一站式校园招聘信息平台开题报告
2020-04-07 10:15:05
1. 研究目的与意义(文献综述)
| 1、设计目的及意义(含国内外的研究现状分析) 目前,在国内外有着大量的信息发布平台,其中所谓招聘信息平台,即指运用互联网及相关技术,帮助雇主和求职者完成招聘和求职的网络站点。各大高校的毕业生都是这些网站平台的使用者,根据2017年度北森校园招聘大数据分析报告显示,2016年7月30日校园招聘广告信息发布迎来第一个小高峰,先比2015年的第一个高峰期8月10日提前了10天,相较于2014年的第一个高峰期9月5日提前了有一个月有余,2016年9-10月的简历投递量达到了全年的1/2以上;2017年的春招在2月10号(春节后一个周)就开始了小高峰,3月7日达到了春季招聘的高峰。可见校园招聘无论是秋季招聘还是春季招聘的高峰期都是来的越来越早,且从招聘季节开始到高峰期的过渡时间越来越短,这已成明显趋势。 在国内关于校园招聘网站并不在少数,智联招聘、前程无忧、海投网等都有针对校园的入口,涵盖职位范围广,信息海量,相较而言更多面向社会人员招聘,为公司企业等提供专业的人才招聘服务,对于校园招聘来讲,其信息量巨大,错综复杂,真假难辨,筛选困难,且时效性不高,不适合于毕业生寻找招聘信息。相比之下各高校的校园招聘网内容针对性更强,时效性更高,职位要求等高清晰,信息来源因为经过学校的筛选,更加安全可靠,但是各学校发布的信息大多范围局限于本校,受限于学校自身实力等多方面,信息来源基本依靠公司的主动投送,无主动获取整合功能。也有一些对校招针对性很强的厂商,例如牛客网,提供针对IT招聘信息的发布与技能培训等,这样极大的方便了IT方向的毕业生,获得此方便的门槛较高,需要较强的自身技术实力。综上,国内的校园招聘平台多而复杂,目前尚未有全面且只针对校园招聘发布信息的平台。 在国外有如Jobs等招聘信息平台,但不必国内规模,以欧洲为例,毕业生的规模远小于国内规模,且各公司基本开放简历网申通道或直接开启招聘会,基本不存在校园招聘季节这个说法,如果放眼全球各地区毕业时间的差异,不同于中国国情,所以在国外鲜有对校园招聘平台的研究。 针对国内校园招聘现状,为了帮助毕业生能够在来的快、来得急的招聘季中可以更有效的查询校招信息,抓住更好的机会,设计一个一站式的校园招聘信息平台是有意义的。 根据TIOBE编程语言排行榜TOP10近十年的变化趋势分析,Python语言一直处于用户增长的状态,它可以开发网站,更广泛的应用于数据科学,开发简单易用,稳定性高,其开源框架Django和Flask均处于Web搭建热门首选。本设计本着开源、精简、可定制的宗旨,采用国内外均流行的Python Web技术,并通过流行的爬虫框架保证信息的可靠性、时效性、针对性与广泛程度,搭建信息数据库。旨在整合校园招聘信息,提供在校招范围内更多样、更精准、更安全的搜索平台,帮助求职毕业生优化信息获取渠道,节省求职成本。 |
2. 研究的基本内容与方案
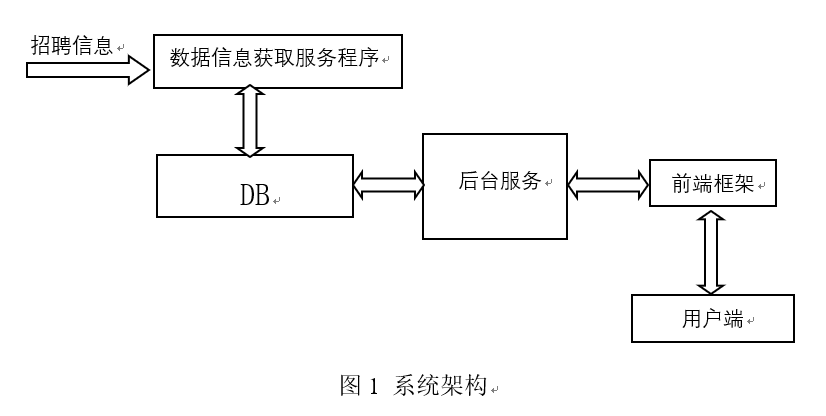
| 2、设计任务和技术方案 设计的基本内容与目标: 1.设计基于Flask框架的web后端服务程序; 2.设计基于Jinja2的模版引擎和Bootstrap开源前端框架的web前端; 3.设计基于Mysql的Python爬虫框架,获取招聘数据信息; 4.基于VPS Nginx Gunicorn部署运行平台,进行调试、上线。 技术方案: 系统原理方框图如下图1所示,系统主要有四部分组成:信息采集部分、数据库控制部分、后台服务框架、前端框架。基于MVC(Model-view-control)的设计模式,使用精简扩展能力强的Flask框架,搭建后台服务程序,实现具体的服务,集成SQLAchemy数据库辅助插件,实现Mysql数据库的增删改查操作,BootStrap与jinja2模版引擎结合,实现响应式前端设计,增前用户的使用体验。爬虫拟采用Beautiful4工具,配合Mysql挖掘校园招聘信息网上的数据。采用在VPS上使用Nginx缓冲请求和响应,可以负载均衡,搭配Gunioncorn处理HTTP请求,实现高并发 高性能的服务器架构。
如图1,数据信息获取服务程序拟采用Python Web信息采集方案,利用爬虫技术,获取目标高校求职网站中的针对性信息。 后台服务使用扩展性强的Flask Web框架,数据库选择MySQL,前端使用Bootstrap框架,使用Git作为版本控制系统,调试、上线拟定于云服务平台。 |
3. 研究计划与安排
| 3、进度安排 1 - 2周 查阅相关文献,了解常见的前端、后台与数据库技术; 3 - 4周 根据查阅的技术资料,翻译外语资料,写开题报告; 5 - 6周 常用网络爬虫算法分析比较并设计实现; 7 - 8周 后台与Web前端的demo设计实现; 9 -10周 各组件拼接,网站整体构建; 11-12周 一站式校园招聘信息平台的上线、测试完善工作; 13-14周 撰写论文,完成初稿; 15 周 修改论文,完成答辩PPT,并交与相关院系老师验收认证; 16 周 参加毕业答辩。
|
4. 参考文献(12篇以上)
[1] 李琳.基于python的网络爬虫系统的设计与实现[j]. 信息通信,2017(9):26-27.
[2] 安子建.基于scrapy框架的网络爬虫实现与数据抓取分析[d].吉林大学, 2017.
[3] 魏冬梅,何忠秀, 唐建梅. 基于python的web信息获取方法研究[j]. 软件导刊, 2018(1).



