分布式深度学习算法的部署及其实现毕业论文
2020-02-16 22:49:09
摘 要
深度学习是机器学习中一种基于对数据进行表征学习的方法,近年来在机器学习领域取得了重大的突破,成为了人们的研究热点之一。有证据表明在深度学习中,模型规模和数据规模的增大能够有效地提高模型精度,但随着规模的增长,在单机训练存在着耗时长等的问题。本文针对深度学习中的卷积神经网络进行研究,完成基于Kubernetes的分布式TensorFlow平台下卷积神经网络算法的部署与实现。主要工作包括完成基于ResNet算法下MNIST数据集手写数字识别的分布式实现,并且与单机式的ResNet算法进行性能比较。
关键词:深度学习;卷积神经网络;分布式;TensorFlow;ResNet
Abstract
Deep learning is a method based on the representation and learning of data in machine learning. In recent years, it has made a major breakthrough in the field of machine learning and has become one of the research hotspots. There is evidence that in deep learning, the increase in model size and data size can effectively improve the accuracy of the model, but with the increase of scale, there is a problem of long time in single-machine training. In this paper, the convolutional neural network in deep learning is studied, and the deployment and implementation of the convolutional neural network algorithm based on Kubernetes' distributed TensorFlow platform is completed. The main work includes the implementation of distributed implementation of handwritten digit recognition of MNIST dataset based on ResNet algorithm, and performance comparison with single machine ResNet algorithm.
Key Words: Deep learning; convolutional neural networks; distributed; TensorFlow; ResNet
目 录
摘要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 2
1.2.1 TensorFlow研究现状 2
1.2.2深度学习研究现状 2
第2章 关键技术介绍 4
2.1 TensorFlow深度学习框架 4
2.1.1 TensorFlow基本概念 4
2.1.2 TensorFlow系统架构 4
2.1.3 TensorFlow框架特点 5
2.2 分布式云平台架构Kubernetes 5
2.2.1 Kubernetes介绍 5
2.2.2 Kubernetes的核心概念 5
2.2.3 Kubernetes架构和组件 6
第3章 卷积神经网络ResNet实现 7
3.1 ResNet卷积神经网络 7
3.1.1 ResNet与梯度弥散问题 7
3.1.2 ResNet与过网络退化问题 9
3.2 ResNet残差模块实现 10
3.3 ResNet卷积神经网络实现 11
第4章 集中式和分布式TensorFlow的部署及其实现 14
4.1 TensorFlow单机模式实现 14
4.1.1 单机模式TensorFlow原理 14
4.1.2 单机模式TensorFlow实现 14
4.1.3单机模式TensorFlow on Kubernetes搭建 15
4.2 TensorFlow分布式实现 15
4.2.1 分布式TensorFlow原理 15
4.2.2 分布式TensorFlow实现 16
4.2.3 分布式TensorFlow on Kubernetes搭建 17
第5章 测试与分析 19
5.1 实验环境 19
5.2 实验结果与分析 20
第6章 总结与期望 22
参考文献 23
致 谢 25
第1章 绪论
1.1 研究背景与意义
深度学习是机器学习研究中的一个新的领域,其通过建立其具有层级结构的人工神经网络,在计算系统中实现人工智能,是机器学习中一种基于对数据进行表征学习的方法。
深度学习的概念由Hinton等人于2006年提出。Hinton针对神经网络存在的梯度消失的问题,提出了无监督预训练对权值进行初始化和有监督训练微调的解决方案。至此之后,深度学习快速发展,机器学习也开始迅速繁荣。2012年,Hinton等人为了证明深度学习的优势,首次参加ImageNet图像识别比赛,通过其构建的卷积神经网络AlexNet以超出第二名(SVM方法)10%以上的top-5准确率一举夺得冠军[1]。从此,深度学习重新回到人们的视野,学术界和工业界开始将目光投向了深度学习领域。2016年3月,谷歌AlphaGo战胜世界围棋冠军李世石的事件,创造了人机大战史上的一个新的里程碑,并把“人工智能”和“深度学习”的热潮推向了一个新的高潮。随着人工智能的不断发展,深度学习技术慢慢地被扩展到机器学习的各个领域,如计算机视觉、语音识别、自然语言处理、音频处理、计算机游戏、搜索引擎和医学自动诊断等领域,并在学术界和工业界产生了颠覆性的影响。
随着对深度学习领域研究的深入,有证据表明增大模型参数规模和训练数据集,能够有效地提高模型精度,但精度提升同时也带来了巨大的训练时间成本。比如在Google Brain实验室发表的论文《Outrageously Large Neural Network: The Sparsely-Gated Mixture-of-Experts Layer》中提到,一个680亿个参数的模型,如果只能单机训练,那耗时将难以接受[2]。通过分布式深度学习训练框架,可以利用大量服务器构建分布式集群来提高训练效率,减少训练时间。
因此,本文通过在分布式云平台架构Kubernetes上部署分布式TensorFlow,通过实现一个深度学习的卷积神经网络(Convolutional Neural Networks, CNN)分布式算法,来实现对MNIST(Mixed National Institute of Standards and Technology)数据集的手写数字字符识别,并与集中式CNN做性能对比进行性能比较分析。
1.2 国内外研究现状
1.2.1 TensorFlow研究现状
TensorFlow是Google推出的一款开源的实现深度学习算法的框架,是基于DistBelief进行研发的第二代深度学习框架[3]。为了可以更加方便地研究超大规模的深度学习神经网络,Google公司在Jeff Dean的带领下于2011年启动了Google Brain项目,同时开发出了第一代分布式机器学习框架DistBelief。但是,由于它是第一代产品,本身高度依赖Google内部的系统架构而没有被开源,导致能够被分享研究的代码少之又少。为了加速机器学习的研究,并将研究成果更好地转化为产品,Google Brain的研究员和工程师基于DistBelief进行了各方面改进,研发出了第二代分布式机器学习框架TensorFlow[4]。
作为一款开源的深度学习框架,TensorFlow一经出现就获得了极大的关注——一个月内在Github上获得的star超过1万。目前,阿里、腾讯、京东、小米、网易等国内知名互联网企业和Airbnb、Uber、Dropbox等硅谷明星公司,都在生产环境大规模地使用TensorFlow。在谷歌内部,更有超过80%的软件项目采用了TensorFlow。得益于开源社区的众多支持,TensorFlow得到了飞速的发展。
2015年11月,TensorFlow在Github上开源;2016年4月补充发布了分布式版本;2017年2月TensorFlow 1.0正式版发布;2019年3月,TensorFlow 2.0发布。目前,TensorFlow正处在快速开发迭代的过程中,每一个新的版本都会有很高的性能优化,出现新的功能。
1.2.2深度学习研究现状
作为机器学习算法研究中的一个新的技术,深度学习的动机在于建立、模拟人脑进行分析学习。深度学习的应用最早见于图像识别,这可以追溯到2012年,DNN(Deep Neural Networks,深度神经网络)技术在图像识别领域取得了在ImageNet评测上将错误率从26%降低到15%的惊人效果。然而在实际上,深度学习的相关知识早就提出,如LeNet-5是一个专为手写数字识别而设计的经典卷积神经网络,早在1998年就被提出,并在20世纪90年代广泛应用于美国多家银行的支票手写识别上。然而,一直到2012年,深度学习并未取得很大的成功,主要受限于三个方向上的影响[5]:
1)硬件:随着计算机行业的不断发展,电脑硬件不断更新,CUP的运算速度在飞速的提升,在如今能够在笔记本电脑上运行小型深度学习模型的情况,是过去二三十年里无法想象的。深度学习依托于大量的数据以及大量的运算,这对于以前的机器无疑是一个沉重的负担。
2)数据:深度学习需要通过对大量的数据进行训练来获取模型。然而在之前,互联网行业并未兴起的时候,图像数据集、视频数据集和自然语言数据集等难以去收集,深度学习缺乏训练的数据来源,难以发展起来。
3)算法:除了硬件和数据之外,在之前我们一直没有可靠的方法去训练非常深的神经网络。直到2006年以后,激活函数(activation function)、权重初始化方案(weight-initialzation scheme)、更好的优化方案(optimization scheme)等算法上的改进,让深度学习进入了一个快速发展期。
如今随着硬件、数据集、算法的不断发展,深度学习进入了一个爆发式的发展阶段,慢慢地被扩展到机器学习的各个领域,如计算机视觉、语音识别、自然语言处理、音频处理、计算机游戏、搜索引擎和医学自动诊断等领域,并且都有着出色的表现。
第2章 关键技术介绍
2.1 TensorFlow深度学习框架
2.1.1 TensorFlow基本概念
在TensorFlow的命名中,Tensor即张量,表示数据,指的是N维数组;Flow表示流动,指的是基于计算图的运算。所以TensorFlow就表示为张量数据在计算图之间流动的运算的过程,即数据结构在神经网络中的分析和处理过程。TensorFlow程序中的计算过程可以表示为一个计算图,图上每一个运算操作可以被视为一个节点,每一个节点可以有任意个数的输入和输出。当在某两个运算中,运算的输入值取自另外一个运算的输出值,节点就可以在这样一种依赖关系下,通过边进行相互连接。用户在使用TensorFlow时,需要通过使用会话(Session)来执行定义好的计算图的运算。
2.1.2 TensorFlow系统架构
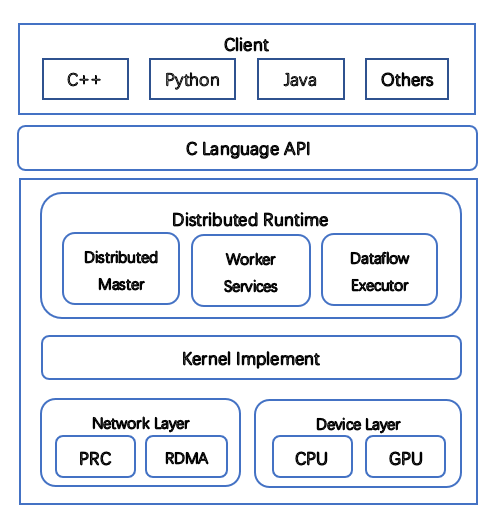
图2.1 TensorFlow系统架构图
TensorFlow系统架构如图2.1所示,一层C的API接口将底层的核运行部分与顶层的多语言接口分离开,分隔出前端和后端两个子系统。其中前端系统提供编程模型,完成计算图的构建;后端系统根据前端部分的代码调用情况,搭建运行环境,并且执行计算图的运算。
2.1.3 TensorFlow框架特点
TensorFlow具有灵活的架构,能够完成各种数据流图的运算,并支持多种语言,可以使用C 、Python、Java等编程语言实现。TensorFlow支持多种环境和集群,能够在单个或多个CPU、GPU上进行计算,支持Linux、Windows等操作系统,具有可移植性。此外TensorFlow从底层实现对线程、队列和异步运算的支持,用户只需要提供目标函数和数据,能够方便地调用所有可以使用的硬件资源,自动把节点分配给不同的设备完成相关计算。
2.2 分布式云平台架构Kubernetes
2.2.1 Kubernetes介绍
Docker是由dotCloud公司发起的一种新兴的容器化的云开源项目,而Kubernetes是由谷歌开源的系统,用于管理云平台上服务器的Docker容器,为Docker容器化应用提供了资源调度管理、服务部署运行、集群扩容等一系列的机制[6]。2015年7月,Kubernetes 1.0正式发布,便吸引了业内巨头的纷纷加入。直到现在,Kubernetes已经成为了业界广泛认可和看好的Docker分布式系统解决方案。
2.2.2 Kubernetes的核心概念



