基于裁判文书的案件罪名预测方法研究毕业论文
2020-02-19 18:14:43
摘 要
得益于人工智能相关理论技术的发展,“X AI”的概念席卷了各行各业,并对传统领域的改革发展造成了深刻影响,法律人工智能就是其中一个新兴的交叉领域。在传统法律服务行业由于人力短缺、工作内容繁杂等原因难以满足日益增长的法律需求的背景下,法律人工智能因其低成本、高效率的优势成为了一种理想的解决方案,具备良好的研究价值和广泛的应用前景,其中一个重要的研究分支就是对案件罪名进行预测。然而现实场景中的案件数据,由于罪行性质和量刑考量的差异,存在着明显的样本类别不均衡问题,给准确预测罪名和识别稀少的罪名标签带来了难度。
针对以上的问题,本文基于裁判文书对案件罪名预测方法进行研究,从数据层的预处理上对原始数据进行增强来减轻数据的不均衡程度。采用了在数据空间中用同义词替换的数据增强方法,具体实现和整合了使用同义词词典、训练本地词向量和引入预训练词向量进行少数类样本过采样的算法,并与特征空间中具有代表性的数据增强算法——SMOTE算法进行对比。
在分类模型方面,本文分别使用FastText模型和SVM模型对增强后的数据集进行验证,在增强算法运行时间、分类器得分、模型训练时间和预测时间三个方面,对比分析了各数据增强方式与两种分类模型的结合算法对罪名预测的提升效果。实验结果表明,本文采用的基于本地训练词向量进行同义替换的数据增强算法,结合FastText模型进行罪名预测时,在运行效率和分类效果上取得了最佳的综合表现。
关键词:案件罪名预测;数据增强;SMOTE;FastText;SVM
Abstract
Thanks to the development of artificial intelligence-related theory and technology, the concept of “X AI” has swept across all walks of life and has had a profound impact on the reform and development of traditional fields. Legal artificial intelligence is one of the emerging cross-cutting areas. In the context of the traditional legal service industry, which is difficult to meet the growing legal demands due to shortage of manpower and complicated work content, legal artificial intelligence has become an ideal solution due to its low cost and high efficiency. It is worth studying and has a broad future of application. One of the important research branches is to predict the accusation of the case. However, the case data in the real-world scenario, due to the nature of the crime and the difference in sentencing considerations, there exists an obvious problem of data imbalance in the labels of data, which makes it difficult to accurately predict the accusations and identify those rare labels.
In view of the above problems, we study the accusation prediction method based on the judgment documents, and augments the original dataset in the preprocessing stage of the data layer to reduce the data imbalance level. A data augmentation method based on synonym substitution in data space is adopted in this paper. The algorithm of using the synonym dictionary, training local word vector and introducing pre-trained word vector to perform over-sampling of minority samples is implemented and integrated. The data augmentation algorithm SMOTE is selected for comparison.
In terms of classification model, we utilize FastText model and SVM model to verify the augmented dataset respectively. The data augmentation methods are compared and analyzed in the aspects of data augmentation algorithm’s running time, score achieved by the classifier, training time and prediction time of the model, to find out how much improvement is made by these methods. The experimental results show that the synonymous substitution algorithm based on local-trained word vector for data augmentation, combined with FastText model, has achieved the best overall performance in terms of operational efficiency and classification effect.
Key Words: accusation predictions; data augmentation; SMOTE; FastText; SVM
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 选题背景与研究意义 1
1.2 国内外研究现状 2
1.3 研究目标和研究内容 2
1.4 论文结构安排 3
第2章 裁判文书数据集介绍及预处理 4
2.1 数据集介绍 4
2.2 数据预处理 5
2.2.1 数据清洗 5
2.2.2 中文文本分词及去停用词 6
2.2.3 数据分析 6
2.3 实验评价指标 7
2.4 本章小结 9
第3章 不均衡数据的增强方法研究 10
3.1数据不均衡问题的介绍 10
3.2数据空间中的数据增强方法 10
3.2.1基于同义词典的数据替换 11
3.2.2基于词向量相似度的数据替换 12
3.3特征空间中的数据增强方法 15
3.3.1文本的向量化表示 15
3.3.2 SMOTE算法 16
3.4 增强后数据集统计分析 16
3.5本章小结 18
第4章 基于裁判文书的罪名预测实验对比分析 19
4.1 中文文本分类的基本过程 19
4.2实验模型介绍 20
4.2.1 SVM模型 20
4.4.2 FastText模型 21
4.3 实验过程与分类结果分析 22
4.3.1实验环境 22
4.3.2实验方案 22
4.3.3实验结果分析 22
4.4本章小结 25
第5章 总结与展望 26
5.1 工作总结 26
5.2 未来工作展望 26
参考文献 28
致 谢 30
第1章 绪论
1.1 选题背景与研究意义
随着大数据挖掘与分析、自然语言处理、机器学习等领域基本理论和技术的发展,人工智能学科越来越多地与其他传统行业的融合,并由此孕育出了一大批的新型交叉学科,其中法律人工智能领域在近年来获得了极高的关注,展现出了十分大的研究和发展潜力。上海交通大学的孔祥俊认为法律裁判是一个大前提为法律、小前提为案件事实的演绎推理模式[1],这表明了法律是一个规范的判断过程,其认知结构符合人工智能的逻辑,因而法律与人工智能的结合具有与生俱来的优势。
根据国家统计局2017年发布的统计数据显示,我国目前律师工作人员数量约为35万人,平均每万人拥有律师数量约为2.52人,该指标与发达国家相比仍有较大差距。例如,美国每万人拥有律师数量约为43人,英国每万人拥有律师数量约为15.4人。这一指标从一定程度上反映了当下我国法律行业面临的困境,即法律服务机构难以满足国民群体产生的庞大法务需求。另一方面,法律服务领域也存在着卷宗数量多、法律条文庞杂等难题,传统的人工服务方式效率较低。因此,法律人工智能不仅能够解决该领域人才短缺的问题,还能将相关从业人员从冗杂的重复劳动中解放出来,提高工作效率。
案件罪名预测作为法律人工智能中的一个重要研究分支,在司法领域的应用越来越广泛。学者曹建峰指出,案件预测的价值主要在两个方面:从个体角度上看,可以帮助当事人拟定理想的诉讼方案,节约诉讼成本;从司法角度上看,可以推动法律服务走向自动化、民主化和商品化,促使人人都能以较低成本便捷地获取法律服务,减少法律资源不对称的影响。同时还能协助法官进行“同案同判”,提高法官和律师的办事规范化程度,实现更广泛的司法正义[2]。
2013年7月1日,中国最高人民法院开通上线了中国裁判文书网,旨在向社会各界公开全部符合条件的生效裁判文书。截至2019年5月17日,中国裁判文书网上收录的裁判文书已超过6800万篇,访问总量超过250亿次。这一举措不仅有效促进了我国司法公开的进程,还为法律人工智能的发展提供了海量宝贵的真实案件数据。
本文将着眼于司法裁判中的案件罪名预测方法研究,利用真实的裁判文书数据训练机器,使其能够对案件被告可能涉及的罪名做出预测,为法官、律师和当事人提供高效的参考途径。
1.2 国内外研究现状
国外的相关研究起步较早,1987年在美国波士顿举办的首届国际人工智能与法律会议(ICAIL)及在随后的1991年成立的国际人工智能与法律协会(IAAIL),对这一新兴领域的未来发展提供了具有前瞻性的指导。Schild[3]通过与基于规则的专家知识系统方法进行对比分析,论证了基于案例的咨询系统是一个更好的途径,并据此实现了原型系统。该系统可根据用户输入的系统预定义问题的相关答案,利用决策树算法来找到历史上的相似案件并作出预测;随着近年来深度学习和自然语言处理相关技术的发展,更多的学者将案件司法裁判预测视为一个文本分类任务,如Şulea[4]等人基于法国最高法院的案件裁判样本,使用其中的事实描述和裁决刑期对案件的裁判结果进行预测,在由多个SVM分类器整合而成的系统上取得了十分好的实验结果;Aletras[5]等人使用欧洲人权法庭公开的案件训练算法模型进行二分类,对实验结果的分析表明案件中对于事实的正式描述是最重要的预测因素。这一结论符合现实主义法学的观点,即司法裁判结果受到案件事实描述的影响最为显著。
国内的学者夏明[6]在刑事案件文本上进行研究,设计了以朴素贝叶斯算法为第一级、关键词共现知识为第二级的二级分类器进行案件分类,并提出了一种规则与字典相结合的方法来提取案件特征,再通过特征密度聚类实现了对串案与并案的挖掘分析;罗炳锋[7]等人认为针对案件罪名预测来说,事实描述不是唯一的依据,需要结合法条信息进行预测,他们在提取了法条特征后使用attention机制,提升了预测的效果;程春惠[8]等人关注到了犯罪文本分类中的类别不均衡问题,首先在预处理阶段对文本中的无关词汇进行了词性过滤,然后在改进的多变量贝努利模型上开展案件的文本分类实验,实验结果在准确率上得到了提高。
1.3 研究目标和研究内容
本文以法律人工智能为研究背景,基于真实的裁判文书数据,对案件罪名作出预测。从本质上来说,这是一个多分类的文本分类任务,旨在通过对裁判文书中的事实描述部分内容进行自然语言处理,随后将其和已标记的罪名标签一同输入文本分类器进行有监督学习,构建案件罪名预测模型。
本文研究的难点在于,在现实情况中由于罪行性质和量刑考量的差异,涉及不同罪名的裁判文书数据存在重度的数据不均衡问题。以刑事案件为例,截至2019年5月17日,中国裁判文书网上共公开了约599万份刑事案件的裁判文书,按照二级案由进行分类统计可知,侵犯财产相关的裁判文书超过193万份,约占32.2%;而危害国家安全相关的裁判文书为160份,仅占约0.003%。因此,数据不均衡问题是制约案件罪名预测的重要原因,本文将从数据不均衡的解决方法上入手,探讨和研究不同的数据增强方式对案件罪名预测结果的影响。最后通过实验对比分析,各方法得到的增强数据集的分类效果,结合两种不同的分类模型FastText和SVM来为将来的罪名预测相关研究提供参考。
具体而言,本文主要研究内容如下:
(1)使用不同的过采样方法对少类样本进行扩增。针对裁判文书数据类别不均衡的特性,本文尝试多种过采样方法,分别从数据层面和向量层面对原始数据集中的少类样本进行扩充。在数据空间中,我们基于同义词替换的思路对少类样本进行同义替换,生成新样本。其中同义词词典的构造手段有三种,分别是引入第三方整理的同义词典、使用本地训练的词向量以及使用第三方预训练的中文同义词工具包Synonyms;在向量空间中,我们使用SMOTE方法生成新的少类样本。
(2)使用数据增强前后的各个数据集分别训练多个文本分类器,对比分析它们对分类效果的影响。在本文中,我们选择FastText和SVM两种模型来分别训练分类器,以探究针对案件罪名预测任务的特点而言最合适的实现方式。
1.4 论文结构安排
本文共分为五章,每一章的主要内容如下:
第一章:绪论。本章主要介绍了本文的选题背景和研究意义,说明了法律人工智能发展的优势并介绍了案件罪名预测的国内外研究。同时阐释了基于事实描述进行案件罪名预测的可行性,对研究难点进行了剖析,确定了本文的研究目标和研究内容。
第二章:裁判文书数据集介绍及预处理。本章首先对实验用到的裁判文书数据集的数据特点进行了详细介绍,并进行了必要的数据预处理工作,完成了实验所需数据集的制备,然后我们制定了实验结果的评价指标,为后续实验做好了准备。
第三章:不均衡数据的增强方法研究。本章主要介绍了数据挖掘和文本分类任务中的数据不均衡问题,并从数据空间和向量空间两个角度实现了多种数据增强方法。
第四章:基于裁判文书的案件罪名预测实验对比分析。在本章中,我们主要使用上一章实验所得的各数据集分别使用FastText和SVM进行分类模型的训练,然后在测试集上进行分类效果的测试,并对测试结果进行对比和分析。
第五章:总结与展望。本章对全文的研究内容进行了概括,总结了各个不均衡数据的增强方法以及FastText和SVM两种分类模型在案件罪名预测任务上的表现,并分析了不同方法之间各自的优势与不足;随后我们对未来的研究工作进行了展望。
第2章 裁判文书数据集介绍及预处理
本文中实验所用的数据均采集自中国裁判文书网上公开的真实裁判文书,本章将对数据集中的数据特点进行详细介绍,并针对本文实验对该原始数据集进行必要的数据预处理和分析,为后续实验做好数据准备工作。
2.1 数据集介绍
本文中所设计的实验均采用CAIL2018数据集[9],该数据集由2018年“中国法研杯”司法人工智能挑战赛所提供,是我国目前第一个针对裁判预测所制备的大型法律数据集,其中的数据收集自中国裁判文书网,均源于中国最高人民法院公开的真实刑事案件。CAIL2018数据集中包含超过260万条数据,而本文采用的数据集为其中的一个子集CAIL2018-Small,并已由大赛主办方事先划分为了训练数据集(data_train.json)、验证数据集(data_valid.json)和测试数据集(data_test.json)。整个数据集包括19.6万份裁判文书样例,其中训练数据集包含154592条数据,验证数据集包含17131条数据,测试数据集包含32508条数据。据大赛主办方描述,数据中筛除了刑法中的前101条(与罪名无关),筛除后的数据共涉及183项法条和202项罪名。
除了拥有数据量大的优势以外,该数据集的另一大优势是其丰富的案件标注信息。数据集中的数据组成如表2.1所示,每条数据均包含以下六个主要字段:事实描述(fact)、被告(criminals)、罚款(punish_of_money)、罪名(accusation)、相关法条(relevant_articles)和刑期(term_of_imprisonment)。其中刑期部分还详细划分了三个子字段:死刑(布尔型数据)、无期徒刑(布尔型数据)和有期徒刑刑期(整型数据),如表2.2所示。罚款的单位为人民币元,刑期的单位为自然月。
表2.1 数据组成示例
被告 | 刑期 | 罚款 | 罪名 | 相关法条 | 事实描述 |
张某某 | 2 | 0 | 盗窃 | 264 | 公诉… |
表2.2 刑期字段示例
死刑 | 无期徒刑 | 有期徒刑 |
False | False | 2 |
本文的实验是基于数据集中的事实描述内容对案件涉及罪名进行预测,即以前者作为数据特征、以后者作为数据标签进行文本分类实验。因此,原始数据集中包含许多对实验而言无用的字段,我们将在下一节进行数据预处理工作。
2.2 数据预处理
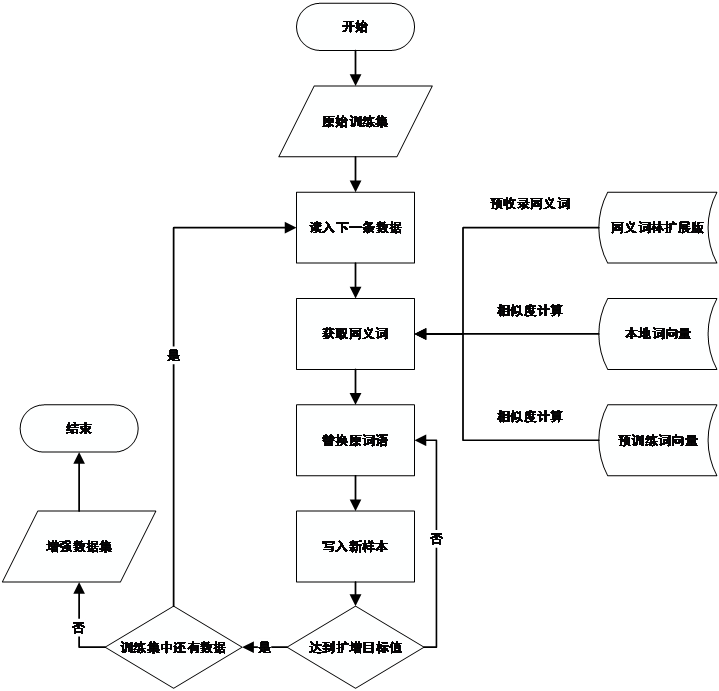
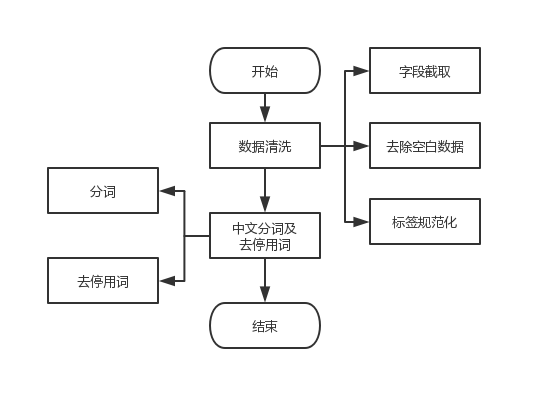
由于CAIL2018数据集在设计之初是为了服务于不同的司法裁判预测任务,数据集中包含大量与罪名预测无关的数据,且具有冗余、数据残缺、标签不一致等特点。然而数据质量决定了文本分类效果的天花板,后续实验都只是在逼近这个天花板,因此我们需要对原始数据集做必要的预处理,数据预处理流程如下图2.1所示。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: