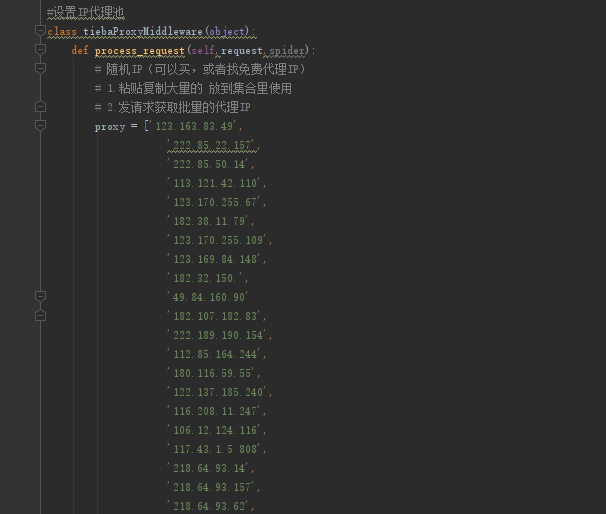
基于Scrapy的贴吧爬虫系统设计和实现毕业论文
2020-02-16 22:34:46
摘 要
本文使用python语言下的Scrapy Django框架,开发了一个贴吧爬虫信息系统,对武汉理工大学吧的数据进行爬取,保存和检索。本项目建立了Sqlite3数据库保存爬取到的数据,并对其进行更新和维护。用Django开发了web应用程序实现对数据的检索和展示。可以帮助想要从贴吧获得信息的同学以更加快速方便高效的方式找到想要的信息。
本文的特色:将Scrapy和Django两种框架相结合,共用数据库,同步开发。
关键词:Django,Scrapy,武汉理工大学贴吧,爬虫,Sqlite3
Abstract
This paper uses python's Scrapy Django framework to develop a tieba crawler information system, which can crawl, save and retrieve the data of wuhan university of technology post bar.In this project, Sqlite3 database is established to save the data crawled, and update and maintain it.Django is used to develop a web application to retrieve and display data.It can help students who want to get information from tieba to find the information they want in a more rapid, convenient and efficient way.
This article features a combination of Scrapy and Django framework , a Shared database, and synchronized development..
Key Words:Django, Scrapy, wuhan university of technology, crawler, search, Sqlite3
目录
第1章 绪论 6
1.1 爬虫的定义 6
1.2 python与Scrapy爬虫框架 7
1.3 贴吧现状分析 7
第2章 需求分析 9
引言 9
2.1功能需求分析 9
2.2 运行环境分析 9
本章小结 10
第3章 系统设计 11
引言 11
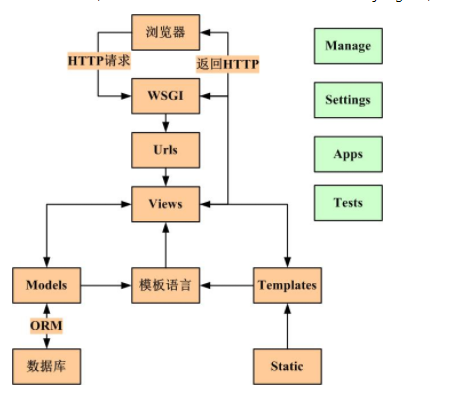
3.1系统总体设计 11
3.2爬虫模块设计 12
3.2.1 Scrapy的架构 12
3.2.2 Spider的逻辑设计 14
3.2.3 Item的设计 15
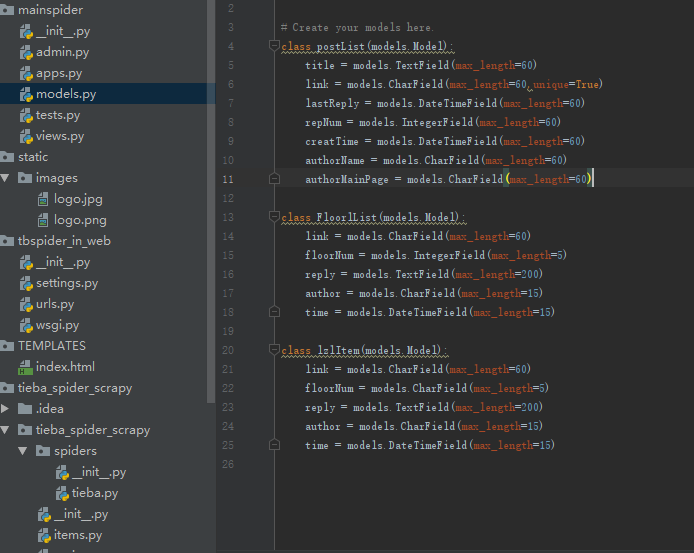
3.3数据库管理模块设计 17
3.3.1 数据库表的设计 17
3.3.2 数据库操作的设计 17
3.4前台展示模块设计 18
3.4.1 数据提交页面的设计 18
3.4.2 搜索结果页面的设计 18
本章小结 18
第4章 系统实现 20
前言 20
4.1开发环境和开发工具 20
4.2 爬虫模块的实现 20
4.2.1 遍历所有页面 21
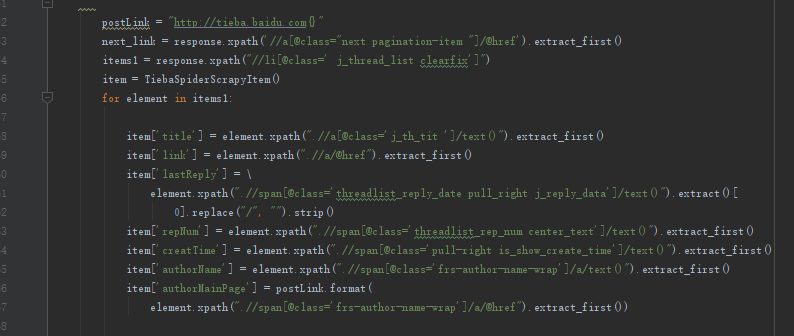
4.2.2用xpath定位数据 21
4.2.3 Pipeline保存数据 22
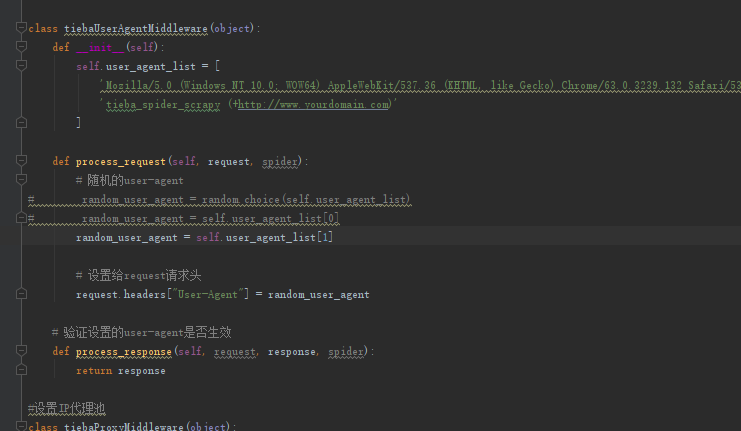
4.3.4应对反爬虫机制 24
4.3数据库的建立和更新 25
第一条命令是: 25
4.4前端页面实现 26
本章小结 27
第5章 系统测试 28
引言 28
5.1爬虫测试 28
5.2表单和界面测试 29
本章小结 30
第6章 总结 31
参考文献 32
第1章 绪论
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,检索所有新出现的网页变得越来越困难,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的搜索引擎便应运而生了,例如传统的通用搜索引擎百度,雅虎和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
从爬虫的定义来说,搜索引擎其实就是通用网络爬虫,它的搜索对象是整个web。现在有人遇到问题问别人的时候,大家都喜欢说有事问度娘,就是让他自己百度搜索一下,可见这种通用网络爬虫的威力之大,日常生活中想要得到的信息用通用网络爬虫基本就能全部得到。
然而,这些通用网络爬虫也不是万能的,度娘也不例外。通用网络爬虫也存在着一定的局限性,如:
(1)不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2)通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
(4)通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,我们需要定向抓取相关网页资源的聚焦爬虫。本次我的选题:基于Scrapy的贴吧爬虫系统就是一个聚焦爬虫实例,它爬取的对象是百度贴吧这个域名范围内的所有内容。
1.1 爬虫的定义
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。 实际的网络爬虫系统通常是几种爬虫技术相结合实现。
通用网络爬虫:
通用网络爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。
聚焦网络爬虫:
聚焦网络爬虫又称主题网络爬虫,是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
增量式网络爬虫:
增量式网络爬虫是 指 对 已 下 载 网 页 采 取 增 量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
深层网络爬虫爬虫
Web 页面按存在方式可以分为表层网页和深层网页。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。例如那些用户注册后内容才可见的网页就属于深层网页。一个普遍的认知是,深层网页中可访问信息容量是表层网页的几百倍,是互联网上最大、发展最快的新型信息资源。
1.2 python与Scrapy爬虫框架
说到开发爬虫,不得不提到python。虽然java,c,c ,php等语言都可以做爬虫,但是Python 的优势在于库更丰富,框架更加成熟,但是对于新手来说,并且python是最易学的,语法也简单。
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
1.3 贴吧现状分析
虽然不止百度有贴吧,但目前最具影响力的只有百度贴吧,所以我的选题——贴吧爬虫系统是专门针对百度贴吧,以下所说的贴吧都是指百度贴吧。
贴吧是结合百度搜索引擎建立的,,以下,它的涵盖目录相当广泛,包括社会,地区,生活,教育,娱乐明星,游戏,动漫,小说,体育,企业,可以说,生活中的方方面面都能找到对应的这么一个帖吧。在2015年贴吧开始疯狂商业化变现之前,吧主本身就是贴吧的普通用户,基本上任何合法用户都可以创建属于自己的贴吧,然后聚集起有相同兴趣爱好的网友。它曾经有十分庞大的用户数量,2014年贴吧的活跃用户数量曾达到2亿之多,如此多的用户产生的的信息量相当庞杂,以至于即使后来的“血友吧事件”,“魏则西事件”发生,使得百度贴吧失信于社会,用户量开始下滑;以及现今的抖音,今日头条,微博等各类社交平台的崛起抢走了贴吧相当一部分的用户,贴吧的用户量依然不可小觑,产生的信息量也依然巨大。这些信息中不乏许多有价值的信息,想要高效的获取这些信息就需要有好的检索方法。通用的搜索引擎检索出来的信息有一定的局限性,它的目标是尽可能大的网络覆盖率,返回的结果通常有大量我们不需要的内容,因此有必要开发出专门针对贴吧的聚焦爬虫,从而更高效迅速的获取我们所需要的信息。
第2章 需求分析
引言
本章介绍了项目的需求分析,主要是对功能需求的分析和对运行环境的分析,需求分析决定了本项目开发的方向,并带有对项目规模的预测。
2.1功能需求分析
贴吧爬虫信息系统是一个对武汉理工大学贴吧的内容进行检索的小型搜索引擎。目的在于方便学生检索贴吧内容。因此贴吧爬虫信息系统的主要功能是:
1、信息检索:对贴吧帖子进行检索,可以选择在特定贴吧里检索或是某几个贴吧或是全部贴吧里检索,可以按照关键词检索,可以按照用户名检索。
2、信息整理:信息检索结果的过滤、删除、排序,可以按时间,相关性,回复量排序。
3、信息展示:信息检索结果的浏览、导出并保存等。
2.2 运行环境分析
作为一个贴吧爬虫信息系统,最重要的功能就是信息的爬取和信息的展示。本系统拟采用Scrapy Django框架,用Scrapy爬取信息;用Django搭建web服务器,以ajax技术实现与用户的动态交互,从而进行信息展示。在系统开发中还会涉及到数据的保存,拟使用Django框架自带的Sqlite3数据库。
为了方便开发,本项目采用作者常用的Windows操作系统进行开发。但是经过一番学习我了解到,python支持的操作系统很多,主流的Windows,MacOS,Linux都是支持的。对应的,本项目的运行环境可以是Windows,MacOS,Linux,但是本系统采用采用python 3.6.3版本,需要Windows 7 及以上的Windows版本。
本项目是一个轻量级项目,存放项目所占磁盘存储空间不大,最占磁盘存储空间的操作就是数据库中存放数据,在爬取了几页贴吧数据后进行估算,仅考虑文字的话,平均贴吧每页数据有86KB,截至当前(2019年5月25日),贴吧有5495页帖子,经计算大约会有460MB数据,由于贴吧渐渐走向没落,帖子的增长速度并不算快,存储这些数据需要的外存不会超过50G。
本项目运行时所占内存不大,即使只有1G内存也足矣。
总结下来,本系统要求的运行环境如下:
操作系统:Windows 7及以上
内存:大于1G
外部存储空间(硬盘):50G以上
需要python版本:3.6.3
需要的依赖库:Django,Scrapy,requests,retrying,scrapy-djangoitem,lxml
本章小结
本项目要实现的功能其实并不复杂,就是很朴实无华的爬取数据,存储数据,查询数据库,web页面显示。项目运行环境要求也不高。
第3章 系统设计
引言
本章介绍了在系统开发时的一些尝试,系统设计的过程,遇到的问题等等。并重点介绍了组成贴吧爬虫信息系统的三个模块:爬虫模块、数据库管理模块、前台展示模块。
3.1系统总体设计
要实现贴吧信息检索功能,可以选择两种方式,一种是,在线爬取的方式,即建立爬虫,输入要检索的内容,然后开始爬取,把想要查询的内容下载保存下来,这种方式可以不需要建立数据库,有检索需求时直接爬取贴吧就行了,逻辑简单,实现容易。美中不足的是这种方式肯定会受到网络延迟,网络传输速度的制约。
图3.1 在线爬取方案
第二种是,先把贴吧的所有数据下载保存到本地文件或是数据库,检索时从本地数据库查询,再把查询结果通过网页显示,这种方式肯定会比第一种方式在查询上速度快很多,但是需要大量存储空间存储数据到本地,还会遇到数据库更新的问题。
经过初步的尝试,第一种方案被否定,原因是检索的耗时过长。
经过几次调试发现,贴吧的帖子数量实在太多,仅武汉理工大学吧的帖子就有 9004687条,也就是900多万条帖子。笔者将在线爬取程序运行了半小时左右,也才遍历了10万条左右帖子,要通过这种方式遍历贴吧的帖子,恐怕效率极低。并且调试时只是仅仅只遍历了帖子的标题而已,若是一条可怜的无人回复的帖子,标题文字数量约占整个帖子总文字数量的1/5,若是一条活跃的帖子,引起大家广泛的回复,标题文字数量可能会占整个帖子总文字数量的百分之一千分之一甚至万分之一。也就是说要是把帖子内容也遍历一遍的话,耗时可能会增加上百倍!尝试了逐条加载的解决方法,也就是把已经搜索到的数据先显示出来,边后台搜索边前台展示,可是缓慢的搜索速度仍是这种方式的致命伤,最后不得不放弃转而寻找别的方式。
综上所述,本系统采用上述的第二种方式。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: