基于DRL算法的船舶路径规划方法研究与实现毕业论文
2020-02-16 22:29:15
摘 要
随着“一带一路”建设的推进,水路运输凭借承载量大、成本低成为远程运输的主要方式,航运事业压力骤增。及时有效地进行船舶路径规划是航运智能化发展的重要内容之一。目前,实现路径规划的算法众多,但大多数研究以离散空间为主,弱化了船舶运动的连续性,且较少结合船舶航行特点进行路径规划。本文利用深度强化学习(DRL)算法探索船舶的局部路径规划和全局路径规划,主要工作如下:
(1)基于船舶航行特点的路径规划分析。结合船舶航行特点分析了船舶路径规划的特点,同时将DRL算法与路径规划问题对比,研究两者的契合点。
(2)基于DDPG (Deep Deterministic Policy Gradient)算法的船舶局部路径规划方法研究。利用参数噪音增强动作的探索性,融合优先回放机制优化DDPG算法的样本批量采样效率,设计合理的奖励函数,实现船舶的无碰撞局部路径规划。
(3)基于PPO(Proximal Policy Optimization)算法的船舶全局路径规划方法研究。通过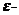 贪婪策略提高动作空间的多样性,同时利用回报值与预测的差量进行样本筛选,根据环境特征设计奖励函数,提高学习效率,保证船舶的安全性与经济性。
贪婪策略提高动作空间的多样性,同时利用回报值与预测的差量进行样本筛选,根据环境特征设计奖励函数,提高学习效率,保证船舶的安全性与经济性。
(4)实验验证与分析。基于pygame构建的实验环境将改进算法与原算法、其他同类型算法进行对比分析,结果表明本文所提出的方法能有效地完成路径规划任务。
关键词:全局路径规划;局部路径规划;连续空间;DDPG;PPO
Abstracts
With the development of the Belt and Road construction, waterway transportation has become a major mode of transportation for long-distance transportation due to its larger carrying capacity and lower cost. The pressure on shipping industry has surged. Timely and effective ship path planning is one of the important contents of the intelligent development of shipping. At present, there are many algorithms for implementing path planning, but most of the researches are based on discrete space, which weakens the continuity of ship motion and they rarely combine ship navigation characteristics for path planning. This paper uses the actor-critic algorithm to explore the local path planning and global path planning of the ship. The main work is as follows:
(1) Analysis of path planning based on the characteristics of ship navigation. Based on the characteristics of ship navigation, the characteristics of ship path planning are analyzed. At the same time, At the same time, the DRL algorithm is compared with the path planning problem to study the fit between the two.
(2) Research on ship local path planning based on DDPG (Deep Deterministic Policy Gradient) algorithm. The paper use parameter noise to enhance the exploratory nature of the action, and the priority replay mechanism to optimize the sample efficiency of the DDPG algorithm, and a reasonable reward function is designed to realize the collision-free local path planning of the ship.
(3) Research on ship global path planning based on PPO (Proximal Policy Optimization) algorithm. Through the greedy strategy to improve the diversity of the action space, the sample is screened by the difference between the return value and the predicted value, and the reward function is designed according to the environmental characteristics to improve the learning efficiency and ensure the safety and economy of the ship.
(4) Experimental verification and analysis. Based on the experimental environment constructed by pygame, the improved algorithm is compared with the original algorithm and other algorithms of the same type. The results show that the proposed method can effectively complete the path planning task.
Key Words:Global path planning; Local path planning; Continuous space; DDPG; PPO
目 录
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.3 本文研究内容 2
1.4 本文组织结构 3
第2章 基于船舶航行特点的路径规划分析 5
2.1 问题描述 5
2.2 船舶航行的数学模型 5
2.3 船舶路径规划特点 6
2.4 DRL算法与路径规划问题的契合点 7
2.5 本章小结 7
第3章 基于DDPG的船舶局部路径规划算法研究与实现 8
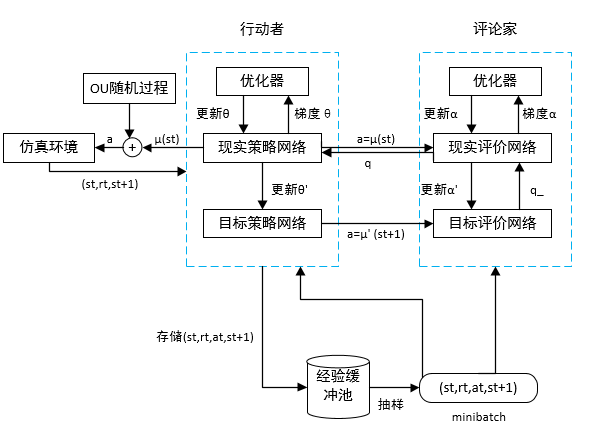
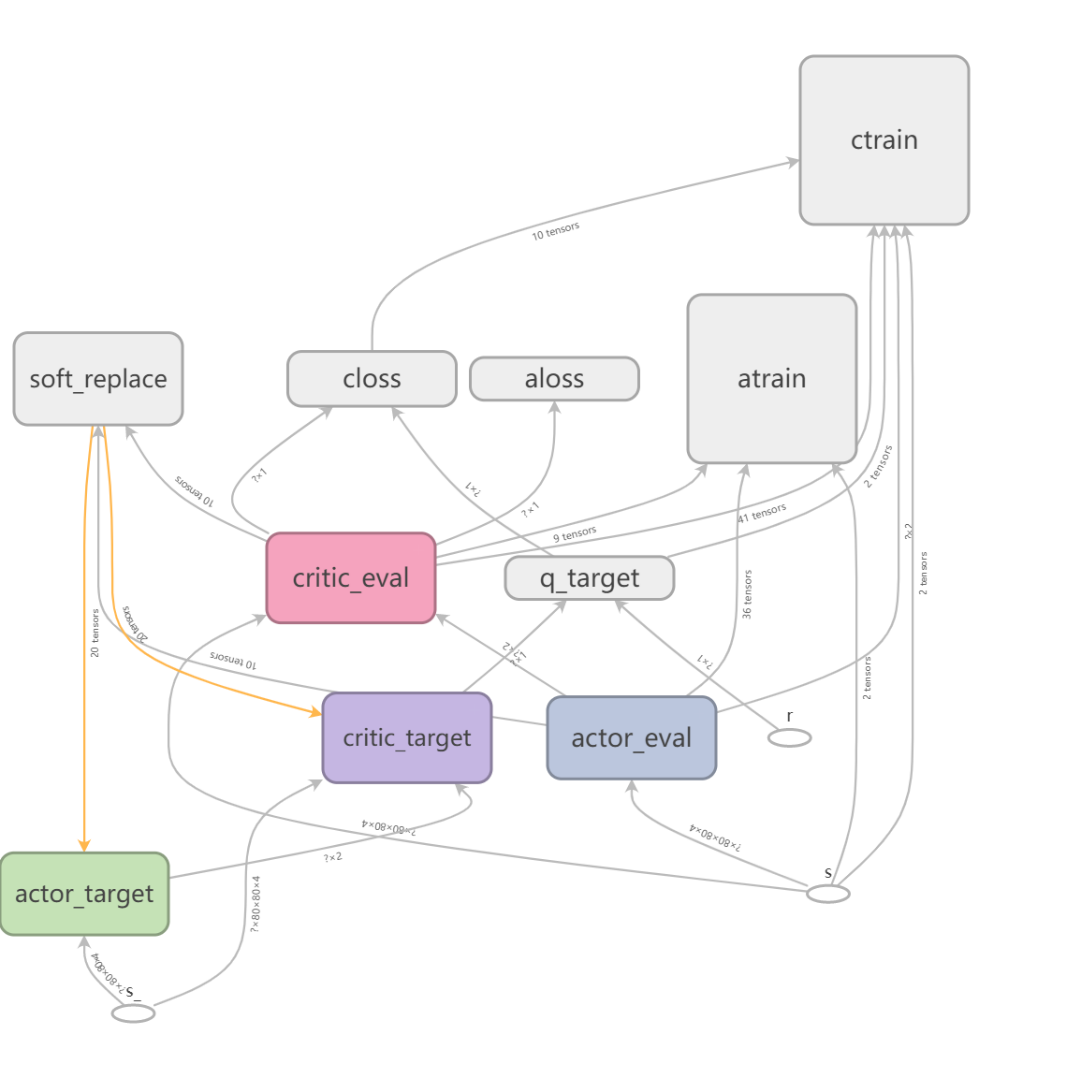
3.1 DDPG算法 8
3.2 基于DDPG的船舶局部路径规划算法的改进 9
3.3 基于DDPG的船舶局部路径规划方法 10
3.3.1 船舶局部路径规划参数设置 10
3.3.2 基于DDPG的船舶局部路径规划算法设计 12
3.4 本章小结 15
第4章 基于PPO的船舶全局路径规划算法研究与实现 16
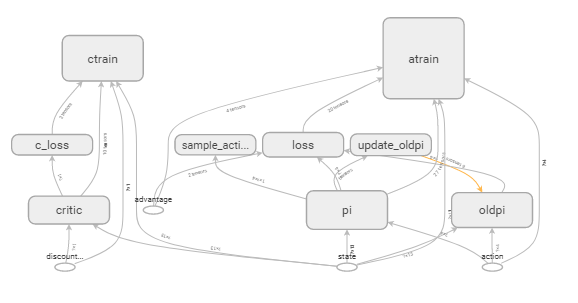
4.1 PPO算法 16
4.2 基于PPO的船舶全局路径规划算法的改进 16
4.3 基于PPO的船舶全局路径规划方法 17
4.3.1 船舶全局路径规划参数设置 17
4.3.2 基于PPO的船舶全局路径规划算法设计 19
4.4 本章小结 21
第5章 路径规划算法实验对比分析 22
5.1 实验平台 22
5.2 环境搭建与实验指标 22
5.2.1 环境搭建 22
5.2.2 实验指标 24
5.3 基于DDPG的局部路径规划算法对比与分析 25
5.3.1 实验方案 25
5.3.2 实验结果及分析 26
5.4 基于PPO的全局路径规划算法对比与分析 28
5.4.1 实验方案 28
5.4.2 实验结果及分析 29
5.5 本章小结 30
第6章 总结与展望 31
6.1 全文总结 31
6.2 下一步工作 31
参考文献 32
致谢 34
第1章 绪论
1.1 研究背景与意义
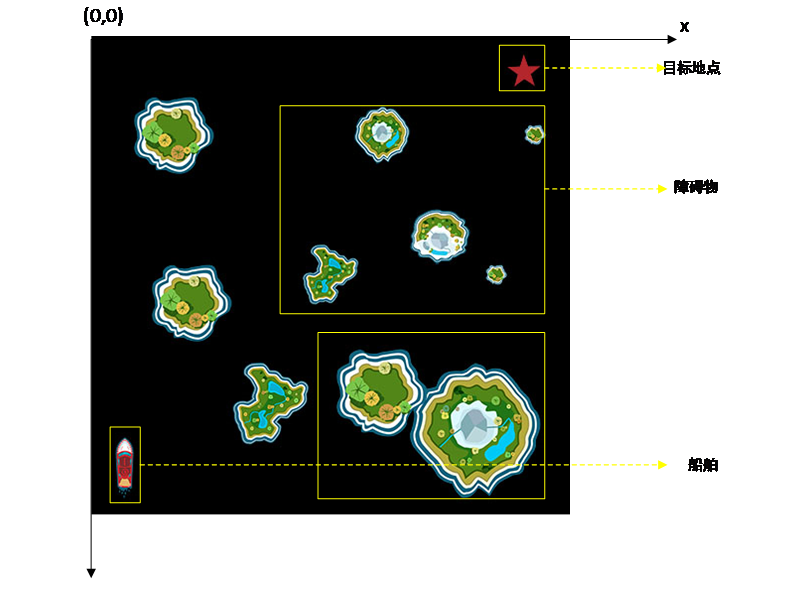
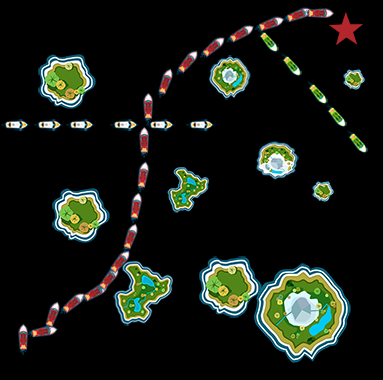
随着航运事业的发展,特别是“一带一路”建设的推进,航运压力加大,船舶驾驶员工作负担加重,基于个人经验的规划航行和应急事件处理能力下降,航运风险上升,有效降低航运风险和压力成为当前亟待解决的问题之一。路径规划的提出为其给出有效的解决方案,在船舶航行过程中,水上船舶、礁石、浅滩等都是航运过程中的巨大威胁,在复杂的水域条件下,实现船舶的自主避碰和导航成为协助船舶操作者工作、降低航运风险和压力的有效手段。目前针对路径规划的研究已经提出众多算法,包括A*算法、蚁群算法、遗传算法等,这些算法普遍使用离散动作空间,这与现实世界的空间连续性不相符合。传统研究中引用船舶碰撞域模型将船舶作膨化处理,使其实现自主避碰,这种方式虽能有效进行障碍物躲避,但也将延长规划路线,降低了经济性。以安全性、经济性与时效性为目标的船舶路径规划是其智能化发展的重要方向。安全性即为有效躲避对船舶产生威胁的事物,经济性旨为以最小的人力、物力耗费实现既定的任务,时效性主要体现为算法的训练时间,尽可能快的完成模型训练。
深度强化学习的提出为路径规划问题提供新的解决思路。将深度学习的特征抽取与强化学习的探索和利用有效结合,利用深度学习的感知能力和强化学习的决策能力,以高维视觉图像为输入控制智能体的行为,获得合理的解决方案。目前深度强化学习研究算法较多:DQN、DDPG、TRPO、PPO、A3C等,结合船舶特点合理选择算法以实现合理的路径规划。本文针对适用于连续空间的DDPG和PPO算法进行船舶规划问题的研究,旨在实现有效的路径规划方案,促进智能航运事业的发展。
1.2 国内外研究现状
(1)船舶路径规划研究现状:船舶的智能化发展对船舶路径规划的要求越来越高,船舶路径规划分为两类:全局路径规划和局部路径规划。全局路径规划中主要解决航行过程中的两个重要问题:从起点到终点航程中避开静态障碍物规划路径长度最短且能源消耗最少;而局部路径规划主要解决航程内对突发船只或漂浮物的躲避问题。目前国内外对船舶路径规划算法的研究如下:
Shengke Ni [1]等人提出了一种基于非线性遗传算法的船舶路径规划方法,应用非线性编程平衡局部优化和全局优化;Lukasz Kuczkowski [2]等人提出一种考虑动态策略障碍物的基于进化算法的路径规划方法,这种方法可以近乎实时地计算船舶的有效且近似最优路径;范云生[4]等人利用栅格将海洋环境信息量化,建立环境模型,对遗传算法引入经济性、安全性和光滑性评价因子进行改进,进一步优化路径;Sung-Min Lee[5]等人基于船舶航线规划问题,提出了一种用于同时确定船舶的路径和速度的路径规划方法;Liu[6]等人基于链图法建立海洋环境模型,设计了一种改进的多种群粒子群优化算法,该算法能够平衡种群的全局和局部搜索能力;杜哲[7]等人针对多移动障碍物的复杂通航环境,结合改进的A*算法提出了基于动态复杂度地图的航迹规划方法;侯春晓[8]等人针对内河无人船应用,提出考虑水流影响的局部路径规划算法,并将直线路径的LOS循迹算法拓展到一般曲线路径的 LOS 循迹控制算法;
(2)基于深度强化学习的路径规划现状:目前应用深度强化学习的路径规划已经在移动机器人、无人车、无人机等领域取得较好的发展,具体研究现状如下:
董培方、张志安[9]等人通过在Q-learning算法中加入初始环境先验信息,对环境区域进行逐层搜索,剔除凹形区域Q值迭代,加快路径规划收敛速度;Wang[3]等人将DQN算法应用到路径规划中,根据问题描述设计状态、动作空间及奖励函数,解决船舶静态和动态障碍物避碰问题;Lei[11]等人将DDQN算法应用到未知环境中,针对不稳定性和稀疏性设计奖励函数和训练方法,实现不同环境下智能体的路径规划;Zhao[12]等人针对局部优化限制和收敛速度慢的问题,将强化学习方法与异步方法相结合,有效解决路径规划问题;Chaymaa Lamini[13]等人提出基于H-MAS架构的新Q-learning方法,此方法使用两种Q表:QET和QMT,以解决部分或完全未知环境中的移动机器人的路径规划问题;
(3)Actor-Critic算法研究现状:AC算法是一类强化学习方法,其综合了policy gradient和value-based的优点,目前AC算法的研究现状如下:
Paul S [14]等人提出一种基于确定性策略的行动者-评论家框架来编码路径规划策略,该强化学习代理仅使用两种不同的环境视图来学习路径规划,其效果优于基于深度Q-learning的方法;刘全等[15]将两组策略参数的加权作为最优策略,使用动作区间对最优动作的取值进行约束,以防止动作越界,利用资格迹更新策略参数,提高了算法的收敛速度和稳定性;Timothy[16]等人结合DQN的经验回放机制和固定目标网络,提出一种基于DPG算法的AC算法-Deep DPG;Schulman[17]等人利用裁剪机制对新旧策略概率比进行限制解决策略梯度更新步长的问题;Wang[18]等人利用置信域标准,有效提高[17]中因裁剪机制限制了的探索能力;Junhyuk Oh[19]等人提出一种AC算法-自我模仿学习,能够充分利用过去的经验进行深度探索;
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: