基于机器学习算法的轴承故障诊断及其风险评估毕业论文
2020-04-11 17:51:24
摘 要
Abstract 3
第1章 绪论 4
1.1 目的及意义 4
第2章 机器学习算法 6
2.1 算法介绍 6
2.2 决策树 6
2.3 SVM 8
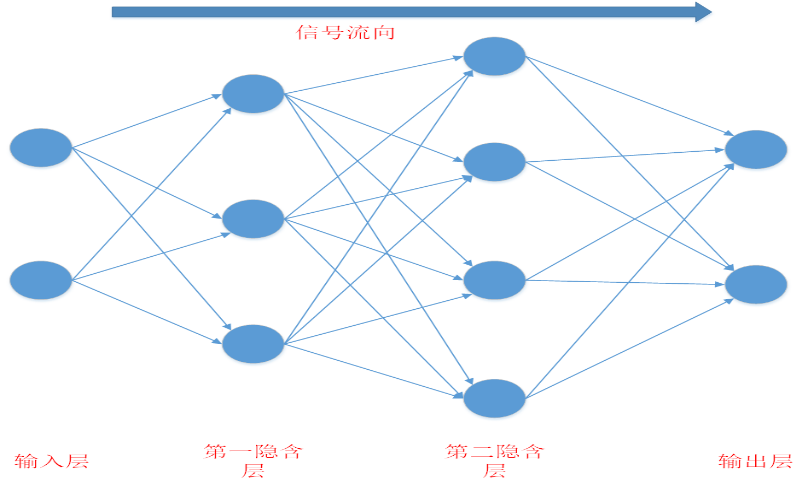
2.4 神经网络 9
第3章 工程实现代码及计算 10
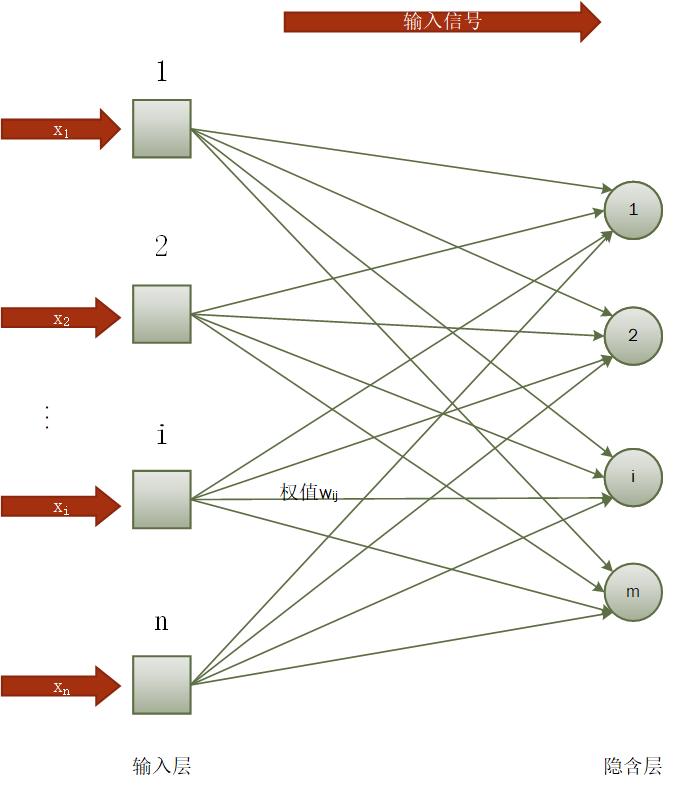
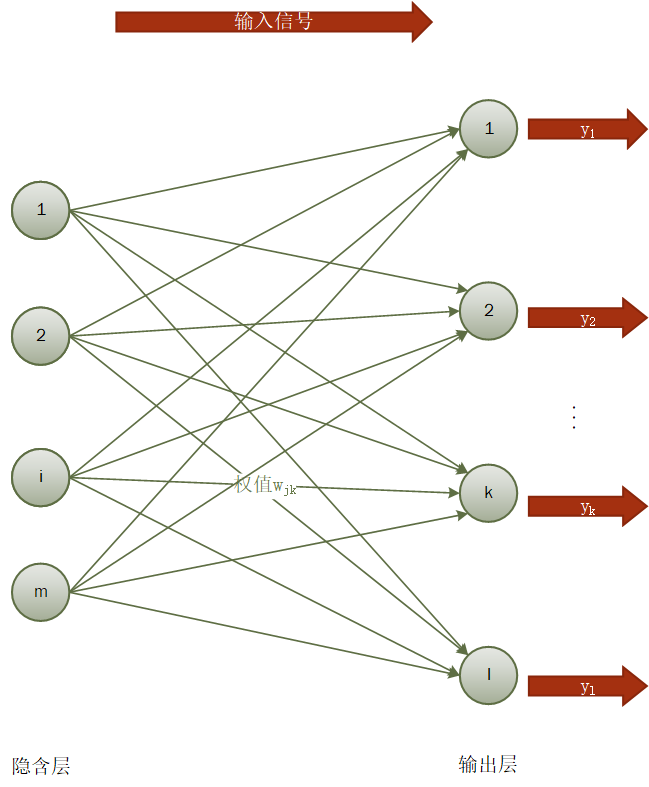
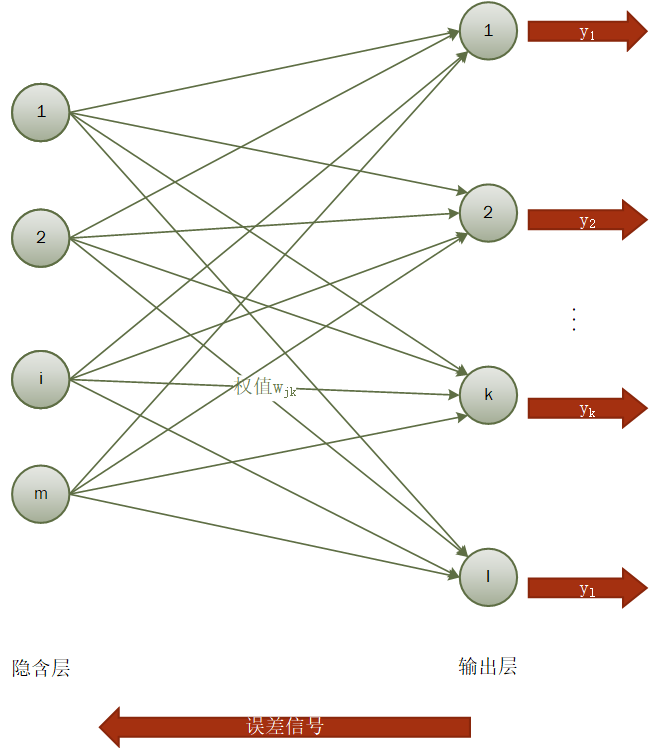
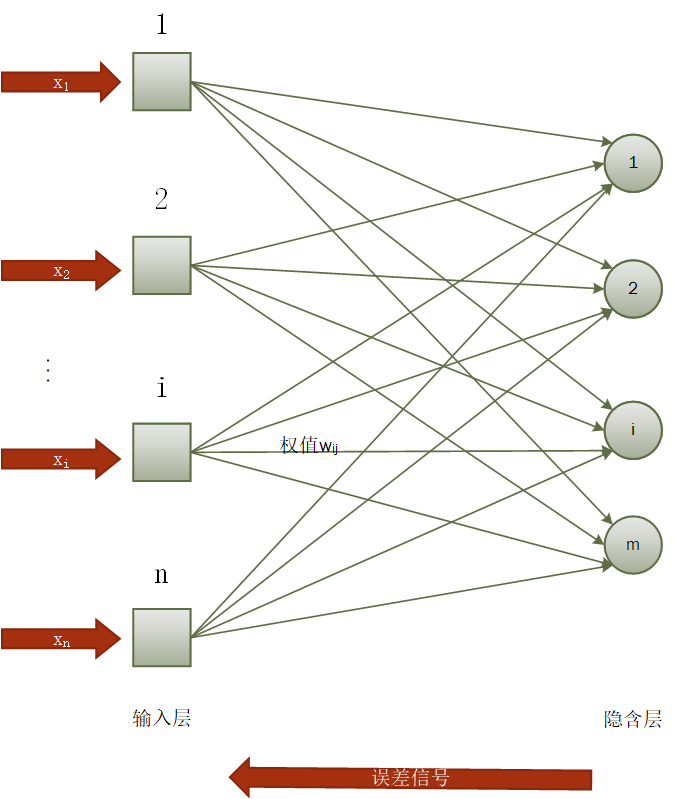
3.1 神经网络理论介绍 10
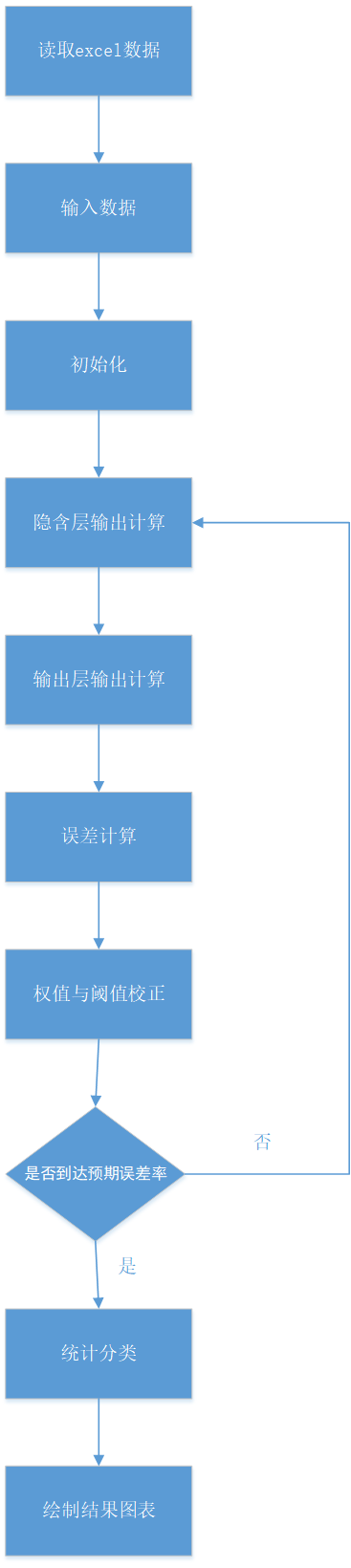
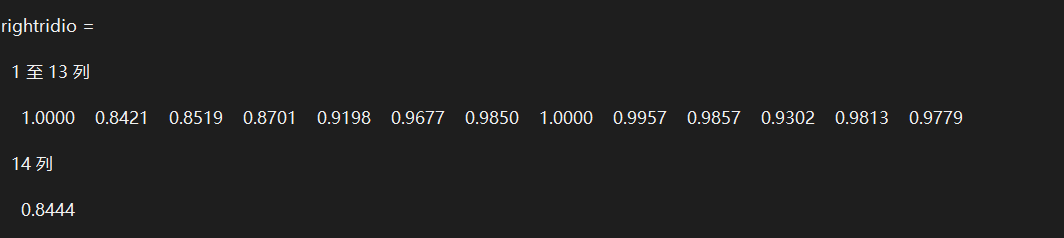
3.2 代码流程及相关计算 14
3.3 总结 20
第4章 风险评估 21
4.1 风险评估 21
4.2 轴承故障风险评估 21
第5章 结论与展望 24
参考文献 25
致谢 26
摘 要
本文主要是通过机器学习算法对轴承故障的诊断,文章选择的算法是神经网络算法,使用所得的数据训练模型,介绍了选择算法的原因、算法的内容以及对数据的处理计算,然后根据所得的结果以及图表进行分析,对轴承故障进行风险评估。论文主要通过以轴承的几种工作状态为属性,比较了SVM、决策树以及神经网络三种算法,确定了工作更加出色的神经网络算法,其中对于SVM、决策树、神经网络三种算法的比较是通过三者各自的优点以及缺点,文中也提及了回归算法等基础算法以及其优缺点,在确定使用神经网络算法之后又比较了单层神经网络(感知器)与多层神经网络,但是由于单层神经网络只能学习训练线性问题函数,所以最终选择多层神经网络(单层隐含层),并且详细介绍了使用的反向传播神经网络,介绍了工作原理以及计算中使用的公式,最终的算法的实现使用了MATLAB,算法中我们使用了矩阵思想,将信息的传递和权重的调整看成矩阵相乘,将这个思想做主要内容,最终在MATLAB上成功实现了算法,并且有使用MATLAB工具箱和不适用工具箱两种实现代码,最终输出了我们算法预测出来的结果与实际实验做出的结果之间的误差值和图,这个值也就表明了我们的算法的准确度,后面我们的算法在预测新的轴承故障类别时也会着重参考这个值。
关键词:SVM; 决策树; 神经网络; 反向传播神经网络; 风险评估
Abstract
This paper mainly deals with the diagnosis of bearing fault by machine learning algorithm. The algorithm is neural network algorithm, and the data training model is used in the experiment. The reasons of the selection algorithm, the content of the algorithm and the calculation of the data are introduced. Then the bearing is analyzed according to the results and the chart, and the bearing is analyzed. Risk assessment of failure. In this paper, three algorithms of SVM, decision tree and neural network are compared by using several working attributes of bearing, and a better neural network algorithm is determined. For the comparison of the three algorithms of SVM, decision tree and neural network, the advantages and disadvantages of the three parties are compared, and the basic algorithms and their advantages and disadvantages are also mentioned. After using the neural network algorithm, the single layer neural network (perceptron) and multi layer neural network are compared, but the single layer neural network is compared. The network can only learn to train the linear problem function, so the multi-layer neural network (single layer hidden layer) is selected, and the back propagation neural network is introduced in detail. The working principle and the formula used in the calculation are introduced. The realization of the final algorithm is MATLAB, and we use the matrix idea in the algorithm. The transfer of information and the adjustment of weight are regarded as multiplicative matrix, and the algorithm is successfully implemented on MATLAB, and the error value and graph between the results predicted by our algorithm and the result made by the actual experiment are output. This value also shows the accuracy of our algorithm, and our algorithm is predicting the new axis. This value will also be referred to when the fault is classified.
Key words: SVM; decision tree; neural network; Back propagation neural network; risk assessment
- 绪论
1.1 引言
轴承是机械设备中最常见的零部件,其性能与工况的好坏直接影响到与之相连的转轴以及安装在转轴上的齿轮乃至整个设备的性能。据统计,在使用轴承的旋转机械中,大约有30%的故障都是由于轴承引起的,轴承在运转过程中会因为各种原因产生损坏,比如装配不当、润滑不良、水分和异物侵入、腐蚀和过载等,并且轴承在使用以及维护过程中也会出现各种故障而不能正常工作,比如疲劳剥落和磨损等。在工作过程中,轴承的振动一般划分为两类:与轴承的弹性有关的振动和与轴承滚动表面的状况(波纹、伤痕等)有关的振动,前者与轴承的异常状态没有关系,后者反映了轴承的损伤状况。轴承的故障诊断有振动诊断法、时序模型参数分析法、冲击脉冲法、包络法、高通绝对值频率分析法等。
风险评估,就是将设备发生事故的可能性(计算出的概率)和事故造成的危害程度(造成的经济损失)进行综合考虑,将设备划分成不同的风险等级。而在这之中,风险管理和风险评估是不可分割的两部分,风险评估技术是前提,它可以预测可能出现的危害风险,并帮我们控制解决风险,降低风险发生的几率,只有这样才能完善风险管理技术,风险管理就是防患于未然。风险评估的目标是在设备使用期间,减少设备故障率,或者在设备预估即将损坏的期间能及时更换,以免发生较大的经济损失。
机器学习的意义,顾名思义就是一种赋予机器学习的能力,让它能够“学习”,从而完成编程无法完成的事情,这里的机器指的是计算机,简单来说就是利用实验所得数据让计算机训练出模型,然后利用模型预测结果。将机器学习用于工业方面是从上世纪就开始的,但近二十年由于计算机技术以及机器学习技术的长足发展,各种机器学习算法在工业上的运用技术也越来越成熟,而利用机器学习算法对轴承故障的分析以及预测、风险评估也就是情理之中的。
机器学习有许多经典的算法,回归算法以及SVM算法都是在工业方面运用成熟的算法,尤其是回归算法,是机器学习算法中最基础的,包括线性回归和逻辑回归,其中线性回归是利用大量数据拟合出一条直线,就可以通过这条直线大致预测;而逻辑回归与线性回归的不同之处在于它模拟出的不是具体的数值,而是一种离散的分类,然后就可以判断,比如判断轴承是否会出现故障。回归算法都需要数据计算,计算机学界有一门学科叫做“数值计算”,专门用来提升计算机进行各类计算时的准确性和效率问题。另外一种经典的算法就是SVM算法,也就是支持向量机的算法,这是一种监督式的学习方法,与逻辑回归的算法有些类似,不过它是一种更加精密的分类式算法,广泛地运用于统计分类以及回归分析中,通过跟高斯“核”的结合,支持向量机可以表达出非常复杂的分类界限,从而达成很好的分类效果。
从上面的介绍可以知道,机器学习算法很早就用于工业方面,并且已经是一门成熟的技术,而在目前的国内外从最早的神经网络(沉寂了一段时间又重新崛起)到SVM再到现在的深度学习,大数据的提出以及迅速成功,但是其实我们实际生活中更加需要的是可扩展的机器学习系统,需要更加出色的优化,需要的是更高的维度,支持更多的特征量,这样才能使模型更加准确,更加精确地完成生活中的实际问题。
- 机器学习算法
2.1 算法介绍
何谓机器学习,从广义上来说,就是给机器学习的能力,让机器能够自己学习,通过不断学习完成一些本来完不成的工作,但从工业实践的意义上来说,机器学习就是利用实验所得的数据,也就是已知的数据,训练模型,然后用得到的模型去预测的方法。在这篇论文中,我们就是利用实验所得的轴承在变化环境中的磨损程度,利用这些数据,训练出较为准确的模型,然后预测接下来实际使用中的轴承磨损情况。
当然,机器学习算法在实际运用过程中,所使用的数据也是很重要的,以正常来说,“数据为王”,数据越多训练效果也会更加精确,但也不是绝对。所谓机器学习过程中的“训练”、“模型”,“训练”是指将数据通过机器学习算法进行处理的过程,“模型”是指上面训练的结果用来对新的数据进行预测的过程,“训练”产生“模型”,“模型”指导“预测”。这与人类的学习历史类似,人类在成长、生活过程中积累了很多的历史与经验。人类会对自己一段时间所积累的经验进行总结,从中慢慢学习,从而获得了生活的“规律”。这些“规律”会在我们遇到麻烦的时候或者说当我们需要它们的时候帮助我们,帮助我们对未来的是进行指导。机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。现在我们知道了机器学习并不是像传统的计算机编程,机器学习并不依赖于编程,它通过数据处理,然后归纳学习,得到结论。
机器学习的方法有许多种,比如回归算法,回归算法比较简单,可以平滑地从统计学迁移到机器学习中,并且回归算法是后面算法的基础,是思路基础,如果没有理解回归算法,就很难学习后面的算法,回归算法分为两类,线性回归和逻辑回归,其中线性回归处理数值问题,最后预测出的结果是数字,而逻辑回归属于分类算法,我们这篇论文中的问题就是分类算法,它预测的结果是离散的分类。惩罚回归方法,是由普通最小二乘法衍生出来的,惩罚回归设计之初的想法是克服最小二乘法的根本缺陷,最小二乘法的一个根本问题就是有时候它会过拟合,过拟合是说在拟合过程中,在数据点中寻找拟合线时,拟合线过于依赖点的选择,比如用两个点来拟合一条直线,这时的主要问题就是针对直线的自由度没有提供足够的数据,惩罚线性回归可以减少自由度使之与数据规模、问题的复杂度相匹配,所以对于具有大量自由度的问题,惩罚线性回归的算法获得了广泛的应用。还有集成算法,它的基本思想是构建多个不同的预测模型,然后将其输出做某种组合作为最终的输出。
- 决策树
决策树是表示基于特征对实例进行分类的树形结构。从给定的训练数据集中,依据特征选择的准则,递归的选择最优划分特征,并根据此特征将数据进行分割,使得各子数据集有最好的分类过程。决策树算法有三要素:特征选择、决策树生成、决策树剪枝。决策树生成的过程是使得满足划分准则的特征不断的将数据划分成纯度更高的不确定性更小的子集的过程。对于当前数据D的每一次划分,都希望根据某特征划分之后的数据纯度更高的不确定性更小。特征选择准则:信息增益、信息增益率、基尼指数,使用某特征划分后,数据子集的纯度高于划分前。不确定性降低。
学习决策树,首先要知道“信息增益”的概念,信息增益IG(A)衡量了一个数据集在被变量A分割之前与分割之后的熵之差,也就是说数据集的不确定程度在分割变量A之后减少了多少。
 (2-1)
(2-1)
其中,
H(D)-数据集D的熵;
T-数据集D在被变量A分割之后所产生的数据子集 D = ⋃t∈Tt⋃t∈Tt;
p(t)-子数据集t所占比例;
H(t)-子数据集t的熵;
使用信息增益作为选择特征依据的算法,叫做ID3算法。信息增益率的本质是给信息增益加上一个惩罚因子,特征较多时,惩罚函数较小,特征少时,惩罚大。惩罚因子:数据D以A为特征作为随机变量的熵的倒数,即:将特征A取值相同的样本划分到同一个子集,之前所说数据集的熵是依据所属类别进行划分的,缺点:偏向于取值较少的特征 因此基于上诉两种方式, 我们不是直接取增益率大的特征,而是在候选特征中找出增益高于平均水平的特征,然后再从中选择增益率高的特征。
总体来说,决策树自身的优点:计算简单,易于理解,可解释性强;比较适合处理有缺失属性的样本;能够处理不相关的特征;在相对短的时间内能够对大型数据源做出可行且效果良好的结果。当然,缺点也显而易见:容易发生过拟合(随机森林可以很大程度上减少过拟合);忽略了数据之间的相关性;对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征(只要是使用了信息增益,都有这个缺点,如RF)。
- SVM算法
SVM算法也是一类经典二分类的分类算法,一般是二维分类找到一条合适的分割线将类别分开,当然分割线会有许多不同的,我们需要考虑的是找到其中最优的分割线。它分类的思想是,给定给一个包含正例和反例的样本集合,SVM算法的目的是寻找一个超平面来对样本根据正例和反例进行分割,各种资料对它评价甚高,说“ 它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中”。
关于超平面,超平面的概念在SVM算法中式很重要的,SVM算法就是通过超平面来划分数据的,在样本空间中,划分超平面可以通过以下线性方程来描述:
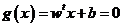 (2-2)
(2-2)
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: