基于深度学习的电影评论情感分类系统研究毕业论文
2020-02-17 21:59:36
摘 要
深度学习是文本分析的关键技术,Word2Vec等词向量空间预测模型的出现使神经网络在文本情感分析领域的应用更进一步。与全连神经网络相比,卷积神经网络(CNN)的稀疏连接、参数共享等特性使其在更好地捕捉文本的语义特征的同时具有较低的时间复杂度。
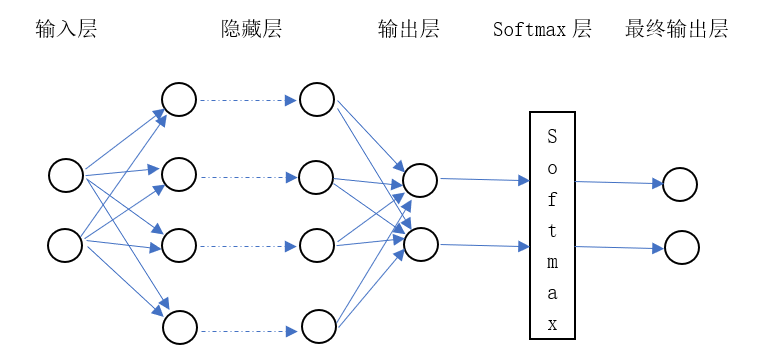
传统CNN执行分类任务时最终输出常使用Softmax分类器,在实践中容易过度拟合。本文结合CBOW语言模型和改进的CNN来进行文本情感分析(CBOW D-CNN),采用Python编程,运用TensorBoard进行可视化操作。为解决传统模型的缺陷,在Softmax分类器中引入Dropout策略,可有效防止过度拟合,优化模型的泛化能力。此外,通过连续词袋(CBOW)语言模型构造了一种连续分布式词语表示方法,形成了新的文本向量表示,使CNN能够更有效地学习文本特征。IMDB电影评论数据集的实验结果表明,与传统分类器相比,该方法的性能得到了显着提高,分类准确率达到89%。
关键词:文本情感分析;深度学习;卷积神经网络;词向量
Abstract
Deep learning is the key technology of text analysis. The emergence of word vector space prediction model such as Word2Vec makes the application of neural network in the field of text sentiment analysis further. Compared with the fully connected neural network, the features such as sparse connection and parameter sharing of the convolutional neural network (CNN) make it have a lower time complexity while better capturing the semantic features of the text.
When the traditional CNN performs the classification task, the final output often uses the Softmax classifier, which is easy to over-fit in practice. This paper combines CBOW language model and improved CNN for text sentiment analysis (CBOW D-CNN), using Python programming, using TensorBoard for visualization operations. In order to solve the defects of the traditional model, the introduction of the Dropout strategy in the Softmax classifier can effectively prevent over-fitting and optimize the generalization ability of the model. In addition, a continuous distributed word representation method is constructed by the continuous word bag (CBOW) language model, which forms a new text vector representation, enabling CNN to learn text features more effectively. The experimental results of the IMDB film review dataset show that the performance of the method is significantly improved compared with the traditional classifier, and the classification accuracy reaches 89%.
Key Words:text sentiment analysis; deep learning; convolutional neural network; word vector
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.3 本文主要研究内容和结构 2
第2章 研究基础及相关理论 3
2.1 基于情感词典的文本情感分析 3
2.2 基于机器学习的文本情感分析 3
2.2.1 无监督学习 4
2.2.2 监督学习 5
2.3 基于深度学习的文本情感分析 7
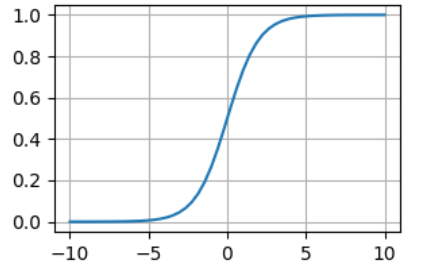
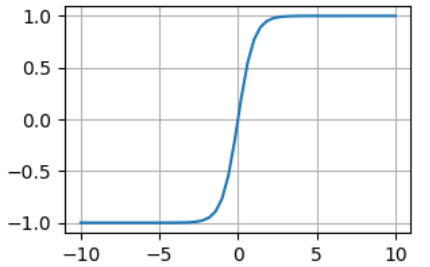
2.3.1 全连接神经网络 8
2.3.2 网络优化方法 13
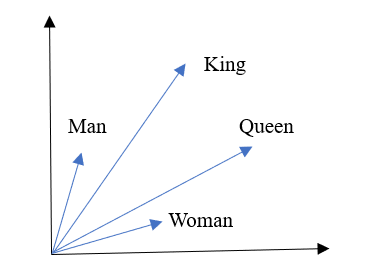
2.3.3 词向量 18
第3章 系统设计与实现 21
3.1 卷积神经网络模型设计 21
3.1.1 卷积与卷积核 21
3.1.2 池化 22
3.1.3 CNN框架 24
3.2 基于CBOW和CNN的文本情感分类系统 24
3.2.1 系统设计 24
3.2.2 系统实现 26
3.2.3 数据分析 30
第4章 总结与展望 35
4.1 工作总结 35
4.2 工作展望 35
参考文献 36
致 谢 38
绪论
研究背景及意义
由于互联网社交平台的快速发展,人们在这些平台上交流与合作成为一大趋势。统计数据显示,社交网络受欢迎程度稳定增长,绝大多数人拥有不止一个社交账号,他们通过文本信息沟通交流、发表评论,分析这类文本信息并揭示其隐藏属性在这样一个信息化时代显得十分重要。这类现象引起了自然语言处理(Natrual Language Processing)这一领域学者的极大关注,近年来对文本处理的研究越来越成熟。
社交网络中最流行的通信格式之一是评论。假如互联网上出现了一个关于时事热点的讨论文章,表达说话人的想法和观点,这样的文章通常会非常吸引人们的眼球,让他人产生情感共鸣,其他人就会开始通过发表各种各样的评论来积极地讨论它。Google 、Facebook和Twitter等社交网络提供了大量数据,可用于分析用户的个性或对公司产品的看法。这些大量数据包含重要的意见相关信息,可用于为企业、商业、科学行业等其他方面带来利益。然而这些数据往往非常庞大,使用手动方法从大量数据中提取意见、感受或态度几乎是不可能的,因此发展基于人工智能和机器学习算法以自动地对社交网络数据进行分类是很重要的。特别是,可以为每段文本分配情绪指数,这样的任务通常涉及检测文本是表达积极,消极还是中性情绪。
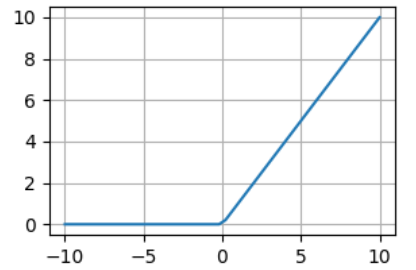
卷积神经网络主要用来提取文本特征,自词向量的概念被提出以来,原本应用于机器视觉领域的卷积神经网络发挥了其更广泛的作用。它使文本特征提取更有效的同时采取多种方式降低参数维度,可以使相应的算法更加适用于大规模语料数据和用于处理数据的机器设备性能。
国内外研究现状
利用自然语言处理技术分析互联网上的大数据文本,探索其中所包含的情感倾向,已成为社会舆论监督和工厂售后信息反馈的重要途径。因此,文本情感分析方法的研究具有重要的社会价值和商业价值。
现有的情感分析方法主要分为情感词典和机器学习[1][2]。情感词典方法在很大程度上依赖于情感词典的质量和覆盖范围。机器学习方法大致分为三个部分,首先将单词映射到向量空间,接着利用语意合成对句子特征进行提取,最后的情绪极性分类需要使用分类器[3]。常用的是支持向量机(SVM),信息熵和条件随机场(CRF)。这些方法依赖于大量手动标记的数据和特征,系统标记成本高[4]。
近年来,深度学习技术在自然语言处理领域取得了长足的进步,出现了各种基于深度学习的文本情感分析方法。例如,Nguyen等人使用递归神经网络(RNN)来提取句子的语义特征,Wang等人使用卷积神经网络(CNN)来提取句子的特征。在深度学习中,最有效的提取句子特征的方法都有利用CNN和RNN这两类神经网络。在AI的其他领域,这些特征自学习方法也取得了丰硕的成果。在NLP任务中,它们可以自动提取句子特征并进行相应学习,对传统语法分析工具不存在依赖性[5],因而受到众多研究人员的青睐。
CNN可以更好地捕捉文本的语义特征,而且具有较低的时间复杂度[6]。然而,传统的CNN网络在情感分析的任务中处于劣势。也就是说,传统的CNN在执行文本情感分类任务的过程中,其输出一般使用的是Softmax分类器,众多的神经网络模型参数很容易在实践中出现过拟合现象[7][8]。为了解决传统CNN的缺陷,在Softmax分类器中引入了Dropout方法,这一方法在防止模型过度拟合方面效果显著,能够有效提升模型泛化能力[9]。此外,通过连续词袋(CBOW)语言模型,构造了一种连续分布式词语表示方法,形成了新的文本向量表示,使CNN能够更有效地学习文本特征。
本文主要研究内容和结构
本文是深度神经网络在自然语言处理领域的研究,具体的目标是拟设计一个基于深度学习的电影评论情感分类系统,达到能够分辨正面评论和负面评论的效果。本文结合CBOW语言模型和改进的CNN深度学习[10]来进行文本情感分析(CBOW D-CNN)。IMDB电影评论数据集的实验结果表明,与传统分类器相比,该方法的性能得到了显着提高,分类准确率达到89%。
本文具体工作如下:
(1) 对文本情感分析基本流程,包括文本预处理、文本表示方法和构建分类模型等进行深入学习研究。在文本表示时,针对高维度和语义不相关的问题,本文使用CBOW语言模型完成Word2Vec词向量构建,将文本单词转化为含有一定语义信息的向量之后有助于神经网络分类模型对文本语义更好的理解。本文使用Dropout优化的CNN模型提取文本特征,减少了传统模型过拟合现象。
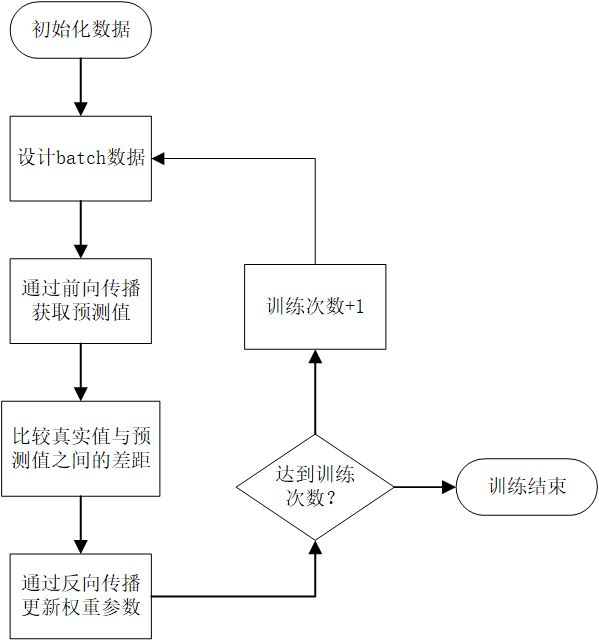
(2) 在构建整个系统时,结合当今比较热门的神经网络方法,在深入了解卷积神经网络基本原理的基础上,设计Python程序,利用卷积神经网络来进行电影评论的文本特征提取和分类,并运用TensorBoard对模型仿真结果进行可视化操作。
研究基础及相关理论
基于情感词典的文本情感分析
情感倾向是文本主观性意见的度量,通过选择含有积极或消极因素的字、词或短语并衡量这些字、词和短语表现出的强烈程度,可以获得文本的情感倾向。Maite Taboada等人在其研究中表示,基于情感词典的文本情感分析,是把文本进行分词后找出情感倾向关键词在情感词典中对应的权重,将整个文本进行语义倾向计算(Semantic Orientation CALculator,SO-CAL)后得出该文本情感倾向是积极或消极。
情感词典是带有语义方向或极性的单词词典,词典的创建一般有两种方式,Stone和Tong等人在其研究中采用了手动创建,Hatzivassiloglou、McKeown和Turney等人则利用种子词自动地扩展单词列表。大多数基于词典的研究都把形容词作为文本语义方向的指标,实际上动词和名词也会在很多场景下体现出情感倾向。在SO评估中还需要考虑一个词的使用语境,例如上下文是否存在否定、情感强化或削弱,Kennedy和Inkpen在其研究中通过创造单独的特征来处理这样的情况[11]。因此,用于分析文本情感的词典一般包含四类:
(1) 语义方向词典,表示消极或积极;
(2) 程度副词词典;
(3) 否定词词典;
(4) 停用词词典。
将四类词语和相应的SO值编译成词典,对任意给定的文本进行分词,用词典中对应的SO值对得到的词进行注释,所有SO值汇总成文本的最后分数,最后根据规定阈值就可以判断文本情感倾向。Taboada等人的研究表明其开发的基于情感词典的SO-CAL在不同领域的文本分类任务上体现出健壮性和可靠性。
基于机器学习的文本情感分析
机器学习是一项现代创新,它不仅帮助人们增强了许多工业和专业流程,而且还促进了日常生活。机器学习是人工智能的一个子集,专注于使用统计技术构建智能计算机系统,以便从可用的数据库中学习。基于机器学习算法的智能系统具有过去经验或历史数据的能力,机器学习应用程序根据过去的经验提供结果。目前,机器学习已经在多个领域和行业中使用。例如,医学诊断,图像处理,预测,分类,学习关联,回归等。
卡内基梅隆大学(Caregie Mellon University)的Tom Michacl Mitchell教授在其1997年出版的《Machine Learning》一书中对机器学习给予了专业的定义:如果一个程序可以在任务T上,随着经验E的增加,效果P也随之增加,则称这个任务可以从经验中学习,这一关于机器学习的定义在学术界被广泛引用[12]。
广告短信分类任务是机器学习算法之一。完成这个任务的典型做法是大量搜集短信,并对每一条短信是否为广告进行人工标注。这些短信数据在机器学习领域被称为训练数据。机器学习算法判断短信是否为广告需要法有所依据,比如发布号码,短信标题,发件人等,这些称为短信的特征。将大量标注过的短信输入到机器学习算法中,机器学习算法会学习到这些短信的特征和标注之间的关系,输入的数据越多,算法习得的特征越显著,对区分未经标注的短信是否为广告也就越精确。
无监督学习和监督学习是机器学习的两种主要学习形式,将数据进行标注属于典型的监督学习。
无监督学习
无监督学习是使用既未分类也未标记的信息对机器学习算法进行特征学习来发现训练实例中的一些结构性知识。由于标注对学习算法来说是未知的,即要划分的类别信息是未知的,并且在很多情况下不知道有多少类别,没有已经划分好类别的样本用于训练算法,因此学习算法的训练目标具有很高的歧义性。这种算法要做的是,将给出的样本聚类(使在一定意义上具有相似性的样本归为一类,较大差异的样本属于不同类别)并划分成几个类。
在无监督学习算法中,使用的许多方法都是基于数据挖掘的,这些方法的主要特点都是寻求、总结和解释数据[13]。无监督学习广泛应用于聚类算法,聚类算法将遍历输入数据并找到这些自然聚类。常用聚类算法有如下三种:
(1) K-Means聚类:将数据点聚合成数量(K)互斥的类,很多复杂性围绕着如何为K选择正确的数字。
(2) 分层聚类:将数据点聚类到父类或子类中。
(3) 概率聚类:以概率尺度将数据点聚类为某一类别。
现代计算机在计算能力和存储成本方面取得了重大进展,但仍然有必要进行数据压缩,保持数据集尽可能小和高效,这意味着算法只运行必要的数据。无监督学习可以通过称为降维的过程来帮助解决这个问题。维度减少(维度=数据集中有多少列)很大程度上依赖于信息理论有关的概念:假设数据大量冗余,并且可以只使用一个数据集来表示数据集中的大多数信息的一部分实际内容[14]。实际上,这意味着以独特的方式组合部分数据以传达意义。下面是两种常用降维算法:
(1) 主成分分析(PCA):查找传达数据中大部分差异的线性组合。
(2) 奇异值分解(SVD):将您的数据分解为另外三个较小矩阵的乘积。
这些方法以及它们的一些更复杂的改进方法都依赖于线性代数的概念,将矩阵分解为更易处理和信息化的部分。减少数据的维度是良好的机器学习算法的重要组成部分。以新兴计算机视觉领域的图像中心为例,可以将训练集的大小减少一个数量级,那么将大大降低计算和存储成本,同时使模型运行速度更快。
监督学习
监督学习(Supervised Learning),也被称为教师学习或者有监督学习,学习的过程是从带有标注的训练数据中学习到如何对训练数据的特征进行标志性判断。这个过程可以形象地描述成:机器学习算法模型从输入的训练数据集中学习到一个函数,当新的没有标注的数据到来时,这个函数能够独立完成对相应的特征进行已习得的特征性判断。在监督学习中一个训练数据集一般会包含很多单独的实例,数据量的增加是该机器学习算法获得的判断函数准确性提高的途径之一。每一个实例的特征就是该算法的输入数据,数据的标注就是算法期望输出的值(训练数据一般由人工标注)。大部分的机器学习都采用监督学习的形式,这种形式的学习主要用于分类和预测[15]。
基于机器学习的文本情感分析就是采用的监督学习形式。文本情感分析是将文本按照情感倾向分为积极、消极或中性,这属于文本分类任务,即将预定义类别分配给文档。采用机器学习方法进行的文本情感分析通常具有如下步骤:
(1) 文本收集:一般情况下可以采用网络爬虫获取数据集,HTML形式的数据还需进一步处理,以提取所需信息,将数据分成开发集和测试集,其中开发集包括训练集和开发测试集,开发集数据均进行人工标注;
(2) 文本预处理:数据预处理主要包括四项工作:标记化、去除停用词、词干和向量空间模型,这一过程也称为文本向量化;
(3) 文本特征化:使用特征选择或者特征提取的方法提取文本关键字,将所有原始语料转化为特征表示的形式;
(4) 特征降维:结合信息理论、统计学等方法得到信息量丰富的文本特征,减少特征的数量以加快计算速度,同时减少噪声提高分类准确率;
(5) 构建分类器:使用不同分类算法,调整特征维度,将训练集中的特征化文本做为输入数据构建分类器,并用开发测试集检验算法分类结果准确度,最后选择最佳算法;
(6) 将训练好的算法用于测试集数据。
与使用机器学习算法进行分类的许多其他应用程序不同,文本文档不适合于算法的立即应用,因为大多数算法只能处理结构化类型的输入。机器学习算法不能接受自然语言作为输入,需要将输入数据处理成计算机能够处理的形式,因此构建文本分类模型的第一步是文本预处理,将文档转换为与许多机器学习算法兼容的向量,通常都做法是将原始文本转换成数值张量。文本预处理包括四个步骤:标记化、去除停用词、词干和向量空间模型。标记化用于删除空格和特殊字符。去除停用词是去除非常常见的单词,用于删除带有很少意义的信息数据,停用词仅具有语法意义且包含众所周知的主题。检索专家认为,一组功能性英语单词(例如“the”,“a”,“and”,“that”)作为检索时的加权术语是无用的。这些单词具有非常低的识别值,因为它们出现在每个英文文本文档中。词干用于从关键字中删除后缀和前缀。文本预处理的最后一步是使用向量空间模型,将经过前三步处理的文本在公共向量空间中表示为标记的向量。把整个待处理文本分解成为单个单词、关键词或n个单词的连续序列,将这些单元作为标记,整个分解过程称为分词,这些单词或序列称为n-gram。向量空间模型的构建过程即采用某种分词方案对原始语料进行分词,然后将生成的标记与数值向量进行关联。
特征提取(FE)的主要目的是将原始文本转换为关键字文本,以便于监督学习算法处理。除此之外,FE可以提供文本中高频词信息,选择相关关键字和识别方法用于在监督机器学习中编码这些关键字。这些关键字通常对提取最佳模式的分类技术产生较大影响。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: