基于k-匿名模型的个性化位置隐私保护算法的研究毕业论文
2020-04-04 10:50:33
摘 要
自从智能手机飞速的普及,为了迎合人们的需求,以及移动技术的飞速发展,智能手机上越俩越多关于位置服务的应用产生,比如手机打车类的、点餐外卖类等,这些应用为人们的生活带来了非常多的便利,但人们在享用这些便利的时候,位置隐私泄露的问题就产生了。人所处的位置或者所经过的地方,往往会让别人分析出更深的关于用户的信息。比如在公司点外卖的时候,如果别人获取到了这个信息就会让别人知道你是从事哪个职业的、在比如别人根据你的日常出行路线,也可以分析出你的职业等信息。为了让人们享受位置服务带来的便利的同时又不会让自己的隐私信息暴露,越来越多的人开始研究基于位置隐私的保护,让用户大胆放心的使用各种基于位置服务的应用。
本文主要进行了如下工作:
1.对隐私保护的常用的三种框架进行了总结,对基本的K-匿名模型进行了分析。
2.对一种非常经典的个性化位置隐私保护算法进行了研究。
3.尝试设计了一种新型的个性化轨迹隐私保护算法。
Abstract
Since the popularity of smart phones, in order to cater to the needs of people and the rapid development of mobile technology, more and more applications for location services have emerged on smart phones, such as mobile phone taxis and order takeaways. These applications are for people. Life brings a lot of convenience, but when people enjoy these conveniences, the problem of leakage of location privacy arises. Where people are or where they go, they often allow others to analyze deeper information about users. For example, when a company takes delivery, if someone else obtains this information, it will let others know which career you are in. For example, according to your daily travel route, you can also analyze your occupation and other information. In order to allow people to enjoy the convenience of location services without exposing their privacy information, more and more people are starting to study the protection based on location privacy, allowing users to use their location-based applications with confidence.
This article mainly carried out the following work:
1. The three commonly used frameworks for privacy protection are summarized, and the basic K-anonymity model is analyzed.
2. A very classic personalized location privacy protection algorithm was studied.
3. Attempts to design a new personalized track privacy protection algorithm.
Key Words:k-匿名,个性化,轨迹,基于位置服务
目录
第1章 绪论 1
1.1研究的背景及意义 1
1.2国内外研究现状 2
1.2.1针对定位引起的隐私研究 2
1.2.2针对位置信息传送过程中引起的位置泄露 3
1.3 本文的研究内容和主要贡献 3
1.4 论文的组织结构 4
2.k-匿名位置隐私保护模型的概念 5
2.2 k-匿名模型的概念 6
2.3 常见的攻击模型 7
2.3.1被动攻击模型 7
2.3.2主动攻击模型 7
第3章 个性化隐私保护相关算法 8
3.1基于位置语义的路网位置隐私保护算法 8
3.1.1个性化需求 8
3.1.2算法基本思想 8
3.1.3算法的优缺点 9
3.2基于位置语义的路网位置隐私保护算法 9
3.2.1个性化需求 9
3.2.2 算法的基本思想 10
3.2.3算法的优缺点 10
第4章 基于路段相似度的个性化轨迹匿名 11
4.1相关概念 11
4.2隐私度量 12
4.3算法描述 13
第5章 实验结果分析 15
5.1实验结果 15
5.2结果分析 17
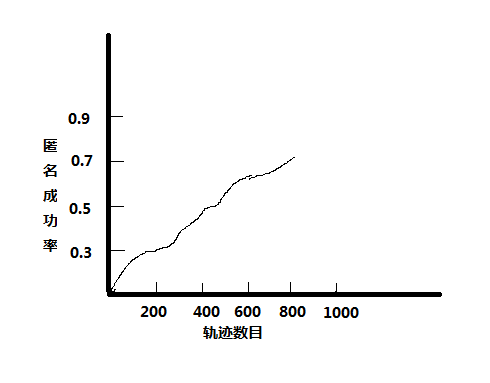
5.2.1轨迹数据集对实验结果的影响 17
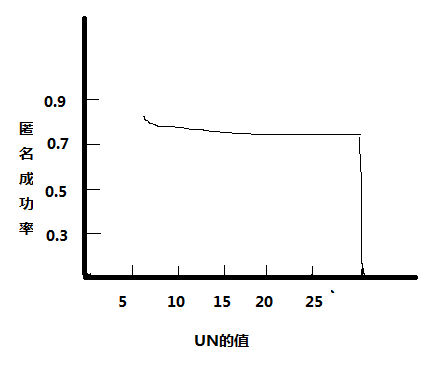
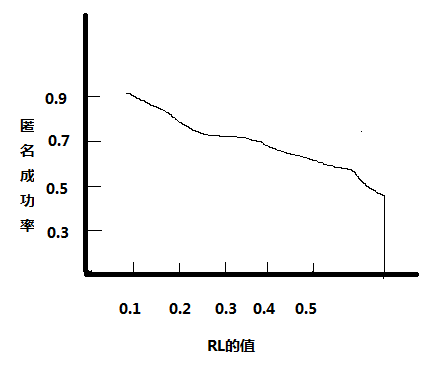
5.2.2用户的个性化需求对匿名成功率的影响 17
第6章总结与展望 19
6.1总结 19
6.2展望 19
参考文献 20
致谢 21
第1章 绪论
1.1研究的背景及意义
随着智能手机的普及,移动互联网飞速发展,手机上很多APP都需要获取到自己的位置信息来提供服务。比如各种地图APP需要通过获取当前位置来实现导航功能;ofo小黄车需要通过获取用户位置来寻找到离自己最近的小黄车。因为用户想要更好的找到自己要查询的对象或者获得更具体的路线,所以用户在享受此类服务的时候,会把自己的精确位置发送给位置服务提供商,以便获得更好的服务质量。当一些攻击者通过攻击获取到用户的位置信息后在结合一些已有的知识背景,就会推出用户的很多信息,比如通过知道用户的精确位置在学校就可以知道该用户是一名学生、通过知道用户查找的目标是医院就可以知道该用户或者用户亲朋好友的身体状况是否良好等,这样会导致自己的隐私完全被别人获取了,所以人们既想有非常好的位置服务质量,又想自己的隐私不被别人获取,这对位置隐私保护提出了一个非常严峻的挑战。图1位常见的LBS服务结构。
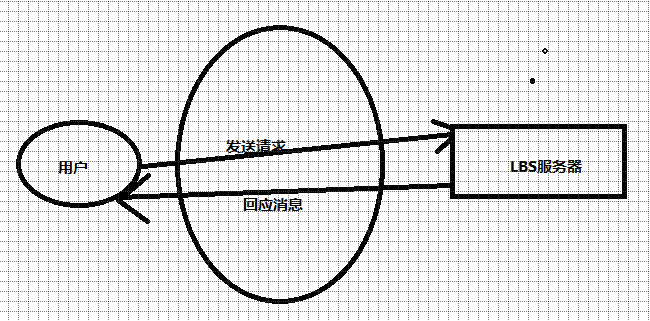
图1.1位置服务结构图
位置隐私保护有几种常用的模型:
1.k-匿名模型:把用户的真实位置匿名成一个非常模糊的位置范围,并且使得该范围包括K个用户的位置,并且此时攻击者无法将该用户与其他的(K-1)个用户区分开来,则称此保护满足K-匿名模型
2.位置l-差异性模型:要求匿名区中的用户既要满足K-匿名模型还要求匿名区域中包含l个不同的物理/实际位置。
3.查询m-不变性模型:要求匿名区中的用户至少有m个用户的查询结果是一致的。
4.查询p-敏感模型:匿名集中所有用户的敏感查询的个数与匿名集中用户个数的商要小于p,则该匿名集满足p-敏感模型。
k-匿名模型是位置隐私保护中比较经典的一种,也是比较基础的一种。但这个模型直接用在生活中缺点还是很明显的:匿名速度跟不上用户的需求、匿名的成功率比较低、系统开销比较大、抗攻击能力比较差。如何提高匿名速度、如何提高匿名成功率、如何提高匿名的抗攻击能力、如何使匿名结果满足用户的个性化需求成为了一个非常难已解决的问题。
研究动机:
- 研究并实现基于位置语义的路网位置隐私保护算法这一个性化的位置隐私保护算法
- 尝试设计一种新型的个性化的轨迹隐私保护。
1.2国内外研究现状
目前在位置隐私保护的领域内[,主要针对二个方向:1.定位阶段引起的位置隐私泄露。2.在位置信息传输过程中引起的位置泄露。
1.2.1针对定位引起的隐私研究
用户的精确定位往往是很难获取的,现代定位技术往往采用锚结点的方法。这些定位算法需要输入锚结点的位置信息,进行处理之后再将目标的精确位置输出。在此过程中输入的锚结点的位置以及输出的目标的精确位置可以被暴露出来,从而造成隐私泄露。文献[1]提出了一种PriWFL算法来解决定位阶段的隐私泄露,其主要解决的是室内定位过程中会产生的位置泄露问题。
由于当前的定位主要是通过GPS来获取自己的定位,所以这类方向的研究目前好像比较少,但还是要提高警惕。
1.2.2针对位置信息传送过程中引起的位置泄露
针对位置信息传送过程中引起的位置泄露是LBS服务过程中最可能发生的。所以国内外很多专家的研究都是关于这一块的。按照请求方式的不同,又可以将此类分为单次请求和连续请求。目前针对单次请求的研究算法已经有很多被提及出来了。比如文献[2]提出的一种考虑了位置语义的基于k-匿名的能够满足用户个性化需求的算法,以及文献[3]提出的一种通过熵来选择匿名区域的k匿名算法。当然还有文献[4]所提出的一种L2P2算法等。这些算法都是为了防止用户的位置隐私被非法攻击者获取。
对于连续请求的位置隐私保护,要对用户的轨迹进行保护,防止非法攻击者通过用户的轨迹信息推测出用户的个人隐私。文献[5]提出了一种VAvatar方法来保护轨迹隐私;文献[6]采用假位置的思路,使用假的轨迹信息来代替真实轨迹信息,从而保护用户的轨迹信息安全。文献[7]采用了一种将K匿名模型与轨迹隐私保护进行结合的方法,对用户的真实轨迹信息进行匿名,从而保护了用户的轨迹信息。还有王杰[8]等人提出的一种多路径轨迹保护算法,主要思想是生成一组假轨迹,从而达到对轨迹信息的保护。
位置隐私保护越来越受到世界各国学者的注意,在国内各大知名高校都开展了关于位置隐私保护的工作。同时人们对位置隐私保护也有了自己的一些要求,所以如何既满足用户的隐私保护又可以满足用户自己的一些需求的隐私保护算法越来越受到学者的关注。
1.3 本文的研究内容和主要贡献
本文主要研究:对k-匿名位置隐私的模型进行掌握,研究一些现有的考虑用户个性化隐私需求的算法,并且尝试设计一种新型的基于K-匿名模型的个性化轨迹隐私保护方法。
本文的主要贡献如下:
- 对k匿名模型位置隐私保护进行了概述,对集中常见的个性化位置隐私保护算法进行了优缺点分析
- 提出了路段相似度的概念,因为当轨迹中路段相同的数目越多的时候,则被攻击者识别出的可能性越低。
- 提出了一种基于路段相似度的个性化位轨迹保护算法,在选择其他k-1个匿名轨迹的时候,采用的是路段相似度来判断2条轨迹是否可以作为同一个匿名集。
1.4 论文的组织结构
本文由六章组成:
第一章为绪论:简要介绍关于位置隐私保护的背景,对国内外研究现状进行了概括,对研究内容进行了描述。
第二章为隐私保护的相关知识点的概括,主要有对位置隐私保护的框架进行了描述,包括:独立结构、中心服务器结构、分布式点对点结构。对K-匿名模型进行了介绍。最后对常见的攻击模型进行了介绍,攻击模型可以分为主动攻击模型和被动攻击模型。
第三章对一些常见的个性化位置隐私保护的个性化需求,基本思想,优缺点进行了描述。
第四章针对基于路段相似性的个性化轨迹隐私保护方案设计。本章主要对一些概率的定义进行介绍,然后对算法进行了描述。
第五章对第四章的算法进行了结果分析,首先是描述了匿名的运行结果,然后对匿名结果进行了更具体的分析。
第六章是总结与期望,对自己这段时间的工作进行了总结,然后是对自己之后的改进提出了一个更具体的期望。
2.k-匿名位置隐私保护模型的概念
2.1位置隐私保护知识的储备
基于位置的服务指的是,用户将自己的精确位置通过无线传输网络发送给位置服务商,位置服务商根据用户的位置以及上下文信息进行处理从而得到用户想要的信息,然后将信息返回给用户,从而使用户享受到良好的服务。基于位置的服务可以分为几种不同的类型,比如根据信息的获取方式不同可以分为主动获取服务和被动获取服务、按照用户查询的要求可以分为点查询和连续查询二类。基于位置的服务往往分为几步:①用户通过定位获取到自己的准确的位置信息并将其发送给LBS位置服务器。②LBS根据接受到的用户位置信息以及一些上下文信息计算出用户需要的结果,③用户将查询的结果发送给用户。因为不同的位置所返回的结果可能会有不同,所以用户发送的位置越精确,用户可以得到的服务质量就越高。但是此时被攻击成功的可能性就越大。
位置隐私保护的基本框架包括三个基本框架:
- 独立结构:独立结构中只有用户的移动终端和位置服务器,此时对位置信息进行保护主要通过客户的移动终端,也就是将隐私保护代码放在客户端中,该结构的流程具体如下:首先,用户得到自己的位置信息以及用户自己输入的上下文信息,此时并不会直接将数据发送到LBS中,而是先通过客户端中的隐私保护代码对数据进行匿名处理或者其他操作从而得到一个匿名集,之后在将匿名集发送到LBS中,LBS处理匿名集并得到一个模糊的候选集并将候选集返还给终端,终端在得到候选集后会根据用户的真实位置对候选集进行处理从而得到用户真正需要的结果,该结构虽然可以有效的防止位置信息泄露,但是对移动终端的性能要求比较高,因为移动终端需要在较短的时间内完成匿名操作。
- 中心服务器结构:中心服务器结构是根据独立结构的缺点(对移动终端性能要求比较高),在客户端和服务器中间加入一个计算能力比较强的并且可信赖的匿名服务器,从而降低了对移动终端的性能要求将移动终端的性能要求转到匿名服务器中。该结构的流程具体如下:首先,用户得到自己的位置信息以及用户孫输入的上下文信息并将这些信息发送给匿名服务器,然后匿名服务器对用户的位置信息进行匿名化操作从而形成一个匿名集,之后匿名服务器将匿名集发送到LBS中,LBS在对匿名集进行处理从而得到一个模糊的候选集,匿名服务器在得到候选集后还得根据用户的实际位置对候选集进行筛选最后得到用户想要的结果并发送给用户。
分布式点对点结构:分布式点对点结构和独立结构在模型上比较相似,都是客户端服务器结构,不同的是分布式点对点结构通过P2P通信技术,使得各个用户自己的位置信息可以相互获取,所以可以快速的形成匿名集并发送给LBS。该结构的流程如下:首先用户获取到自己的位置信息,然后根据P2P通信技术获取到其他K个用户的位置信息从而形成匿名集并发送给LBS,LBS返回模糊候选集后,客户端通过用户的真实位置对候选集进行筛选从而得到用户真正想要的结果。
2.2 k-匿名模型的概念
k-匿名在隐私保护中的定义是使每个个体的敏感属性都隐藏在包含k个个体的群体之中,使该个体的敏感属性被攻击到的概率为1/k。将k-匿名技术在位置隐私保护中就形成位置-k匿名。由于在现实生活中第三方是无法完全信任的,将自己的信息完全暴露在LBS会严重危害到用户的位置隐私。所以我们的算法主要采用中心服务器结构,也就是在客户端和位置服务器中间加入一个可信赖的匿名服务器。这样可以保证位置服务器获取到的并不是用户的真实位置。
下面介绍一种普通查询的k-匿名模型的算法:
输入:用户的真实坐标p(x,y),三方提供的用户分布图T,匿名集的大小k值,当前匿名集CRS
输出:匿名集R((x1,y1),(x2,y2)…(xk,yk))
步骤1:另CRS=空
步骤2:在图中寻找与用户位置最短的其他用户坐标q(X,Y)
步骤3:CRS=CRS∪q
步骤4:将CRS中的元素值与K进行比较如果不满足k值则继续调用步骤2、3
步骤5:return CRS
该算法虽然可以简单的对用户的位置信息进行匿名,但抗攻击能力不是很强,而且用户无法自己定义自己的隐私保护要求,所以在实际的生活中并不能通过这种简单的匿名算法对用户信息进行匿名。
匿名算法的效率主要根据用户自身定义的需求来判断,主要根据匿名的时间,匿名的成功率,匿名的结果是否满足用户的具体需求来判断的。
。
2.3 常见的攻击模型
2.3.1被动攻击模型
被动攻击指的是攻击者收集用户所发出的匿名信息,然后根据一些背景知识对匿名信息进行分析从而推知用户的真实位置。恶意攻击者可以通过对自己的了解,以及一些敏感的位置点等来推测出用户的相关信息被动攻击主要包括以下三种
- 社会关系攻击:恶意攻击者通过截获用户目标的社会关系,在根据与其有社会关系的人的位置来得到用户的信息,比如已知用户和一个位置信息被暴露的用户是同事,所以恶意攻击者也可以推知用户的具体职业。
- 基于语义的攻击:攻击者利用匿名区域所在的地理位置和背景知识从而缩小匿名范围,最后成功推出用户的真实位置。比如攻击者知道今天属于春节,但是用户的匿名区域还出现在学校周围则可以推测出该用户并不是学生而是居住在学校周围的用户。
- 伪装用户攻击:伪装用户攻击是一种专门针对分布式点对点结构的攻击模式,因为点对点结构的用户通过P2P是可以知道其他用户的位置信息,因为点对点结构要求系统中的所有用户是彼此信任的。所以该攻击很容易实现。
2.3.2主动攻击模型
主动攻击模型中,攻击者不仅只根据自己的背景知识来获取用户的真实位置,还试图发一些干扰信息给匿名服务器,试图破坏匿名效果,从而获取到用户的真实信息。比较常见的主动攻击模型是洪水信息攻击。这种攻击方式主要是发送大量的虚拟位置信息和其他无用信息。这些信息有可能被包含到匿名集中,从而可以进行排除,达到获取用户真实位置的目的
第3章 个性化隐私保护相关算法
上一章介绍了基本的K-匿名模型但是对个性化的需求并没有更好的实现,本章将会对现有的考虑了个性化需求的位置隐私保护算法进行归纳。
3.1基于位置语义的路网位置隐私保护算法
本算法主要采取的是中心服务器结构,前面已经介绍过了就是在客户端和服务器之间加入一个可信赖的匿名服务器。
3.1.1个性化需求
对于一个用户而言,这个算法的隐私需求是由用户输入的一组数据PRu(UN, SN, SENu)表示。
UN指的是匿名中的用户数目,是一个基于k-匿名模型的体现,UN的值就类似于K-匿名模型中的K,该值可以保证用户在匿名集中与其他k-1个用户无法进行区分。从而达到保护的目的,该需求是位置隐私保护中最基本的需求。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: