基于实体类EJB和Oracle数据仓库的一款CS数据挖掘系统的设计与开发毕业论文
2020-02-23 18:21:27
摘 要
在电信系统中,工作人员每每需要对用户收费时,都是依据其登入登出记录计时的。登录日志中记载了用户的登入记录和登出记录,依据其对应关系进行一一配对,最终组合成一条条完整的登录记录。用户登录名,登入时刻,登出时刻,登录时长,登录终端机器IP等信息组成一个完整的登录记录。理想状态下,在配对的时候,用户的一条登入记录跟一条登出记录是一一对应的,但有时候会出现一些异常,例如有可能在我们收集信息时用户尚未登出,所以日志文件中就没有登出记录与登入记录进行配对。所以我们将这些登入记录先保存在一个特定的文件夹中,等到下次采集到能匹配的记录在配对。在整个电信系统中,这些记录肯定是数不胜数的,单纯的依赖人力手工费时费力,还容易忙中出错。这时,一个具体的系统——数据挖掘系统(DataMiningSystem)就应运而生,这个系统应该可以自动,较快速而准确的完成这些功能。在该系统中,通过互联网将对应好的用户登录记录发出到采集系统服务器,配好对的用户登录记录数据就会被服务器端接管,然后数据库将其保存到用户登录记录明细表中,而最终,通过整合用户登录记录明细表中的信息就可以得到用户登录日报表,月报表和年报表。
关键词:数据挖掘;客户端;服务端;
Abstract
In the telecommunication system, when workers need to charge users, they are all clocked according to their log-in and log-out history. The login log records the user's log-in and log-out records, and performs pairing based on their corresponding relationship, and finally combines into a complete log-in record. User login name, login time, logout time, login duration, login terminal machine IP and other information form a complete log-in record. Ideally, when pairing, a user's login record corresponds to a logout record, but sometimes there will be some anomalies. For example, the user may not log out when we collect information, so the log file There are no logout and log records to pair. So we will first save these login records in a specific folder and wait until the next record that matches can be matched. In the entire telecommunication system, these records are certainly innumerable, and relying solely on manpower is time-consuming and laborious, and it is easy to make mistakes in the process. At this time, a specific system, DataMiningSystem, came into being. This system should be able to complete these functions automatically and quickly and accurately. In this system, the corresponding user login record is sent to the collection system server via the Internet. The user login record data that is properly paired will be taken over by the server, and the database will save it to the user login record list. , You can get user login date, monthly report, and annual report by integrating the information in the user login record details.
Key Words:Data ming;client;serve
目录
摘要 I
Abstract II
第1章 绪论 3
1.1研究背景 3
1.2国内外研究现状 3
1.3研究目的及意义 4
1.4论文组织结构 5
第2章 理论部分 6
2.1数据挖掘基本知识 6
2.2数据挖掘功能 6
2.2.1概念描述:定性与对比 7
2.2.2关联分析 7
2.2.3分类与预测 7
2.2.4聚类分析 8
2.2.5异类分析 8
2.2.6演化分析 8
第3章 设计部分 9
3.1开发平台 9
3.1.1 J2EE平台的主要技术 9
3.1.2 J2EE平台应用程序的开发工作 10
3.1.3总结 10
3.2系统需要实现的功能 11
3.3系统用例 12
3.3.1用例图 12
2.3.2用例描述 12
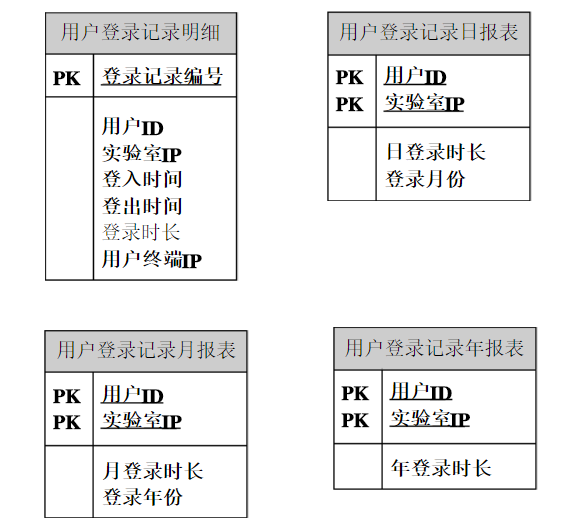
3.4数据库表设计 17
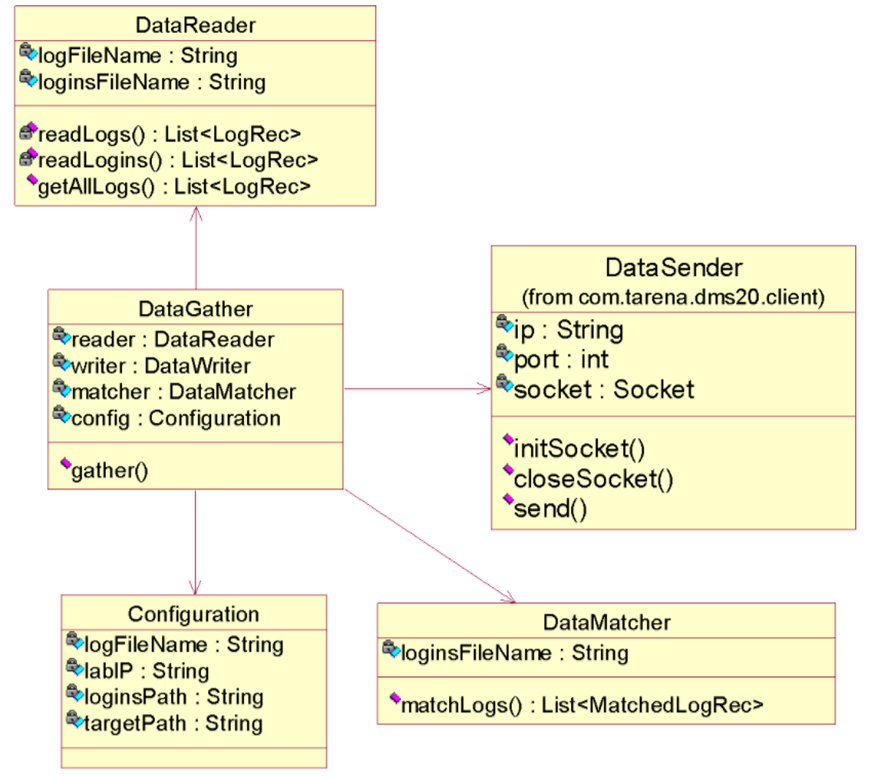
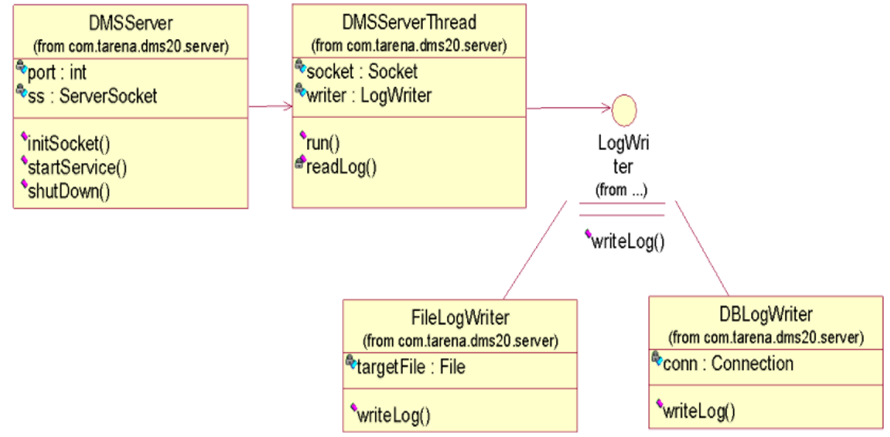
3.5总体类图 19
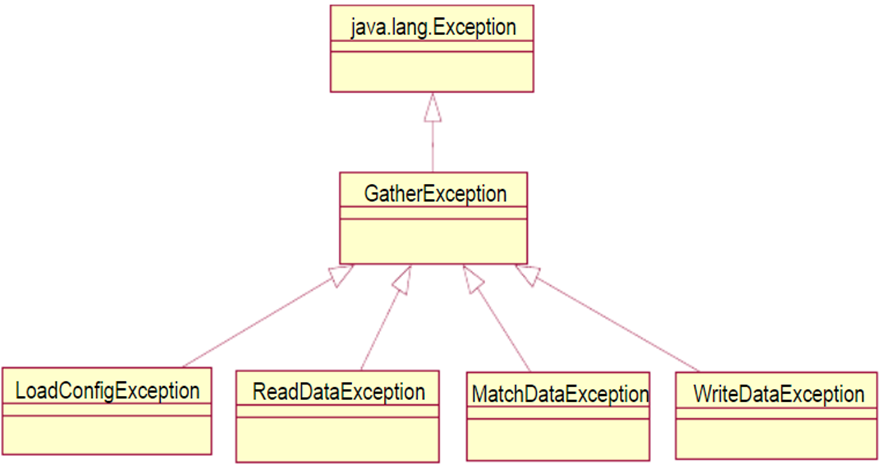
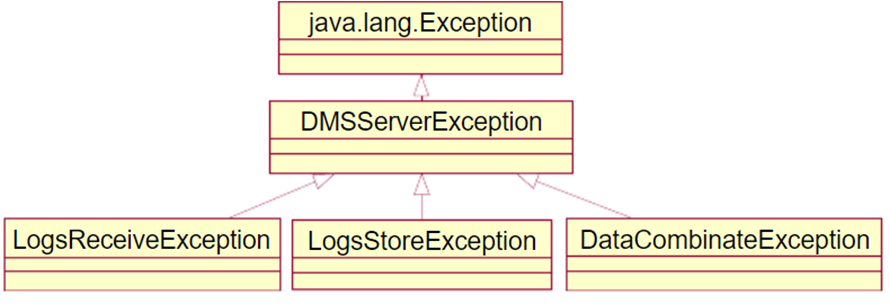
3.6异常处理 21
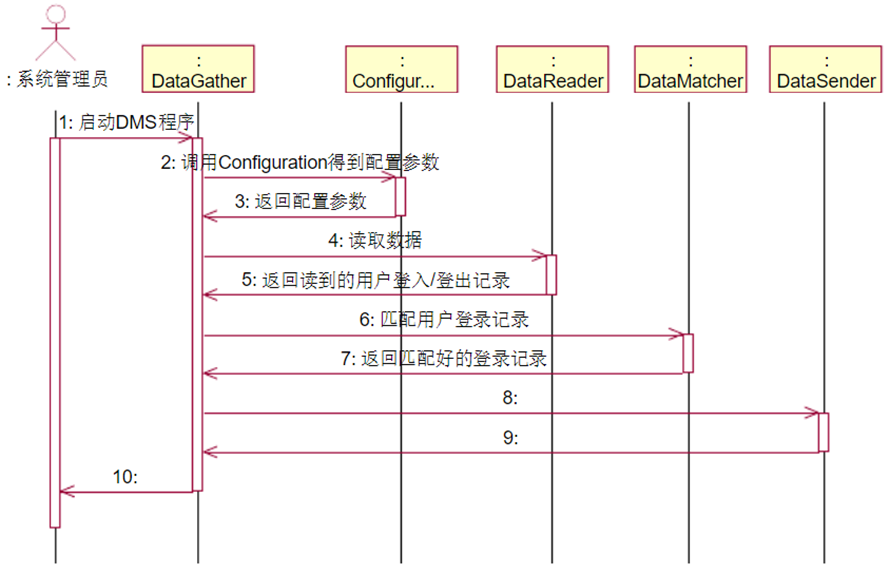
3.7用例实现 23
第4章 结论 25
4.1总结与展望 25
参考文献 1
致谢 2
绪论
1.1研究背景
二十世纪,数据库技术得到了重大突破并被广泛使用.大量信息在给人们带来方便的同时也带来了一大堆难题;第一是信息过于庞大,很难被消化;第二是信息真真假假辨识困难:第三是信息容易被泄露,其安全得不到保障;第四是信息形态不相同,不好统一处理。人们开始提出一个新的想法:“要学会舍弃信息”,并开始思考:“怎样才能不被信息掩埋,而是从中实时发掘有效信息、加深信息的利用程度?”如何从包含庞大信息的数据库中挖掘出内在的、有价值的信息来帮助做决定呢?为了适应时代要求和社会需要,知识发现和数据挖掘技术出现了,而且表现出了强盛的生命力。信息处理的更新更高的要求就是预测未来,数据库技术因为数据挖掘的出现进入了一个更高级的发展阶段。
数据挖掘技术(DataMining)【1】被誉为将来信息处理的尖端技术之一,数据库,人工智能、机器学习,统计学,知识工程、面向对象方法、信息检索、高性能计算以及数据可视化等多个学科和多个尖端科技都涉猎其中,这足可看出其研究范畴多么广阔,发展前景多么可观。所以数据挖掘技术从80年代末最先出现,短短二十多年它的发展就日新月异。
1.2国内外研究现状
自1989年第11届国际联合人工智能学术会议上初次定义KDD【2】这一概念以来,人们对数据挖掘的关注越来越多,并且在计算机这一块它成为了一个大热门,从发现方法到系统应用,它的探索重点也慢慢发生了转变,而且各种各样的发现策略和技术集成也迎来了一个春天——得到了更多的关注,还有各个学科之间也逐渐呈现一种水乳交融的状态。从总体上看,国外对数据挖掘研究更加深入,研究内容更加广泛,己经在挖掘知识的种类上获得了重大的突破。
1、关联规则的研究。这几年对关联规则的钻研内容颇多。当下,关联规则的挖掘已从单一概念层次关联规则的发现提升到多概念层次关联规则的发现,并且提高算法的效率和规模可收缩性成为了探究要点。目前,定量关联规则以及其他种类的关联规则的发现被深入的钻研,提出了关联规则的兴趣性的观点。与此同时,提高挖掘过程的效率方面也得到了重视,人们对此也做了不少探索。比较著名的算法有Apfiori,Charm,FP-Growth,MagnumOPUSS,GenMax。
2、数据分类技术探索。基于决策树的分类方法在大规模数据库条件下的应用研究;在较高的抽象层次分类中,M.Mehte.等人针对大型数据库提出了一种快速分类算法,称为QUEST中的超级学习算法,SLIQ:分类与回归的管状领域研究、最近邻分类方法的改进等等。
3、聚类规则【3】研究。最近几年,人们开始在大型数据库中研究聚类,R.Ng和1.Han基于随机搜索以及统计学中的两个聚类算法PAM和CLARA,研究出了一个适用于大型应用的聚类算法:CLARANS。M.Este等人针对CLARANS算法的不足之处,整理了改进方法。T.Zhang等人则提出了另一种聚类算法:BIRCH。
4、泛化、简约和特征提取研究。数据的表达和理解能力由于数据可视化的出现得到了巨大的提升,这是数据简约的一种非常重要的技术,它正受到广泛的关注。
与国外相比,国内对数据挖掘与知识发现(MDKD)的探索晚了一些,1993年国家自然科学基金初次帮助对该领域的研究项目。目前,对数据挖掘的基本理论及其应用研究广泛的在清华大学、中科院计算技术研究所、空军第三研究所、海军装备论证中心等开展。此中,北京系统工程研究所投入了较多物力人力去钻研模糊方法在知识发现中的运用,并取得了一些显著成果,而在数据立方体代数方面,北京大学也有一定的发言权;关联规则开采算法受到了华中理工大学、复旦大学、浙江大学、中国科技大学、中科院数学研究所、吉林大学等多个单位的重视,它们对其开展优化和革新方面的探究:南京大学、四川联合大学、山东师范大学、上海交通大学等单位也不甘寂寞,纷纷响应号召并加入了探讨的行列,非结构化数据的知识发现以及Web数据挖掘被它们选中拿来攻克。如今虽然国内探索与海外上的进展差距并不是很大,也有了比较多的研究成果比如:总参六十一所李德毅教授在云模型方面的研究、复旦大学的施伯乐教授在关系数据厍中知发现方面取得很大的突破,南京大学开发的KNIGHT系统等.但是在现实应用方面却几乎寥寥无几,成功的例子非常少见,没有形成一股可观的力量。总的说来.国内在数据挖掘方面的开发还停留在不太成熟的阶段,仅仅在实验,并不可以真正的投入到现实生产运用中去。
数据挖掘这种技术和其他技术一样也必须要花时间和精力来研究和开发,渐渐走向成熟阶段,最终被人们接受。现在许多通用的数据挖掘系统已经被开发出来,但是想要到达智能系统的期望还远远不够。在最近的数据挖掘钻研和开发中,研究人员也面临着五花八门的挑战,并考虑到了各种需求。即使有些问题比较难解决,但是这些问题将连续的激励着相关研究人员做进一步的钻研和改良。随着数据挖掘任务和方法的发展,我们坚信它必然能带给我们更多的好处,可以节省我们的时间和金钱,并促使我们发现新的知识,打开信息世界的大门。
1.3研究目的及意义
电信行业的竞争日益激烈,想要发展,那么对于客户的需求就要多加留意,那就需要多投入一些时间和精力在这个方面。通过客户的消费数据可以从中发掘出他们的消费特点和价值取向。电信运营商们对于分析历史数据这一块产生了浓厚的兴趣,想要从中发现对自己有利的信息。但是这些数据过于庞大,人工不可能完成。使用传统手段去处理,软硬件达不到标准,对系统资源占用太多。然而随着数据库和数据挖掘技术的出现,这些问题得到了解决。
数据挖掘不是一种简单的技术,要想学好,还必须学习数据库技术、统计学、计算机、模式识别等各种学科的基础知识,没有打牢固这些基础,学起来事倍功半。对数据进行抓取、变换、分析和建模,然后发掘出对于企业发展至关重要的数据,根据这些建立商业模型,以后要做什么决定都有了参考,这就是数据挖掘。尖端技术,名副其实。
将数据挖掘用到电信产业,电信业务就能得到质的飞跃。从海量数据中得到有效数据,根据业务需求建立分析模型,困扰电信运营商很久的难题就这样迎刃而解。不管面对多么复杂诡谲的局面,数据挖掘能够直击内在,帮助决策者快速而准确的做出决定。数据挖掘极大的提高了工作效率,对社会经济的发展做出了巨大贡献。
1.4论文组织结构
本文共4分为四章,各章内容如下:
- 介绍研究背景、国内外研究现状、研究内容。
- 论文的理论部分,介绍了数据挖掘的概念和特点,挖掘的过程,以及功能。
- 论文的设计部分,包括开发平台的介绍、系统的功能需求、系统用例、数据库表设计、总体类图、异常处理和用例实现。
- 总结论文工作所做的研究,分析得失,为下一阶段的工作打下基础。
第2章 理论部分
2.1数据挖掘基本知识
数据挖掘(DataMining,简称DM)【4】,通俗的说就是从五花八门的数据中发掘或整理出有效的信息,也就是知识,数据挖掘概念的定义描述版本还是比较多的,如下给出一个被广泛接受的定义描述:数据挖掘,又称为数据库中知识发现(KnowledgeDiscoveryfromDatabase,简称KDD),它是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程。
全部的知识发现(KDD)过程还是比较复杂的,它由几个部分组成,其中的一个重要的组成部分就是数据挖掘。整个知识挖掘的主要步骤有:
1.数据清洗(dataclearning),其作用就是消灭数据杂音和与显然偏离了挖掘主题的数据;
2.数据集成(dataintegration),其作用就是把来自四面八方的大量数据源中的相关信息凑在一起;
3.数据转换(datatransformation),其作用就是把数据的存储形式变换一下,怎样让数据挖掘展开工作更容易就怎么转变;
4.数据挖掘(datamining),其作用就是通过智能方法发掘出数据模式或规律知识,它是知识发现的一个重要步骤;
5.模式评估(patternevaluation)【5】,其作用就是按照一定评估尺度,有作用的模式知识就从挖掘成果中挑选出来了;
6.知识表示(knowledgepresentation),其作用就是把挖掘出来的知识清楚直观的呈现给用户,基本会用到可视化和知识表达技术。
2.2数据挖掘功能
在我们需要做决定时,可以通过数据挖掘技术发掘出各个方面的知识供我们参考。在大多数情况下,那些有意义的信息知识都隐藏在庞大的数据海洋中,用户并不能轻易找到。所以一个合格的数据挖掘系统,它应该可以同时搜寻和发现多层次多方面的知识,用来达成用户的期望和实际需求。另外数据挖掘系统还应能够挖掘出多种层次(抽象水平)的模式知识。数据挖掘系统还应容许用户指导挖掘搜索有价值的模式知识。下面将介绍数据挖掘功效以及所能够挖掘的知识类型。
2.2.1概念描述:定性与对比
通常情况下对一个含有海量数据的数据集合总体情况的总结就是一个概念。如想获取所售手机基本情况的一个整体概念就可以通过对一个公司所售手机基本情况的概述做一个总结。概念描述就是对含有大量数据的数据集合进行概述性的总结并获得简明、准确的描述。取得概念描述的方法主要有以下两种:
(1)通过更加广义的属性,概要的总结所要分析的数据;其中被剖析的数据就被叫做目标数据集;
(2)分析两类数据的特征并且进行对比,然后根据对比成果得出概要性分析;而其中两类被分析的数据集,它们分别被称为目标数据集和对比数据集。
数据概要总结就是利用数据描述属性中更广义的(属性)内容对其进行归纳描述。简单的数据库查找基本就可以获取到我们需要的数据,然后拿来分析。数据概要总结每每都用更广义的关系表或特征描述规则来进行输出展现。
2.2.2关联分析
在给定的数据集中存在一种出现频率很高的我们称之项集模式知识的东西,找出它的方法就是关联分析。在市场营销、事务分析等应用领域,关联分析被普遍使用。
2.2.3分类与预测
分类就是发掘出一组模型或者是函数【6】,使得它能够概括数据集合的典型特征,用来方便我们分析辨认出不明数据的归属或种类,就是把未知事物归类到它应该属于的类别中去。我们可以从一组类别归属已经知道的训练样本数据中,通过分类方法学习获得分类模型或者是函数。
可以采纳应用多种多样的方式描述输出通过分类挖掘所获取的分类模型。分类规则、决策树、数学公式和神经网络是主要的表示方法。其中的决策树是一个拥有层次布局的树状结构,转变为分类规则就异常的容易。
当我们预测不明数据信息具体例子的归属类别(有限离散值)时,经常会使用分类。但在某些情况下,我们需要预测的某数值属性的值,它是连续数值的,我们定义这样的分类叫做预测。虽然预测既包含连续数值的预测,又包含有限离散值的分类;但是约定俗成,我们还是使用预测来表示对连续数值的预测,而使用分类来表示对有限离散值的预测。
2.2.4聚类分析
区分聚类分析与分类预测【7】的一个关键的地方就是,第二种的模型中用来学习的数据是已经分好类别的,也就是我们通常所说的监督学习方法;而聚类分析呢?不管是在学习的时候还是在预测的时候,用来分析处理的数据都是没有标签的,也就是不确定它该归属到哪一类。因此聚类分析属于无监督学习方法。这就是它们最大的区别。
聚类分析中,有一个基本原则就是聚集起来的各个类别之间的区别越大越好,而各个类别里的各个对象则是越相似越好,还有专门的公式用来度量数据对象之间相似度,通过这些就可以将聚类分析中的数据对象划分为如果干组。因此同组对象相似度一定高于不同组。聚类分析所获得的每一个组都可以看作一个同类对象的集合。用这些集合再进行分类学习就可以得到分类预测模型。另外,一次又一次的对这些集合实行聚类分析操作,就可以获得一个有条理的结构模型。
2.2.5异类分析
一个数据库中通常会有一些稀奇古怪的不合群的数据,既不适合分类预测模型【8】,也不适合聚类分析模型。我们把这些与众不同的数据对象放在一起,统称为异类。大量数据挖掘方法会先排斥异己,把这些异类屏蔽,然后在进行数据挖掘和分析处理。但是这些异类也不是毫无用处,某些情况下有奇效,它们的作用可能会更大,比如各种贸易诈骗犯罪举动的主动测试。异类挖掘也就是对异类数据进行分析处理。
要找到数据中的异类,就要用到数理统计的方法了,就是通过拥有的数据搭建的概率统计分布模型,或者是通过相似度计算算出的相似数据对象分布,使异类数据无所遁形。从已知数据中或者是它们的期望值中发掘出那些显而易见的改变就被称为偏离测试。
2.2.6演化分析
随着时间的改变,数据对象也会发生改变,找到它们的变化规律和趋势并进行建模描述,这就是数据演化分析【9】。概念描述、对比概念描述、关联分析、分类分析、时间相关数据分析(这其中又包括:时序数据分析、序列或周期模式匹配,以及基于相似性的数据分析),这些都是常见的建模方法。
第3章 设计部分
3.1开发平台
J2EE开发平台【10】是一个企业级的开发平台,它的关键部分就是Enterprise JavaBeans API,它的应用程序的服务器终端有一个比较规范的组件模型。孤掌难鸣,单靠这技术本身它是运行不起来的,需要其他Java技术支撑才能搭建出来。传统开发平台有许多局限性,于是sun公司开发这个了这个平台去改良,这样电子商务就能得到更好的发展。相对传统平台,此平台表现良好,如稳定高效、安全、多用户、可移植、独立,企业Java开发工作更加方便快捷。
3.1.1 J2EE平台的主要技术
J2EE主要是由部分协议、应用程序接口、服务系统等部分组成,可以提供Web多层应用的开发技术,是开发工作中不可或缺的一项重要技术手段。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: