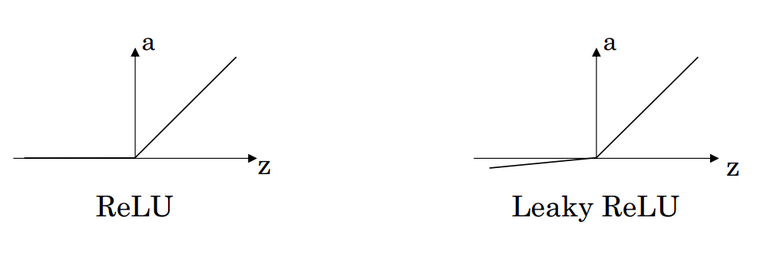基于CNN的单幅图片超分辨率重建研究毕业论文
2020-02-17 22:00:30
摘 要
单幅图像超分辨率还原是指由一幅低分辨率图像通过某种方法重新构造出高分辨率图像,牺牲了时间带宽以换取空间分辨率。本文首先介绍了传分辨率还原的历史和研究意义,并介绍了传统的超分辨率图像算法,基于插值的,基于重构的和基于学习的,并比较了各种方法的优缺点,之后着重研究了基于稀疏编码的超分辨率还原。
本文在探究稀疏编码算法的基础上,应用了一种与之对应的三层卷积神经网络结构SRCNN,实现了端到端的高低分辨率映射。SRCNN在基于深度学习的基础上,通过反向传播算法不断更新卷积核的权值参数,优化了整个系统。在深入研究机器学习与深度学习的原理和基于卷积神经网络的重构基础上,利用caffe框架进行训练,并用MATLAB实现基于CNN的超分辨率重建的编程,对该算法的设计步骤进行详细说明,并使用该算法对单幅图像进行重建,通过与其他图片重建算法进行比较,阐明利用CNN进行图片超分辨率重建时,能大大提高准确率与速度。
关键词: 卷积神经网络;超分辨还原;matlab
Abstract
Single-image super-resolution restoration refers to the reconstruction of a high-resolution image by a low-resolution image in some way, at the expense of time bandwidth in exchange for spatial resolution. This paper first introduces the history and research significance of resolution reduction, and introduces the traditional super-resolution image algorithm, based on interpolation, reconstruction-based and learning-based, and compares the advantages and disadvantages of various methods, then focus on Super-resolution restoration based on sparse coding is studied.
Based on the exploration of sparse coding algorithm, this paper applys a corresponding three-layer convolutional neural network structure SRCNN, which realizes end-to-end high-low resolution mapping. Based on the deep learning, SRCNN continuously updates the weight parameters of the convolution kernel through the back propagation algorithm, and optimizes the whole system. Based on the in-depth study of the principles of machine learning and deep learning and the reconstruction based on convolutional neural networks, the caffe framework is used for training, and the programming of CNN-based super-resolution reconstruction is implemented by MATLAB. The design steps of the algorithm are described in detail. And use this algorithm to reconstruct a single image, compare it with other image reconstruction algorithms, and clarify that when using CNN for image super-resolution reconstruction, the accuracy and speed can be greatly improved.
Key words: Convolutional Neural Networks; Super Resolution; matlab
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 课题研究背景 1
1.2 国内外研究现状 1
1.3 研究意义 3
第2章 SRCNN原理 5
2.1 卷积神经网络 5
2.1.1 卷积层计算 5
2.1.2 权值共享 6
2.2 激励函数 7
2.3 损失函数 8
2.4 前向传播和反向传播 9
第3章 SRCNN系统设计与实现 11
3.1 SRCNN的设计思想 11
3.1.1 卷积神经网络的设计 11
3.1.2 损失函数的选择 12
3.1.3 卷积核大小和层数的选择 13
3.2 SRCNN实现 13
3.2.1 利用Caffe框架训练 13
3.2.2 特征图的提取 14
3.2.3 利用Matlab编程 16
3.2.4 与其他方法相比 18
第4章 总结与展望 20
参考文献 22
致 谢 24
第1章 绪论
1.1 课题研究背景
超分辨率重建技术简单地说,就是把低分辨率图像进过一定处理后还原出高分辨率图像,上世纪七十年代就开始被应用在航天领域,用来重建卫星拍摄的低分辨率图像。经过几十年的发展,超分辨率还原技术出现了从插值到重构,再从重构到学习的两次变革,本文在传统超分辨率还原算法基础上,重点研究了基于深度学习(主要是基于卷积神经网络)的超分辨率还原。
近年来,人工智能应用的潮流逐渐在各个领域崭露头角,而人工智能的兴起与深度学习的快速发展密不可分,其中最主要的几个原因是:
一:大数据与物联网时代的来临为深度学习提供了海量数据基础,大量的移动设备,物联网设备为训练提供了大量的数据;
二:高速发展的硬件设备满足了巨大的计算量,高速地硬件发展和计算速度的提升大大缩短深度学习的周期,海量数据带来的海量计算在十几年前往往需要几周甚至几个月去训练一个神经网络,而GPU加速可以提高20-30倍的计算速率,大大提高了效率,使得深度学习得以快速地发展;
三:算法的优化,如ReLU函数的提出使得算法运行的更快。算法创新所带来的影响,实际上是对计算带来的优化,通过改变算法,使得代码运行的更快,这也使得我们能够训练规模更大的神经网络,或者是多端口的网络。
1.2 国内外研究现状
单幅图像的超分辨率重建是图像处理中的一个常见课题,旨在从低分辨的影像中恢复高分辨的图像[1][2]。对于一张低分辨率图像,可能对应着许多不同的高分辨率图像,例如,近视者看到的模糊场景就是低分辨率图像,由于模糊图像缺乏足够的信息,所以近视者无法判断场景的真实情况,假设近视者看到一个模糊的人影,他既可能把他认作A,也可能把他认作B,即一张低分辨率图像可能对应着很多不同的高分辨率图像的解。换句话说,这是一个有多种解决途径的逆向问题[3][4][5]。
图像超分辨率还原主要有基于插值的,基于重构的和基于学习的超分辨率还原,而基于学习的又可以分为基于机器学习的和基于深度学习的超分辨率还原。下面详细介绍每一种方法:
(1)基于插值的超分辨率重建
插值法,顾名思义就是通过公式,计算出某个像素点周围的几个像素点的值,并插值到这个像素点周围[6]。这种算法的优点是十分方便与快速,只需要低分辨率图像与插值计算公式便可以完成。但这种算法的缺点也很明显,那就是插值出的像素点依赖附近的像素点计算出,计算值与周围的像素点会很接近,使得复原的图像不够锐利,边缘平滑,从视觉上看比较模糊。
常用的插值算法有:邻近插值法,双线性插值法,双三次插值法等。本文在后面用到了双三次插值法(Bicubic interpolation)用作图像还原的对比。双三次插值是二维空间中比较常用的插值方法。在这种方法中,被插值的点可以通过附近的十六个像素点的加权平均得出,加权系数通过两个三次多项式得到,在两个方向上使用。基于插值的算法在对图像质量要求不高时有着广泛的应用。
(2)基于重构的超分辨率重建
基于重建的方法通常都是基于多帧图像的,需要结合先验知识[11][12][13][15]。有如下方法:
1.凸集投影法(POCS)
2.贝叶斯分析方法
3.迭代反投影法(IBP)
4.最大后验概率方法
5.正规化法
超分辨率重构的基本过程为:先进行图像退化分析,然后进行图像的配准,最后根据配准的信息对图像进行重构。但这些方法不是本文研究的重点,故本文不做深入讨论。
(3)基于机器学习的超分辨率重建[16][17][18][19][20]
稀疏编码是一种机器学习的算法[21][22],在利用深度学习进行超分辨率还原之前,基于稀疏编码的方法是最有效和效果最好的:
1. 从低分辨率图片中切割出不同的图像块,并进行归一化处理,这种切割是块与块之间是重叠的;
2. 使用低维词典(Low-resolution dictionary)编码,得到一个稀疏参数;
3. 使用高维词典(High-resolution dictionary)结合稀疏参数进行重建;
4. 将不同图像块加权之后进行重新组合。
(4)基于深度学习的超分辨率重建
基于深度学习的超分辨率重建,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)[23]。
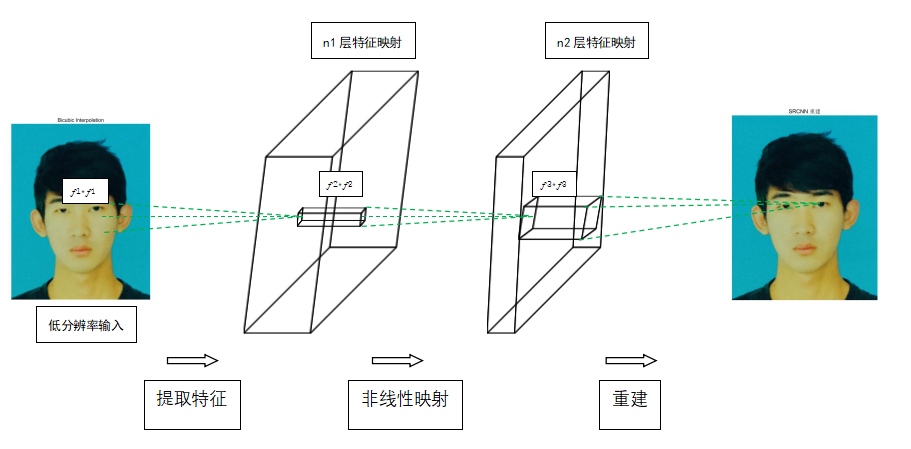
2014年Dong等人提出的SRCNN将SISR带入了深度学习的领域 ,该网络将卷积神经网络对应于稀疏编码的结构,用三个卷积层代替稀疏编码的三个步骤,提出了一种端到端的图像超分辨率方法。对于一个低分辨率图像 X,先用一个卷积层提取其特征图,再用一个卷积层进行非线性映射,最后用一个卷积层恢复出高分辨率图像。这种端到端的模型不仅便于优化,而且运算速度更快。基于深度学习的图像超分辨率还原是现阶段研究的趋势,也是效果最好的方法。
1.3 研究意义
图像超分辨率重建技术是利用DSP、机器学习以及深度学习方面的知识,通过不同的算法,将原低分辨率图像复原成高分辨率图像的过程。旨在解决由于自然环境影响,硬件设备较差和传输失真等原因造成的图片模糊,质量低下等问题。
图像超分辨率重建的研究在以下几个领域有着重大意义[21],主要包括:
(1)卫星遥感领域
众所周知,第一个SR思想为了提高遥感图像分辨率的需求所驱动的。由于卫星飞行轨道距离地球表面几百千米,导致采集到的地面图像信号像素极低,在地球上的实际距离,这对于识别与信息处理带来了极大的不便,将卫星图像超分辨率重建,可以是识别的精度提高一个数量级,对于原来只能看清千米百米级别的低分辨率图像现在我们可以看清到十米级别,这将大大提升后续的处理精度。
(2)医疗诊断领域
低分辨率的医疗图像可能导致医生对病情判断失误,误判漏判等情况,可以在原有的低分辨率图像基础上重建高分辨率图像,对B超,CT等医疗图像进行超分辨率重建,实现对胎儿图像,大脑内部图像的高分辨率还原,在原医疗设备没有更新升级的情况下获得了更好的医疗图像,既节省了成本,又提升了诊断效率。
(3)监控与刑侦领域
监控摄像头在交通领域,安全领域有着广泛的应用并发挥着巨大作用。监控摄像头由于体积和数据传输速度受限等原因,往往只能拍摄低分辨率的视频,拍摄出来的画面物体和人脸模糊,难以辨认。利用超分辨率还原监控画面,可以将低分辨率监控截图重建,还原高分辨率的图片,使得文字,人脸,环境的要素可以得到更好的辨认。
(4)生物识别
超分辨率还原在生物识别中也很重要,包括面部,指纹和虹膜图像的分辨率增强。生物特征图像的分辨率在识别和检测过程中至关重要。基于生物特征图像结构化特征的冗余性和相似性,基于实例的单帧SR与外部数据库是分辨率增强的有效方法。利用SR,可以明显增强形状和结构纹理的细节,有效保留全局结构,提高相关应用的识别能力。

图1.1 超分辨率还原的应用
第2章 SRCNN原理
2.1 卷积神经网络
神经网络结构示意图如图2.1所示,卷积神经网络是在神经网络的基础上,引用了卷积层计算发展而来。在图像处理领域,卷积神经网络是被广泛使用的一种高效而且快速的方法,可以把它当做一个黑盒子使用,无需关心中间的过程而只考虑输入和输出地去使用它。卷积神经网络延续了神经网络的层级网络,只是引入卷积计算,可以说是传统神经网络的针对图像处理方面的一个改进。传统算法往往需要人们手动设定特征提取参数,低效且不易寻找规律。
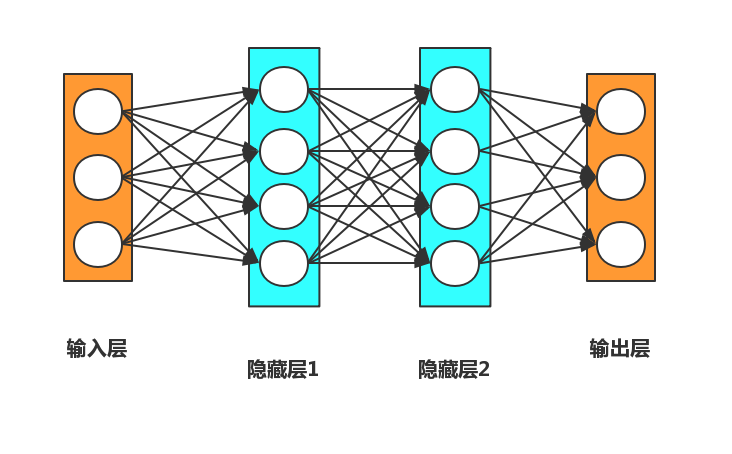 图2.1 传统神经网络结构示意图
图2.1 传统神经网络结构示意图
深度学习作为机器学习的重要发展,通过BP算法能够自动更新权值参数,即自动学习特征,高效而且迅速,所以在图像识别,语音处理,人工智能等众多领域逐渐崭露头角。卷积神经网络继承了神经网络自动学习特征的特点,并且通过权值共享大大缩减了所需参数的设定,大大提高了计算速度与资源利用率,尤其适合进行图像的重建,分类,识别。
2.1.1 卷积层计算
卷积神经网络中最重要最核心的一个层次,就是卷积计算层,卷积神经网络的名字也由此而来。在卷积层,有两个关键操作:
1:局部关联,每个神经元看做一个滤波器。
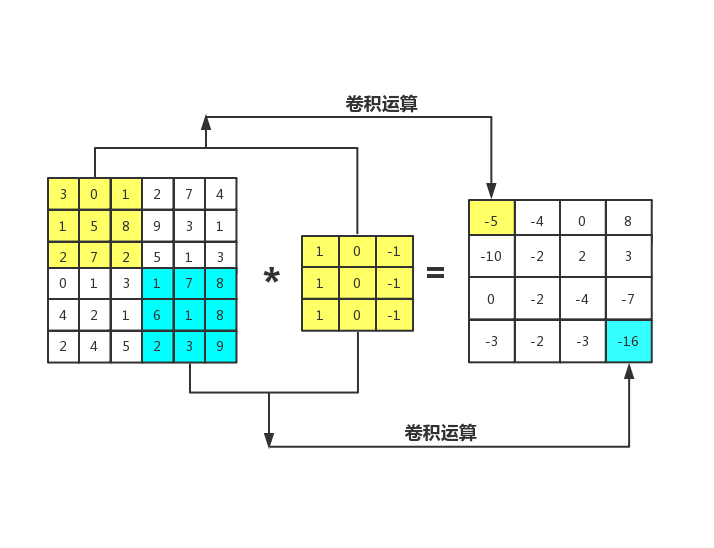 2:窗口滑动,滑动卷积核对原图像依次进行计算。
2:窗口滑动,滑动卷积核对原图像依次进行计算。
图2.2 卷积操作示意图
图2.2是一个6×6的灰度图像。灰度图像与RGB图像不同,不是6×6×3的矩阵,而是6×6×1的。通过构造一个3×3滤波器,去检测图像中的垂直边缘。
假设构造一个3×3的过滤器如上图所示,对这个6×6的图像进行卷积运算,卷积运算用“ * ”来表示,用3×3的滤波器对其进行卷积,最终得到一个4×4的矩阵。
2.1.2 权值共享
假设需要处理一个像素很多的图片,比如一张2048×2048个像素图片,它足有4兆多那么大,但是特征向量的维度达到了2048×2048×3, 因为普通图片都是RGB三通道的,所以要处理的数据将会是1200万。假设输入1200万的数据,这代表着,特征向量x的维度会高达1200万。假设在第一层卷积层中,有500个神经元,再把所有的权值组成矩阵 w1,如果使用了标准的全连接网络,这个矩阵的大小将会是500×1200万=60亿。这意味着矩阵w1会有60亿个参数,对于计算机来说,这也是一个很大的数字。在有如此多参数的情况下,难以保证获得足够多的数据来预防神经网络发生竞争需求和过拟合,处理60亿个参数的神经网络所需要的内存资源往往是难以接受的。
但对于图象处理来说,研究者不希望只能处理小图。所以,需要卷积核帮我们进行计算,它是卷积神经网络中最重要的一个环节。由于不同的卷积核和图像进行卷积可以得到不同的特征图,所以不需要单独得为每个神经元设定一组参数,而是通过一个相同的卷积核实现参数共享。权值共享本质就是对图像用同样的卷积核进行卷积操作,卷积操作也保证了神经元能检测到图片所有位置的特征。通过平移可以检测到不同位置的相同特征,这也是为什么卷积神经网络有较好的平移不变性。
2.2 激励函数
通俗的讲,激励函数在神经网络中的作用就是提升映射的非线性性。神经网络在添加激励函数之前仅仅只是在做线性变换,无论这个神经网络有多少层,仍是线性变换,这使得神经网络的拟合能力大大受限。在激励函数为神经网络引入非线性因素后,理论上只要神经网络层数够深,就可以表示任何的映射关系。
激励函数通常加在神经元节点的计算过程之后,神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,在进行计算与激活后将输出值传递给下一层。
在早期,人们在神经网络中常用的激励函数是Sigmoid函数,它的公式是
(2.1)
当输入趋向无限大时,输出趋向1,当输入趋向负无穷时,输出趋向0,输出结果只能在(0,1)的范围内。这个函数常用在二分类问题之中,但使用Sigmoid函数容易出现梯度弥散或者梯度饱和。当构造一个深层神经网络时,反向传播更新参数需要乘以激励函数的倒数,当没一层激励函数都是Sigmoid函数,参数就会不断减小直至接近于0,此时称这种情况为梯度消失。如果输入的是比较大或者比较小的数,会产生饱和效应,导致神经元类似于死亡状态。图2.3给出了Sigmoid函数的图像与公式。
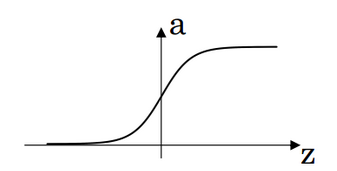
图2.3 Sigmoid函数
现在,人们常用来替代Sigmoid函数的激励函数是ReLU(Rectified Linear Unit)函数,又称修正线性单元,ReLU函数很好地解决了梯度消失的问题,参数可以很好地更新而不考虑梯度问题。相对于Sigmoid激励函数,对ReLU求梯度非
常简单,因为它不是1就是0,可以非常大程度地提升随机梯度下降的收敛速度。。ReLU函数的公式如下:
(2.2)
然而,当输入为负值的时候,由于此时输入小于零而梯度为零,从而导致其参数无法得到更新,ReLU 的学习速度由此变得很慢,甚至可能使神经元直接死亡,此后无法再激活它。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: