基于神经决策森林的数据挖掘与分类毕业论文
2020-02-25 22:45:27
摘 要
在当前信息高速传递的时代,人们每天都需要处理大量信息,如今,由于信息过于繁杂,人们接收到的信息不一定是我们可以直接使用的,提升处理信息的手段变得尤为关键,在这样的背景下,数据挖掘已经成为了一门重要的学科,广泛应用于各行各业。数据分类是其中一个非常重要的内容,如何准确而又高效的将数据分类成为了关键问题。
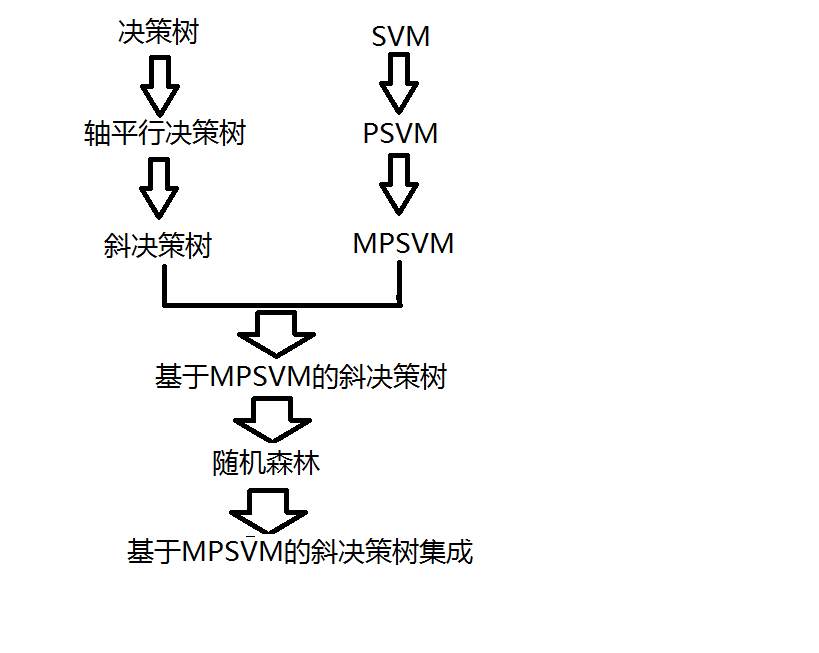
本文先介绍了传统支持向量机的基本概念,由于传统支持向量机缺乏对数据几何特征的学习,引入了近似支持向量机的方法,然后又因为划分超平面对于平行条件的限制影响了分类器的划分精度,出现了更精确的多平面近似支持向量机(MPSVM)的方法。
随后介绍了决策树的基本概念,决策树是非常重要的分类算法之一。传统决策树采用的平行于坐标轴的判定依据导致决策树生长的过于庞大,于是在此基础上提出了改进的斜决策树,可以使生长所需的分割平面变少,减少划分次数,降低决策树的复杂度。随后将MPSVM方法与斜决策树结合,产生一种新的方法,应用过程中发现在处理小规模样本时MPSVM会出现矩阵奇异的条件限制,需引入Tikhonov正则化方法来改进。除此之外,还可以让决策树以异构的方式生长,即前半段满足条件的部分用改进后的新方法,而后半部分使用原方法。
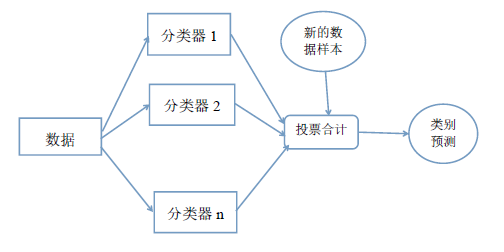
为了提高分类方法的泛化能力和分类精度,将改进后的MPSVM与斜决策树结合的分类器进行随机森林集成。
以上述随机森林作为理论依据,对UCI标准数据库中样本数据集Iris(鸢尾花)、Breast_cancer(乳腺癌)和Mushroom(蘑菇)进行分类实验,通过比较结果的精度来对改进的效果作出研究。从而判定基于MPSVM的斜决策树对于数据分类起到了明显的改善作用。
关键词: 数据分类;支持向量机;决策树;随机森林
Abstract
In the era of information transferred with a high speed,people need manage lots of information every day.Nowadays,it’s important to develop better methods to manage information because of information getting more and more complicated.Under such a background,data mining has become a very important subject,extensively used in all walks in life.Data classfication is one of a significant problem.It’s crucial to classify data accurately and efficiently.
This paper first introduce the basic concept of suppor vector machine.Because vector machine lack of learning of data geomatrical features,we bring in the method of proximal support vector machine.Then,deviding hyperplane requires the condition of being parallel,which influence the accuracy of classifier.Then the more accurate method of multisurface proximal support vector machine(MPSVM).
Then we introduce the basic concept of decision tree,which is one of the most important classfication methods.The traditional decision tree make decisions with conditions parallel to coordinate axis,which makes the tree grow too big.On this basis,it comes a modified oblique decision tree,which reduces dividing times and decrease the complexity of decision tree.Then we combine MPSVM with oblique decision tree.With this new method,we find its limiting condition that occurs when it comes to small-sample-size problem.And we need bring in two regularization methods to improve it.
In order to improve the generalization and classfying accuracy of this classified method ,we ensemble the classfiers that combines the MPSVM and oblique decision tree.
Based on the above theory,we test it with 3 different data set in UCI standard database.Comparing the result of tests,we found that ensembled oblique decision tree based on the MPSVM did improved the accuracy of the classified problem.
Key words: Data classification;Support vector;Decision tree;Random Forest
目录
1 绪论....................................................1
1.1引言...............................................1
1.2国内外发展现状...............................................1
1.2.1支持向量机的现状与发展.......................................1
1.2.2决策树的现状与发展.......................................2
1.3本文的研究内容...............................................2
2 支持向量机....................................................4
2.1传统支持向量机.............................................. 4
2.2近似支持向量机...............................................5
2.3多平面近似支持向量机...............................................6
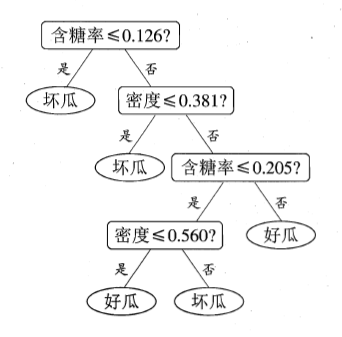
3 决策树....................................................9
3.1决策树介绍..............................................9
3.1.1概念及基本算法.......................................9
3.1.2划分选择.......................................11
3.2斜决策树..............................................12
3.3由MPSVM改进的斜决策树..............................................14
4 随机森林....................................................17
4.1集成学习..............................................17
4.2 Bagging..............................................17
4.3随机森林..............................................18
4.4算法图示.............................................19
5 实验及结果分析.................................................20
5.1 UCI数据库..............................................20
5.2 Iris数据集实验..............................................20
5.3 Breast_cancer数据集实验..............................................25
5.4 Mushroom数据集实验..............................................29
5.5 其他实验..............................................33
5.5.1 car数据集实验......................................33
5.5.2数据集比较...................................... 34
6 总结及展望.................................................35
参考文献.................................................36
致谢.................................................38
1 绪论
1.1 引言
数据被认为是知识的来源,海量数据通常包含大量有价值的信息。近年来,随着信息技术的发展,生产数据收集数据的能力越来越高,在数据库和物联网发展的推动下,大量数据不断增长并趋于多样化,但在一定程度上它们也是相互关联的。在数据量呈现爆炸式增长时,我们在数据分析和知识获取方面的能力相对比较落后。在许多情况下,获得的数据没办法直接满足实际需要,经常会通过大量的数据处理工作,将原有的数据资源转化为满足需求的形式,然后再根据需求进行改进并投入使用,从而实现真正的价值。从数据的收集和管理到数据分析,数据挖掘和分类变得越来越深入。数据挖掘是一个涉及许多领域的跨学科课题,包括统计学,数据库,机器学习和人工智能等。分类问题是数据挖掘技术中一个非常重要的研究课题。使用分类技术,可以从数据集中提取描述数据的相同模型和功能,并且可以在一定程度上分配将未知类型的数据分配到已知的数据集中。在数据分类中,最基本的分类就是给定含有多个不同特征的数据集,通过一定的分类规则,可以将数据集中的样本划分到对应的类别之中。数据丰富多彩,而且划分方式多种多样,如何获得分类效果较好的分类器就是本文所讨论的主要问题。数据分类在很多情况下都会被运用。比如在遇到数据缺失时,可通过所得结果,运用模型函数反推出所缺的数据范围,从而使缺失项的误差最小化。或者在处理错误数据时,可以通过决策树的“剪枝”或者随机森林的方法,在进行数据分类的时候去掉看起来很明显的错误数据。在碰到预测性函数时,可以通过已知的特征和结果,即输入输出数据集,产生分类函数,再用新的输入特征加上分类函数,得到结果,就可以推算出的未来的结果,从而做出可靠性高的预测。除此之外,数据分类还能在图像识别中做出贡献,那就是将图上的点处理成数据,作为输入,然后通过进行分类处理,得到所给图像属于哪一类别。这些都只是分类问题在有关现实中可解决的问题的一小部分,还有更多的应用需要被探索。由于给出的数据和分类方法不一定标准,这就需要在分类器上作出改进。
1.2国内外的发展现状
1.2.1 支持向量机的现状与发展
支持向量机(SVM)是Cortes 和Vapnic 于1995 年提出的,当时它是一种新的分类。这种分类思想在机器学习中起着重要的作用。它基于最小化结构化风险的原则,以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标。传统的SVM问题不适合求解大规模问题,主要是在求解过程中有一个大规模的核矩阵,使得内存过大。核函数的质量直接影响SVM 分类器的性能。它涉及很多计算,时间成本太大。因此,J.Platt 提出了一种贯序最小优化,即选定子工作集的样本数为2,每次迭代只需要调整两个样本点,也就是仅解决优化问题的两个变量。后来许多人对训练时间问题进行了研究,但还是没有一种算法能够有效解决这个问题。之后,研究人员又提出了许多新的支持向量机算法。例如,Mangasarian 等人在2001 年提出的近似支持向量机(PSVM)将不等式问题转化为方程。后来在2006 年,又提出了基于广义特征值的近似支持向量机(GEPSVM)来改变超平面的选择,也就是将平行的条件扩展到了不平行。之后,又对SVM 进行了许多不同的改进,逐渐进入大众视野。支持向量机在求解小样本,非线性和高维问题方面显示出许多独特的优势,并且可以应用于其他机器学习应用以生成新算法。目前对支持向量机的改进方法的研究已经逐渐深入,事实证明,这是一个很好的辅助工具,可以用于机器学习。支持向量机适用于几乎所有的学习任务,通常包括和等。目前,它有广泛的应用,包括、、等。这是一种传统和先进的分类思想。
1.2.2 决策树的现状与发展
在众多的机器学习算法中,决策树是使用最广泛而且最基本的分类方法,最常用于。从发展看,决策树起源于于Hunt 等人在1966 年提出的。在此基础上,其他决策树学习算法陆续被研究出来。其中影响最大的是Quinlan 于1986 年提出的。由于ID3 倾向于取值较多的属性且忽略了属性间的相互联系,Quinlan 于1993 年又研制了。其后为了简化决策树的规模,提高生成决策树的效率,又出现了根据基尼系数来选择属性的决策树算法。为进一步提高效率,研究者在决策树的基础上不断作出了改进,生成了各种各样的决策树算法。:与如与、、等原理和技术相结合,寻找更好的等。是由美国科学家Leo Breiman 将其在1996 年提出的与Ho 在1998 年提出的相结合,于2001 年发表的一种机器学习算法。随机森林是一种非线性的的组合分类器,采用随机放回抽样的方式抽取训练样本和特征集,训练得到大量的弱分类器组合成为随机森林分类器。而每个决策树的训练和决策互不影响,这就极大的提高了整体模型的训练以及决策的速度,而且很方便进行并行运算和多核运算。随机森林对噪声有很好的容忍性,避免了传统分类器容易出现过拟合的缺点,大量实验证明随机森林有着不错的准确率,尤其在处理大量、高维度数据的时候表现的尤为明显的优点。而且其准确率会显著提高。
1.3 本文的研究内容
本文的研究的核心是构造出一个以改进的SVM 为基础的斜决策树算法。首先通过学习各种不同的基础的分类算法,根据不足作出改进,然后各方法结合,得到一个相对较好的分类方法。最后对比改进前后的不同算法的效果,通过实验以及实验数据的处理得出结论。
本文一共分为六章,结构如下:
第一章绪论,主要介绍了课题的研究目的与意义,然后简要介绍了支持向量和决策树的国内外发展现状,最后论述了全文的主要研究内容和结构。
第二章主要介绍了支持向量机,先阐述了传统的支持向量机的基本概念及数学模型,然后对其作出改进,介绍了改进后的支持向量机算法。
第三章主要介绍了决策树,先从传统的决策树算法开始讨论,随后描述了用于衡量划分纯度的指标,然后讨论了分类性能更优越的斜决策树,并将其与前面讨论的MPSVM相结合,生成新的分类方法。此时由于奇异矩阵的条件限制,引入了Tikhonov正则化方法和轴平行异构来改进。
第四章主要介绍了集成学习的两类算法:Bagging和随机森林。有了上述基于MPSVM的斜决策树算法,将决策树通过合适的方式聚合,以获得更好的分类性能
第五章利用上述随机森林算法对UCI标准数据集Iris(鸢尾花)、Breast_cancer(乳腺癌)、Mushroom(蘑菇)进行实验及结果分析,对每个数据集都分别使用了随机森林,用Tikhonov正则化加MPSVM改进的斜决策树集成和MPSVM改进的斜决策树集成以轴平行异构生长的方法
第六章总结与展望,总结全文的工作及心得,对数据分类今后的发展作出了展望。
2 支持向量机
2.1 传统支持向量机
机器学习的核心在于构造出于真实情况无限接近的模型,而真实的情况往往不可预知,所以需要一个使结构风险最小的方法——。
支持向量机主要是将输入空间通过非线性变换的方式映射到一个高维的特征空间,并在这个高维空间中找出最优的线性分界超平面。给定支持向量机二分类模型(如图2.1 所示),其中,“ ”和“-”分别表示训练数据集中的两个类别。在三维坐标系里,XOY 平面将坐标空间分为两个部分,由此可引申至一维是点划分,二维是直线,三维是平面,而四维开始已经无法用几何表示,因此把此用来分隔的东西称为超平面。
对于某个训练样本数据集D=(),(),…(),要想将不同类别的训练样本分开,有许多不同划分超平面可以达成目标,最合理的应该选择到两类样本相同距离的超平面,因为要找到有一个最优的分界平面,不仅需要能将两个类别的数据正确分隔开,还需要使这两类数据直接的分类间隔或分类空隙最大化,由于不被包括在训练集中的样本可能会比已包括的样本更接近划分超平面,这样选择划分超平面可以尽量减少对于未知样本错分的可能性。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: