基于图形处理器的AES算法加速解决方案外文翻译资料
2022-11-08 20:47:02

英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
基于图形处理器的AES算法加速解决方案
Radu-Daniel TOMOIAGĂ, Mircea STRATULAT
摘要:本文的主要目的在于分析非图形计算中使用图形处理器的可能性。GPU如今不仅使用在游戏引擎和电影编解码,而且有了更广阔的的应用——密码学。我们使用GPU作为一个密码辅助处理器来加快AES算法的处理速度。我们在CUDA平台上实现基于GPU的AES算法。从运行存储在内存中的小数据块和存储在硬盘中的文件中的大数据块两方面的实验,可以看出在CUDA平台上可以得到11.95Gbps的加速效果。
关键词:AES,标准检查程序,密码学,CUDA,GPU.
- 前言
传统的处理器开发已经接近其技术极限,一个高性能的处理器供应商通常是提高处理器频率,但其温度和功耗方面又会产生新的问题,对此,一个解决方案是提供多核处理器。多核处理器在性能方面得到了提升,但为了多核所使用特殊的开发软件也受到了限制。另外一个代替多核处理器的解决方案是采用云计算,但云计算非常复杂并且需要大量的资源(计算机)。这两种方案都非常昂贵:多核处理器比普通的显卡更昂贵,而且GPU能够提供的功能多核处理器也不完全能提供。云计算基于大量的采用计算系统的硬件资源,这也是它非常昂贵的原因。
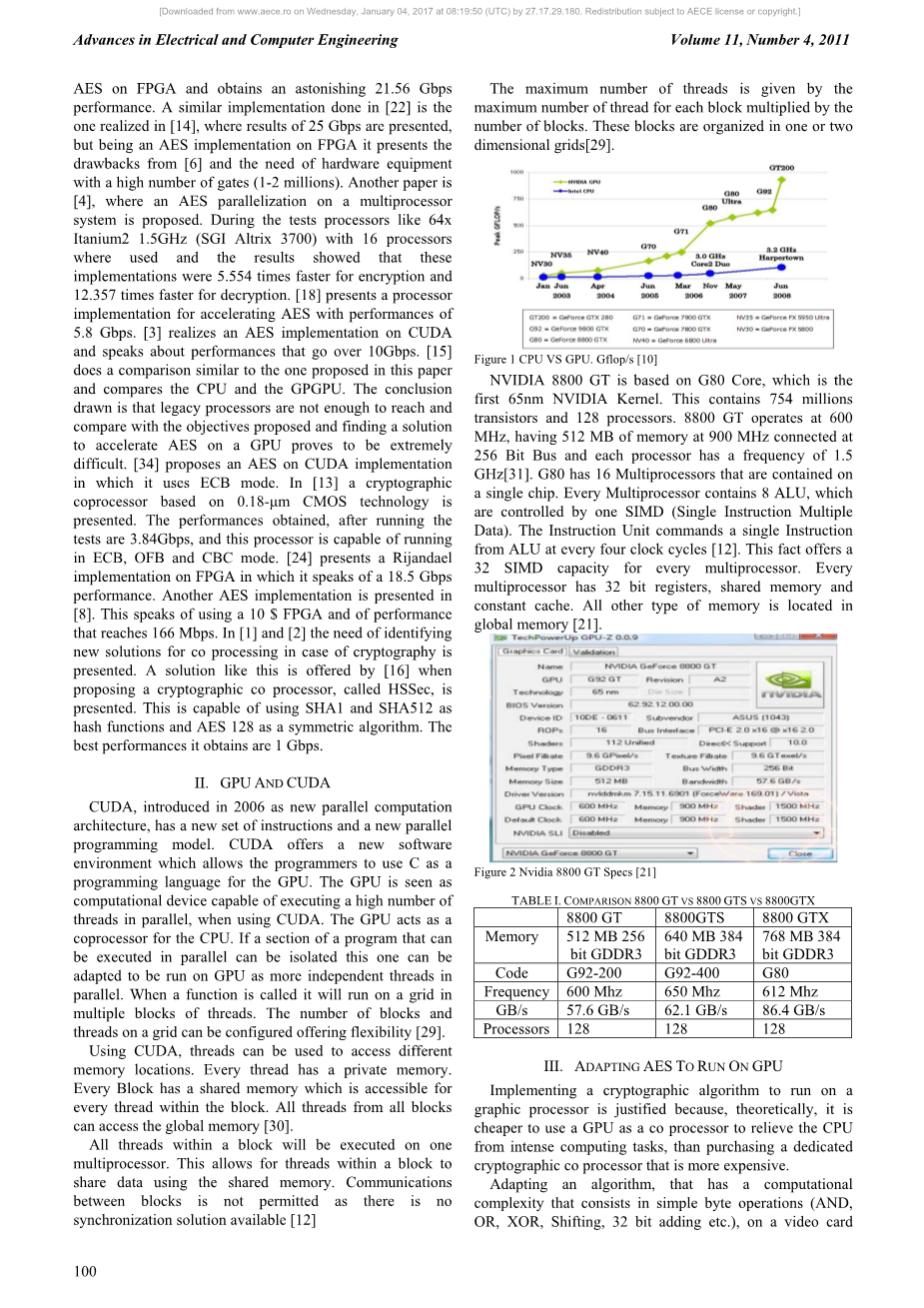
针对以上问题提出的解决方案就是图形处理器(GPU)。GPU包含许多核同时可以并行处理多线程。从众多的密码原语中我们选择对称标准算法——AES算法。在文献【32】中,作者从库克2005年成功利用GPU实现加密算法开始,在硬件环境为处理能力位96 GFLOP的英特尔酷睿2 (QX6850)处理器和处理能力位330GFLOP 的NVIDIA GEFORCE 8800GTX显卡下,分析了DirectX和OpenGL,并得出结论。AES算法获得了4.5Gbps的性能而DES算法获得了2.8Gbps的性能。
在文献【17】中,Michael Kipper基于GPU运行AES算法并得到了比在CPU上运行快14.5倍的结论。他还指出,仅仅是用蛮力运行AES算法可不会有这样的成功。类似的在文献【19】中,Luken Brandon基于GPU运行了改进的AES算法和DES算法,测试中使用100MB大小的文件,AES算法的运行速率比在CPU上运行快了3.75倍,DES算法的运行速率比在CPU上快了4.5倍。
在文献【20】中,Manavski Svetlin提出了他基于GPU使用NVIDIA提供的CUDA平台对于AES算法的加速性能:AES分组长度为128时性能最好,采用8MB的文件大小,其运行速率比CPU上快了19.6倍。
文献【26】提出了另一种AES算法的改进。作者基于汇编语言用OpenGl进行了两组试验:顶点编程和分段编程。使用奔腾4处理器3 Ghz,2MB二级缓存,1 GB 内存和GeForce 8800 GTS 640 MB的显卡平台,输入尺寸从4 KB和16 MB,他获得10 Mbps和95 Mbps之间的性能。试验中,作者使用只在解码可以并行处理的CBC(CIPHER-BLOCK)加密分组链接模式,但最终由于更高的并行性和采用相同代码简化加解密过程,作者更推荐使用CTR计数器模式。
在文献【5】中,作者提出采用8位AVR单片机和GPU(8800 GTX和GTX295),使用NVIDIA的CUDA平台得到59.6 Gbps(GTX295)和14.6 Gbps(8800 GTX)加密和52.4 Gbps(GTX295)和14.3 Gbps(8800 GTX)解密性能。本文只使用查找表作为主要优化方法,得到的结果与输入文件大小无关。采用了CTR计数器模式,在此模式下加解密使用相同的源代码,因此在加密性能和解密性能上没有太大差异。文献【7】提出了一种评估应用程序的方法,他设计使用了一种明显简化过程的分析概念,并提出使用代表科学和商业应用的新的分析结构统计和收集试验数据。文献【33】提出了一种修改AES算法中的列混合步骤的改进,并得到比原来方法快得多的结论,但并未给出测试过程和获得的加速比。在文献【6】中,实现了基于FPGA的AES算法加速,加速性能为2Gbps,但主要的不足之处在于FPGA的硬件设计和学习,而且其性能在2007年被打破:文献【20】达到了8.28Gbps的性能,文献【22】基于FPGA使用相似的显卡达到了惊人的21.56Gbps。文献【14】的实现方式与【22】相似,达到了25Gbps的性能但其体现了跟文献【6】相同的缺点:使用大量的硬件设备——1-2百万的逻辑门。文献【4】提出了多处理器AES并行化。使用64 x Itanium2 1.5 ghz(SGI Altrix 3700)测试处理器与16个处理器得到加密快5.554倍,解密快12.357倍。文献【18】提出一个处理器实现加速AES算法的5.8Gbps的性能。文献【3】提出在CUDA平台上实现AES算法的性能超过了10Gbps。文献【15】做了在CPU和GPGPU上的性能比较,得到了传统处理器很难到达比较的目标,并且认为在GPU上加速AES算法已经非常困难了。文献【34】提出了在CUDA平台上采用ECB电子密码本方式实现AES算法。文献【13】提出了基于0.18mu;m CMOS的加密协处理器方式,测试得到了3.84Gbps的性能,并且该处理器可以支持运行ECB电子密码本模式、OFB输出反馈模式和CBC加密反馈模式三种。文献【24】在FPGA中实现了Rijandael算法并声称得到了18.5Gbps的性能。文献【8】提出了另一种AES算法的实现,声称10美元制作出来的FPGA芯片即可达到166Mbps的性能。文献【1】和【2】提出密码学需要新的解决方案——类似于文献【16】提出的叫做HSSec的加密处理器(能使用SHA1和SHA512作为hash函数和AES128位对称算法),兵器其最好性能为1Gbps。
- GPU与CUDA
2006年引入的CUDA新并行计算体系结构中,有一个新的指令集和一个新的并行编程模型。CUDA提供了一个新的软件环境,允许程序员使用C作为 GPU编程语言。在CUDA平台中,GPU被视为有能力执行大量的并行线程的计算设备。GPU充当CPU的协处理器。如果程序的一部分可以并行执行,则可以孤立这一部分到GPU中并行运行更多的独立线程。当函数被调用时,他讲运行在由多线程组成的程序块的网格中。网格中可以程序块和线程的数目可以配置以提高灵活性 [29] 。
使用CUDA,线程可以用来访问不同内存位置。每个线程都有一个私有内存, 每个块都有一个所有线程共享的内存。每个块中的所有线程都一颗访问全局存储器[30]。
程序块中的所有线程都被多处理器执行,这使得线程可以使用共享内存来共享数据,块内的通信是不被允许的,因为没有同步解决方案[12]。
线程的最大数量由每个块的最大线程数乘以块的数目得到,块被组织在一个一维或二维网格中[29]。
图1 CPU VS GPU的浮点运算能力对比
四核
双核
每秒执行的浮点运算次数(GFLOP/s)
英伟达8800 GT是基于G80的核心,这是第一个65 nm的 NVIDIA内核。它包含7.54亿个晶体管和128个处理器。8800 GT运行在在600 MHz,有512 MB的内存,900 MHz连接 256位总线和每个处理器的频率为1.5 GHz[31]。G80的16多处理器都包含在一个芯片上。每个多处理器都包含8个运算器,由SIMD(单指令多数据)控制。一个指令周期等于四个时钟周期[12]。这一事实位每个多处理器提供了一个 32 SIMD的处理能力。每一个多处理器都有32位寄存器,共享内存和恒定的缓存。其他所有类型的存储都存储于全局存储器中。
表1 8800GT、8800GTS、8800GTX显卡型号性能比较
|
8800GT |
8800GTS |
8800GTX |
|
|
存储器 |
512MB 256bit DDR3 |
640 MB 384bit DDR3 |
768 MB 384bit DDR3 |
|
编码 |
G92-200 |
G92-400 |
G80 |
|
频率 |
600 Mhz |
650 Mhz |
612 Mhz |
|
带宽 |
57.6GB/s |
62.1GB/s |
86.4GB/s |
|
处理器 |
128 |
128 |
128 |
图2 NVIDIA 8800GT显卡信息
- 基于GPU的AES算法实现
利用GPU实现加密算法是非常合理的,理论上讲,使用GPU作为多处理器来减轻CPU的计算任务比购买更加专用的加密处理器更加便宜。实现一个计算复杂性非常高的算法,能够实现简单的字节运算(与、或、异或、移位、32位加等)、需要能够运行复杂运算和浮点数运算的显卡是研究的基础。
基于GPU的AES算法实现必须考虑到以下几个方面:CPU AES优化必须重新分析,因为这是进行查找表的基础,理论上可以减缓在GPU的情况下计算速度。为了确认AES在GPU完全实现需要完成两个步骤: 第一步是实现AES算法使用查找表和在第二步中AES不用查找表, 只使用基本操作实现。
GPU是为了并行运算设计的而并不适用于基于前一步结果的加密算法(串行),算法实现必须建立在比内存操作更复杂的计算上,使用支持CUDA环境的显卡其优点是CUDA可以使用移位操作,提供灵活的内存访问,数据可在GPU中直接定义而不需要额外的从CPU中复制过来的操作[23]。
在传统处理器的情况下,优化的AES 算法是用基于存储在内存中的查找表代替算术运算,不同于CPU,GPU可以在一个时钟周期内进行更多的操作。根据文献【23】,GPU比CPU的延迟更大,因为分析内存访问可知,在进程中是GPU在执行。在文献【25】的测试中,作者得出了在进行大量操作时GPU比内存访问更快的结论。
基于GPU实现AES算法时需要考虑到:CPU想要获得更好的性能,而GPU被专门设计用来执行并行多任务的,只能够执行可进行并行计算的AES工作模式(ECB电子密码本模式和CTR计数器模式),尽管CBC模式在解密时也可被并行计算。AES的工作模式有ECB电子密码本模式,CBC加密分组链接模式,CFB加密反馈模式,PCBC传播密码块链接模式,OFB输出反馈模式,CTR计数器模式。下面对于每种模式的加密进行了说明。
从两种可以并行计算的模式中选择了CTR模式,因为CTR模式更加安全并且更适合大规模并行化。ECB模式的缺点在于各明文块采用相同的密钥加密。分析了CTR模式之后我们不需要进行其解密,因为该模式下的加解密蔡永祥相同的源代码,测试只需要调用加密功能即可,如果需要解密再调用一次函数即可。
CTR使用一个简单的方法来生成密钥。它将一个随机数和和计数器的值在一个块进行加密。这个随机数要比块小得多,因为必须要在计数器中有足够的空间,由CTR提供的O设施可以轻松的进行明文访问和随机文本部分的访问。CTR的主要优势是它可以高速的运行并行应用程序[11],主要缺点是算法可能受到特定的硬件故障攻击[27]。
图3给出了一个简化的实现算法并行计算的流程方案。
图3 AES并行算法示意图
图4 电子密码本模式工作示意图
图5 CBC加密分组链接模式工作示意图
图6 CFB加密反馈模式工作示意图
图7 PCBC传播密码块链接模式工作示意图
图8 OFB输出反馈模式和CTR计数器模式工作示意图
密钥扩展是在CPU中完成的(因为主要是串行操作,不需要GPU),而实际的加密过程是在GPU中完成的。本文优化了所有线程的存储:所有线程均使用全局存储器,以完成一个内存访问分组。数据访问合并允许GPU进行更快的读写操作[17]。初始阶段,进行数据处理之前要先完成全局内存访问。然后数据在共享内存中的移动就更快了。如果每个线程从全局存储器加载共享存储器中的数据(可能从不使用),则在使用共享存储器之前需要同步步骤。同步对于向全局内存中写数据非常必要[17] 。 剩余内容已隐藏,支付完成后下载完整资料
资料编号:[138667],资料为PDF文档或Word文档,PDF文档可免费转换为Word



