融合多层次注意力机制的图像理解技术研究毕业论文
2020-02-17 22:00:20
摘 要
随着信息领域的发展,如何快速准确地提炼出图像中包含的大量信息引起了人们的关注。本设计基于这一问题,通过Python软件建模,对基于多层注意力机制的图像理解问题进行了研究。
设计的目标在于对任意输入图像生成描述语句。模型构建的主要思路是采用卷积神经网络(选择VGG_16)提取出图像中包含位置信息的特征向量,之后用循环神经网络(选择LSTM,长短期记忆网络)生成具有描述性的语句。LSTM网络中每个单元的输入包含图像描述语句,隐含状态以及上下文向量。其特色在于,每一步LSTM中输入的上下文向量都是利用网络上一步储存信息和隐向量对图像特征向量进行计算加权来获得,即在LSTM网络中融合了多层确定性的注意力机制。之后利用Adam算法进行模型优化训练。训练评估数据集采用MS COCO。获得的模型通过BLEU、CIDEr、METEOR、ROUGE-L四种指标进行评估,一方面判断训练模型的质量,另一方面与几种已有的具有代表性的模型进行评估数据比对。最终最优模型评估结果为BLEU-4:0.288;CIDEr: 0.824;METEOR:0.232;ROUGE-L:0.514,得分较好,在之后输入图片实例进行测试时也获得了较为准确的描述。
关键词:图像描述;注意力机制;卷积神经网络;循环神经网络;Python
Abstract
With the development of the information field, how to quickly and accurately extract a large amount of information contained in the image has attracted people's attention. Based on this problem, this design studies the image understanding problem based on multi-layered attention mechanism through Python software modeling.
The goal of the design is to generate a description statement for any input image. The main idea of model construction is to use the convolutional neural network (VGG_16) to extract the feature vector containing the position information in the image, and then use the cyclic neural network (LSTM) to generate the input of each unit in the descriptive statement. LSTM network contains image description statements, implied states, and context vectors. The feature is that the context vector input in each step of the LSTM is obtained by calculating the weight of the image feature vector by using the previous information stored in the network and the hidden vector, that is, a multi-layered deterministic attention mechanism is integrated in the LSTM network. Then use the Adam algorithm to carry out model optimization training. The training assessment data set uses MS COCO. The obtained model is evaluated by four indicators: BLEU, CIDEr, METEOR, ROUGE-L. On the one hand, the quality of the training model is judged. On the other hand, several existing representative models are used to compare the evaluation data to the final optimal model. The evaluation results were BLEU-4: 0.288; CIDEr: 0.824; METEOR: 0.232; ROUGE-L: 0.514, the score is good, and accurate descriptions were obtained after inputting other image examples.
Key Words:image description; attention mechanism; CNN; RNN; Python
目 录
第1章 绪论 1
1.1 研究的目的与意义 1
1.2 国内外研究现状 2
1.3 论文内容安排 3
第2章 设计的相关原理 4
2.1 系统设计框架 4
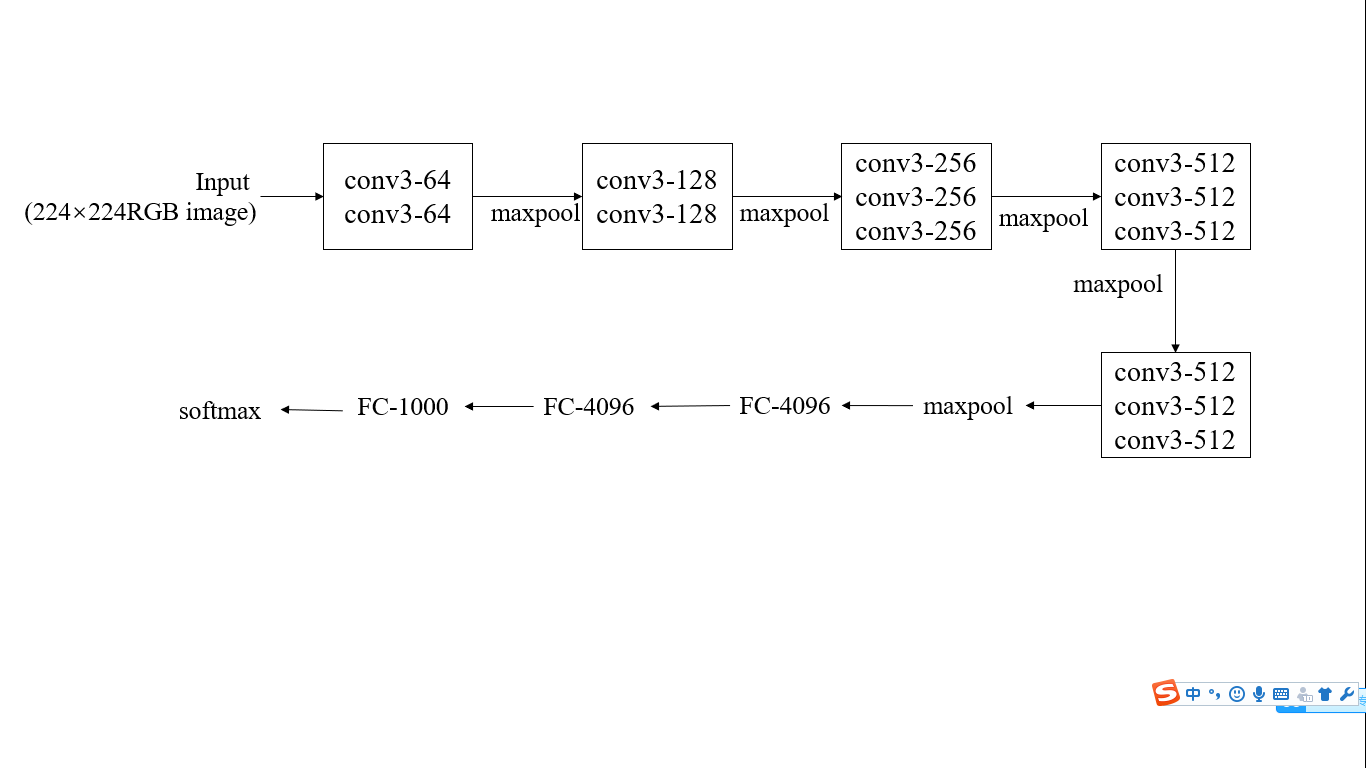
2.2 编码器:卷积神经网络 5
2.3 注意力机制(Attention Machine) 6
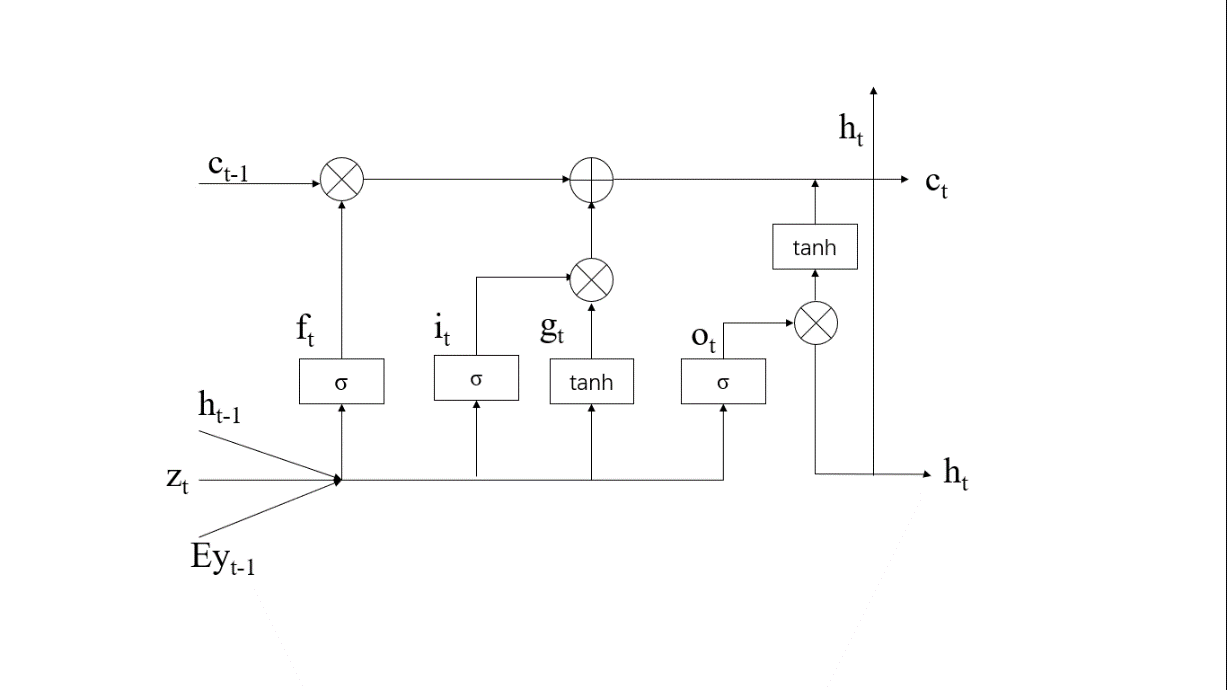
2.4 解码器:长短期记忆网络(LSTM) 8
第3章 系统的设计与实现 11
3.1 数据库 11
3.2 模型建立 11
3.2.1 编码器结构(VGG_16) 11
3.2.2 解码器结构(LSTM) 12
3.3 训练、评估与测试过程 13
3.4 评估测试结果 14
3.4.1 评估指标 15
3.4.2 评估结果 16
3.4.3 图像标注实例 17
第4章 结论与展望 23
参考文献 24
附录A 26
致 谢 41
第1章 绪论
1.1 研究的目的与意义
随着现代信息技术的快速发展,图像中包含的信息也显现出了不断膨胀的趋势。由于图像中包含的信息较多,并且缺乏上下文的约束,人们并不容易筛选出其中所需要且重要的信息。相比较于图像信息,文字信息属于一种高级的视觉信息,人们可以通过文字信息快速获得图像中的主要内容。如何将图像信息快速准确地转变为文字信息给计算机领域提出了一个问题,由于这两者之间的信息量差距很大,因此必须要把如何抓住图片中的关键信息这一部分考虑在内。从认知科学的角度来看,人类在看向物体时倾向于选择性关注图像中最重要的关键信息,从而忽略图像本身的低解析背景,这不是将整个图像压缩成静态形式,而是注意允许突出的特征根据需要动态地出现在前面。虽然这种注意力机制可能会丢失一部分的信息,但是能够最高效率地利用人脑有限的分析资源,将大量视觉信息压缩成描述性的语言,因此是一种有效的解决方案。自动生成图像的描述是一个接近于场景理解核心的任务,这也是计算机视觉的主要目标之一。因此该任务要求字幕生成的模型足够强大,不仅要确定在图像中的对象,同时也要以自然语言表达其关系以及它们的属性以及所涉及的活动。除了视觉理解之外,还需要自然语言模型的帮助。
深度学习的实质是建立包含了很多层隐层的神经网络。在该网络中输入大量训练数据,模型可以通过这样的有效训练来学习其中较为有用的特征,从而增加最终结果的准确性[1]。深度学习强调了模型的深度以及特征的重要程度,同时利用大量的数据学习特征,这使神经网络能够学习到比人类学习的更加丰富的内在特征。如今通过卷积神经网络(CNN)与递归神经网络(RNN)[2]的结合,在视觉与语言信息之间的转换问题中已经获得了最新进展。这种方法没有明确性地表示出图像包含的高级信息,Qi Wu等人[3]研究了这种直接情况的可能性。受人类视觉感知系统所具有的注意力机制的启发,并获得机器学习、图像理解等方面的技术支持,该设计针对图像描述这一目标,实现了一种基于注意力机制的模型。这是一种包括了上下文特征以及静态局部特征的典型encoder-decoder网络结构。该模型能够自动地学习并描述图像中的主要内容,相较于传统的CNN与RNN模型,注意力机制可以决定图片中的哪一部分更加值得关注,从而对关键部分进行特征提取,获得图片中最有效的信息。该模型利用了Tensorflow框架,通过使用标准方向传播技术以确定性注意力机制进行训练,并在数据集MS COCO中定量验证了注意力机制的有用性,最终实现了对图像的文字描述,并且获得更高的准确性。
图像生成文本虽然具有一定的挑战性,但是该目标在如今生活中还是有着较为广泛的应用前景。一方面,在图像搜索过程中,可以使用丰富的图像搜索元数据,来增强搜索的效果,另一方面,该技术对于视觉障碍人群也有很大的帮助,如在导航中帮助盲人观测周围的物体,或者添加到手机拍照APP中帮助盲人判断人物状态是否合适,与此同时该技术也可以应用于幼儿教育中看图说话等方面。除此之外,图像描述也可以用于游戏领域,提高玩家的游戏体验感等。该设计将自然语言描述,视觉注意和图像理解相结合,无论是在计算机视觉领域还是心理学领域,都有一定的研究意义。
1.2 国内外研究现状
近年来,深度学习领域发展十分迅速,基于注意力机制的神经网络逐渐成为了研究的一个热点,无论是在图像理解,语音识别还是自然语言处理方面都有一定的应用。在机器翻译的进展中表明,使用循环神经网络(RNN)能够以更加简单的方式完成翻译,因此在图像描述中也考虑将图像的特征提取与循环神经网络相结合[4]。
在图像描述领域,一些研究者的工作结合了用于视觉和语言模型的子网络,在编码器-解码器的大框架上进行创新,使其能够应用于图像描述方面的工作。O. Vinyals等人[5],Karpathy A等人[6],Donahue J等人[7]在神经图像描述方面的具有开创性的工作,使用卷积神经网络将二维图像编码为静态视觉特征向量,然后将该向量输入到RNN中将其解码为相应的语言序列,即图像对应的描述。Mao等人[8]提出了一种多模态回归神经网络(m-RNN)的模型,他们首先将卷积神经网络与循环神经网络在多模式的情况下相互交互,将图像信息与文字信息之间进行有效的结合,并将其应用于相关检索任务,使性能有着显著性的提高。
然而在上述研究中,静态向量存在着缺点,它并不能够使图像的特征适应句子的上下文内容进行动态的变化。然而在机器翻译的领域,已经有研究者引入了注意力机制,如D. Bahdanau等人的论文[9],提高了机器翻译的质量。近年来随着深度神经网络的快速发展与不断成熟,以及机器翻译领域中得出的较好结果的启发,注意力机制也被逐渐应用于了计算机视觉领域。Xu K等人[10]提出了图像字幕中的第一个视觉模型,他们使用“硬”注意力机制可以选择最需要关注的图像区域,另一方面,“软”注意力机制可以很好地平衡空间中的特征。除去对图像空间信息的关注,Johnson J等人[11]从另一个角度出发,使用视觉系统来定位与描述了自然语言图像中存在的显著区域将图像本身特征以及文本同时映射,使用检索的方式寻找两种方法之间的相关性信息,从而对LSTM网络进行进一步地训练。Chen L等人[12]在现有的图像描述方法主要考虑了空间属性的情况下(注意力建模之后形成空间概率),充分地考虑卷积神经网络的spatial、channel-wise、以及multi-layer的属性。Chen L等人富有创造力地将三种属性结合后进行应用,并提出了channel-wise attention 和spatial attention两种注意力机制,一个更多关注语义相关区域,另一个会注意语义属性。这个算法的成功之处是在于合理假设人类视觉不会立即处理整个图像,只是在需要的时间与地点关注整个图像。这可以将注意力视为一种动态地特征提取方法。
由于大多权威的图像描述数据集都是英文描述,因此国内论文关于图像描述的内容较少。国内大多数利用了视觉注意力机制的相关,是进行图像检索或者是图像的显著区域提取。张威等[13],在2017年的论文中,提出了一个将图像动态语义知道与自适应注意力机制相结合的图像字幕生成模型,并且根据Johnson J等人[11]的工作,利用了图像的密集属性信息来对模型进行额外的监督,提高模型描述的准确性。
由最近几年国内外的论文可以发现,将注意力机制应用到图像理解方面是一个较新并且发展迅速、成果明显的技术,除此之外,它在实际生活中也有比较广泛的应用。由于如今拥有国外经典论文中的技术基础作为支撑,该问题的研究是比较有意义且可行的。
1.3 论文内容安排
该论文的内容主要分为四大部分。
在第一部分中,本文主要介绍了图像理解问题相关的背景,包括目前国内外的主要研究成果和创新以及该论文所研究题目的意义和应用前景。其中详细阐述了该模型中使用的注意力机制技术的发展。
第二部分详细介绍了模型所使用的基本encoder-decoder框架,详细内容分别为编码器侧使用的CNN,解码器侧使用的LSTM,以及在RNN中添加的多层注意力机制。该部分主要是详述了图像描述结构模型基本原理和算法部分,并给出主要的模型框架。
第三部分阐述了在Python中对模型进行的训练,评估以及测试。首先介绍了如何利用Python对模型进行实现,包括CNN网络的选择,LSTM参数设置,Tensorflow库相关内容,以及数据库的选择和其基本特征。之后叙述了在训练过程中采用的主要训练算法,评估中的正则化方式以及评估指标等相关内容。最后将模型评估所得的结果与之前几个较有代表性的模型结果进行对比分析,并且利用已有的模型,应用于自己的图像生成结果。
最后一部分对该设计内容从不同的方向进行总结,一方面回顾反思设计过程中出现的问题,另一方面提出具有实践意义的改进方向并对今后的应用前景进行展望。
第2章 设计的相关原理
该模型设计目的是将输入单个图像,输出的一段对该图像的描述性自然语句。使用卷积神经网络来提取图像中的视觉特征,使用LSTM将相应的特征解码为一个句子。在解码过程中通过融合多层次的确定性注意力机制来提高LSTM网络生成描述的质量。最后通过BLEU,METEOR,ROUGE-L和CIDEr这四种不同的评估方式来评估模型的准确性,并与几种不同的图像标注模型相对比。该模型主要利用Python中的Tensorflow库来进行构建,所使用的数据集为微软COCO数据集,最终可以实现给定任意图像来生成较为准确流畅自然语句的结果。
机器翻译以及图像描述领域研究的进展表明,给定一个强大的序列模型,通过“端到端”,在给出输入句子的情况下,可以最大化输出翻译或者描述的正确率。机器翻译的模型利用循环神经网络将可变长度的输入编码为固定的维度向量,并将其“解码”为期望的输出句子。在图像描述中使用了相似的设计思想,卷积神经网络的特性决定了它也能够将图像编码为固定的维度向量。相比较于机器翻译,图像描述在解码过程中增加了一个图像向量这一输入量,因此LSTM网络处理数据的任务更加艰巨。
2.1 系统设计框架
本系统主要使用标注问题常使用的编码器-解码器(Encoder-Decoder)结构,利用该模型生成的视觉注意模型,这些模型属于最近连接计算机视觉与自然语言的趋势。
该结构中,编码器的作用是将长度不确定的序列转换为后续操作需要使用的定长隐藏向量,在深度学习中,常常使用循环神经网络(RNN)或者卷积神经网络(CNN)来对输入信息进行定长编码。
本系统中在解码器端增加了注意力机制,因此在编码器输出张量后,模型要通过训练学习对于这些张量进行权重分配。需要分配权重的是图像所对应的注释向量,因此权重具有与注释向量相同的长度。该权重的分配与编码器中的隐藏定长向量以及解码器上一步所输出的内容有关,如此才能训练获得权重的最佳分配。得到相应的注意力权重之后,与编码器的注释向量通过注意力函数相结合就可以获得加权之后的编码器输出。之后获得的加权输出输入到解码器中,解码器通常是循环神经网络(RNN),较为常用的有门控循环单元(GPU)与长短期记忆网络(LSTM),解码器的输入除了有加权后的编码器输出,还有上一步生成信息。解码器不断重复这一过程直至获得序列所有的输出内容为止。系统的总体设计如图2.1所示:
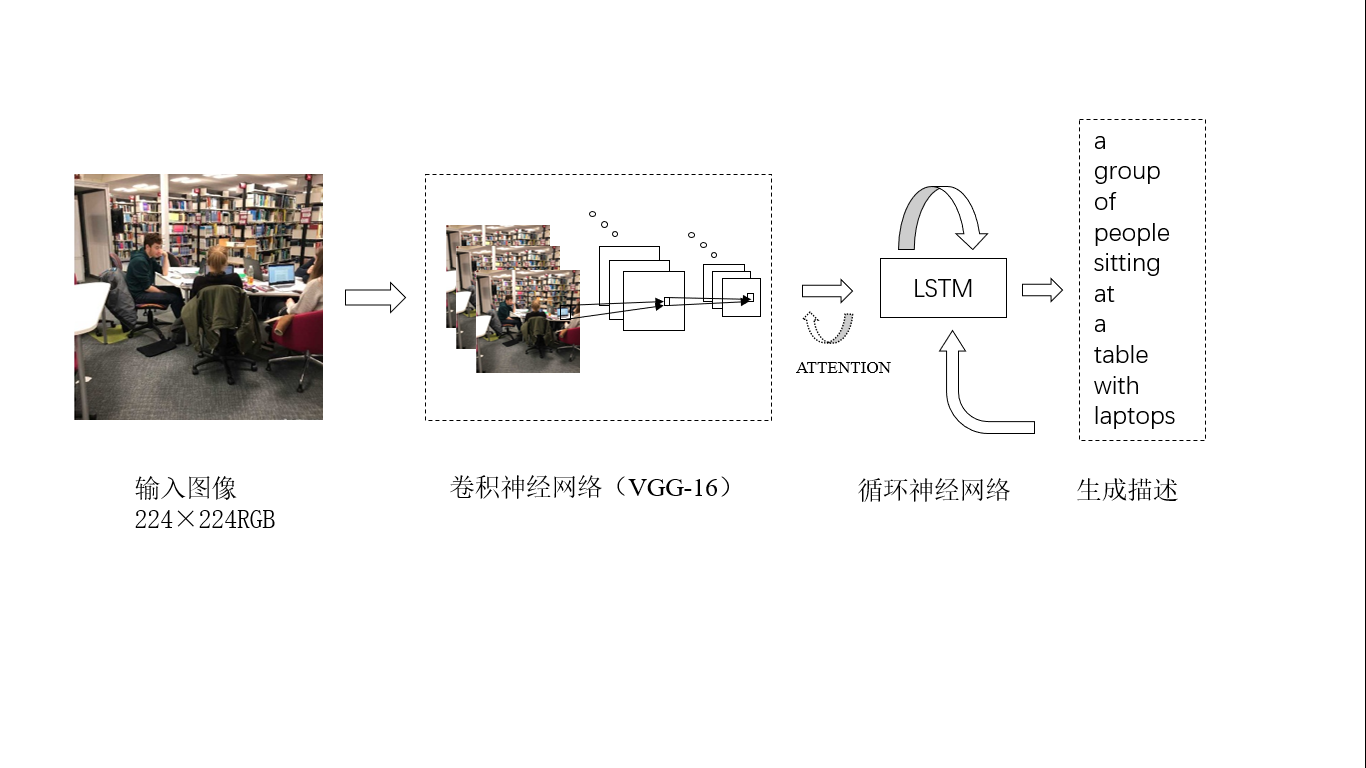
图2.1 系统总体设计图
2.2 编码器:卷积神经网络
卷积神经网络(convolutional neural networks,CNN)是一种前馈神经网络,是具有权值共享结构的多层感知器,受早期的延时神经网络的影响,CNN也是第一个成功训练多层网络的算法。人工神经网络的参数过多,相较于一般网络,CNN通过其空间关系如局部连接与参数共享使其模型复杂度比较低,权值数量也较少。当本设计输入为图像时,这一优点表现地更加明显,它使图像可以直接作为网络的输入。CNN参数数目的减少显著提高了BP算法的性能,因此有助于提高最终生成字幕的质量。CNN网络结构的核心特点是将权值共享,局部感受区域和时间或者空间的亚采样这三种结构相结合。
在CNN的网络结构中,其层级结构的底层是以输入图像中的局部感受野(只有一小部分)作为输入,每一层都通过数字滤波器来获得所观测数据的最显著特征,之后信息再依次传递到不同的层。图像的空间联系是局部的,每一张图像中的像素点只与周围的像素点关系较大,若参数过多时容易收敛到一个较差的局部极值。同时由自然图像的统计特点可知,每个神经元可以与局部连接使用相同的参数,在一个映射面上的神经元可以权值共享。这意味着每个神经元不需要对全局的特征进行感受,而是感受一小部分的空间区域,在下一层中将神经元提取的信息综合起来获得全局的信息,从而成倍减少了该网络中需要训练的参数数目,提高处理图像的效率,这也减小了过拟合的可能性,也使该网络对输入的图像畸变的容忍度较高。其中神经元提取图像的特征,每种神经元就是一种卷积核。卷积核存在差异,提取的特征就不相同,所以如果要提取图像中的多个特征就需要多个不同的卷积核,这些卷积核使用不同的参数来对图像不同特征进行放映,即特征匹配。最基础的CNN网络最少有五个隐含层,即两个非线性可训练的卷积层,两个非线性的降采样层(池化层)和一个全连接层。它的每一层都是数个二维平面,而每一个二维平面都包括着数个神经元[1]。
本设计中选择CNN作为图像的“编码器”,CNN将输入图像嵌入到固定长度的矢量中来产生丰富的输入图像表示,这种表示可以用于各种视觉任务[5],因此将CNN与训练用于图像分类任务,并使用最后的隐藏层获得的内容作为RNN解码器的输入。在卷积神经网络中,通过很多层的卷积输出之后,一个数就概括了原始图像中许多信息,因此卷积层的输出即提取的特征是包含有图像自身的位置信息的。从原图经过卷积后得到14×14的feature map,即卷积层为14×14×256,每个14×14的向量长度为256。为了将这些具有同样特征的信息提取出来,对其做一个处理。多通道的卷积输出同样的位置也对应着原图像同样的位置,因此需要将卷积层的多输出变成一个个的向量,即组合不同通道相同位置的值,即14×14个向量。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: