基于机器学习的旅游景区用水量预测及平台搭建毕业论文
2020-02-17 20:27:25
摘 要
如今用水浪费问题在旅游产业表现尤为突出,本文针对某景区的用水量无法合理调度造成用水浪费的问题,以该景区2015到2017三年的用水量数据为对象,使用python语言,构建了包括决策树、决策森林、支持向量机、神经网络、最近邻在内的五种模型,采用机器学习的方法,对该景区未来用水量进行了预测,通过选用适当的评价标准,通过测试集的预测实验,证明了模型在此类问题上的预测准确性,并且展现了机器学习在旅游产业有水量预测方面方法简洁预测准确的优越性,最后,基于PYQT5与QTdesigner等其他工具开发了该旅游景区的用水量预测平台。该平台具有实时查询历史数据并可视化,训练模型对比选择,未来用水量预测的功能,具有快速展示实时查询预测并指导用水量调度的功能。本文的具体内容如下:
(1)模型的构建
(2)模型的检验及评价
(3)预测平台的搭建
本文将较为成熟的机器学习结合数据处理等技术应用到旅游领域的工程问题上,发挥了其实际解决问题的工作,达到了运用知识服务社会的功用。
关键词:机器学习;用水量预测;预测平台;实际应用
Abstract
With the help of Python language and multiple tool modules, this research has completed the data analysis, modeling, visualization and platform building of water consumption in tourism industry. The platform includes five models: decision tree, decision forest, support vector machine, neural network and nearest neighbor. These five models perform well in the model construction stage, which is of guiding significance for the prediction and rational use of water consumption. Through the modeling of the water consumption of tourism industry and the forecasting platform, this paper has a guiding significance for the tourism industry in the future.
This research mainly studies the applicable model of tourism industry, and selects the appropriate model to complete the construction and build a prediction platform for users.
The research results show that the five models of decision tree, decision forest, support vector machine, neural network and nearest neighbor are convenient to predict water consumption in the tourism industry. By adjusting the training parameters, the platform can be applied to the prediction of the platform, and the platform is convenient for users to use.
The feature of this article is to apply more mature machine learning and other technologies to engineering problems in the field of tourism, and give full play to its practical solution to problems, so as to achieve the function of using knowledge to serve the society.
Key Words:machine learning;water consumption prediction;wrediction platform;practical application
目录
第1章 绪论 1
1.1研究背景及意义 1
1.2研究现状与问题分析 2
1.2.1机器学习现状及应用场景 2
1.2.2研究领域问题分析 2
1.3研究内容与结构安排 2
1.3.1主要研究内容 3
1.3.2论文结构安排 3
第2章 模型构建 4
2.1前言 4
2.2特征的选择 4
2.3数据分析及处理 4
2.3.1数据的可视化预分析 4
2.3.2异常值检测及替换 5
2.3.3数据的降维 6
2.3.4数据的标准化 7
2.4模型的对比及选择 7
2.4.1 k近邻模型(knn) 7
2.4.2决策树算法 8
2.4.3随机森林 9
2.4.4支持向量机 10
2.4.5神经网络 11
2.5其他方法的结合使用 12
2.5.1 K-means方法的结合使用 12
2.5.2 文本数据数值化 12
第3章 模型检验及评价 13
3.1模型的检验方法 13
3.2模型的评价指标 14
第4章 预测平台的搭建 17
4.1 平台功能需求分析 17
4.2 UI界面制作工具的选用 17
4.2.1 python常用框架的比较选用 17
4.3 界面及逻辑的连接实现 18
4.3.1一致性原则 19
4.3.2准确性原则 19
4.3.3可读性原则 19
4.3.4布局合理化原则 19
4.3.5系统响应时间原则 20
第5章 总结 21
参考文献 22
致 谢 23
第1章 绪论
1.1研究背景及意义
在旅游领域,以往的用水没有理论的指导,造成了许多用水的浪费,在社会可持续发展的当今,结合先进的技术支持为用水提供指导,是非常重要的。
中国被联合国列为13个人均水资源最贫乏的国家之一,水少人多、水资源时空分布极不均匀,水资源短缺已成为中国经济社会可持续发展面临的重大挑战之一。在当今社会,通过结合机器学习等先进方法,进行用水量的预测可以协助水厂大大降低,用水量,在这个水资源短缺,可持续发展被提倡的社会,这将会取得巨大的收益。为缓解水资源供需矛盾、保障水资源可持续开发利用,中国早在1983年就引入了水资源配置概念,对有限的水资源进行分配,开展需求调控。20世纪90年代开始,中国实施用水定额政策,对城市生活、农业生产、工业生产制定了用水定额。到 2015 年,共有 29 个省、自治区、直辖市出台了用水定额标准。2012年,中国开始实行严格用水总量的控制制度,而加快制定高耗水工业和服务业用水定额国家标准则是这项制度的重点之一。2015年,中国已成为世界最大的国内和出境旅游消费国。旅游业对GDP的综合贡献占全国GDP总量的10.8%。旅游直接和间接就业7911万人,占全国就业总人口的10.2%。考虑到旅游业在推动中国经济发展,特别是在增加就业、缓解贫困中发挥了越来越重要的作用,中国将旅游业作为国民经济的战略性支柱产业和现代服务业进行重点发展。旅游业发展需要消耗大量的水资源。随着中国旅游业重要性的提升,其水资源消耗研究的重要性将愈加凸显。但中国现在还没有旅游业用水定额标准,这会导致无法实施旅游业水资源利用总量的控制。在此背景下,提出全面测算旅游业水资源使用量的方法,不仅可为中国设定旅游业用水定额提供数据支撑,还可为全面认识旅游业水资源使用、促进旅游业水资源可持续利用提供科学依据。机器学习的方法多种多样,如何选取模型及方法要根据实际问题的不同,进行选择,在旅游产业用水量方面,多用的预测模型有支持向量机和神经网络运用这些方法,可以克服传统回归方法的许多弊端,如传统的回归预测对于不确定的非线性系统表现非常差,而机器学习可以只通过历史数据与进行较为准确的预测。在外国机器学习算法的研究较为领先,机器学习的应用对比国内也较为早,在自动化生产等方面更是遥遥领先国内。在用水量预测方面,所用技术较为成熟简单,用水量预测也非常关键,所以在用水量预测的研究与应用是刻不容缓的。
1.2研究现状与问题分析
1.2.1机器学习现状及应用场景
机器学习根据主流分类现状结果主要可以分为强化学习、监督学习和无监督学习。监督学习是指数据是带有标记的,通过大量带有标签的数据特征进行学习,机器通过对训练集的预测,输出的结果再与期望结果相互比较进行模型的修正,将此过程多次重复,已达到训练模型进行预测帮助觉得的作用。
无监督学习主要包括分类及降维两种方法。机器拿到没用标记的数据,只能通过其自带的属性比如数据之间的距离和密度,对数据进行分类或者聚类。数据特征种类较多时,存在有效信息重复,并且计算量过大,可以通过主成分提取相关性等办法进行数据的降维处理,以达到数据维度的减少提高模型质量及训练速度。
强化学习是带有激励的,模型通过每次结果的好快反向激励模型,是模型在不断的试错中得到学习,更加接近人类的学习方式,谷歌的AlphaGo便是基于此算法。
机器学习的应用场景很多,随着现代数据量的飞速增加,机器学习在数据领域得以大方光彩。机器学习在数据挖掘与数据分析领域中发挥着极其重要的作用。数据挖掘与数据分析技术是数据分析和机器学习领域的结合,是数理统计与计算机科学技术的相结合,利用机器学习技术进行数据分析,对采集到的各类数据进行自动化的处理,同时利用数据存取技术与数据分析技术实现数据的高效读写并可视化分析建模提高模型的准确度。
1.2.2研究领域问题分析
在机器领域算法众多,预测效果参差不齐,且受到数据的影响,对于一个特定的数据集合仍没有专门的办法来选取合适的训练算法。对用待训练数据的处理也较为麻烦,在数据分析领域,需要大量的经验以指导人们清洗数据并完成模型的建立及训练。
在旅游产业用水量方面,人们较少的关注用水量的把控,致使用水的浪费,而这个问题是值得关注的,用水量预测是值得与知识相结合分析的一个领域。
1.3研究内容与结构安排
本小节主要对本文的撰写进行说明方便的读者更加容易理解本文的内容与结构。主要包含两个方面,研究内容与本文的写作安排。
1.3.1主要研究内容
本次研究是对机器学习在数据分析方面的应用研究,主要分为模型的建立及训练和用水量预测平台的搭建两部分。通过对来自水厂3年的用水量数据进行机器学习达到预测知道之后用水量的作用。本次研究数据是带有用水量标记的,主要用到机器学习中无监督学习的算法,并且结合无监督学习的方法对数据进行分析,以达到模型的建立,并且完成用水量预测平台的搭建。
1.3.2论文结构安排
论文首先从模型的构建入手,对现有常用模型进行分析,然后选用此次数据最适合的模型构建,并加以改进评价,训练模型并保存。之后完成对UI平台的搭建分析,并将平台与模型相结合。完成本次研究的所有撰写。
第2章 模型构建
2.1前言
模型的构建涉及到一系列流程:特征的选取、数据的分析、数据的预处理、数据的训练、模型的评价、数据的预测、结果的可视化,需要数理统计及编程建模等多方面知识。
2.2特征的选择
特征的选取应为与待预测值相关的数据,本次研究待解决问题为旅游产业用水量预测,其旅游产业用水量主要与旅游人数的多少有关,人们决定是否出行,取决于天气、假期的英雄,所以本次选用的数据特征有记录日期、用水量、最高气温、最低气温、星期、假日情况、天气情况。数据特征情况如下(部分):
记录日期 | 用水量 | 最高气温 | 最低气温 | 星期 | 假日情况 | 天气情况 |
20150101 | 3165 | 11 | 5 | 4 | 1 | 0 |
20150102 | 3291 | 16 | 5 | 5 | 1 | 0 |
20150103 | 3280 | 20 | 6 | 6 | 1 | 0 |
20150104 | 3185 | 18 | 11 | 7 | 0 | 1 |
表2.1部分特征数据展示
2.3数据分析及处理
2.3.1数据的可视化预分析
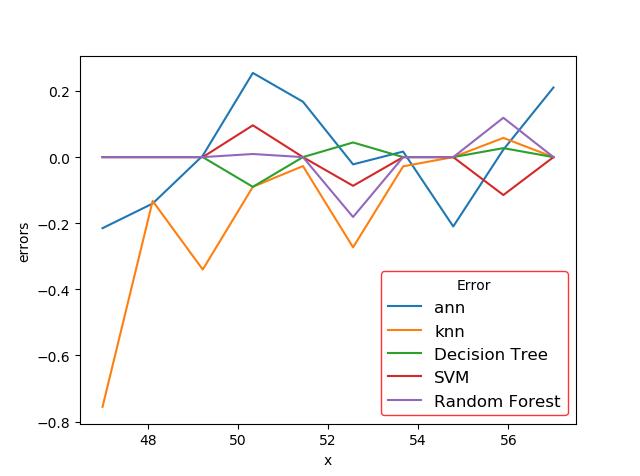
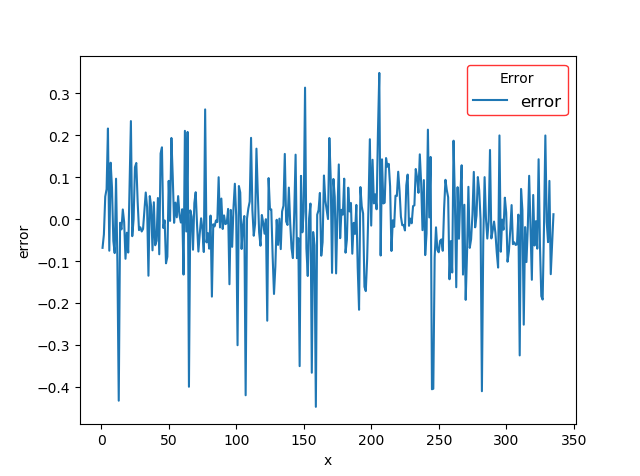
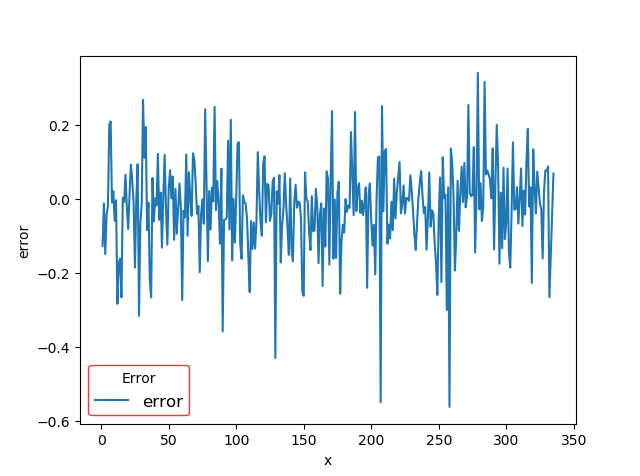
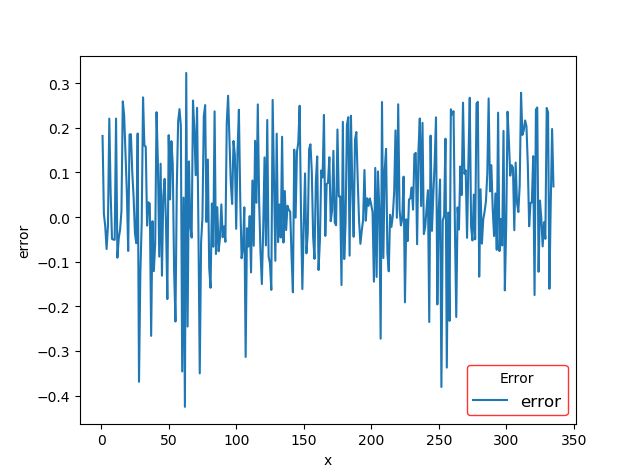
数据可视化是借助于图形化手段,将现有的数据等令人枯燥无味的数据进行图形化的展示,现如今数据量海量增加,数据与我们密切相关,但是如文字文本表格等各类数据并不能给我们直观的感受,甚至长时间观看此类数据会给我们带来疲劳的感受,为了增加了解数据的体验与效率也是为了不懂数据的人都能够看懂数据,数据可视化至关重要。数据可视化作为一个不断更新进步的技术,在许多领域有广泛的应用,在数据挖掘数据分析方面更是至关重要,本文在本次建模的开始与结果的展示都用到了数据可视化。建模的第一步是探索性数据分析,通常我们通过图标等汇总统计量进行探索性数据分析。通常来说,通过的系统的分析与可是化的方法,计算出数据的中位数均值方差,变量间的相关性分布状况等各种信息,并进行适当的可视化方便我们对数据有直观的了解,辅助之后的建模工作。本次研究通过计算各变量的均值方差判断各变量间的相关性,并绘制y值的散点图,辅助分析。在模型完成后还需要对模型的评价标准模型的预测值等进行可视化的展示,只有通过可视化的展示才能够更好的看到模型的效果。
2.3.2异常值检测及替换
异常值的出现原因主要分为两大类:人为错误,自然错误。又可以细分为:数据处理错误,数据输入错误,抽样错误,测量误差,实验误差,故意异常值,自然异常值。
异常值的判别方法有:
(1)简单统计分析,将统计数据简单的通过某种图标或者可视化展示出来,通过和合理的范围标准做比较来检查出异常值。
(2)3δ原则分析,假如数据呈现正态分布,依据正态分布的定义及性质,数据点距离平均值3δ之外的概率为 P(|x-μ|>3δ) <= 0.005 ,这属于小概率事件,所以我们可以认为发生小概率事件是发生了异常值。如果数据不呈现正态分布的规律,可以通过计算其方差均值等特征,再根据已有的经验等多方面因素,来检测数据,当数据偏离均值一定范围时,则可以认为是异常值
(3)箱型图分析,是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,通过这种方法可以检测数据的对称性和分散程度,在需要对几个样本进行比较时,使用这种方法,可以更好更直观。
异常值的常用处理方法有四种:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:
![1180120-20180806174718141-1644339311[1]](http://www.biyelunwen.org/wp-content/uploads/2020/02/lw4132_2020217202723368.png)