基于视频的3D车辆检测及追踪方法研究毕业论文
2021-12-02 13:08:27
论文总字数:23857字
摘 要
本文在已有的开源单目视频流3D车辆检测及跟踪框架基础之上,分析了其模型设计上的不足与对应的改进方法,并在其启发下设计了新的3D信息估计模型,替换了最初设计中结构较为简单的3D信息估计卷积子网络模型。为研究3D信息估计子网络的结构对3D车辆追踪流程的整体影响,本文共设计了两种不同的3D信息估计子网络,其一为加深原子网络部分分支的加深模型,其二为在加深模型中引入额外的3D信息偏移量分支,优化3D信息估计结果的偏移量模型。实验结果显示,相比于本文自行训练的初始模型,本文中设计的两种模型使3D车辆追踪系统在MOT多目标跟踪量化评价指标上几乎全面上升;与计算资源占优的开源系统相比,本文的优化模型虽然在多目标跟踪准确度(MOTA)等三个指标上有所下降,但是在多目标跟踪精度(MOTP)等五个指标上均有明显提升。此外基于加深模型的偏移量模型在没有任何指标下降的条件下,成功地额外提升了MOTP指标。可视化视频结果中,在目标较为稀疏的场景内,本文模型的车辆追踪边界框更加稳定。上述研究结果表明,本文设计的两种优化模型均能提升3D车辆追踪流程的整体效果,且偏移量分支模型能额外提升改进效果。
关键词:单目视频流;3D车辆跟踪;模型优化Abstract
This paper first analyzes some deficiencies of an open source 3D vehicle detection and tracking framework and corresponding optimization solutions, then inspired by the framework, this paper has designed new 3D estimation models and replace the convolution sub-network model in the original system which is simple in structure. To study the overall influence of the 3D estimation model to the entire 3D vehicle tracking pipeline, this paper has designed two different 3D estimation model, the first one is the deep model which deepens some branches of the network, the second one is the offset branch model which adds additional branches to the deep model to refine 3D results. The experiment result shows that compared to the original model this paper trained, these two models this paper designed has almost all-roundly improved the performance of the entire system on the MOT benchmark; even when compared to the open source framework that benefits from greater computing resources, models of this paper still improve five indexes in the benchmark including MOTP, although three indexes in the benchmark including MOTA has deteriorated. In addition, the offset branch model successfully further improves MOTP without influencing other indexes. In the visualization video, results that come from systems which use models of this paper are more stable in scenarios with sparse targets. The above research has shown that two models this paper designed can improve the overall performance of the 3D vehicle tracking pipeline, and offset branch model can further improve it in extra.
Key Words:monocular video stream;3D vehicle tracking;model optimization
目 录
摘要 I
Abstract II
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状分析 2
1.2.1 单目2D目标检测 2
1.2.2 单目深度估计 2
1.2.3 单目3D车辆跟踪 3
1.2.4车辆跟踪数据集 5
1.3 研究内容及章节安排 5
1.3.1 研究内容与技术路线 5
1.3.2 章节安排 7
第2章 系统分析与模型评估 8
2.1 系统分析 8
2.2 模型评估 8
2.2.1 模型训练与成果比较 9
2.2.2 模型结果分析 10
2.3 本章小结 11
第3章 单目3D信息估计模型优化 12
3.1 模型优化方案研究 12
3.1.1 模型结构分析 12
3.1.2 优化方案设计 13
3.2 优化模型评估与结果分析 15
3.2.1 优化模型训练 15
3.2.2 优化模型评估 16
3.2.3 模型优化结果分析 18
3.3 本章小结 19
第4章 总结与展望 20
4.1 总结 20
4.2 展望 20
参考文献 22
致谢 24
第1章 绪论
1.1 研究背景及意义
基于视频的车辆目标检测及追踪是对车辆进行行为分析的重要环节,在智慧交通,无人驾驶等场景中有重要应用价值。但是,现实交通场景是三维的,视频中的图像只是现实三维世界在二维上的投影,这个过程势必伴随着大量信息丢失。这也给基于视频的车辆检测及追踪任务带来一些问题,例如车辆遮挡难检测、车辆空间信息丢失等,这极大的影响了后续智慧交通应用的实现。
近年由于基于卷积神经网络的深度学习方法在机器视觉上的进展,高精度的2D车辆目标的检测和跟踪成为可能。然而,2D检测和跟踪方法只能得到目标在图像平面上的属性,如目标在图像上的尺寸、坐标位置等,缺少了在三维世界中的真实信息,包括三维尺寸、方向、真实位置等。而在智慧交通应用中,为了进行目标的位姿估计、速度估计、运动规划等活动,这些信息是必要的。
人类具备从车载视频中感知其他车辆三维空间的能力,例如不仅可以发现具有遮挡的车辆,而且能够推理出车辆之间的相对位置及道路空间上的分布。在3D车辆跟踪领域,为了从车载视频中获取必要的三维数据,许多方法使用多目镜头,结合光学、几何学知识来获得车辆目标的完整三维信息;部分方法辅助使用车载激光雷达(LiDAR),这类方法在LiDAR的帮助下能获得物体表面的点云数据,因此车辆目标表面上的部分点的距离直接可得,大幅降低了3D车辆检测和跟踪的难度。然而,由于单目镜头相对于多目镜头与LiDAR更加廉价,而且如一般的车载行车记录仪与监控摄像头的数据都可以直接应用在该类方法中,因此单目的视频流数据最为丰富,且许多日常应用场景都采用单目视频。
综上所述,在研究基于视频的3D车辆检测与跟踪方法时,如何使用最广泛的单目镜头视频,获取、估计可靠的目标车辆的3D信息,有重大的研究价值。而在获取目标车辆的3D信息后,应用就能使用3D边界框标记目标车辆并预测车辆运动,以完成目标车辆的跟踪。因此,如何让机器能够像人类那样从车载视频等单目视频中学习到车辆的先验3D信息,从而用3D边界框准确地标记出检测到的车辆,并且在较长的视频序列中对车辆目标进行跟踪对于智慧交通领域的三维场景理解具有重要意义。
1.2 国内外研究现状分析
1.2.1 单目2D目标检测
近年由于基于卷积神经网络的深度学习方法在机械视觉上的进展,精确、高效的目标检测成为可能。主流方法主要分为两种:一步检测与两步检测。两部检测的代表为以滑动窗口与区域候选为主要思想的R-CNN系列模型。在2015年,Shaoqing Ren、Kaiming He以及Girshick等人提出了著名的Faster R-CNN算法[10],通过在特征图上生成大小不同的锚点选取最合适的目标检测提案。Faster R-CNN是第一个真正意义上的端到端的深度学习检测算法,也是第一个准实时的深度学习目标检测算法,由于其高效、精确以及端到端的模型特点,它现在仍在许多最先进的模型中被作为2D物体检测的子网络。
不同于“区域提案”的思路,一步检测是基于回归的目标检测方法。2015 年,华盛顿大学的 Joseph Redmon等人提出的 YOLO 算法[11]。它的核心思想就是采用整张图作为网络的输入,直接在输出层回归边界框的位置及其所属的类别。之后YOLO也仍在不断被使用与改进,2018年YOLOv3[23]的发布又大幅提升了该系列的检测精度与计算速度。

图1.1 2D目标检测效果图
1.2.2 单目深度估计
由于从2D图像中缺少3D空间信息,为更好完成3D车辆跟踪任务,网络常常需要更多的空间信息,深度是3D车辆跟踪任务中最常用的额外信息,许多工作通过估计的深度来完成3D跟踪任务。除部分3D车辆跟踪任务在模型中自行回归预测深度外,也有许多最新的工作着重于从单目图像中生成深度图。FastDepth[12]通过类似于全卷积的网路,将不同分辨率的卷积特征在上采样时进行融合,完成了一个简单但有效的深度估计网络。2017年,Tinghui Zhou等人[13]基于SFM(Structure From Motion)的思想,从视频流中重建3D信息。2019年,Godard等人[14]又对基于SFM的深度估计方法提出了多项改进,使得SFM深度估计工作获得了显著的进步。

图1.2 单目深度图估计效果图
1.2.3 单目3D车辆跟踪
(1) 基于回归的3D信息估计方法
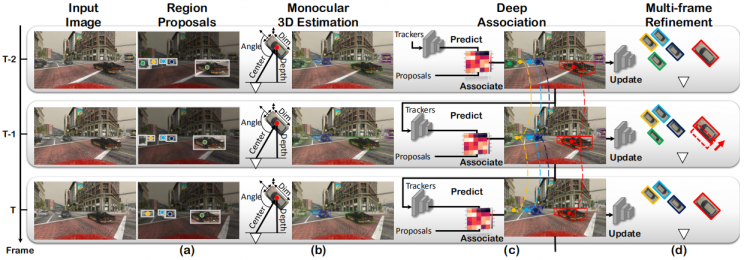
3D跟踪任务的目标,就是生成目标对应的3D边界框以确定其位姿信息。早期部分工作中,3D车辆跟踪的模型与2D检测类似,同样使用类似2D车辆跟踪中的网络架构,基于回归的思想复原所有所需的三维信息。2017年的Mousavian等人的方法[15]使用多个全连接子网络对2D检测得出的ROI卷积得到的特征图进行车辆尺寸、方向进行回归。而最新的部分方法,仍使用这种思路,通过网络回归来获取所有3D参数。Simonelli等人[3]通过获取不同分辨率的特征向量,再用这些向量结合全连接层回归所有的3D参数。而MonoGRNet[2]通过复杂的网络结合浅层和深层特征向量,先回归车辆中心点深度,再直接回归物体定位和与3D边界框的8个顶点完成3D检测工作。Ren等人的方法[9]使用子网络网络获取深度图像,再结合2D检测结果ROI回归物体在三维世界中的尺寸、方向与其中心相对2D检测结果中心的差距,再利用上述数据将原来的2D检测结果提升至3D跟踪结果。Hu等人的模型(以下称JointMono3D)[1]延续了Mousavian等人的方法[15],优化了2d检测部分[18]和提取ROI特征的卷积层[17],并各用包含3层3*3的卷积层的卷积子网络回归物体尺寸、方向、中心及中心点的深度,最后使用LSTM估计车辆运动,生成运动预测并以此提高之后帧的3D跟踪效果,其具体流程见图1.3。此外,在今年入选CVPR2020会议的论文中,Mingyu Ding等人[24]设计了复杂的过滤器生成网络,结合深度图像动态地调节卷积层过滤器属性与特征图的像素感受野,并将特征图进行融合,以此使用深度图指导网络对特征图进行卷积并回归所有3D信息参数。
请支付后下载全文,论文总字数:23857字
相关图片展示: