基于用户评论的情感识别系统研究与实现毕业论文
2020-02-19 07:54:12
摘 要
互联网的技术的迅猛发展在不知不觉中极大地改变了人们的生活方式,越来越多人选择线上购物。与此同时,用户评论的规模也在逐渐扩大,而对用户评论进行情感分析可以为商家和用户提供有价值的参考信息。本文基于用户评论对情感识别系统进行研究,分别实现了基于字典和机器学习的用户情感识别系统。
本文首先用爬虫工具采集用户评论,然后对其进行数据去重清洗,获得较为整洁的用户评论数据。随后采用基于词典和基于机器学习的方法对用户评论的情感进行分析,对常用的较为权威的词典进行整合构建包含基础情感词库、否定词库和程度副词词库的词典。随后采用python语言对用户评论文本进行去停用词、分词、进行词性标注最后按照情感值计算公式分析评论的情感倾向。基于机器学习的用户评论情感分析,首先对文本数据进行去停用词、分词,并选用TF-IDF为特征提取方法。随后将用户评论文本向量化,选用支持向量机(SVM)用于对用户评论的情感极性进行分类。最后对比两种方法发现基于机器学习的用户评论情感识别系统对评论文本的情感倾向识别更为准确。
关键词:用户评论;情感识别;情感词典;机器学习
Abstract
The rapid development of Internet technology has dramatically changed people's lifestyles, and more and more people choose online shopping.At the same time, the size of user reviews is gradually expanding, and sentiment analysis of user reviews can provide valuable reference information for merchants and users.This paper studies the emotion recognition system based on user comments. The user emotion recognition system based on dictionary and machine learning is realized respectively.
Firstly, this paper collects user reviews with the crawler tool, and then cleans the data to get more neat user reviews.Meanwhile, dictionary-based and machine learning-based methods are used to analyze the emotions of user reviews.Based on the emotional analysis of dictionary users'comments, a dictionary containing basic emotional lexicon, negative lexicon and degree adverb lexicon is constructed by integrating commonly used authoritative dictionaries.Then, Python language is used to delete stop words, segment words, tag part of speech in the user's comment text. Finally, the emotional tendency of the comment is analyzed according to the formula of emotional value calculation.Based on the sentiment analysis of user reviews by machine learning, the text data is first used to remove stop words and segment words, and TF-IDF is selected as feature extraction method.The user comment text is then vectorized and a support vector machine (SVM) is used to classify the emotional polarity of the user's comments.Finally, compared with the two methods, it is found that the sentiment recognition system based on machine learning is more accurate for sentiment orientation recognition of comment text.
Key words: User comment;Emotion analysis;Sentiment dictionary;Machine learning
目录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.3 研究内容与章节安排 2
第2章 用户评论数据采集与预处理 3
2.1 用户评论数据选取 3
2.2 用户评论数据采集及规范化 3
2.2.1 数据采集 3
2.2.2 用户评论中文分词 4
2.2.3 数据清洗 5
第3章 基于词典的用户评论情感的研究 6
3.1 用户评论情感基础情感词库 7
3.2 用户评论辅助词典的构建 7
3.2.1 否定词词典 7
3.2.2 程度副词词典 7
3.3用户评论情感词典的情感值计算 8
第4章 基于机器学习的用户评论情感识别 9
4.1 用户评论特征提取方法 9
4.1.1 TF-IDF 9
4.1.2 卡方检验 10
4.1.3 互信息 11
4.2 文本情感分类器 11
4.2.1 K近邻分类器 11
4.2.2 朴素贝叶斯分类器 12
4.2.3 支持向量机分类器 14
4.3 本章小结 15
第5章 用户评论情感分析系统的实现 16
5.1 基于词典的用户评论情感的实现 16
5.1.1 基于词典的用户评论情感识别系统的构建 16
5.1.2 基于词典的用户评论情感识别系统的实现 17
5.2 基于机器学习的用户评论情感系统 17
5.2.1 基于机器学习的用户评论情感系统的构建 17
5.2.2 基于机器学习的用户评论情感识别系统的实现 18
5.3对比研究 18
第6章 总结与展望 19
6.1总结 19
6.2展望 19
参考文献 20
致谢 21
第1章 绪论
1.1 研究背景及意义
随着科学技术的不断发展,互联网技术越来越多地渗透到我们的生活中,网络购物逐渐成为人们日常生活中不可或缺的一部分。最新研究预测,到2021年,全球电子商务销售额将达到新高度。全球电子商务业务预计将增长265%,从2014年的1.3亿美元增长到2021年的4.9万亿美元,表明将来电子商务市场没有下降的趋势,且未来形势一片大好。
随着线上购物市场的日益成熟,商品质量和客服的服务质量成为消费者主要的评判依据。由于线上购物无法做到实体店购物一样通过直接的接触来了解商品的质量信息,只能通过直接询问网上客服以及历史评论来判断该商品是否值得购买,故从以往其他消费者的评论中获取商品信息成为较为主要的渠道。
情感识别包括人脸情感识别、语音情感识别、语言文字识别和生理模式识别四大类。其定义为计算机对从传感器采集来的信号进行分析和处理,从而得到对方(人)正处在的情感状态的行为。针对用户评论数据采集起来为文本形式,故而本文中提及的情感识别为语言文字识别。本文旨在实现的情感识别系统的效果为:输入用户评论数据,系统可自动计算出其情感倾向。通过情感识别这一技术,不仅能够使消费者更加了解商品,做出正确选择,同时也让有利于商家做出提升销量的策略,对二者均有很大的好处。
1.2 国内外研究现状
近年来,情感分析日益得到研究者的广泛关注,为了提高情感分析的准确率,稳定性等指标,很多新的算法被提出。这些算法主要可以分为两类,基于词典的方法和基于机器学习的方法。
基于词典的情感分析方法需要自主构建或使用已构建好的情感词典,对经过数据预处理后的文本进行情感词匹配,并依据情感值计算规则进行情感识别。而基于机器学习的方法需要先构建一个有大量人工标注语料的训练集,通过选定特征提取方法提取特征词,构建出分类器进行情感识别。
上世纪50年代末,LUhn第一次将词频的统计思想应用于自动分类,自此拉开了文本分类技术的序幕。随后,Maron(1960)成为发表关于文本分类论文的第一人。1997年赫尔辛基大学的一个科研小组发表了一篇将数据挖掘技术应用于经过预处理的文本数据的论文。Turney在2002年提出了整条文本情感极性的判断方法,其依据为待测文本中的词汇和短语与种子词典中情感词汇或短语的关联度。Godbole N、Srinivash M和Skiena在2007年发表了以博客文章以及新闻内容为研究内容的情感词典构建方法,提出了情感分析模型,构建了较为完整的情感分析系统。Bracewell D.B.于2008年首次提出了一种基于WordNet的半自动词典创建算法,且精度较高。而Jijloun等人则在2010年提出基于通用词典生成面向主题的情感词典,从而降低因主题分散产生一词多义问题的几率。2013年,周咏梅、杨佳能和阳爱民初次在论文中提出基于HowNet和SentiWordNet来构建情感词典,并通过校准参考词典的情绪值,对情感词典进行优化。
2002年,Pang首次将机器学习方法应用于情感分析领域,使用包括支持向量机、最大熵以及朴素贝叶斯等多种有监督的机器学习方法对电影的影评进行了褒贬情感的分类研究。Dave等人是首批研究句子情感倾向的学者,其对句子的情感倾向进行打分,最后,结合得分和特征判断句子的情感极性。随后,E.Riloff等人提出了对篇章级文本情感分类的方法,在判断文章有无感情倾向句子的基础上,利用情感词典识别相应句子的情感极性。国内的李景阳、孙茂松等人在2005年综合TF-IDF加权及支持向量机分类的方法对中文文本进行分类。随后,李寿山等人基于不平衡语料的情感分析方法,对未标注的语料进行筛选和自动标注。
1.3 研究内容与章节安排
本文的主要研究内容为:首先选定商品并对其用户评论数据进行采集,然后对文本进行处理,并分别采用基于词典和基于机器的方法对文本数据的情感进行识别,最后对比两种方法得出结论。
本文的章节安排如下:
第1章:介绍了情感分析技术的发展历程及研究意义,并概括了本文的主要研究内容和章节安排。
第2章:对用户评论数据进行采集以获取文本数据集,并对数据进行去重等预处理。随后对用户评论文本进行分词和去停用词。
第3章:对情感词典进行研究,概述情感词库的基本构成以及情感值的计算问题。
第4章:对机器学习的概念进行概略阐述,并对机器学习的特征提取方法以及文本情感分类器进行介绍。
第5章:分别对基于词典和基于机器学习的情感识别系统进行构建,并得到实验结果,最后对比分析两种方法得出结论
第6章:总结本文的内容,并对今后的工作进行展望。
第2 章 用户评论数据采集与预处理
2.1 用户评论数据选取
为了使获取的用户评论信息更具价值,需要对即将采集的数据类型进行一定程度的筛选。
21世纪是开放与发展的时代,在物质文明和精神文明并重的情况下,人们在满足自己的物质需求的同时,也追求更高层次的精神享受。在日常的休闲活动中,通常我们会用电子设备来听音乐、与朋友亲人通话、影音欣赏、玩竞技游戏,这些通常都是现代人的户内休闲方式。这些休闲方式都与耳机密切相关,耳机原是给电话和无线电上网使用的,但随着科技的不断发展,耳机的多用于手机、随身听、收音机等可携带电子设备和电脑以及音响。
根据世界银行分预测,我国将在2020年成为世界上最大的经济体。
索尼是日本著名的大型综合性跨国企业集团。它是世界视听、视频游戏、通信产品和信息技术的领导者,世界上最早的便携式数字产品的先驱,是世界最大的电子产品制造商之一、世界电子游戏业三大巨头之一、美国好莱坞六大电影公司之一。无论是面向大众的中低端以及面向商务的蓝牙降噪,还是面向烧友的各种旗舰,索尼都有大量的用户。所以本文选择索尼耳机的评论进行用户情感分析。
2.2 用户评论数据采集及规范化
在进行情感识别之前首先需要获取用户评论文本,对数据进行于预处理,使得最后系统分析的数据文本较为规范,有利于情感识别系统对用户情感的识别。
2.2.1 数据采集
网络爬虫是一种程序,它可以通过一个设定好的程序自动获得所需的网页内容,其主要用于搜索引擎。网络爬虫向网站发起请求,获取资源后分析并提取有用的数据信息,网络爬虫的工作步骤如下图2-1所示。
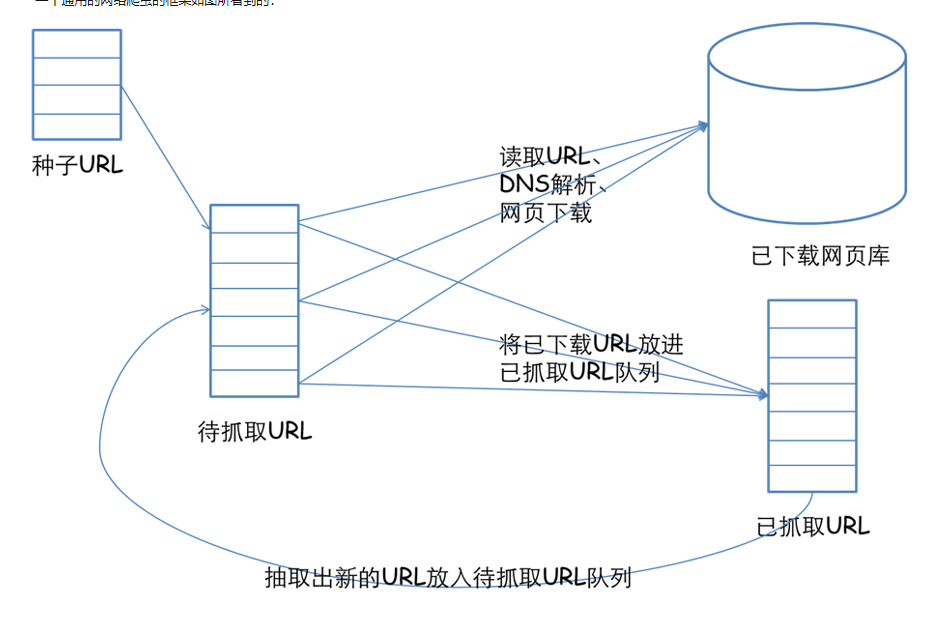
图2-1网络爬虫工作流程
工作流程如下:首先选取种子URL,将其放入待抓取URL队列。在待抓取序列中取出待抓取在URL,解析DNS,下载其相应的网页放入已下载网页库中,并将已下载的URL放入已住抓取URL序队列。最后在已抓取URL队列中抽取新的URL放入待抓取URL序列中。
python爬虫遵循“发送请求——获取响应内容——解析内容——保存数据”的过程,这实际上是对我们使用浏览器获取网络信息的过程的模拟。首先通过http库向目标网页发送request,若收到响应,则返回respone获取网页内容,随后根据内容格式不同选用不同的解析方式进行解析,最后将采集到的内容保存为文本格式即可。
2.2.2 用户评论中文分词
通过网络爬虫获取的评论文本数据包括很多无用的噪声数据,需要对其进行处理才能进行情感分析。首先,程序需要对用户评论文本分词,以实现规范化。分词的意思是,根据一定的规范将连续词序列重组,之后得到重组的单词序列。而中文分词指的是把文本中的汉字序列按照一定的方法进行切分进而转化成带有明确语义信息的词语序列。中文文本的分词最重要的就是采用不同种类的分词方法以减小语义的歧义。中文分词采用的算法特点各不相同,故而将其分为基于规则、基于统计、基于语义、基于理解四类分词方法。目前使用较多的中文分词工具为为jieba、SnowNLP、THULAC、NTPIR、NLTK和LTP。本文主要对jieba和ltp的进行简要介绍。
(1)Jieba分词是一种主流的中文分词工具,使用人数较多。Jieba分词不仅可以对繁体字句进行分词同时支持自定义词典。jieba支持三种分词模式:精确模式、全模式和搜索引擎模式。其中精确模式最为精细,常用于文本分析;全模式分析最为全面且速度也很快,但易模糊;搜索引擎基于精确模式能对长词二次切分,提高召回率,适用于搜索引擎分词。jieba使用的是基于统计的分词方法,其在前缀词典的基础上,高效扫描文本数据,生成有向无环图,并采用动态规划查找最大概方式对词频进行最大切分组合,最后采用HMM模型使用Viterbi算法处理未登录词。
Algorithm | Time | Precision | Recall | F-Measure |
LTP-3.2.0 | 3.21s | 0.867 | 0.896 | 0.881 |
jieba | 0.26s | 0.814 | 0.809 | 0.811 |
(2)哈工大的语言技术平台(Language Technology Platform,LTP)是一整套中文语言处理系统,具有自动分句功能。LTP基于中文标点符号进行分词,例如句号、问号、感叹号、分号和省略号等。其主要分词流程为:提取字符特征、计算特征权重值、Viterbi解码。但是LTP存在一些缺陷,由于URI的构造规则有一定限制,无法提交一些特殊字符,故LTP只能在其离线API中提交这些特殊字符。另外,LTP还有一个缺陷,它的分词切分方式与词典匹配策略并不一致,因为它是通过基于特征的算法将用户的外部词典添加到系统中的。
对两种分词工具进行评测,其结果如表2-1所示。
表2-1 两种分词评测结果
二者相比较,准确率以及召回率相差无几,但是速度差异较大,故而选用速度较快的jieba进行中文分词。
2.2.3 数据清洗
除文本分词外,文本相似度计算也是情感分析中的一个关键步骤。文本相似度计算可以用于检测重复或相似的词组,在具体应用中可以用作检测出恶意重复的词组进行去重处理。在建立情感词典的过程中,该计算方法也常用来识别同义词,并对其进行极性的标注。余弦相似度算法和simhash算法是做文本相似度计算中较为常用的两种方法。这两种方法的原理如下所示:
(1)余弦相似度算法。该算法的原理是计算一个向量空间中两个文本向量之间夹角的余弦值,来衡量两个文本相似性。余弦值在-1到1之间,实际应用中常在0,1之间。
对于向量,向量,余弦相似度记为,其计算如下:
(2-1)
由上式可知,若两个向量的方向越接近0º,余弦值越接近1,其相似度越高。反之,若其两个向量两个向量的方向越趋近于90º,余弦值趋近于0,则表示相似度越低。当使用余弦相似度算法计算词向量相似度时,需要将文本进行向量化。而在向量化过程中,需要建立向量空间模型(VSM),将文本进行向量化处理,得到向量空间中的一组向量。
在实际应用中往往需要先对向量进行预处理,将不同的向量调整为同等长度。常用的方法有两种:一种是去除向量中相关性较低的词语,以达到两个向量的长度相同;另一种是归并向量,它基于新向量的合并向量中是否存在原始向量,如果存在,则使用表示该词的词的频率。如果不存在,则将节点设置为0。余弦相似算法短文本的处理往往较为准确,实际应用也常以小文本为主。但是该算法步骤复杂,需要对文本逐一进行矢量量化和余弦计算,浪费CPU时间,不适合长文本。
(2)Simhash算法。该方法由Google的研究人员提出,常用作处理海量网页的处理。该算法首先对文本数据进行降维处理,通过特征处理方法,将高维的特征向量映射成低维的特征向量,通过对比两个向量的Hamming Distance来确定文章是否重复或者近似。该方法可以组合原文本数据,之后向量化处理,并计算文本词频得到hash值。



