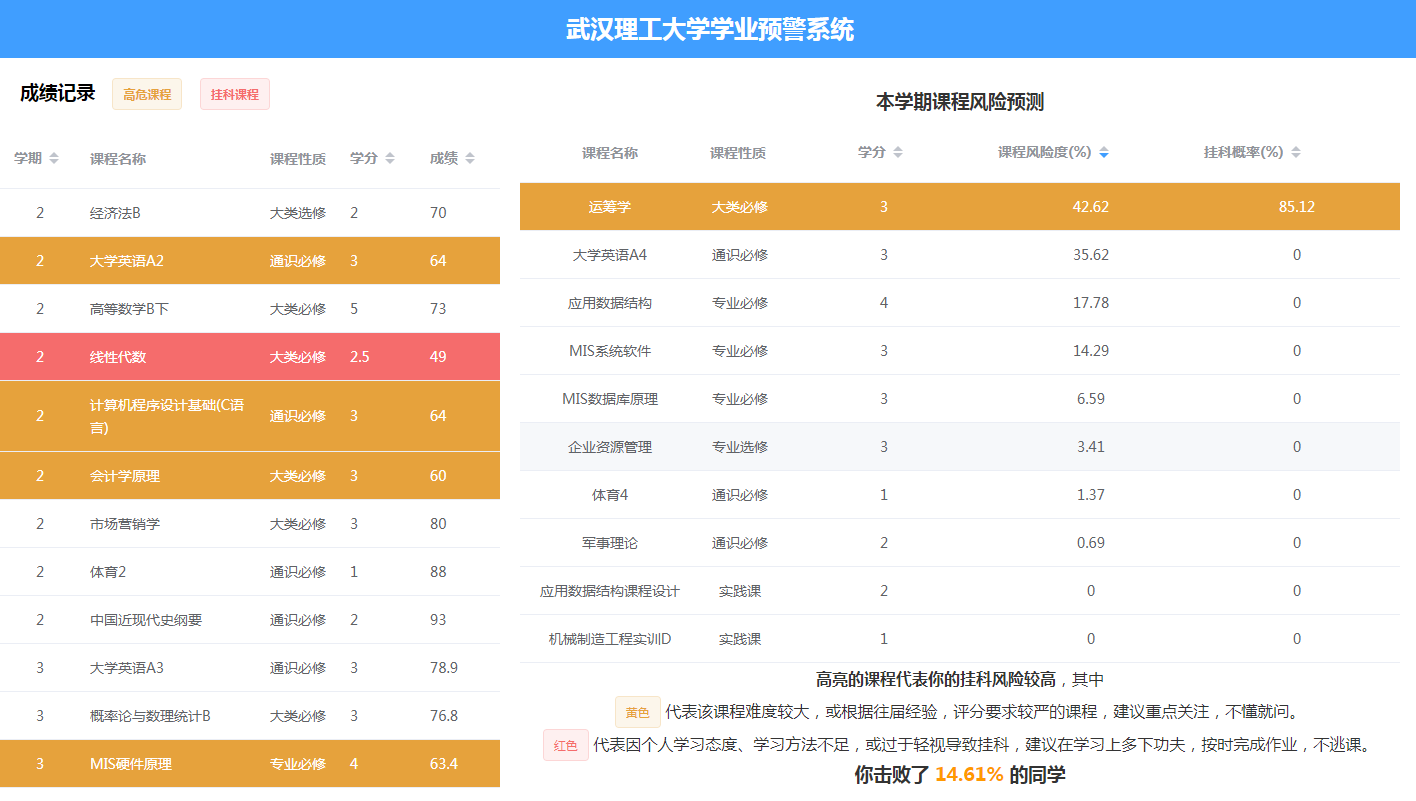
4.2.2 学生成绩报告 18
4.2.3 课程成绩预测 18
4.2.4 班级成绩一览 18
4.2.5 教务数据管理 19
4.3 系统实施 20
4.3.1 用户登录 20
4.3.2 学生成绩报告 20
4.3.3 课程成绩预测 21
4.3.4 班级成绩一览 22
5 总结与展望 23
6 参考文献 24
致谢 25
1 绪论
1.1 背景及意义
1.1.1 研究的背景
进入新世纪以来,中国高等教育事业发展迅速。各个领域的重大科学研究成果不断涌现,重点大学的国际排名和知名度也在不断提升。随着信息技术和互联网在教育领域的普及,学校在很多方面都实施了信息化。在教育信息化的过程中,很多教育资源如沉积在数据库中的成绩信息并未得到充分的利用。而这些成绩往往包含着很多有价值的信息[1],是反映学校的教学水平、课程设置的合理性、学生的学习行为及其知识掌握程度的第一手资料,这些数据可以为学校改进招生和教学工作提供重要依据。但是,学生成绩的管理并没有引发高校的足够重视。特别是在分析和处理学生成绩时,大多数高校的教育信息系统的功能仍停留在传统的增删改查阶段,只能获得一些数据的表面信息;难以进行数据的深度挖掘,就无法获取重要的有价值的知识。缺少对学生成绩的横向和纵向比较研究,也鲜有各学科成绩间内在关联的挖掘。
1.1.2 研究的意义
学科成绩间的内在联系是广泛存在于各个专业的各门课程中的,学科成绩间内在联系的分析和研究对学生和学校都有着十分重要的意义。通过了解学科成绩间存在的内在联系,学生可以清楚地认识到基础课程、先导课程的重要性,并在选课的时候,做到扬长避短,通过更多地选择与自己优势课程成绩正相关的课程来帮助提高成绩[2]。而对于学校来说,分析学科成绩间的内在联系可以为各专业培养计划中的课程设置提供重要的参考依据。
此外,通过对学生以往成绩的对比分析,可以为每个学生的学业水平做出科学合理的预估,为划分奖学金评定与学业警示的标准提供参考。对于每个学生而言,能更好地认识到自己学习上的优势和劣势,从而做出针对性的调整;对于学校而言,可以事前针对发现有重修或退学风险的学生,采取更有效的干预措施。
采用数据挖掘技术对高校教务数据进行全方位的分析,可以发现学业成绩与各种因素之间隐含的内在联系,这是传统评价方法无法做到的;可以了解学生各方面的能力,并为学生提供科学的个性化的指导,有助于学校的人才培养。同时,有助于教师优化教学流程和改进教学方式,完善高校教学培养方案,从而进一步提高我国高校的办学水平。
1.2 研究现状
1.2.1 国外研究现状
在美国等发达国家,数据挖掘技术早已走进了教务工作,成为了教务工作人员对学生成绩进行分析的重要手段[2]。美国教育部于2012年投入两亿美元开发教育数据计划,以运用数据分析来完善教育教学工作。其中的学习分析系统就是用于理解学生个性化学习模式,它通过数据挖掘、训练数据和功能模拟的框架模式运作。这个学习分析系统能够发现很多教师未曾关注的信息,用于帮助学生更有针对性的学习。例如针对学生考试不及格,分析其中的影响因素,可能包括教学环境、学习态度和能力、家庭原因等。
美国教育数据领域,既有IBM等大公司的身影,也有一些新兴的公司专注于此,比如Civitas Learning这家公司利用数据挖掘技术中的机器学习算法,分析并帮助学生制定个性化的学习计划,从而提高学生成绩[3]。公司的立足之本是在教育领域构建的庞大的教育数据库,这些海量数据包括了来自各学校的上百万条的学生数据和相关记录,包括学生的考试成绩,重修率、出勤率等。通过数据分析,公司帮助学生了解成绩不佳的主要原因,并及时调整学习方式和选修课程,对有退学风险的学生提出预警。
加拿大的教育科技公司Desire to Learn的业务是根据学生的历史成绩数据、社会行为及家庭状况等,分析和预测学生未来的课程成绩[4]。这家公司分析过加拿大乃至全球上千万学生,利用公司提供的管理系统,也是在线学习平台,与学生在线交流、测试,监控学生阅读书籍等。通过持续不断的分析,系统不仅为学生也为教师提供了大量信息,辅助教师及时发现学生成绩不佳的影响因素,并做出相应的调整和改进。
1.2.2 国内研究现状
近年来,各高校普遍建立了教务管理信息系统,其中许多都按照自身的需要建立了成绩分析系统。目前,国内的教务管理系统一般采用功能模块设计,以武汉理工大学为例,教务管理系统由学分制选课系统、课表查询、成绩查询和评教等功能模块组成。在系统的实现上,一般采用关系数据库模型,数据库中主要包括学生的姓名、学号、专业、考试成绩等信息。
目前国内高校的成绩分析系统,仍停留在原始的数据库管理和查询阶段。最常见的方法就是计算数据库内各个字段的合计值、平均值、极值等,统计优秀率、及格率,以直方图、饼图的形式显示。至于对成绩的进一步分析,如基础课程和专业课程成绩的相关分析、影响学科考试成绩的因素分析等,基本是用手工计算的方法进行研究。
随着数据库技术的发展和国内教育信息化的普及,高校普遍堆集了大量的教务数据。然而,数据库中隐含的丰富知识和宝贵信息尚未获得充分探索及利用。海量数据的生成、堆积与滞后的数据分析方法、工具之间的矛盾,是当前高校学生成绩管理的主要矛盾。针对这一现状,需要有新的技术来自动、智能和快速地分析海量的学业数据,由此引发了一个新的研究方向:数据挖掘(Data Mining)技术研究。
1.3 研究思路与研究方法
1.3.1 研究思路
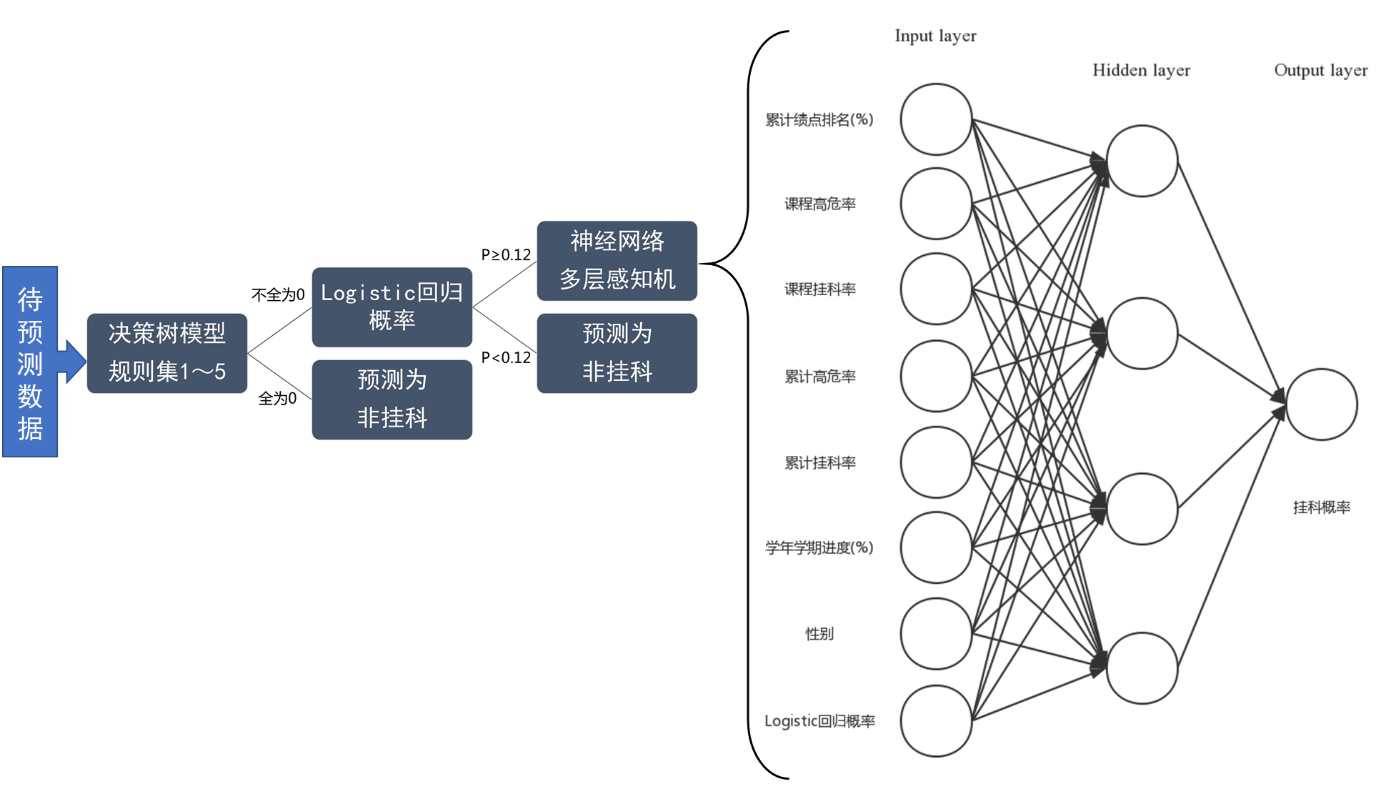
参照国外先进的解决方案,结合国内的现有实际情况,以武汉理工大学学生基本信息和课程成绩数据为样本,运用数据挖掘及相关专业技术,分析影响本科学生学业失败风险的关键因素。首先运用统计分析、多维分析方法观察学生成绩数据,进行了数据清洗、数据衍生变量生成、数据汇总合并等数据预处理,然后运用决策树算法、Logistic回归分析和神经网络算法建立了学生挂科预测模型。接下来在学生挂科预测模型的基础上,设计与开发了高校学生学业预警系统。从学生、教师、辅导员三个角度,进行学业挂科风险管理;系统提供预测挂科信息,方便不同用户采取更有效的干预措施。具体包括以下几个步骤。
(1)数据准备
从学校教务处获取全校部分专业学生的基本信息及其本科阶段各课程的历史成绩记录作为研究样本。用Microsoft Excel导入上述数据,结合统计学方法对各项数据进行初步预处理,包括数据类型转换、数据筛选、变量定义和计算、数据表拼接等。
(2)模型建立
对于数据挖掘工具的选择,本研究采用IBM的SPSS Modeler软件。2009年IBM公司收购了SPSS数据分析软件公司,将其广受赞誉的SPSS统计分析软件和Clementine数据挖掘软件进行整合,并更名为SPSS Modeler(简称Modeler)后再次推向全球市场。Modeler集成了诸多机器学习的优秀算法和一些行之有效的统计分析方法,并继续保持了SPSS产品的一贯风格——界面友好且操作简捷,因而是探索数据挖掘问题的理想工具[5]。
数据挖掘的算法多种多样,基于学业预警的研究目的,把学业风险程度作为待预测的变量,宜选择分类算法进行建模。所谓分类预测,是指基于数据集中的其他属性预测一个或多个离散变量,其中典型的分类算法有决策树、Logistic回归和人工神经网络。
(3)方案评估与实施
从精度和查全率两个方面,对各模型的质量进行评估,综合运用效果较好的模型作为学业预警系统的核心算法。通过模型,分析所研究的各变量对于学生学业风险程度的影响。在此基础上,使用Web前端技术开发实现高校学生学业预警系统,即实现数据导入和学业风险预测的自动化,并对学业预警的结果进行可视化呈现。
形成技术路线如图1.1所示。
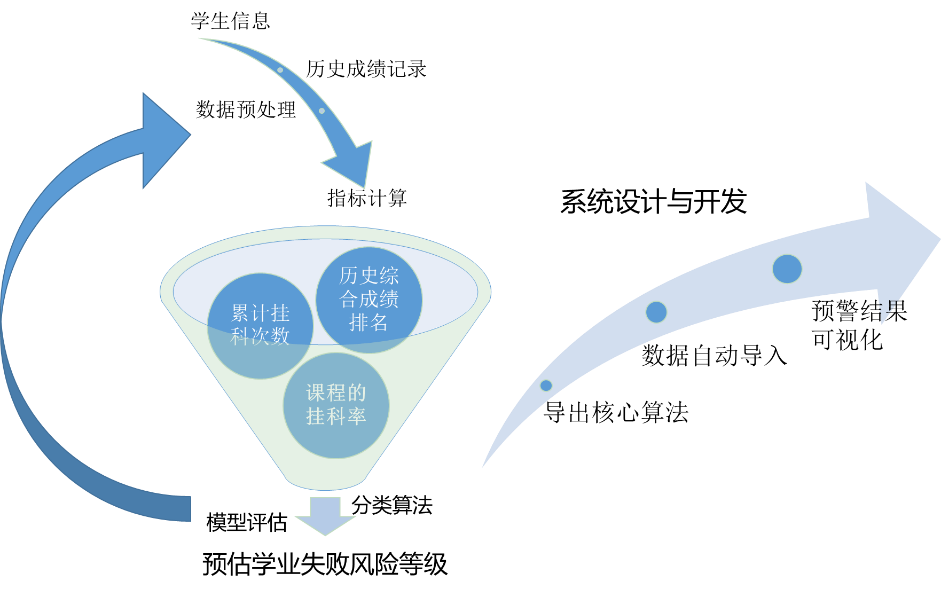
图1.1 技术路线图
1.3.2 研究方法
本文在研究的过程中主要采取了统计分析、决策树方法、Logistic回归方法、神经网络与生命周期法等研究方法。
(1)统计分析:在现存的学业数据的基础上,运用统计学中的因素分析法分析影响学业失败风险的主要因素,并据此设计一系列衍生指标;运用分组分析、比较分析法对总体按专业班级、学年学期、课程类别、挂科风险等级等进行划分,对各指标数值进行多维度的比较,以揭示数据的隐含规律。
(2)决策树:使用决策树方法生成可读性强的规则集,直观的展现出学生和课程的属性特征与是否挂科之间的联系逻辑。
(3)Logistic回归方法:以数学函数的形式建立模型,量化各输入变量对挂科概率的影响方向和程度。
(4)神经网络:通过机器学习算法对数据集多维属性空间的搜索,生成更复杂的函数发现数据与学业风险程度之间的深层次规律,进一步优化提高模型的精度。
(5)生命周期法:运用生命周期法进行学业预警系统开发,包括系统分析、系统设计、系统实施等环节。
2 数据理解与准备
2.1 样本选择与变量定义
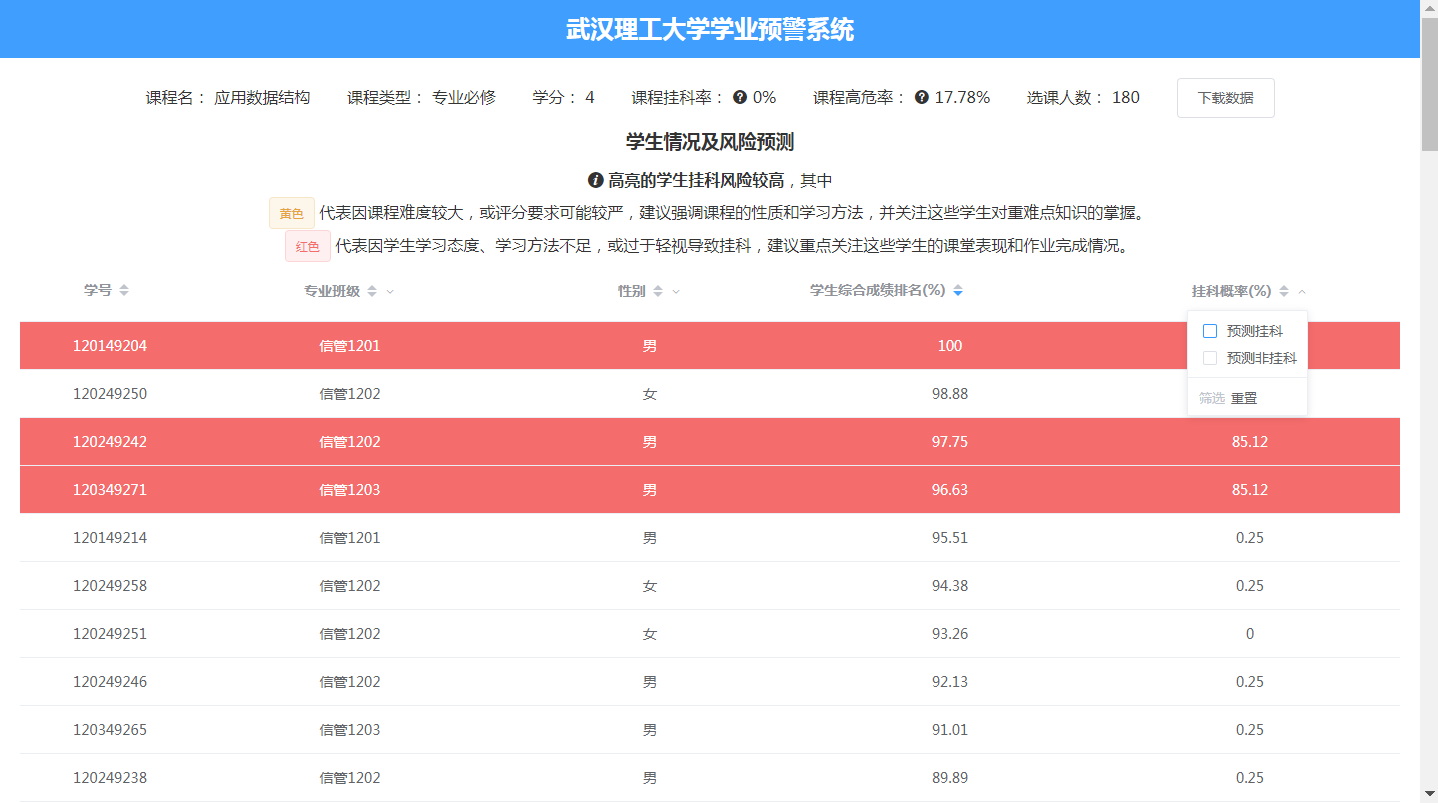
在班级日常的学习中,不难发现:挂科门数比较多的学生通常在学习态度、学习方法或学习能力等方面存在一定问题,同时这也会严重影响其综合成绩和排名,那么他在今后的学习中再次出现挂科的风险比其他同学更大一些。
但即便如此,某些课程历史上几乎没有过挂科的情况(例如军事理论、体育课这样的课程),预测该学生也不会在这样的课程上挂科;但若某门课程的挂科率较高,或考试卷面成绩不及格的同学较多,在一定程度上反映了该课程的难度较大,就可以认为他在该课程上的学业风险较高。
为此,从学校教务处获取11级、12级已毕业的信管、生物技术专业全体学生的基本信息、大学本科四年的各科成绩数据作为研究样本,包含每个学生的学号、性别、生源地,及其四年内所修读课程的名称、时间、平时成绩、期末考试成绩、总评成绩等。在上述成绩数据的基础上,设计一系列衍生指标,衡量影响学业失败风险的各因素,具体变量如表2.1所示:
表2.1 变量定义
分类 | 变量名称 | 变量描述 |
连续型 | 平均学分绩点(GPA) | 参照武汉理工大学学生手册规定的算法计算,反映学生各门课程的综合成绩水平 |
连续型 | 累计学分绩点 | 在GPA的基础上,计算每学期的累计GPA(第一学期累计到当前学期之前的加总的GPA) |
连续型 | 累计GPA排名(%) | 累计学分绩点在全专业学生中的排名/专业学生数*100% |
二分型 | 是否挂科 | 若总评成绩lt;60,取值为1;否则取值为0 |
二分型 | 是否高危 | 若总评成绩≤60或期末考试成绩≤60或实验成绩(如有)≤60,取值为1;否则取值为0 |
连续型 | 课程的挂科率 | 每门课挂科的人数/考试人数 |
连续型 | 课程的高危率 | 每门课高危的人数/考试人数 |
连续型 | 学生累计挂科率 | 累计到当前学期之前,每个学生的挂科门数/已考试门数 |
连续型 | 学生累计高危率 | 累计到当前学期之前,每个学生的课程高危门数/已考试门数 |
2.2 数据预处理
用Microsoft Excel对上述各项数据进行初步预处理:
- 将所有文本类型的成绩记录转换为数字类型。
- 统计每门课程的选课人数,选课人数不足60人的课程多为不具代表性的通识选修和个性课程,将其排除在研究范围外。
- 规定同一学生的同一课程只保留其修读的第一学期最高成绩。学生挂科后,即便通过之后的重修课程考试,也视为发生过一次学业失败。
- 筛选出11级学生成绩数据,按课程分类汇总后,计算每门课程的挂科率、高危率。
- 数据表转换:获取的原始成绩表(部分如表2.2所示),以每个人的每门考试作为一条记录;为方便计算每个人的GPA等综合指标,将其转换为以每位学生作为一条记录,以每门课成绩作为属性,如表2.3所示。
表2.2 教务处原始成绩表
学年学期 | 学号 | 课程代码 | 课程名称 | 课程性质 | 学分 | 平时成绩 | 期中成绩 | 期末成绩 | 实验成绩 | 总评成绩 |
2012-2013-2 | 1 | 1060001110 | 军事理论 | 通识必修 | 2 | 92 | 90 | 91 | ||
2011-2012-1 | 1 | 4020287060 | 纲要 | 通识必修 | 2 | 90 | 80 | 83 | ||
2011-2012-2 | 1 | 4050064110 | 高等数学A下 | 大类必修 | 5 | 95 | 53 | 66 | ||
2011-2012-1 | 1 | 4050091050 | 专业导论 | 通识必修 | 1 | 85 | 85 | 85 | ||
2011-2012-2 | 1 | 4050099110 | 基础生物学 | 专业必修 | 3 | 90 | 77 | 81 |
表2.3 学生学期成绩表
学号 | 大学计算机基础 | 大学英语A1 | 军事训练 | 体育1 | 中国近现代史纲要 | 专业导论 |
学分行 | 2 | 3 | 1.5 | 1 | 2 | 1 |
62 | 75 | 78 | 95 | 79 | 90 | 86 |
63 | 60 | 64 | 85 | 80 | 87 | 67 |
64 | 63 | 69 | 85 | 71 | 91 | 76 |
65 | 87 | 82 | 95 | 82 | 93 | 86 |
66 | 62 | 84 | 85 | 80 | 89 | 86 |
67 | 80 | 93 | 85 | 86 | 91 | 86 |
- 筛选出12级学生成绩数据,计算学生的累计挂科率、累计高危率、累计GPA排名等衍生变量。
- 数据表拼接:将学生信息表、学生原始成绩表、课程信息表、转换后的学生成绩表的相关列关联起来形成新的学生成绩表,并将成绩转化为两个取值为0或1的二分变量,分别表示是否挂科、是否高危,这有助于后期进行建模分析。
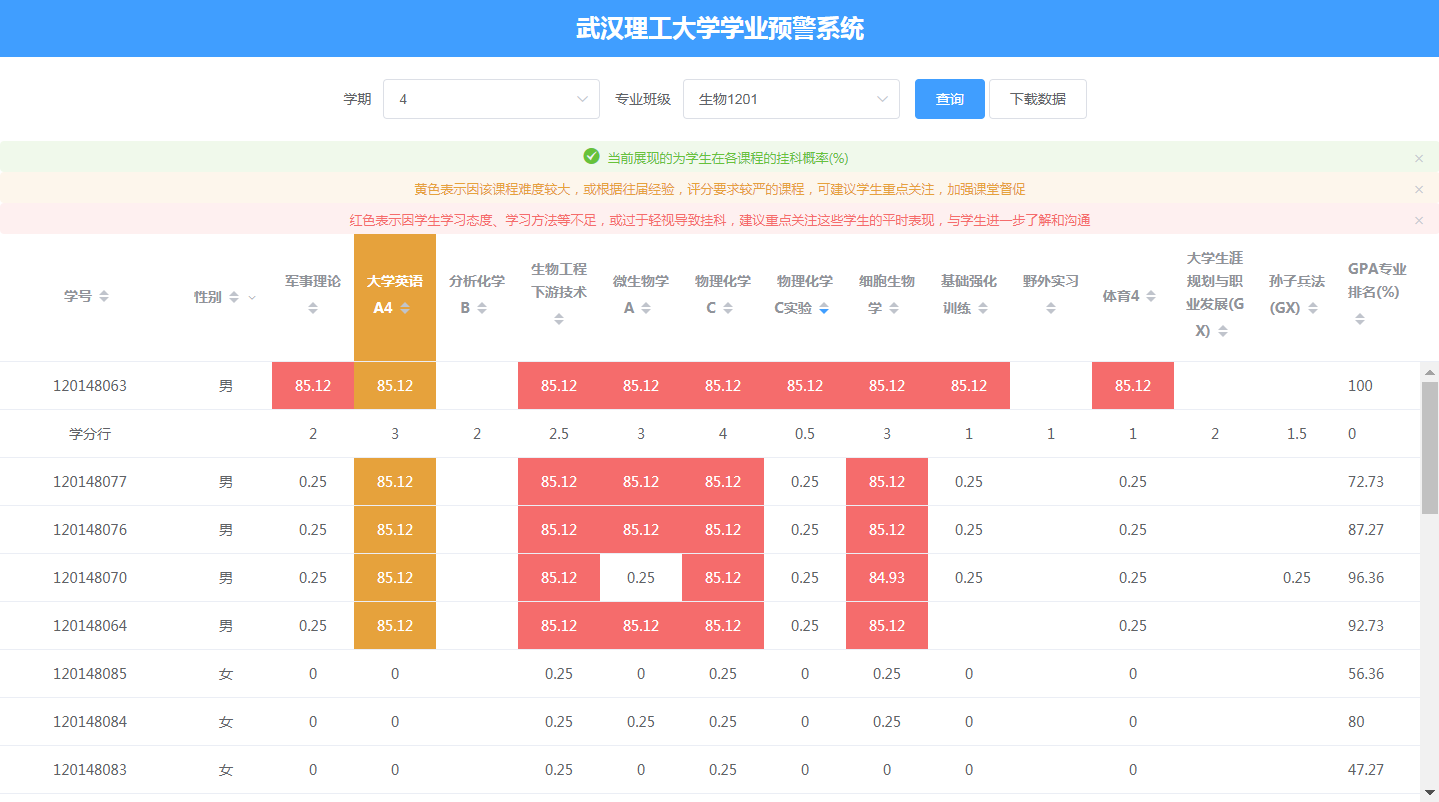
- 数据探索性分析:利用Excel的条件格式功能,根据学生每学期累计综合成绩排名百分位的高低,显示为不同的颜色,如表2.5所示。可以清楚地看到,在大二大三排名倒数的学生在这之前的成绩也较差;大一两个学期名列前茅的同学,后面的成绩基本不会差。这也印证了通过学生历史成绩预测其未来表现的可行性。
表2.4 拼接后的部分学生成绩表
学年学期 | 学号 | 课程名称 | 课程性质 | 学分 | 期末成绩 | 总评成绩 | 课程挂科率 | 课程高危率 | 累计绩点排名百分比 | 累计挂科率 | 累计高危率 | 性别 | 是否挂科 |
2 | 58 | 体育2 | 通识必修 | 1 | 90 | 88 | 0.000 | 0.014 | 0.036 | 0.000 | 0.000 | 女 | 0 |
2 | 58 | 中国近现代史纲要 | 通识必修 | 2 | 87 | 89 | 0.000 | 0.000 | 0.036 | 0.000 | 0.000 | 女 | 0 |
3 | 58 | 大学英语A3 | 通识必修 | 3 | 86 | 90 | 0.000 | 0.048 | 0.055 | 0.000 | 0.000 | 女 | 0 |
3 | 58 | 动物生理学 | 专业必修 | 3 | 91 | 93 | 0.000 | 0.000 | 0.055 | 0.000 | 0.000 | 女 | 0 |
3 | 58 | 高等数学A下 | 大类必修 | 5 | 91 | 92.8 | 0.090 | 0.486 | 0.055 | 0.000 | 0.000 | 女 | 0 |
3 | 58 | 生物化学A | 大类必修 | 4 | 85 | 87.1 | 0.000 | 0.158 | 0.055 | 0.000 | 0.000 | 女 | 0 |
4 | 58 | 军事理论 | 通识必修 | 2 | 90 | 90 | 0.000 | 0.007 | 0.055 | 0.000 | 0.000 | 女 | 0 |
表2.5学生综合成绩指标统计表
学号 | 排名百分比1 | 排名百分比2 | 排名百分比3 | 排名百分比4 | 排名百分比5 | 排名百分比6 |
99 | 16.36% | 38.18% | 32.73% | 32.73% | 34.55% | 30.91% |
100 | 76.36% | 81.82% | 81.82% | 74.55% | 76.36% | 76.36% |
101 | 81.82% | 69.09% | 60.00% | 41.82% | 38.18% | 40.00% |
102 | 72.73% | 54.55% | 61.82% | 60.00% | 60.00% | 61.82% |
103 | 85.45% | 94.55% | 98.18% | 100.00% | 100.00% | 100.00% |
104 | 54.55% | 76.36% | 78.18% | 72.73% | 72.73% | 74.55% |
105 | 1.82% | 1.82% | 1.82% | 3.64% | 1.82% | 1.82% |
106 | 67.27% | 78.18% | 67.27% | 58.18% | 65.45% | 65.45% |
107 | 43.64% | 21.82% | 21.82% | 25.45% | 21.82% | 18.18% |
108 | 18.18% | 45.45% | 34.55% | 21.82% | 23.64% | 23.64% |
109 | 25.45% | 58.18% | 58.18% | 69.09% | 69.09% | 67.27% |
110 | 14.55% | 14.55% | 12.73% | 16.36% | 18.18% | 20.00% |
111 | 78.18% | 36.36% | 38.18% | 50.91% | 50.91% | 52.73% |
112 | 89.09% | 96.36% | 83.64% | 85.45% | 89.09% | 89.09% |
204 | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
205 | 62.92% | 56.18% | 67.42% | 77.53% | 84.27% | 75.28% |
206 | 82.02% | 87.64% | 75.28% | 68.54% | 62.92% | 64.04% |
207 | 34.83% | 33.71% | 38.20% | 26.97% | 28.09% | 30.34% |
208 | 64.04% | 67.42% | 71.91% | 71.91% | 70.79% | 71.91% |
209 | 5.62% | 7.87% | 7.87% | 4.49% | 4.49% | 3.37% |
210 | 91.01% | 77.53% | 84.27% | 83.15% | 85.39% | 89.89% |
211 | 65.17% | 75.28% | 79.78% | 73.03% | 75.28% | 77.53% |
212 | 21.35% | 34.83% | 40.45% | 31.46% | 29.21% | 26.97% |
213 | 67.42% | 73.03% | 78.65% | 78.65% | 77.53% | 79.78% |
214 | 97.75% | 96.63% | 95.51% | 94.38% | 95.51% | 94.38% |
215 | 88.76% | 89.89% | 88.76% | 86.52% | 87.64% | 87.64% |
216 | 47.19% | 68.54% | 62.92% | 59.55% | 53.93% | 52.81% |
217 | 38.20% | 38.20% | 35.96% | 25.84% | 25.84% | 24.72% |
218 | 7.87% | 6.74% | 5.62% | 5.62% | 5.62% | 5.62% |
219 | 78.65% | 71.91% | 58.43% | 51.69% | 50.56% | 50.56% |
3 模型建立与评估
3.1 研究模型建立
分类是一种重要的数据分析形式,它提取刻画重要的数据类的模型。这种模型称为分类器[6],预测分类的类标号。分类可用于预测,并从历史数据记录中自动得出给定数据的广义描述,以便预测未来的数据归类。
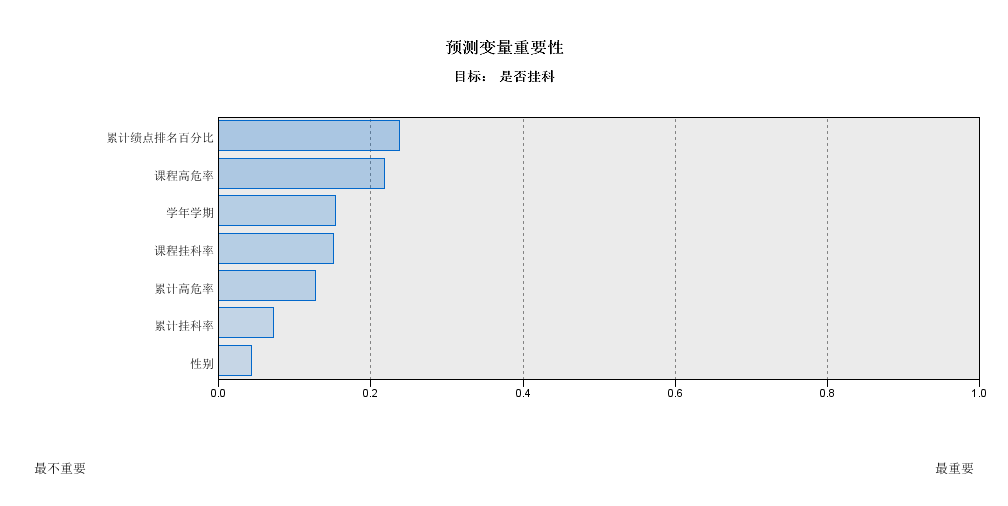
分类具有广泛的应用,本研究将前期计算得出的课程的高危率、学生累计挂科率等指标作为输入变量,使用SPSS Modeler软件对学业风险等级(是否挂科)这一分类变量进行预测,具体用到了以下三种分类算法。
3.1.1 C5.0决策树算法
决策树算法是一种非常典型的分类算法。使用决策树算法时,必须首先处理数据,训练生成可读性强的规则集或决策树,随后在该结果的基础上,分析和判断其他数据。决策树算法实质上是通过一系列规则,对数据的类别逐步进行划分的过程。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: