SPARK下面向AIS数据的流聚类算法研究与实现毕业论文
2020-04-04 10:49:54
摘 要
随着中国海运事业的蓬勃发展,国内船舶航运呈现出高速化、智能化、数字化的趋势。面对海运整体发展的新形势,船舶自动识别系统(Automatic Identification System,以下简称AIS)在海事管理领域得到广泛应用。大量与船舶相关的AIS数据不断产生,如何从海量数据集中发现有用的模式和趋势并快速有效的挖掘出有价值的信息,成为研究热点之一。聚类分析是数据挖掘与预测分析的核心问题之一,它为后续的回归分析、关联规则分析提供了基础。AIS数据流聚类算法,根据AIS流式数据高实时性的特点,通过流聚类算法将记录、观察值等分组到相似的对象集合中,将源源不断产生的流式数据集合划分成相对均匀的簇,实现簇内的记录相似度最大,簇之间的相似度最小的算法。研究表明,数据流聚类算法应用于船舶AIS数据的分析处理取得良好的成效。
本文总结研究前人的工作,并结合此次毕业设计所选取的Spark平台研究性能较高的D-Stream算法①,展开面向AIS数据流聚类算法的研究,完成如下工作:
- 面向AIS数据流的聚类算法研究。首先对船舶自动识别系统(AIS)以及本次设计的研究对象AIS数据流的特点进行介绍。然后研究两个经典聚类算法:BIRCH算法、CluStream算法,并且分别将它们和AIS数据流结合起来进行论述。通过对两个算法的深入研究总结出面向AIS数据流的D-Stream算法的改进思路;
- 面向AIS数据流的D-Stream算法的改进方法研究。首先研究改进前的D-Stream算法,分析D-Stream算法的不足。然后研究本文将使用的聚类标准以及度量聚类簇优劣的标准,并结合AIS数据的特点选取对应的标准作为后续度量算法聚类精度的评判依据。最后基于CF树型结构和双层处理架构提出面向AIS数据流的D-Stream算法的改进方法;
- Spark平台下面向AIS数据流聚类算法设计及实验验证。首先介绍Spark平台的相关内容以及经典MapReduce计算模型。然后结合Spark平台提出面向AIS数据流的改进D-Stream算法的设计与实现,最后进行实验验证,包括数据来源、相关的预处理以及实现方案并对聚类结果进行分析,对比改进前后D-Stream算法的优劣。
关键词:AIS数据流;聚类算法;Spark平台;D-Stream;
Abstract
With the vigorous development of China's shipping industry, domestic ship shipping is showing a trend of speed, intelligence, and digitization. In the face of the new situation of the overall development of maritime transport, the Automatic Identification System (AIS) has been widely used in maritime management. A large number of ship-related AIS data are continuously generated. How to discover useful patterns and trends from massive data sets and quickly and effectively mine valuable information becomes one of the research hotspots. Cluster analysis is one of the core issues of data mining and predictive analysis. It provides the basis for subsequent regression analysis and association rule analysis. AIS data flow clustering algorithm, according to the characteristics of high real-time performance of AIS streaming data, grouping records and observations into similar object sets through flow clustering algorithm, and dividing the stream data sets continuously generated by the source into relatively uniform The cluster implements an algorithm that maximizes the similarity of records within a cluster and minimizes the similarity between clusters. The research shows that the data flow clustering algorithm has been applied to the analysis and processing of ship AIS data and has achieved good results.
This article sums up the work of predecessors, and combines the D-Stream algorithm with higher performance in the Spark platform chosen for this graduation project, and develops a research on AIS data flow clustering algorithm, and completes the following work:
1. Research on clustering algorithms for AIS data flow. First, the characteristics of the AIS data stream of the ship's automatic identification system (AIS) and the design of this study are introduced. Then study two classical clustering algorithms: BIRCH algorithm, CluStream algorithm, and combine them with AIS data stream to discuss. Through the in-depth study of the two algorithms, the improved idea of the D-Stream algorithm for AIS data flow is summarized.
2. Research on improved method of D-Stream algorithm for AIS data stream. First, we study the D-Stream algorithm before improvement and analyze the shortcomings of D-Stream algorithm. Then we study the clustering criteria that will be used in this paper and the criteria for measuring the strengths and weaknesses of clustering clusters, and combine the characteristics of AIS data to select the corresponding criteria as the evaluation criteria for clustering accuracy of subsequent measurement algorithms. Finally, an improved D-Stream algorithm for AIS data streams is proposed based on the CF tree structure and the double-layer processing architecture.
3. The AIS data flow clustering algorithm design and experimental verification are shown below the Spark platform. First, the relevant content of the Spark platform and the classic MapReduce calculation model are introduced. Then, the design and implementation of improved D-Stream algorithm for AIS data stream is proposed in combination with Spark platform. Finally, experimental verification is performed, including data source, related preprocessing and implementation scheme, and analysis of clustering results. Comparison of improved D-Stream before and after The merits of the algorithm.
Keywords: AIS data flow; clustering algorithm; Spark platform; D-Stream;
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.3 本文研究内容 3
1.4 本文组织结构 3
第2章 面向AIS数据流的聚类算法研究 5
2.1 AIS数据简介 5
2.2 面向AIS数据流的BIRCH算法研究 6
2.2.1 BIRCH算法特点 6
2.2.2 面向AIS数据的CF树型结构生成算法 8
2.3 面向AIS数据流的CluStream算法研究 10
2.3.1 CluStream算法特点 10
2.3.2 面向AIS数据的双层处理架构算法 12
2.4 本章小结 13
第3章 面向AIS数据流的D-Stream算法改进方法研究 14
3.1 D-Stream算法 14
3.2 D-Stream算法分析与改进思路 15
3.2.1 聚类标准 16
3.2.2 聚类簇优劣标准 16
3.3 基于CF树型结构改进D-Stream算法 18
3.4 基于双层处理架构改进D-Stream算法 19
3.5 本章小结 21
第4章 Spark平台下面向AIS数据流聚类算法实验验证 22
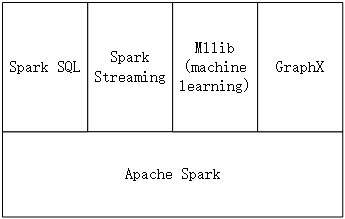
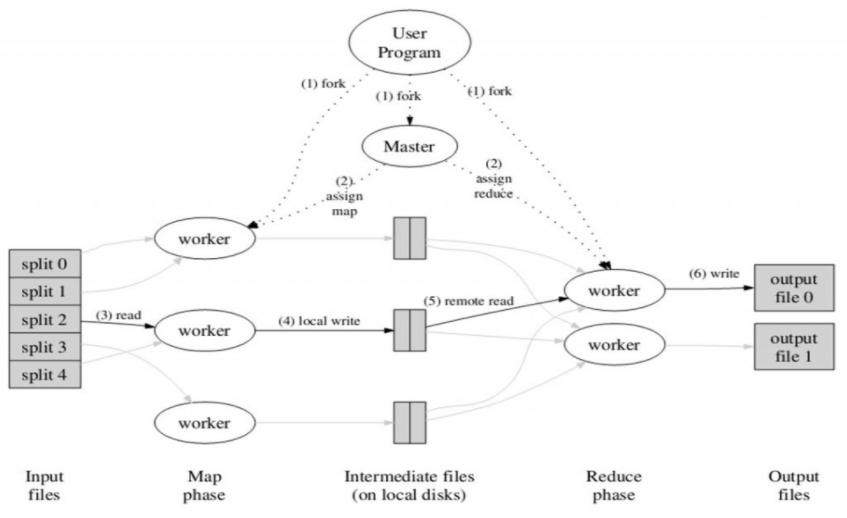
4.1 Spark平台及MapReduce计算模型 22
4.2 Spark平台下面向AIS数据的改进D-Stream算法设计与实现 24
4.3 实验平台与数据预处理 27
4.3.1 实验平台 27
4.3.2 数据来源 27
4.3.3 AIS数据预处理 28
4.4 实验方案 28
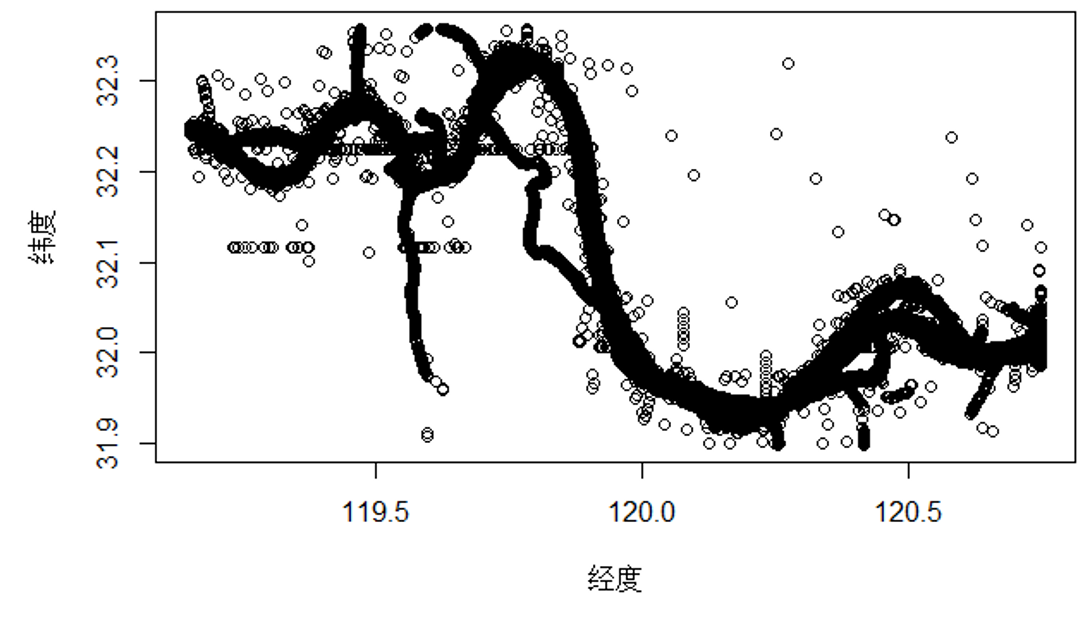
4.5 实验结果与分析 29
4.5.1 运行效率对比 29
4.5.2 聚类质量对比 30
4.5.3 实验结果分析 30
4.6 本章小结 31
第5章 总结与展望 32
5.1 全文总结 32
5.2 下一步工作 32
参考文献 34
致 谢 36
第1章 绪论
1.1 研究背景与意义
随着海运事业的不断发展,中国海运船队规模稳居世界第三位,海运船舶呈现出高速化、智能化、数字化的趋势。同时,随着经济的增长,进出港口、航道的船舶流量也不断增加,为了适应大型船舶航行需要,加强海上生命安全保障、提高船舶航行效率,建设一套性能可靠的数字助航系统迫在眉睫,AIS系统便应运而生。通过AIS系统获取AIS数据,并进行聚类挖掘,将为船舶航行轨迹的分析奠定基础,从而提高海事监管的智能化与自动化水平。
同时,依托新时代的发展,人工智能大数据领域迎来了空前的发展机遇,中国在国家战略层面上也开始了全面的部署和规划。2017年7月8日,国务院关于印发《新一代人工智能发展规划的通知》,基于大数据平台,研发高可用、高效率、高可靠的算法解决智能交通、工业建设以及国防科技等领域的问题迫在眉睫。
海上航行船舶流量巨大,拥有高精度高可用AIS系统的引导辅助不仅能够避免发生碰撞同时可以提高航行效率。依托于大数据Spark平台的分布式集群可以很好地应对AIS系统对海量实时流数据分析处理的要求。聚类分析是数据挖掘的一种重要研究方法,在网络监控日志分析、金融股市交易数据分析、电话通信业务等领域有广泛应用。但是现有的数据流聚类技术普遍忽略不确定性特征,而AIS数据却具有很强的实时性的特点,导致聚类结果与实际情况出现偏差,实际应用的参考价值低。因此,基于Spark平台研究AIS数据流聚类算法对于船舶航行的风险分析和控制具有重要意义。
1.2 国内外研究现状
国内研究现状如下:
(1)邢长征等人[1]提出一种基于密度和扩展网格的数据流聚类算法,解决现有聚类算法在计算网格密度时未考虑附近范围空间的影响因素而导致聚类边界粗糙不平滑的现象。通过将网格密度的计算范围从本网格内部合理地扩展到相邻紧凑的网格空间,动态确定网格的扩展区域,进而通过该聚类算法中引入的凝聚度标准衡量附近周围空间数据点对网格内部密度的影响。为进一步解决聚类边缘的轮廓分布不平滑的问题,使用边界点阈值距离函数从噪声数据点中分离出类的边界点,并给出改进的网格合并算法,通过簇间连通性简化簇合并的判断条件,减少算法执行时间。实验结果表明,该算法具有较高聚类效率。
(2)刘卓等人[2]针对现有的数据流聚类算法普遍忽略数据不确定性的特征,容易导致聚类结果的不合理甚至不可用的问题,提出了不确定度模型下数据流自适应网格密度聚类算法(adaptive densitv_based clustering algorithm over uncertain data stream,ADC UStream)。同时针对某些聚类算法片面考察数据不确定性且大多基于简单的K-Means算法的问题,提出在存在级和属性级不确定性统一策略下,构建不确定熵度模型进行不确定性度量,综合考察两种级别的不确定性。采用基于网格密度的聚类算法,通过衰减窗口模型设置空间和时态的自适应密度阈值,适应不确定性数据流的高实时性性和非均匀随机分布的特征。通过实验结果分析,ADC UStream算法在聚类质量和聚类效率方面都具有较好的性能。
(3)曲武等人[10] 针对传统的数据流聚类框架CluStream算法并行处理困难、可扩展性低、处理高维数据性能降低的问题提出基于云平台的LSH分布式数据流聚类算法DLCStream,引入经典的Map-Reduce框架和位置敏感哈希机制,DLCStream算法能够通过位置敏感哈希机制快速找到数据流中的聚类模式完成数据流的聚类。通过精准的理论分析和实验验证结果表明,DLCStream算法在可扩展性、聚类结果质量和高效并行处理方面有更大的优势。
国外研究现状如下:
(1)Alex R等人[7] 通过各种算法分割一个分组对象提出了聚类集成方法的想法,然后得到这些算法的结果通过共识函数进行组合得到最终的聚类结果。提出了一种以分类零件的Squeezer算法为识别功能的CEBMDC的聚类算法。设计了一个上下文感知系统(能够感知、推理和响应当前上下文信息的系统),用来进行交通事故预测和预防。在系统的思维阶段,使用动态贝叶斯网络(DBN)模型来预测事故的可能性和严重程度。并且将贝叶斯模型和参数的不确定性加入考虑范围。使得系统能够实时预测事故,并且在事故发生后进行原因诊断。
(2)Agostino Forestiero等人[11]提出一种基于数据流聚类的方法采用分散式自下而上自我组织策略的多代理系统上将相似的数据点分组。数据点与代理相关联并进行部署到二维空间,通过应用启发式策略同时工作生物启发模型,被称为植绒模型。代理移动到固定空间时间,并且当他们遇到其他代理进入预定义的可视范围时,他们可以决定组成一个群如果他们是相似的。羊群可以加入形成类似的群组。该策略允许合并基于密度的方法的两个阶段从而避免计算需要离线集群计算。实验结果表明,生物启发式方法可以在真实和合成数据集上获得非常好的结果。
总结:
(1)国内外关于数据流聚类算法的研究很多,但是针对AIS数据特点的流聚类算法研究较少,多数研究使用静态的数据集模拟动态实时数据进行分析,这对于具备高实时性的数据的分析处理并不合适。
(2)国内外关于数据点聚类标准优化,例如:从简单网格划分到网格加上扩展区域的优化;以及当出现新增数据点时如何计算它对聚类区域的影响权重包括是否重新划分聚类区域的相关研究较少。
1.3 本文研究内容
数据挖掘与预测分析作为一个高速发展的未来学科正在被各个领域广泛应用于生产实践中,它横跨统计学、数学、机器学习、人工智能等多个领域,对该技术缺乏应用的行业将会在21世纪的全球竞争中落伍。聚类分析是数据挖掘与预测分析的核心问题之一,它为后续的关联规则分析、回归分析提供了简化基础。如何利用大量的AIS数据完成轨迹聚类并优化流聚类算法提高聚类精度是本文的研究重点。本文主要完成以下几方面的工作:
(1) 本文首先总结研究前人的工作成果,介绍AIS数据流的特点,并结合AIS数据流的特点重点研究两个流聚类算法:BIRCH算法、CluStream算法。总结两个算法的可取之处,提出基于云平台的面向AIS数据流的D-Stream算法的优化改进思路。
(2) 研究面向AIS数据流的D-Stream算法改进,首先研究D-Stream算法,说明D-Stream算法存在的不足,根据前文研究总结得出的结论提出D-Stream算法的改进思路。针对本文使用的基于内存运算的Spark平台,由于内存相较于磁盘而言存在价格高容量小等不足,因此运用BIRCH算法的CF树型结构对原始海量数据进行汇总统计信息提炼以达到减小内存的负载同时提高整体性能的目的。针对AIS数据流高实时性、数据量巨大的问题单遍处理往往不能够充分挖掘数据的价值,因此利用CluStream算法的经典双层处理架构对D-Stream算法进行优化。同时说明聚类簇划分标准用以对原始数据进行划分簇以及度量聚类簇优劣的标准用以衡量聚类算法的聚类质量。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: