基于OpenAI Gym平台的乒乓球对弈算法设计与实现毕业论文
2021-11-28 21:24:02
论文总字数:27900字
摘 要
强化学习问题在自动控制、信息论、博弈论等领域都有应用,被用于解释有限理性条件下的平衡态、设计推荐系统和机器人交互系统。最近的一些强化学习算法在一定程度上能够被看作可以解决复杂问题的通用智能,这些算法可以在围棋和电子游戏(如星际争霸II和王者荣耀)中达到甚至超过人类水平。在不久的将来,深度强化学习将会在许多领域发挥重要作用。
最近几年,基于端到端的深度强化学习在电子游戏上取得了令人瞩目的成果,包括棋类游戏、第一人称射击游戏Atari 视频游戏、即时战略游戏等。它们不需要手动提取特征即可自动完成游戏学习,在个别游戏中已经超越了人类顶尖玩家。现在有很多公司组织已经开源了深度强化学习算法的测试平台,本文将基于Open AI的gym中的Pong电子游戏来寻找一个可行的游戏策略,使得该策略可在游戏Pong中达到超越人类玩家的水平,因此本文研究内容如下:
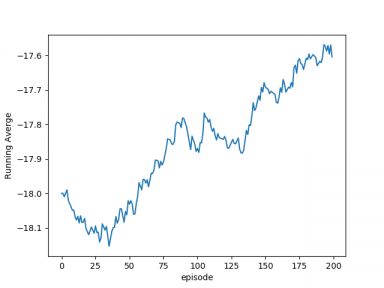
首先,搭建了gym平台,这是运行乒乓球虚拟环境必不可少的组件,它让本文可以只关心了强化学习算法的实现和测试,而无需把时间花在乒乓球虚拟环境的构件上;其次,本文通过现有强化学习算法训练能够实时且稳定控制Pong游戏获得胜利的agent,这是本文的核心任务之一,包括了游戏环境的MDP建模,算法原理的代码实现,agent的模型训练等;在获得不同强化学习算法构建的agent模型后,本文对比分析了这些算法的在Pong游戏上的表现,这为改进强化学习算法提供了可能;最后,本文尝试将模型和游戏部署在PC平台,以达到和人类对抗的目的。
本文的特色在于算法的输入仅是纯像素,这和人类实时感知的信息是相同的,但智能体却能通过一些时间的训练达到超越人类的水平。游戏环境搭建方面,Open AI中的gym模块提供了很多游戏接口,本文仅研究Pong这一款游戏的控制策略的生成算法;本文的工作是在虚拟环境Pong中对一系列强化学习算法做出验证,这有利于强化学习能够低成本应用在现实生产活动中,本文研究成果能够丰富游戏领域强化学习的理论与方法,对研究通用智能具有一定的实际意义。
关键词:强化学习;游戏;策略控制;卷积神经网络;像素输入
Abstract
Reinforcement learning problems have applications in fields such as automatic control, information theory, game theory, etc., and are used to explain the equilibrium state under the condition of limited rationality, design recommendation systems, and robot interaction systems. Some of the recent reinforcement learning algorithms can be regarded as general intelligence that can solve complex problems to a certain extent. These algorithms can reach or exceed human levels in Go and video games (such as StarCraft II and King Glory). In the near future, deep reinforcement learning will play an important role in many fields.
In recent years, end-to-end deep reinforcement learning has achieved remarkable results in video games, including board games, first-person shooter Atari video games, and real-time strategy games. They do not need to manually extract features to complete the game learning automatically, and have surpassed the top human players in individual games. There are many companies and organizations that have open sourced a test platform for deep reinforcement learning algorithms. This article will find a feasible game strategy based on the Pong video game in the Open AI gym, so that the strategy can reach the level of surpassing human players in the game Pong. , So the content of this article is as follows:
First, the gym platform is built, which is an indispensable component for running the virtual environment of table tennis. It allows this article to focus only on the implementation and testing of reinforcement learning algorithms without having to spend time on the components of the virtual environment of table tennis. This article trains agents that can control Pong games in real time and steadily through existing reinforcement learning algorithm training. This is one of the core tasks of this article, including MDP modeling of the game environment, code implementation of algorithm principles, and model training of agents ; After obtaining the agent models constructed by different reinforcement learning algorithms, this article comparatively analyzes the performance of these algorithms on Pong games, which provides the possibility of improving reinforcement learning algorithms; Finally, this article attempts to deploy the models and games on the PC platform. In order to achieve the purpose of confronting humanity.
The characteristic of this article is that the input of the algorithm is only pure pixels, which is the same as the information that humans perceive in real time, but the agent can reach beyond human levels through some time of training. In terms of game environment construction, the gym module in Open AI provides many game interfaces. This article only studies the generation algorithm of the control strategy of Pong; the work of this article is to verify a series of reinforcement learning algorithms in the virtual environment Pong This is conducive to the application of reinforcement learning at low cost in real production activities. The research results of this paper can enrich the theory and methods of reinforcement learning in the game field, and have certain practical significance for the study of general intelligence.
Key Words:Reinforcement learning; game; strategy control; convolutional neural network; pixel input
第1章 绪论
1.1 研究背景和研究意义
随着移动通信技术和互联网技术的不断发展,手机和各种电子设备越来越必不可少,而电子游戏也已经成了人们生活中的一部分。玩家们通过游戏来进行社交,同时也是人们闲暇时候的一种娱乐方式。当然,游戏产业一路蓬勃发展,怎样为游戏玩家提供具有差异化的游戏体验是目前游戏设计和开发面临的一大挑战。近年来,随着深度学习和强化学习的崛起,深度强化学习给研究人员在游戏中采用机器学习的方法提供了新的解决思路。
本文尝试结合将深度学习和强化学习结合并将其应用于Pong视频游戏中,所以本文将深入研究一个有趣问题:如何教机器玩视频游戏。从这个任务入手尝试结合深度学习的模型和强化学习的模型并在各个视频游戏中进行测试,并对比分析经典的几种深度强化学习算法。在弄清楚机器是如何玩视频游戏这个问题之前,首先从人类玩家是怎么进行游戏的开始分析:
- 玩家点击手柄中的开始按键,游戏开始场景变换,玩家捕捉到画面的变化,大脑会对收到的图像信号进行处理。
- 大脑将图像信号转换为游戏中的语义信息,这些信息主要包括敌我位置,物体类别等。
- 玩家将依靠自己的认知经验选择一个操作,该操作通过控制器(手柄)传递到游戏内部。
- 游戏环境接收玩家指令并处理后,游戏场景将自动切换到下一帧,此时游戏可能回馈玩家一定的回报,如金币增加、敌人死亡等。循环往复,直到游戏结束。
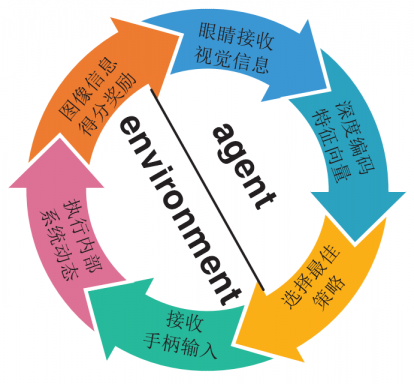
- 视频游戏流程图
图1-1描述了进行视频游戏的整个过程,左半部分属于玩家无法干涉的游戏内部境,玩家控制的只是上述游戏循环的右半部分。即从接收视觉信号进行处理,到通过手柄输出到游戏。而执行玩家指令并切换到下一帧场景,以及计算玩家得到回报是游戏本身负责的。
人类玩家实际需要操作的过程就如上所述,接下来使用agent去模拟人类玩家,也就是让agent去替代人类玩家进行视频游戏。通常将机器玩家称为agent(又称智能系统或智能体)。与人类玩家的操作相比,agent需要负责以下方面:
- 接收游戏场景信号和回报信号,对收到的视觉信号进行处理与理解,包括降维,高层特征抽取等,例如识别敌我位置,场景物体等。
- 根据历史信息以及累积的经验,对当前游戏场景选择合理的游戏操作。
- 将动作通过手柄传递给游戏模拟器。
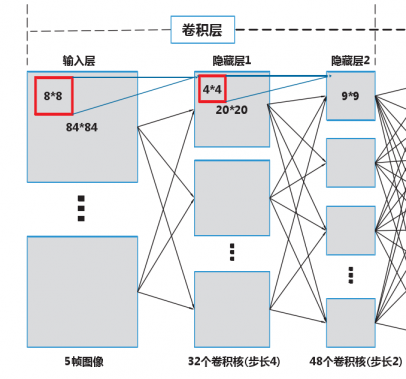
人类玩家通过逐渐地熟悉游戏内容可以玩的越来越好,本文的目的在于通过对强化学习算法的研究希望agent也能和人一样通过学习来提高游戏水平。人脑在对图像的特征提取上具有优异的能力,传统强化学习不足的地方便是处理这种原始数据。随着DL和RL的发展,现在对原始图像进行特征提取的部分不再由人工特征完成而是由DL来完成。将DL强大的特征提取能力和RL的环境学习能力结合并应用于视频游戏是本文的重点研究内容,将这样的模型称为深度强化学习(Deep Reinforcement Learning,DRL)模型,同时我们相信这项技术也可以通用到机器学习的各个领域中。
本文关于乒乓球对弈算法设计与实现能够丰富游戏领域强化学习的理论与方法,在模拟环境或游戏上取得成果之后,转移到现实生活中就可以创造巨大的利益,,比如为玩家提供差异化的游戏体验。
1.2 国内外研究现状
近年来,深度强化学习的研究备受瞩目。特别是,谷歌在国际性期刊《自然》上发表的论文中首次将深度学习与强化学习结合后,形成的深度强化学习智能体在电子小游戏上的表现超越了人类,之后AlphaGo和AlphaZero的出现,更让大家了解到深度强化学习的作用,目前在深度强化学习的研究领域的主要研究平台由视频小游戏或棋类游戏中转移到了复杂的实时策略游戏中,最有代表性的就是星际争霸游戏。然而,要想在实时策略性游戏中取得较好战绩,就需要从多个方面进行研究,工作量是非常巨大的,比如,运用机器学习算法对游戏的整体策略进行规划,对游戏的结果进行估计,对智能体行为的可解释性进行研究。目前,深度强化学习的研究主要在微型操作场景中,其主要包含的内容就是单智能体的行为决策问题以及多智能体之间的合作与竞争问题。接下来,本小节将从这两个方面介绍国内外研究现状。
深度强化学习获得飞速发展是在2015年之后,谷歌团队基于非常经典的动作值函数学习(Q learning)算法[16],将其与深度学习结合起来进而提出的深度动作值网络(Deep Q Network)[17]算法达到了在雅利达视频小游戏上超过人类成绩的水平。在此之后,深度动作值网络算法被应用于很多小游戏,比如,愤怒的小鸟[18],并在此之上也取得了超越人类水平的成绩。随之很多改进版本的深度动作值网络算法就被提出了,比如,经验回放池中的数据读取不再是随机读取,而是为数据赋予不同的读取权限[19];为解决估计过高问题,提出的双重深度动作值网络算法[20],为了进一步精确动作值函数,提出Dueling网络架构[21]等。随着深度动作值网络算法的不断改进,研究者们发现,深度动作值网络算法比较突出的缺点就是当行为决策的动作空间是连续型动作空间时,算法就会遭遇维数灾难问题,为了解决此问题,就有人结合确定性策略梯度算法[22]和深度动作值网络算法提出了深度确定性策略梯度算法[23],适用于具有连续动作空间的情形,解决了维数灾难的问题,成为现在经典强化学习算法之一。
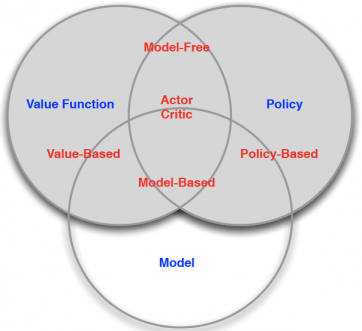
深度动作值网络这类强化学习算法通常称为基于值函数的算法,即选择使值函数最大的动作来不断更新行为策略。与深度动作值网络算法不同的另一个类别的算法策略梯度算法,其本质是直接根据强化学习的目的,确定目标函数为最大化未来收益,然后运用梯度上升法,不断更新策略的参数,以获取最优策略的方法。原始的策略梯度算法,也有很多不足之处,比如方差过大的问题[24],而之后提出的行动者评论家算法[25]就有效的缓解了该问题的影响。此后,针对不同的方面进行优化,策略梯度类算法也得到很快的发展。策略梯度算法还有一个本质的优点就是既支持离散动作同时也支持连续性动作,而且其本身的算法学习速度要比深度动作值网络算法的速度快很多。
请支付后下载全文,论文总字数:27900字
相关图片展示: