基于深度学习的人脸识别毕业论文
2020-04-08 14:30:11
摘 要
传统的人脸识别方法由于姿态、光照、遮挡及表情的变化这些因素的影响而难以提高识别精度。而卷积神经网络通过多层卷积操作提取图像的抽象特征,基于大型的数据集进行训练,实现复杂的函数逼近,得到更具判别性和鲁棒性的模型。
在实际的应用中,人脸识别的身份不一定每次都在训练集中,此时无法通过最后一层预测属于识别的身份属于哪一类且在大型的数据集上测试的精度不高。对此,本文研究了基于深层卷积神经网络模型提取深度判别性和聚类性特征的方法。主要研究内容如下:
(1)构建浅层的卷积神经网络模型,比较卷积核尺寸和卷积层数对于模型识别精度的影响。
(2) 先使用Softmax和CenterLoss联合监督的深层inception-resnet-v1模型和前述浅层模型提取深度特征,再用两种深度特征对支持向量机和朴素贝叶斯模型进行训练,然后测试模型识别的精度。识别的结果表明浅层模型提取的深度特征的具有一定的判别性,而深层inception-resnet-v1模型提取的深度特征具有更强的判别性。
(3)通过k-means算法来观察两种模型在训练数据集上提取的特征的聚类性,标记聚类中心的身份后。在测试数据集上预测输入数据的身份为距离它最近的中心点的身份,然后得到测试精度。得出浅层模型提取特征具有一定的聚类性,但测试精度不高,深层模型提取的特征具有更明显的聚类性,且测试精度更高。当识别图像的身份类别被包含在数据集中时,可以利用特定的特征匹配算法来匹配深度特征进而判别人脸身份。
(4)由于深度特征在欧几里德空间的聚类性,可以依据欧几里德空间的距离设置阈值来判断人脸对是否属于同一身份。使用lfw数据集上面的6000对人脸对依据ROC、AUC、识别精确度来评价提取深度特征的模型的识别性能。得出深层模型的识别性能良好且远高于浅层模型。因此当识别人脸的身份类别不在训练集中时,可以用深层inception-resnet-v1卷积神经网络模型提取的深度特征来识别人脸对的相似度进而判别人脸对是否属于同一身份。
关键词:深度学习,人脸识别,卷积神经网络,深度特征
Abstract
The traditional face recognition method is difficult to improve the recognition accuracy due to the influence of factors such as posture, lighting, occlusion and expression change. With the development of deep learning, convolutional neural networks have been introduced into the field of face recognition. The convolutional neural network abstracts the abstract features of the image through a multi-layer convolution operation, trains on a large data set, realizes a complex function approximation, and obtains a more discriminative and robust model
However, in an actual application, the identity of the face recognition may not always be in the training set. At this time, it is impossible to predict which class belongs to the identified identity through the last layer. And the accuracy of testing on large data sets is not high. In this regard, this paper studies a method for extracting deep discriminative and clustering features based on a deep convolutional neural network model. The main research content is as follows:
(1) Constructing a shallow convolutional neural network model to compare the effect of convolution kernel size and convolutional layer number on model recognition accuracy
(2) Firstly, the deep inception-resnet-v1 model jointly supervised by Softmax and CenterLoss and the aforementioned shallow model are used to extract deep features. Then, two deep features are used to train the support vector machine and the naive Bayesian model, and then the accuracy of the model identification is tested. The recognition results show that the deep features extracted by the shallow model have a certain discriminability, while those extracted by the deeper model have a stronger discriminability.
(3)The K-Means algorithm was used to observe the clustering of the features extracted by the two models on the training dataset and label the identity of the clustering center. Predict the identity of the input data on the test data set as its nearest center point, then get the test accuracy. It turns out that the extracted features of the shallow model have a certain degree of clustering, but the testing accuracy is not high. The features extracted by the deep model have more obvious clustering and higher testing accuracy. When the identity category of the image is included in the data set, a specific feature matching algorithm can be used determine the face identity.
(4) Due to the clustering of deep features in the Euclidean space, given a pair of images, a threshold can be set based on the distance of the Euclidean space to determine whether they belong to the same identity. Using 6,000 pairs of human faces in the LFW dataset to evaluate the performance of the recognition based on ROC, AUC, and recognition accuracy. It turns out that the recognition performance of the deeper inception-resnet-v1 model is good and much higher than the shallow model. Therefore, when the class of the face to identify is not in the training set, the deep feature extracted by the deeper inception-resnet-v1 convolutional neural network model can be used to identify the similarity of the face pair to determine whether the face pair belongs to the same identity.
Key words: deep learning, face recognition, convolutional neural network, deep features
目录
第1章 绪论 1
1.1 研究背景及意义 1
1.2人脸识别的算法流程 2
1.3人脸识别国内外研究现状 2
1.4人脸识别的难点 3
1.5本文结构安排 3
第2章 人脸识别的浅层CNN网络结构研究 5
2.1 人脸图像数据集的优选及其预处理 5
2.1.1人脸图像数据集的优选 5
2.1.2 人脸检测与图像预处理 6
2.2人脸识别神经网络构建 6
2.2.1神经网络的结构 6
2.2.2神经网络训练 8
2.3人脸识别卷积神经网络构建 9
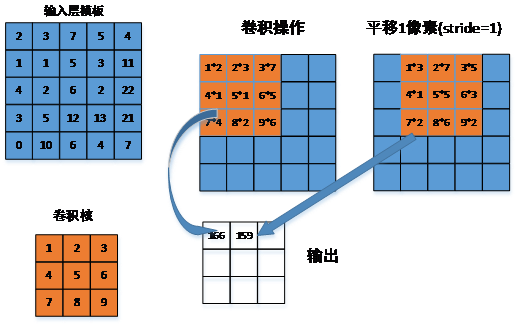
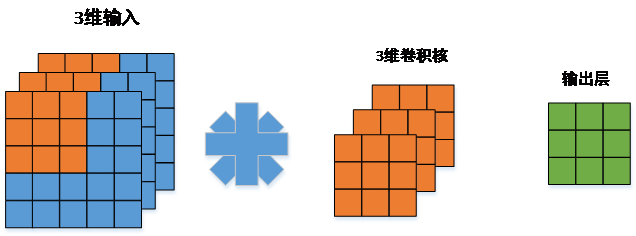
2.3.1输入图像的卷积 9
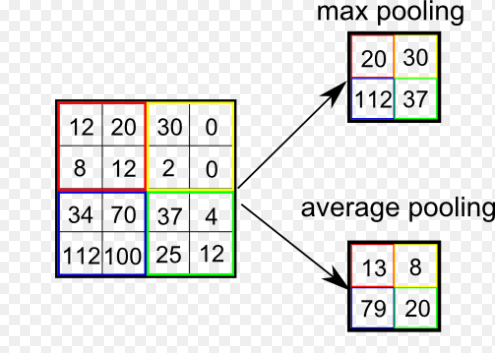
2.3.2输出层的池化 11
2.3.3深度特征 11
2.3.4过拟合与正则化 12
2.4浅层CNN的性能比较 14
2.4.1卷积核尺寸的比较实验 14
2.4.2 CNN层数的比较 16
2.5本章小结 17
第3章 深层CNN人脸特征提取及其聚类性分析 18
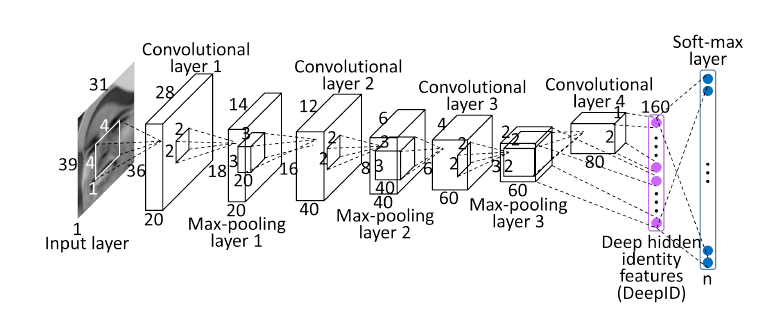
3.1人脸识别深层模型Inception-resnet-v1的构建 18
3.1.1模型的结构 18
3.1.2 CenterLoss联合监督训练 21
3.2人脸深度特征的判别性 23
3.2.1 基于支持向量机的深度特征分类器 23
3.2.2基于朴素贝叶斯的深度特征分类器 25
3.2.3实验结果 27
3.3人脸深度特征的聚类性 27
3.3.1基于k-means算法的深度特征聚类性 27
3.3.2基于欧几里得空间的聚类性实验与结果分析 28
3.3.3人脸相似度测定 29
3.4本章小结 30
第4章 基于LFW数据集的人脸对识别 31
4.1人脸对数据集介绍 31
4.2人脸对识别性能评价指标 31
4.2.1正确率测试 31
4.2.2实验ROC曲线 32
4.3实验设计与结果分析 32
4.4本章小结 33
第5章 总结与展望 34
5.1总结 34
5.2展望 35
致谢 36
参考文献 37
第1章 绪论
1.1 研究背景及意义
人的身份信息在社会生活中代表人的独一无二的身份,随着信息技术的发展,身份信息发挥的作用越来越重要,如何安全、有效的识别身份信息已成为一项重要的研究课题。传统的钥匙、磁卡等物品,虽然可以代表身份信息,但是可以被复制、盗取,也容易遗失,这类物品遗失后不仅要花钱和时间来补办,被盗或者复制后更可能带来经济财产的严重损失。信息技术的发展使得利用生物信息识别身份成为可能,每个人的生物识别信息是独特的,不能被复制,也不会遗失的,因此以其不可复制性、方便携带、不会遗失等优点,越来越得到人们的青睐。
生物识别信息包括人的指纹、人脸、视网膜、声音等,其中人脸具有个体差异性大、获取成本低廉、方便采集等优点,因此具有很高的研究价值和实际作用。人脸识别是指先采集人脸的图像,用特定的算法检测人脸并提取人脸的特征,然后对人脸的特征进行识别的过程。
人脸识别的研究起源于20世纪六十年代末,随着计算机技术以及人脸识别算法的发展,已经取得了长足的进步。尤其是近来随着深度学习、人工智能技术的兴起,人脸识别更是取得了重大的突破。现今人脸识别已经广泛应用与人们的生活的各个领域,其中新兴的领域主要有:
(1)刷脸开户及支付。将预先采集的人脸图像数据存储起来,在以后进行身份验证的时候再提取人脸的图像与已经存储的图像进行对比判断身份。在现今的电子商务中,密码支付容易被遗忘且有泄漏的可能,而指纹支付又需要灵敏的传感器,相比之下,刷脸支付要更加方便可靠,因此也得到越来越广泛的应用。百度钱包、支付宝等支付软件已经逐步推行刷脸支付技术。
(2)企业门禁系统。许多企业采用的门禁系统公式指纹识别,公司员工需要到达指定地点进行签到,人数较多时还需要排队。而人脸识别可以主动抓拍人脸,公司员工无需进行签到打卡,节约了时间。
(3)视频检索。人脸识别可以在监控视频中智能的分析人物的属性和身份,检索犯罪分子,提前预防安全事故的发生。此外,视频检索、人脸识别的应用也为公安局破获案件、抓捕犯罪分子提供帮助。各大安防企业也相继推出人脸识别系统。
此外,人脸识别的研究也积极推动着图像处理、深度学习以及人工智能的进步。由此可见,人脸识别技术具有很大的研究和应用价值。
1.2人脸识别的算法流程
宽泛来讲,人脸识别包括人脸采集与预处理、人脸检测、人脸校准、识别4个过程。
人脸采集和预处理是指通过拍照、录制视频或者从网上下载图片或视频文件来得到人脸的图像,并且对图像进行特定的预处理使其符合一定的要求。
人脸检测是指检测给定图像或视频帧中是否存在人脸,如果存在则给出人脸的大小尺寸和位置。人脸检测算法的性能的好坏直接影响后续的人脸特征提取和识别的过程。
人脸校准是指确定人脸中的各个基准点,比如瞳孔、鼻尖、嘴角、眼角等的坐标,然后进行坐标变换和人脸切割,得到校正之后的图像。经典的人脸校正的算法有(Cootes et al.,1995,2001)。
特征提取是人脸识别的关键问题,是指将人脸数据表示成一定的特征数据,然后对特征数据进行判别和区分。特征表示需要包含两个特点:判别性和鲁棒性,判别性是指特征表示对于不同身份的人脸之间的差异具有敏感性,鲁棒性是指对于相同人脸的识别对于遮挡、光照、姿势等变化所得到的识别结果具有一定的不变性。
最后识别是指对于提取到的特征用特定的算法进行识别身份的过程。
1.3人脸识别国内外研究现状
传统的人脸识别方法有很多,有基于模板匹配的方法,将人脸图像与数据库中的模板匹配找到最相似的模板;基于几何特征的方法,将面部器官的形状及其位置进行检测比较,实现识别;基于代数分析的方法,例如主成份分析法(PCA)[1]、线性判别分析法(LDA)[2]、隐马尔科夫法(HMM)等;基于稀疏表示[3]的人脸识别方法,例如MPR,SRC算法等;然而,姿态、光照、遮挡及表情的变化这些因素的影响使得传统人脸识别方法的精度难以提高。
随着深度学习的发展,卷积神经网络(CNN)被引入人脸识别领域,CNN采用多层卷积、非线性网络结构,提取人脸图像的特征后利用前馈神经网络学习,得到识别性能更高的模型,并且利用该模型可以提取判别性更强的特征,在互联网海量人脸数据集的支撑下,借助GPU组成的运算系统,基于深度学习的人脸识别已经在精度和速度上都已经超过传统的方法,甚至超过人类的辨识水平。
2014年,Facebook提出DeepFace[4]卷积神经网络框架并将此框架在大型数据集上进行训练,然后在LFW数据集上分类测试获得了97.35%的精度,性能已经与人工识别接近。而经典的Eigenface人脸识别算法在LFW上只能达到60%的识别率。香港中文大学的DeepId[5]网络改进了CNN,联合了局部和全局特征,使用联合贝叶斯处理深度特征以及利用识别和认证两种监督信息训练,精度达到99%以上。牛津大学的视觉几何组使用VGG[6]网络用了较大的输入图像和深层网络拓扑结构获得了98.95%的精度。Google的FaceNet[7]网络采用三元组损失函数作为监督信息在大小仅200M的人脸数据集上进行训练,在lfw上取得了99.63%的精度,之后百度[8]甚至得到了99.77%的准确率。此外,CNN的网络的层数不断的加深,VGG[6]的卷积网络有16层,FaceNet[7]的网络有22层,ResNet[9]网络已经达到152层。
1.4人脸识别的难点
随着人脸识别技术的发展,它在学术界和产业界的关注度日益提升,在日常生活中人们对于人脸识别技术的越来越广泛的使用不断推动着人脸识别的发展。但目前人脸识别技术还不能满足日益增长的实际应用的需求,它主要面临的挑战有:
(1)光照和姿态引起的人脸变化
由于图像处理技术是基于图像的像素进行处理计算的,获取照片时光照强度会影响像素值的大小,这可能导致同一个人的不同光照下的照片的像素值差异较大而使最终的识别结果差异较大而降低人脸识别的性能。拍照时人脸的姿态可以是任意的,不同的姿态会使得图像中像素的空间分布不同,使得人脸检测和定位的困难,或者导致原本适应一种姿态的识别技术在另一种姿态下就没什么作用了。
(2)数据规模庞大计算复杂度高
在深度学习应用到人脸识别以前,传统的人脸识别方法收到计算复杂度的限制,在小数据集上面表现良好,但是在大规模数据集性能就较差,泛化能力较差。深度学习具有较强的泛化能力,但是需要训练的数据集也十分庞大,其泛化能力也收到训练集的影响。世界上有60亿人口,不同地区、不同肤色的人的面部差异也比较大,训练数据集无法包含所有人,这最终会对其泛化能力有很大的影响。
随着深度学习网络的层数和参数的增加以及数据集的增大,计算的复杂度也
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: