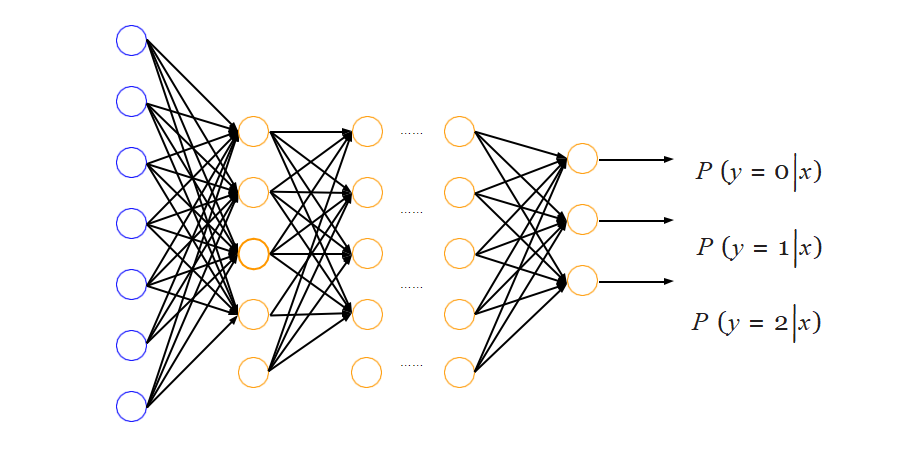
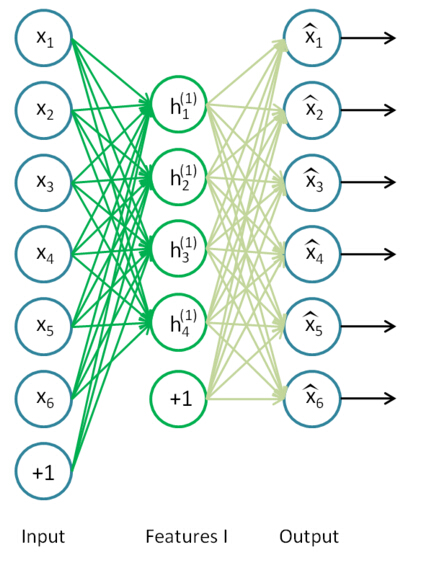
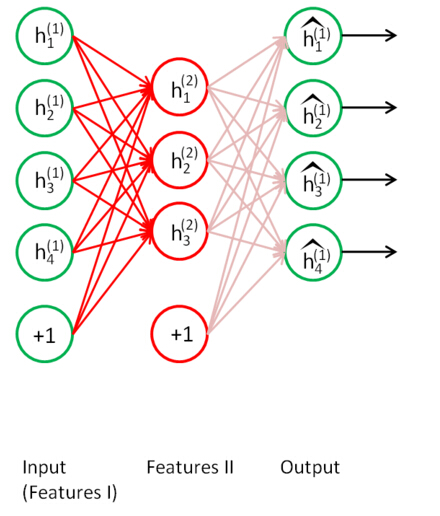
机器学习在手写图像识别中的应用毕业论文
2020-04-07 14:08:57
摘 要
人工智能目前引领了新一代的技术浪潮,引起了科学界和产业界的广泛关注。作为人工智能的一个重要分支,机器学习的理论和技术也已取得巨大发展,其中深度学习是其当前的核心代表之一。作为深度学习模型的一种典型结构,以自编码器为基本组成部分的栈式自编码神经网络在无监督学习及非线性特征提取过程中扮演着至关重要的角色。在本毕业论文中,首先在介绍几种常见深度学习模型的基础上,重点介绍了自编码器的基本概念、原理及其几种子类型。然后,详细介绍了堆栈自编码神经网络的结构、特征提取方式及其训练过程。然后,在Matlab平台上实现堆栈自编码神经网络的算法,并基于MNIST数字手写数据库对其性能进行了验证和分析。最后,在简要分析深度栈式自编码神经网络目前存在的问题之后,对其未来发展趋势进行了展望。
关键词:深度学习;自编码器;堆栈自编码器;手写图像识别
Abstract
Artificial intelligence has led a new generation of technology wave, which has attracted wide attention from the scientific community and industry. As an important branch of artificial intelligence, the theory and technology of machine learning have also been greatly developed, and deep learning is one of its core representatives. As a typical structure of deep learning model, the stall code neural network with self encoder as the basic component plays a vital role in the process of unsupervised learning and nonlinear feature extraction. In this thesis, on the basis of introducing several common deep learning models, the basic concepts, principles and several seed types of the self encoder are introduced. Then, the structure, feature extraction and training process of the stack self code neural network are introduced in detail. Then, the algorithm of stack self code neural network is implemented on the Matlab platform, and its performance is verified and analyzed based on MNIST digital handwritten database. Finally, after a brief analysis of the existing problems of deep stacked self code neural network, the future development trend is prospected.
Key words: deep learning; self encoders; stack self encoders; handwritten image recognition
目录
第一章 绪论 1
1.1 深度学习的起源和发展 1
第二章 深度学习的经典模型 4
2.1 多层感知机 4
2.2 循环神经网络和递归神经网络 5
2.3 卷积网络 6
2.4 受限玻尔兹曼机 7
2.5 深度信念网络 8
2.6 生成式对抗网络 8
2.7 自编码器 9
第三章 自编码器类型 10
3.1 降噪自编码器 10
3.2 变分自编码器 10
3.3 稀疏自编码器 11
第四章 栈式自编码神经网络 13
4.1 栈式自编码神经网络的结构 13
4.2 栈式自编码神经网络的训练过程 14
4.3 栈式自编码神经网络实验 16
第五章 深度学习的未来 20
5.1 深度学习未来应用领域 20
5.1.1 语音识别 20
5.1.2 图像识别 20
5.1.3 自然语言处理 20
5.2 深度学习研发面临的重大问题 20
5.2.1 理论问题 20
5.2.2建模问题 20
5.2.3工程问题 21
5.3 总结 21
参考文献 22
感谢语 23
附录1:程序 24
第一章 绪论
1.1 深度学习的起源和发展
“人工智能”一词最初是由达特茅斯学会于1956提出的。其目的在于让机器完成人类脑力才能完成的“复杂工作”。经过长年累月的研究,许多原理被这一领域的研究者们发现,人工智能的内涵也随之不断扩大。现在,人工智能包括很多领域,如计算机视觉识别,机器学习,语音识别……由于这个研究领域的范围很大,其研究人员必须具备心理学知识、计算机知识、甚至哲学知识。目前,研究人工智能的主要材料手段和能够实现人工智能的机器都是计算机。人工智能的历史与计算机科学和技术的发展史有关。从人工智能出世以来,其技术和理论一天比一天成熟,应用的领域也越来越大。除了涉及到计算机学科外,还囊括了生物学、语言学、控制论、心理学、信息理论、医学、仿生学和哲学。在未来,人工智能不仅可以模拟人思考过程,像人类一样思考,而且可以超过人类的智慧,其科技产品成为人类智能的“容器”。
2017年,在中国的政府工作报告中第一次出现,意味着这个61岁的“新生儿”随着则政策环境的进一步优化,将迎来快速发展的机会。在这个大数据时代和互联网时代,人工智能正在影响并且改变着我们的生活。打开手机,语音识别可以执行人的指令;打开语音输入法,可以实现语音文本的转换;打开百度,我们可以看到网页只能推荐的内容。中国在人工智能领域取得了一些成就。艾媒咨询数据显示,2016年度我国人工智能产业规模增长率达到43.3%,超过100亿元,预计2017年达到153亿元,并于2019年增长至345亿元。
在过去两年中,以百度、腾讯和阿里为代表的中国科技巨头一直在人工智能领域工作。百度在人脸识别领域获得了世界性的认可。在两个最权威的国际人脸识别技术评估中,获得了一等奖,腾讯推出了一个自动新闻写作机器人。中国的计算机视觉识别、语音识别等领域达到了国际领先水平。有大批具有竞争力的企业和科研院所在中国涌现,并有良好的发展基础。
对此,媒体咨询分析人士认为,中国的人工智能行业起步较晚,但在领域布局、技术研究和其他基础设施方面都在进行中。随着科技、制造等技术巨头的布局,AI产业规模将进一步扩大。
据统计,截至2017年底,中国人工智能领域已有近1000家初创企业,主要分布在视频大数据、大数据智能分析、智能医疗、无人驾驶、人脸识别等领域。
在人工智能领域,最成熟的语音识别已经达到了99。准确率为7%。机器人已经能够说话、听、说、读、写和翻译,而AI正走进普通人的家。
机器学习属于人工智能的一个学习领域,它是通过使机器能够从大量的历史数据中学习规则来进行新样本的智能识别或预测未来的算法,因为其在人工智能领域应用范围广,影响较大,在很多情况,几乎成了人工智能的代名词。从上世纪80年代以来,机器学习的发展经历了两个阶段:浅层学习和深层学习。
20世界80年代末,BP反向传播算法的发明[1],给机器学习带来了希望,而且提出来基于统计模型的机器学习浪潮,这种浪潮一直持续到今天。人工神经网络从大量的历史数据中学习统计规则来进行新样本的智能识别和对未知事件的预测均是通过BP算法实现。此时人工神经网络也被称为多层感知器。由于多层网络的训练困难,大多数实际使用的是一个只有一层隐层节点的浅层。
90年代开始,又有各种浅层机器学习模型被提出,如Boosting[2]、支持向量机、最大熵方法[3]等。其中支持向量机和Boosting被看做具有隐含层节点,最大熵法可以看做无隐层节点。这些模型在理论分析和应用上都取得了很大的成功。因当时训练方法没有太多的经验和技巧,理论分析难度较大,多层次的人工神经网络一直没有受到研究者们的重视。
人们受到脑神经系统具有丰富层次结构的启发,深度学习应用而生,深度学习中,一般网络都有很多层,随着网络层数的增多,训练网络采用的梯度会下降,这样梯度弥散的现象会在低层网络中出现,这一现象导致深度学习一直没能实现大的跨越。2006年,来自多伦多大学的教授Hinton的一篇文章[4]改变了这一现象,他和他的学生在国际的学术刊物《科学》上发表了一篇文章,在深度学习的领域掀起一波学习热潮。文章中提到两个主要观点:(1)多隐层的人工神经网络特征学习能力很高,提取到的特征更清晰,便于进一步进行分类;(2)深度学习在训练上遇到的困难,可以通过对每一层进行初始化,进行解决,每一层的初始化可利用无监督学习来实现。
2011年,谷歌语音识别的研究者和微软研究院在 语音识别领域实现了近十年的重大技术突破,采用深度神经网络技术把其误码率降低了25%左右。第二年深度神经网络技术在图像识别领域也有非常大的进展,在国际最大的图像识别数据库评测上,将错误率从26%降到了15%。同一年,深度神经网络技术也被应用于制药企业的药品活性预测问题中,并取得了史无前例的结果,纽约时报当时报到了这一重要成就。
在2012,Hinton的研究团队,在提出深度神经网络后的第六年,使用卷积网络将错误率降低到15.3%。这个网络的结构叫做亚历克斯网[5]。
2012年,在IMANETET ILVRC2013竞争中,前20名团队采用了深度神经网络技术,深度模型或卷积网络被用来进一步优化网络的结构,效果前所未有。冠军是纽约大学的Rob Fergus研究团队。前五的团队将错误率降低到11.20%,这种模型被称为CalrIFAI[6]。
2014年这项技术进一步取得进展,GoeleNET[7]在ILVRC2014的竞赛中,不可思议地增加了卷积网络的层数,超过了20层,将Top5的错误率降到了6.66%,成为了当年最大的赢家。随着网络层次的增加,通过反向传播来预测误差也越来越困难。因为误差预测是从顶层传输到底层的,传到底层的误差会非常小,所以,很难进行基础参数的更新。GoeleNET使用的策略是把监督信号添加在中间层,这样缩短传播距离,提高了基础参数的更新效率。
2014年5月,百度聘请斯坦福著名教授吴恩达出任首席科学家,在硅谷成立了一个新的人工智能实验室。2014年1月,谷歌收购了深度学习的公司DeepMind。因为深度学习在学术界和工业界带来的巨大影响,麻省理工学院科技评论将其列为2013年度世界十大技术突破。
第二章 深度学习的经典模型
2.1 多层感知机
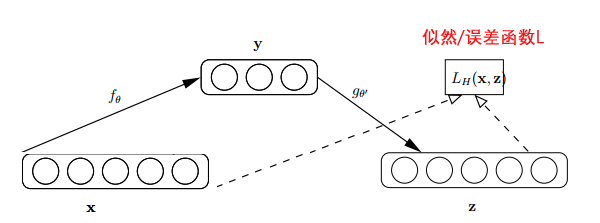
感知机是人工神经网络中的一种典型结构,如图 1所示,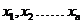 为输入变量,
为输入变量,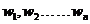 为权重,
为权重,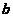 为偏置,
为偏置,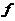 为预知函数。每一个输入都有自己的权重,然后加上一个偏置,经过函数得到输出的结果。
为预知函数。每一个输入都有自己的权重,然后加上一个偏置,经过函数得到输出的结果。
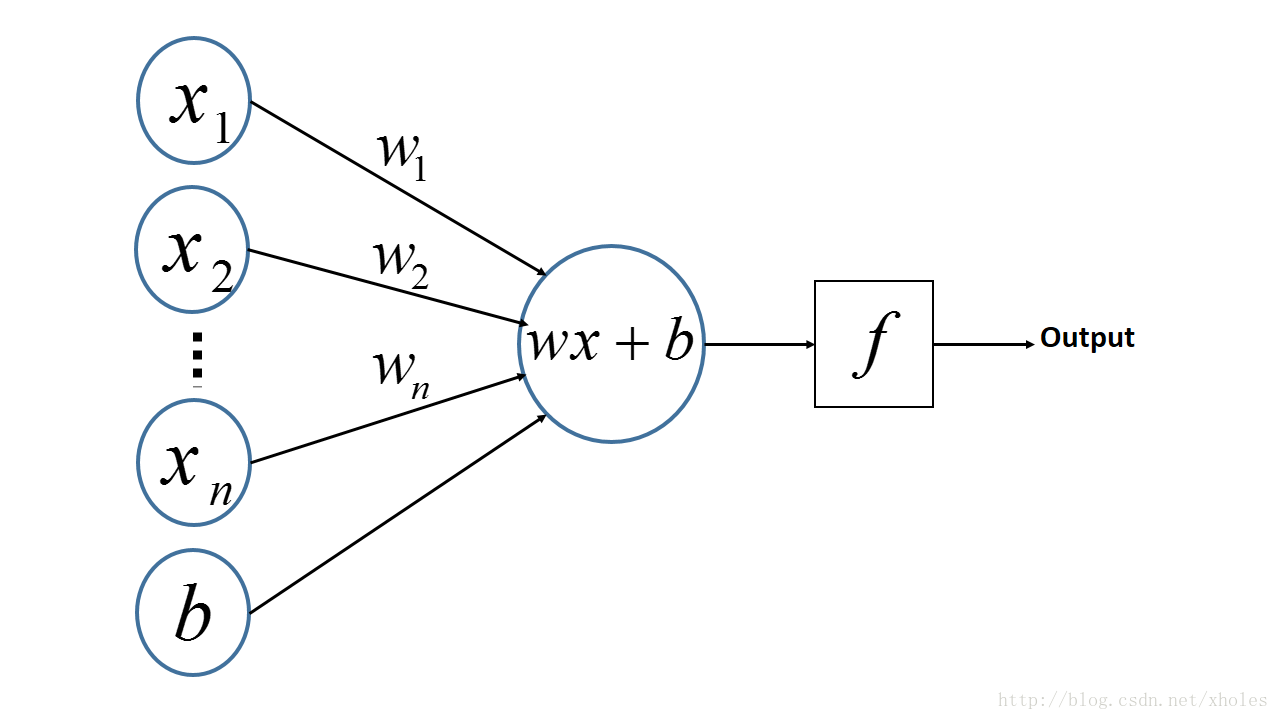
图 1 感知机神经网络模型
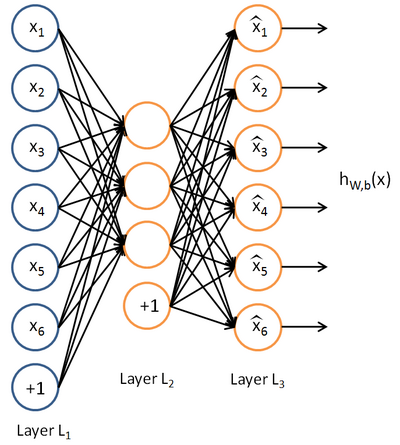
多层感知机[8]是由感知机推广而来的,其一个重要特点就是多层,将上面多个感知机集成。第一层为输入层,最后一层为输出层,中间层叫隐层。隐层的数量可多可少,其结构如图 2,图中结构只有一个隐层,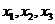 为输入层,
为输入层, 为偏神经元。
为偏神经元。
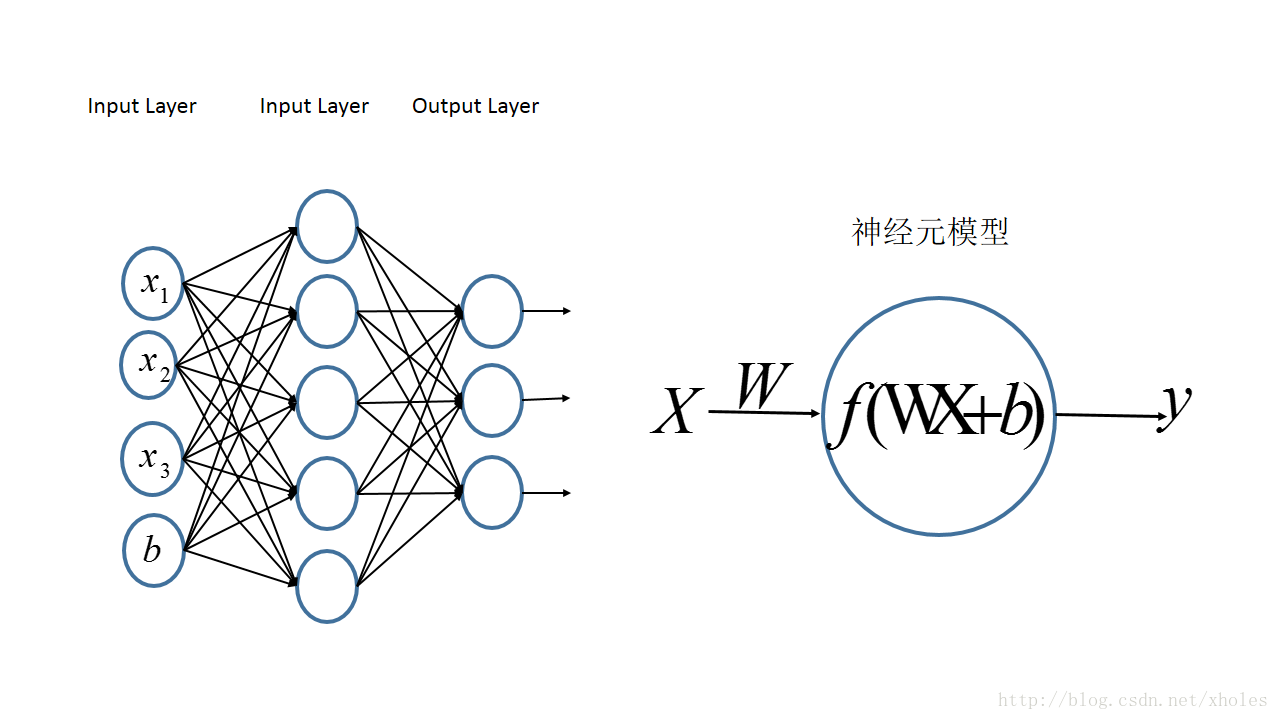
图 2 多层感知机模型结构图
2.2 循环神经网络和递归神经网络
循环神经网络是一种对序列数据建模的神经网络。递归神经网络是一种可以对时间或结构进行递归的神经网络,两者都可以用于处理有序列的问题,两种神经网络均可成为RNN。其结构如图 3:
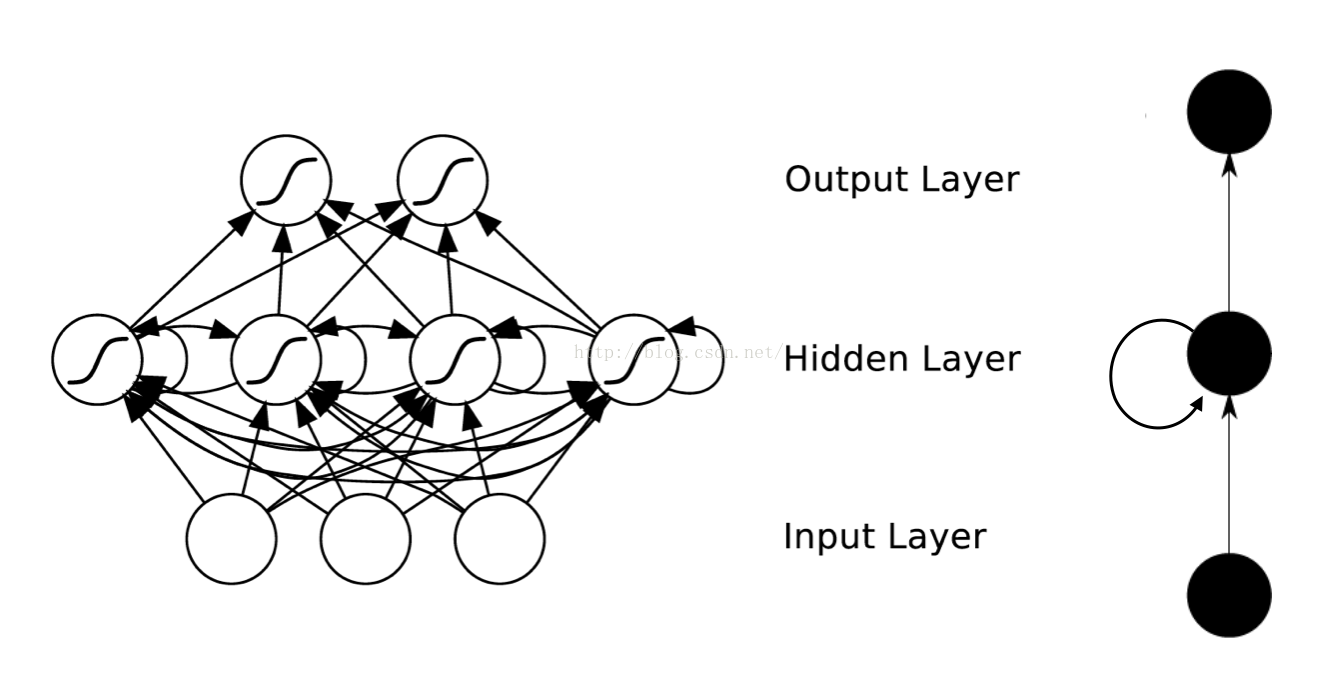
图 3 循环/递归神经网络结构
传统神经网络是输入层-隐藏层-输出层,在层与层之间进行连接的,在每层之间的节点是没有连接的,这两种网络结构在中间隐藏层之间有连接,意味着,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。和传统的深度学习模型中隐层单元彼此间是完全对等的不同,这里隐层从左向右是有时序的。
举个最简单的例子,我们预测股票走势用RNN就比普通的DNN效果要好,原因是股票走势和时间相关,今天的价格和昨天、上周、上个月都有关系。而RNN有“记忆”能力,可以“模拟”数据间的依赖关系。
为了加强这种“记忆能力”,人们开发各种各样的变形体,如非常著名的Long Short-term Memory,用于解决“长期及远距离的依赖关系”。如图 2所示,左边的小图是最简单版本的循环网络,而右边是人们为了增强记忆能力而开发的LSTM。
同理,另一个循环网络的变种 - 双向循环网络[9]也是现阶段自然语言处理和语音分析中的重要模型。开发双向循环网络的原因是语言/语音的构成取决于上下文,即“现在”依托于“过去”和“未来”。单向的循环网络仅着重于从“过去”推出“现在”,而无法对“未来”的依赖性有效的建模。
递归神经网络和循环神经网络不同,它的计算图结构是树状结构而不是网状结构。递归循环网络的目标和循环网络相似,也是希望解决数据之间的长期依赖问题。而且其比较好的特点是用树状可以降低序列的长度,从 降低到
降低到 ,熟悉数据结构的朋友都不陌生。但和其他树状数据结构一样,如何构造最佳的树状结构如平衡树/平衡二叉树并不容易。
,熟悉数据结构的朋友都不陌生。但和其他树状数据结构一样,如何构造最佳的树状结构如平衡树/平衡二叉树并不容易。
其主要应用于语音分析,文字分析,时间序列分析。主要的重点就是数据之间存在前后依赖关系,有序列关系。一般首选LSTM,如果预测对象同时取决于过去和未来,可以选择双向结构,如双向LSTM。
2.3 卷积网络
卷积网络(CNN)是一种深度前馈人工神经网络,已经成功地应用于图像识别,是深度学习领域非常经典的模型,从某种意义上卷积网络的出现和应用极大地推动了深度学习的浪潮。此外,卷积网络也是一个很好的计算机科学借鉴神经科学的例子。卷积网络的本质是在多个空间位置上共享参数。
卷积运算是一种数学计算,和矩阵相乘不同,卷积运算可以实现稀疏相乘和参数共享,可以压缩输入端的维度。和普通DNN不同,CNN并不需要为每一个神经元所对应的每一个输入数据提供单独的权重。
与池化相结合,CNN可以被理解为一种公共特征的提取过程,不仅是CNN大部分神经网络都可以近似的认为大部分神经元都被用于特征提取。
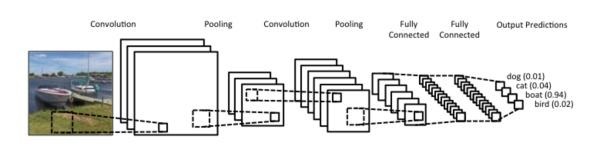
图 4 卷积、池化过程
以图 4为例,卷积、池化的过程将一张图片的维度进行了压缩。从图示上可以看出卷积网络的精髓就是适合处理结构化数据,而该数据在跨区域上依然有关联。
2.4 受限玻尔兹曼机
玻尔兹曼机是一个基于能量的模型,一般用最大似然法进行学习。但更多的是适合理论推演,有相当多的实际操作难度。
受限玻尔兹曼机更实用,受限玻尔兹曼机是玻尔兹曼机的一种特殊拓扑结构,它是一种对称耦合的随机反馈型二值单元神经网络如图 5,它由两部分构成,由可见层和隐藏层层组成,网络节点分为可见单元 和隐单元
和隐单元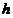 ,用可见单元和隐单元来表达随机网络与随机环境的学习模型,通过权值
,用可见单元和隐单元来表达随机网络与随机环境的学习模型,通过权值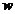 表达单元之间的相关性。
表达单元之间的相关性。
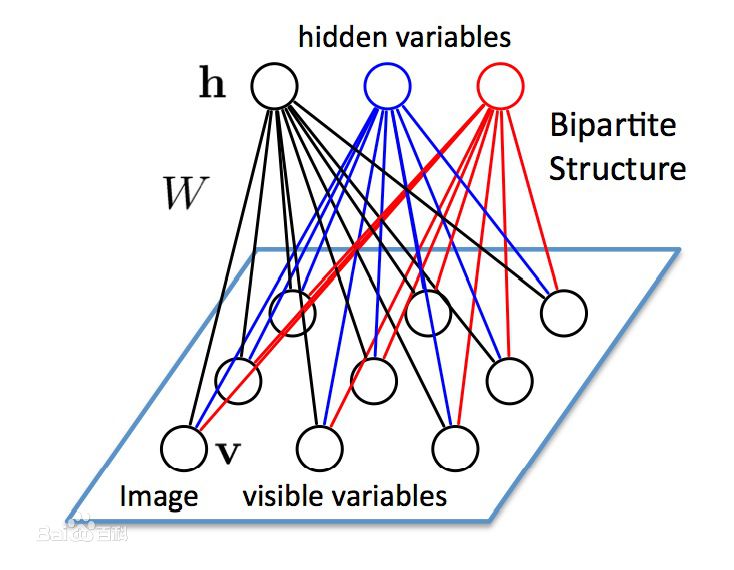
图 5 玻尔兹曼机结构
现在该模型已经成功应用于协同滤波、分类、降维、图像检索、信息检索、语言处理、自动语音识别、时间序列建模、文档分类、非线性嵌入学习、暂态数据模型学习和信号与信息处理等任务。
2.5 深度信念网络
深度信念网络(DBN)是Hinton在06年提出的,主要有两个部分: 堆叠的受限玻尔兹曼机和一层普通的前馈网络[10]。
DBN最主要的特色可以理解为两阶段学习,阶段1用堆叠的受限玻尔兹曼机通过无监督学习进行预训练,阶段2用普通的前馈网络进行微调。
神经网络的精髓就是进行特征提取。与自编码器相似,堆叠的受限玻尔兹曼机有数据重建能力,及输入一些数据经过受限玻尔兹曼机还可以重建这些数据,这意味着学到了这些数据的重要特征。
将受限玻尔兹曼机堆叠的原因就是将底层首先玻尔兹曼机学到的特征逐渐传递到上层,逐渐抽取复杂的特征。比如图 6从左到右就可以是低层RBF学到的特征到高层RBF学到的复杂特征。在得到这些良好的特征后就可以用第二部分的传统神经网络进行学习。

以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: