典型大数据应用JVM垃圾回收算法的评测毕业论文
2020-02-23 18:20:49
摘 要
Abstract V
第一章 绪论 1
第二章 Spark框架 3
2.1 Spark简介 3
2.2 Spark与Hadoop 3
2.3 MapReduce 4
2.4 Scala语言 5
2.5 HotSpot虚拟机 5
2.6 虚拟机运行时数据区域 6
2.6.1 程序计数器 6
2.6.2 Java虚拟机栈 7
2.6.3 本地方法栈 7
2.6.4 Java堆 8
2.6.5 方法区 8
2.6.6 运行时常量池 8
2.6.7 直接内存 9
第三章 垃圾收集器与内存分配策略 10
3.1 对象的存活 10
3.1.1 引用计数算法 10
3.1.2 可达性分析算法 10
3.1.3 引用的强度 11
3.2 垃圾收集算法 11
3.2.1 标记-清除算法 11
3.2.2 复制算法 12
3.2.3 标记-整理算法 12
3.2.4 分代收集算法 13
3.3 垃圾收集器 13
3.3.1 Parallel Scavenge收集器 13
第四章 大数据下JVM性能测试 14
4.1 PageRank算法 14
4.2 GC日志 15
4.3 VM参数与GC实例 15
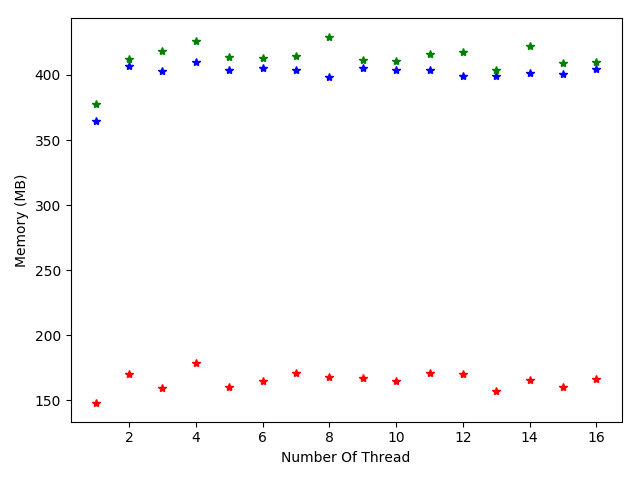
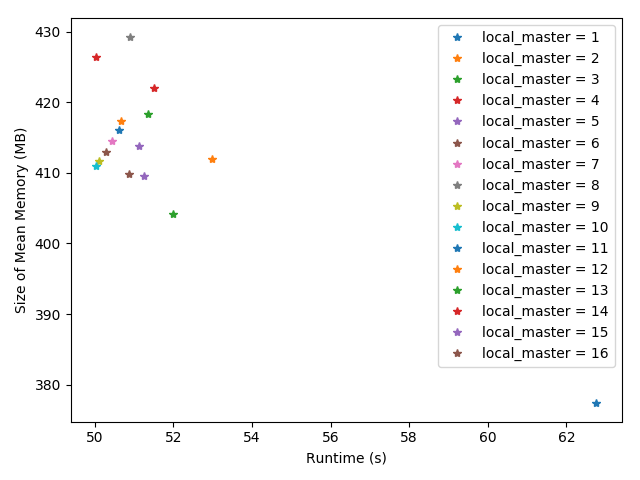
4.4 大数据情况下线程数对于Java虚拟机性能的影响 17
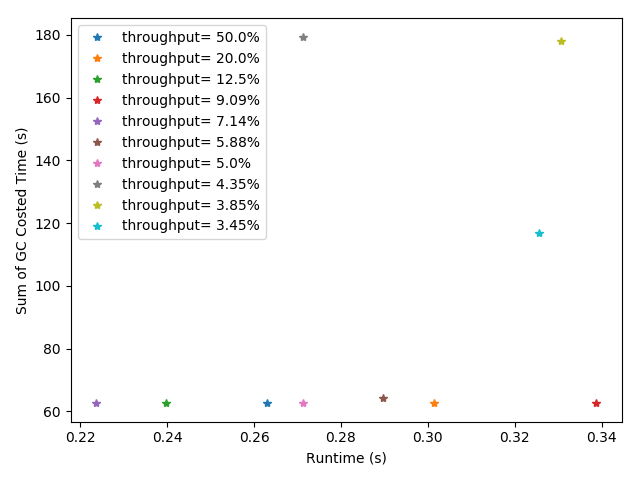
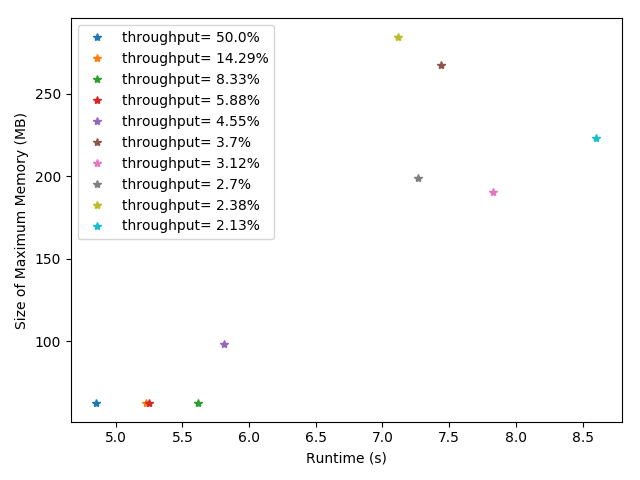
4.5 大数据情况下吞吐量对于Java虚拟机性能的影响 18
4.6 大数据情况下停顿时间对于Java虚拟机性能的影响 20
第五章 结论与展望 23
致 谢 24
摘 要
本文首先对于JVM及其垃圾回收算法和大数据环境进行了介绍与分析,说明在大数据条件下,针对海量对象和较高的计算需求,开发者需要对JVM进行专门地应对才能更好的提高JVM的性能。
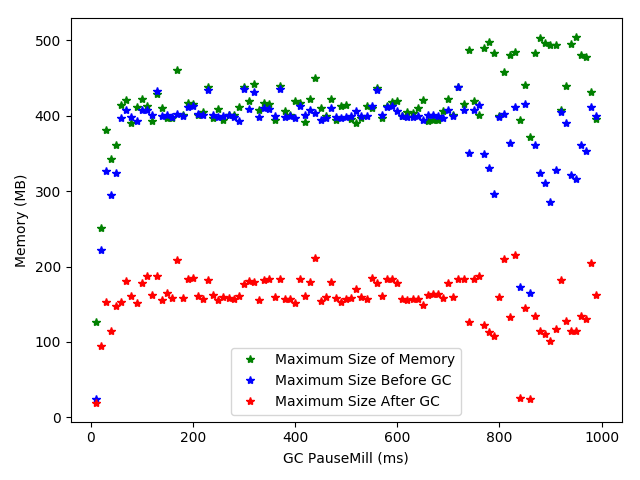
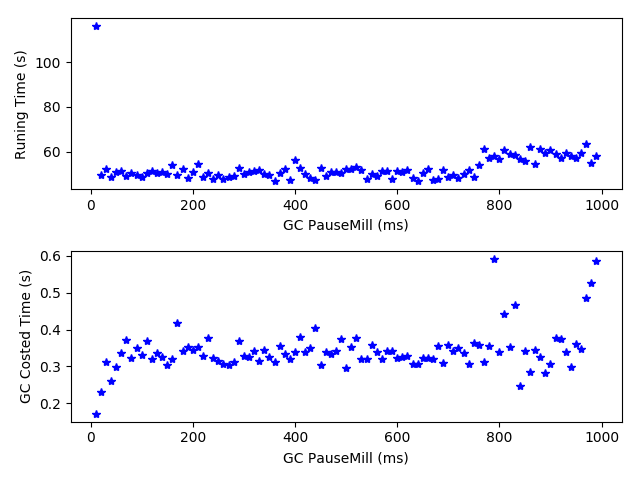
实验部分首先针对一个个案进行分析,通过实验分析验证了垃圾回收日志和JVM性能指标之间的对应关系。通过运行时间、GC消耗时间、GC前内存已使用容量、GC后该区域内存使用容量、该区域内存总量等指标衡量Java虚拟机性能,之后以PageRank算法为例,针对线程数、吞吐量、停顿时间等指标进行实验,分析性能指标与Java虚拟机参数之间的关系,并根据实验结果给出了合适的JVM参数。
关键词:JVM;垃圾回收算法;大数据应用
Abstract
This article first introduces and analyzes the JVM and its garbage collection algorithm and big data environment, and shows that under the conditions of big data, developers need to specifically respond to the JVM to better improve mass objects and higher computational requirements for improving JVM performance.
The experimental part first analyzes one case and verifies the correspondence between the garbage collection logs and the JVM performance indicators through experimental analysis. Measure the performance of the Java virtual machine by running time, GC consumption time, memory capacity before GC, memory usage in the area after GC, and total memory in the area. Take PageRank as an example for thread count, throughput, and Pause time and other indicators are tested to analyze the relationship between performance indicators and Java virtual machine parameters, and appropriate JVM parameters are given based on the experimental results.
Key Words:JVM;Garbage Collection;Big Data Application
绪论
Java自诞生以来就受到各方面的瞩目,在步入大数据时代以后,各种运行在JVM(Java Virtual Machine)上的大数据应用更是对于Java虚拟机的性能提出了极高的要求。许多大数据应用都采用高级程序设计语言进行设计,而这些高级程序设计语言往往都通过垃圾回收算法进行自动的内存管理。
现代计算已经进入了大数据时代。对于来自各行各业的科学家,网络上存在的大量数据能够让他们发现更多有趣的信息,而这些数据需要同样大型的数据系统进行处理。作为一个面向对象语言,Java经常被选择作为工具来实现大数据处理框架。在大数据条件下,许多云系统,类似Hadoop、Spark、Zookeeper等都用托管式语言编写。垃圾回收支撑着许多高级语言的优点,能够减少管理指针的工作,提升安全性并且避免内存泄漏。这些垃圾回收的特性提升了开发者和使用者的生产效率。
然而,但是,对于垃圾回收算法而言,快速且庞大的堆给垃圾回收添加了许多的限制,这些特性并非是免费的午餐。对于JVM,在数据处理过程中垃圾回收的时间可以占到三分之一的比重。一个1GB的数据输入可能会带来大小达12GB以上的堆。数据处理任务会给JVM带来大量的对象,导致长时间的垃圾回收暂停时间,使得虚拟机中堆的大小变得难以控制。一个高性能的垃圾回收(Garbage Collection)算法将会给给JVM带来极大的性能提升。
目前国内外对于垃圾回收算法的研究一直在进行。如Ionel Gog[1]等人对于批处理及并行处理情况下的JVM性能进行了研究,提出了Broom优化算法,Yingyi Bu[2]等人则对JVM中的Bloat现象进行了研究。Martin Maas[3]则分析了分布式系统中的垃圾回收算法。Khanh Nguyen[4]等人则提出了针对大数据应用的Yak优化算法。本文将通过实验对于在大数据环境不同种类应用下的垃圾回收算法性能进行研究,探索大数据环境下垃圾回收算法的性能特征。对于垃圾回收的具体过程进行分析。
我们最常用的评价垃圾回收器的性能指标有吞吐量与停顿时间等,对于停顿时间更短的程序,这样的程序适合需要与用户交互的程序,一个良好的响应速度对于用户的体验是十分重要的。对于一个有高吞吐量的程序,则可以以较的高效率地利用CPU时间,尽快完成程序的运算任务,这种程序主要适合在后台运算而不需要太多交互的任务;具体的指标包括吞吐量、垃圾回收器负载、停顿时间、垃圾回收频率、反应时间、堆分配等。
本研究首先将对垃圾回收算法的发展和种类进行调查研究,针对目前环境和Java的版本变化和不同的虚拟机,选取主要的垃圾回收算法作为对象进行研究。目前典型的垃圾回收算法包括标记-清除(Mark-Sweep)算法、复制算(Copying)法、标记-整理(Mark-Compact)算法、分代收集(Generational Collection)算法等,研究将根据应用广泛程度等指标进行选取研究。
Spark是一种基于内存计算的大数据分布式计算框架。Spark基于内存计算,提高了在大数据环境下,对于数据处理的实时性,并在同时保证了高容错性和高可伸缩性。Spark允许用户将Spark部署在大量廉价硬件之上,形成计算集群。本文结合Spark计算引擎,将研究应用在大数据环境下,针对大数据环境下虚拟机中垃圾回收算法的性能进行分析。设计实验,针对垃圾回收算法的各项指标进行评测,比较不同垃圾回收算法和不同数据输入条件下的实验结果,根据实验结果对于算法性能进行分析。
之后对于应用进行根据数据的处理细节进行分类,应用软件统计吞吐量,通过应用对于计算资源、存储资源的占用以及处理方式的不同分为不同类型,如计算密集型(CPU-bound)、I/O密集型((CPU-bound)),采取指标进行分析。
Spark框架
Spark简介
Apache Spark 是以用于大规模数据处理为目标而设计的快速通用的计算引擎,是一个用来实现快速而通用的集群计算的平台。
Spark[5]原本是2009 年作为UC Berkeley RAD lab所开源的类Hadoop MapReduce的通用并行框架。实验室中的研究人员曾经使用过Hapdoop MapReduce。他们发现MapReduce在迭代计算和交互计算任务上表现得效率低下,便开发了Spark。因此从一开始Spark就是为交互式查询和迭代算法设计的,同时还支持内存式存储和高效的容错机制[6]。
2009年,第一篇有关Spark的研究论文在学术会议上被发表,这一年,Spark项目正式诞生。2010年该项目通过BSD许可协议开源发布。2013年,Spark项目被捐赠给Apache软件基金会,同时切换许可协议至Apache2.0。2014年2月,Spark成为Apache的顶级项目。2014年11月,Databricks团队使用Spark 刷新数据排序世界记录。现在,Spark已经成为了流行的大数据处理系统之一。
用户可以使用Apache Spark提供的 Java,Scala,Python 和 R 等语言的高级 API其中还包括一组高级工具,这些功能丰富的工具含有适用于机器学习的 MLlib,适用于图计算的 GraphX,以及 Spark Streaming和使用 SQL 进行处理结构化数据处理的 Spark SQL,
Spark与Hadoop
Hadoop是根据谷歌发表的MapReduce和Google文件系统论文中的内容,自行实现而成。最早是由Ghemawat等人于2003年提出原型[7]。并于2006年推出Hadoop 0.1.0版本。而这个项目也催生出MapReduce[8]。
Apache Hadoop作为一款支持数据密集型分布式应用程序,这个应用以Apache 2.0许可协议发布的开源软件框架。
Hadoop框架能够透明地为应用提供可靠性、数据移动等功能。它实现了MapReduce编程范式,即应用程序被分区成许多小部分,对于每个部分都能在集群中的任意的节点上运行或者重新运行。Hadoop除此之外还提供了分布式文件系统,通过分布式文件系统可以存储所有计算节点的数据,这种系统能够提供非常高的带宽。MapReduce编程范式和分布式文件系统使得整个框架能够自动处理节点故障。应用程序与成千上万的独立计算的电脑和PB级的数据通过这些连接起来。
现在普遍认为整个Apache Hadoop“平台”包括的部分有Hadoop内核、MapReduce、Hadoop分布式文件系统(HDFS)以及一些相关项目,例如有Apache Hive和Apache HBase等等。
Spark继承了Hadoop MapReduce的优点,也有着很多的不同。MapReduce任务的中间输出结果在Spark中能够保存在内存,不再需要读写HDFS,这样的话数据挖掘与机器学习等需要迭代的MapReduce的算法就能够通过Spark获得性能的提升。同时,Spark可以将任何HDFS (Hadoop Distributed File System, Hadoop分布式文件系统)上的文件读取为分布式数据集,也可以支持其他支持Hadoop接口的系统,通用性良好。
Spark 作为一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面能够表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了可以提供交互式查以外,它对于迭代工作负载还能进行优化。
Spark 是通过 Scala 语言,它将 Scala 用作其应用程序框架。Spark与 Hadoop 不同的是,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。
MapReduce
MapReduc是一个用于大规模数据集的并行运算的软件架构。一个MapReduce程序由Map(映射)和Reduce(归纳)两个过程组成。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的,虽然他们和原来的意思并非一样。
映射函数就是对独立元素组成的概念上的列表中每一个元素进行指定的操作。事实上,列表中的每个元素都是被被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这种设置使得Map操作是可以高度并行的,这对于高性能计算和并行计算领域是非常有用的。
而归纳操作指的是对一个列表的元素进行适当的合并。虽然这个过程不如映射函数那么并行,但是因为归纳总是有一个简单的答案,大规模的运算相对独立,所以归纳函数在高度并行环境下也很有用。
最后MapReduce过程通过Shuffle(洗牌操作)对数据惊喜重新分配,使在MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。
当前的软件实现是指定一个Map函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Scala语言
Scala是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性,Spark就是由Scala编写的。洛桑联邦理工学院的Martin Odersky于2001年基于Funnel的工作开始设计Scala,Funnel是把函数式编程思想和佩特里网相结合的一种编程语言。Java平台的Scala于2003年底/2004年初发布。.NET平台的Scala发布于2004年6月。该语言第二个版本,v2.0,发布于2006年3月[9]。
因为Scala运行于Java平台。所以JVM(Java Virtual Machine,Java虚拟机)的性能对于Spark程序的运行来说至关重要。
HotSpot虚拟机
从1996年初Sun公司发布的JDK1.0中所包含的Sun Classic VM到今天,大量的虚拟机层出不穷。目前SunJDK和OpenJDK默认的虚拟机是HotSpot虚拟机。HotSpot虚拟机最初是由一家名为“Longview Technology”的小公司设计,Sun公司意识到了这款虚拟机在JIT编程神有着许多的优秀理念,并且实际效果也非常出众,所以在1997年收购了“Longview Technology”公司,从而获得了HotSpot虚拟机。最终HotSpot虚拟机在JDK1.2中被加入JDK。
HotSpot虚拟机的优势在于热点代码探测能力。热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知JIT编译器以方法为单位进行编译。如果一个方法被频繁调用,或方法中有效循环次数很多,将会触发标准编译和OSR(栈上替换)编译动作。通过编译器与解释器恰当地协同工作,可以再最优化的程序响应时间与最佳执行性能中去的平衡,而且无需等待本地代码输出才能执行程序,即时编译的时间压力也相对减小,这样有助于引入更多的代码有绘画技术,输出质量更高的本地代码[10]。
虚拟机运行时数据区域
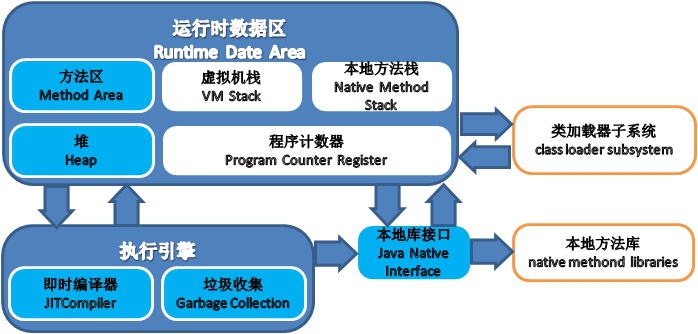 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,已经创建和销毁时间,有的区域随着虚拟机进程的启动而创建,有些区域则依赖用户线程的启动和结束而创建和销毁。
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,已经创建和销毁时间,有的区域随着虚拟机进程的启动而创建,有些区域则依赖用户线程的启动和结束而创建和销毁。
图2.1 Java虚拟机结构
程序计数器
程序计数器(Program Counter Register)是一块比较小的内存空间,他的功能可以看做是当前线程执行字节码的行号指示器。在虚拟机的概念模型之中,字节码解释器工作的时候就是通过改变计数器的值来选取下一条执行的字节码指令,程序执行过程中的分支、循环、跳转、异常处理、线程恢复等基础功能是依靠这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换,并分配处理器执行时间的方式来实现。对于任意时刻,一个处理器只会执行一条线程中的指令。因此,每个线程东欧需要一个独立的程序计数器来保证在进程切换的时候才能恢复到正确的执行位置。每条线程之间的计数器互相之间不会影响,数值也独立储存。这一块内存区域被称为“线程私有”。
如果线程正在执行一个Java方法,那么程序计数器记录的是正在执行的虚拟机字节码指令的地址;如果线程正在执行Native方法,那么这个计数器的值就会为空。这个内存区域是唯一一个在Java虚拟机规范中没有规定OutOfMemoryError情况的区域。
Java虚拟机栈
Java虚拟机栈作为同样的线程私有区域,描述的是Java方法执行的内存模型。每个方法在执行的时候会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口灯不同的信息。每个方法从被掉用到执行完成的过程都对应着一个栈帧在虚拟机中进栈到出栈的过程。
在栈帧中存储着编译期可知的各种基本数据类型和对象引用,而具体存储他们的地方就是局部变量表,当进入一个方法的时候,这个方法在帧中需要的大小是已经通过编译完全确定的,局部变量表的大小在方法运行期间不会改变。
在Java虚拟机规范中,这个区域规定了两者异常,如果线程请求的栈深度大于虚拟机所允许的深度,将会抛出StackOverflowError异常;如果虚拟机可以动态扩展内存时无法请求到足够大的内存的时候,则会抛出OutOfMemoryError异常。
本地方法栈
本地方法栈与虚拟机栈发挥着类似的作用,他们的区别只是Java虚拟机栈为虚拟机执行Java方法进行服务,而本地方法栈则是使用Native方法。同样,本地方法栈也会抛出StackOverFlowError和OutOfMemoryError异常。
Java堆
对于大部分应用,Java堆是Java虚拟机所管理的内存中最大的一块。在Java虚拟机启动时创建,并且是线程共享的一个区域。Java堆唯一的目的就是存放对象方法,几乎所有的对象实例都是Java堆中分配内存的,虽然随着JIT编译器的发展和逃逸分析技术的逐渐成熟,所有对象都在堆上变得不那么绝对了。
Java堆是垃圾收集器管理的主要区域,从内存回收角度来看,现在收集器基本都采用分代收集算法,所以Java堆中国还可以细分为:新生代和老年代。从内存分配的角度来看,线程共享的Java堆中可能划分出多个线程私有的分配缓冲区。无论如何划分,每个区域都是用来存放对象实例,更为细致的划分只是为了更快地,更好地去回收内存和分配内存。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: