图像字符识别方法研究毕业论文
2020-02-16 22:09:50
摘 要
许多文档是以纸质文档的形式保存的,将其录入计算机是一件非常繁琐的事情,而字符识别自动、快速的处理能大大提高信息的采集速度,减轻人们的工作强度。现如今,随着计算机技术的快速发展,图像字符识别技术多年以来不断的完善与改进,其技术已经在各个领域得到了广泛的应用,让大量纸质文档、证件信息能够快速、便捷的录入计算机中。
本文针对图像字符识别的相关方法进行研究,使用开源软件OpenCV与Tesseract-OCR进行辅助完成中文印刷体文字的图像识别。主要的工作包括:1、图像的预处理,本文对预处理的方法进行了相关的研究,如图像灰度化、图像二值化、图像腐蚀。研究了其预处理的作用与实现效果,OpenCV中相关函数的使用方法。2、字符识别,使用Tesseract-OCR对处理的图像进行字符识别,研究了其使用方法,对其效果进行了测试,并研究了其他识别的相关技术。
最后完成的主要功能是通过eclipse进行图片文件的读取,从而完成中文印刷体文字的文字识别,完成后可以观察原图片、预处理图片与识别的文本。
关键词:图像预处理;字符识别;OpenCV;Tesseract-OCR
Abstract
Many documents are stored in the form of paper documents. It is very cumbersome to record them into the computer. The automatic and fast processing of character recognition can greatly improve the speed of information collection and reduce people's work intensity. Nowadays, with the rapid development of computer technology, image character recognition technology has been continuously improved and improved over the years. Its technology has been widely used in various fields, allowing a large number of paper documents and document information to be quickly and conveniently entered into computers in.
This paper studies the related methods of image character recognition, and uses open source software OpenCV and Tesseract-OCR to assist in image recognition of Chinese printed characters. The main work includes:1. Image preprocessing. This paper has carried out related research on preprocessing methods, such as image graying, image binarization and image etching. The role and implementation of its preprocessing and the use of related functions in OpenCV are studied. 2, character recognition, using Tesseract-OCR to character recognition of the processed image, studied its use method, tested its effect, and studied other related technologies.
The main function of the final completion is to read the image file through eclipse, thus completing the text recognition of the Chinese printed text. After completion, the original image, the preprocessed image and the recognized text can be observed.
Key Words:image preprocessing; character recognition; OpenCV; Tesseract-OCR
目 录
第1章 绪论 1
1.1 研究的目的及意义 1
1.2 字符识别的发展概况 1
第2章 图像字符识别技术 3
2.1 图像字符识别的技术 3
2.1.1 模板匹配法 3
2.1.2 人工神经网络 3
2.1.3 支持向量机 3
2.1.4 BP神经网络算法 4
2.2 Tesseract-OCR引擎 4
2.2.1 Tesseract-OCR介绍 4
2.2.2 Tesseract-OCR的使用原因 5
2.2.3 Tesseract-OCR的识别过程 5
第3章 系统分析与总体设计 6
3.1 需求分析与工作流程 6
3.2 系统功能模块设计 6
3.2.1 图片输入模块 6
3.2.2 图片预处理模块 7
3.2.3 图片转化模块 7
3.2.4 文字识别模块 7
3.3 开发环境 7
第4章 系统功能实现 8
4.1 图像的输入 8
4.2 图像预处理 8
4.2.1 图像灰度化 8
4.2.2 图像二值化 10
4.2.3 图像腐蚀 11
4.3 图像转化 13
4.4 字符识別 14
第5章 系统测试分析 15
5.1 识别结果的分析 15
5.2纠错处理 17
5.2.1 Merge样本文件 17
5.2.2 配置字体文件 17
5.2.3 生成BOX文件 18
5.2.4 字符纠错 18
5.2.5 生成训练文件 18
第6章 总结与展望 20
6.1总结 20
6.1展望 20
参考文献 21
致 谢 22
第1章 绪论
1.1 研究的目的及意义
随着21世纪信息时代的到来,信息技术特别是计算机技术、通信技术和计算机网络技术的发展速度越来越快,信息对整个社会的影响也越来越重要。社会的不断发展使得信息量急剧的增长,面对大量的信息,信息的处理速度便成为信息技术发展的一道难题,而计算机的发展给信息处理带来了新的解决方法。目前,有大量的信息被储存在图片、视频中,如果依靠人工的方法提取其中的信息,那是非常的繁琐,并且效率低下。因此,字符识别技术就越来越受到人们的重视。
字符识别又称之为光学字符识别(Optical Character Recognition),简称OCR,是一种对图像进行分析,提取其中文字的方法。一般使用扫描仪或照相机等设备,将需要获取的字符信息转化为图片格式,通过对图片进行处理,提取其中包含文字的区域,然后用字符识别技术将其转化为计算机可识别的文本文字的过程。通过这样的方法,我们可以将一些不可编辑的文档和图片转换为可编辑的内容[1]。
在经济活动中,很多业务系统都需要录入纸质文档和证件(身份证、行驶证、护照等证件)信息,传统的人工录入方式,不仅录入速度低下,而且使用的人力成本也较高,其人工带来的错误率难以降低,对企业的风险也难以估计。而在手机移动端录入各种证件、单据也非常麻烦,面对较长的数据,一旦输错查看起来非常麻烦,用户体验很差,如果使用字符识别,能快速的拍照识别,就能提升用户体验和使用效率。
字符识别技术已经大量地应用于人们的日常生活中,现在一般通过扫描仪、外接摄像机等设备将识别图像传入计算机,然后对其中的关键字段进行识别与认证,例如通用机打发票字符的识别[2]。字符识别在对表格、文字方面的字符处理有相当高的识别率,因此银行的存单,超市的进货单,增值税发票等都可以使用字符识别技术进行识别。
目前,仍有大量信息需要通过文字识别技术转换到计算机中,针对不同情况的文字识别技术也在不断的发展,如何提高识别的速度和识别的准确率将会是字符识别的重要发展方向。
1.2 字符识别的发展概况
在上个世纪60年代初,模式识别技术得到人们重视,并迅速发展成为一门学科。模式识别是通过计算机来实现对复杂信息进行自动处理的过程,模式识别的相应技术理论都在很多领域中得到了应用,其中对模拟人类部分脑力活动的研究推动了人工智能发展,也加快了计算机信息处理的速度与效率[3]。而字符识别技术作为模式识别的一个重要分支,也随之进一步发展。目前,字符识别技术经过不断的深入研究,已经逐渐完善,大量应用于日常生活中。
早在1929年,德国科学家Tausheck就已经提出了字符识别的概念。而后在1955年,出现了第一款印刷体数字的字符识别产品,后来又进行了印刷体英文的识别。在此之后手写体数字和英文的识别成为了字符识别的研究热点。而印刷体汉字由于其结构复杂,汉字数量众多的原因,其研究比较靠后,最早的一篇关于汉字识别的文章由美国IBM公司的Casey和Nagy发表。
目前,关于字符识别的技术都已经十分成熟,从最初的对印刷体字符的识别,到现在开始研究对手写体字符的识别,从对单个字符的识别,到现在可以运用文字的表达方式来对前后文进行判断识别,字符识别的效率与准确性越来越高。现在,还可以通过对识别样本的细化,针对不同需求的软件进行设计,例如针对汽车牌照的字符识别、针对身份证的字符识别等。
第2章 图像字符识别技术
2.1 图像字符识别的技术
随着字符识别技术的不断探索与研究,除了最基础的模板匹配法外又提出了更多的分类方法。例如McCulloch W和Pitts W提出的人工神经网络(ANN)、Vapnik和Chervonenkis提出的支持向量机(SVM)、Rumelhart DE和McClelland JL提出的BP神经网络算法等,为模式识别注入了新的活力,也增加了字符识别技术识别的精度与准确性。
2.1.1 模板匹配法
模板匹配是最先被使用于字符识别技术的方法,也是最基本的模式识别方式。它采用的是对图像进行匹配的方法,即采用文字模板对识别的图像进行匹配,选择其中误差最少的文字作为识别结果。模板匹配法在对少量的字符进行识别时有着一定的正确性,但对大量字符进行处理,会面临精准度低、耗时多的问题[4]。
2.1.2 人工神经网络
人工神经网络(ANN)能够自动学习和记忆,通过模拟人的神经系统对字符进行识别。人工神经网络是一种运算模型,由于其结构与人类神经网络相识而得名。人工神经网络有着多种的的输出函数,又称之为激励函数(activation function),每个函数相当于一个神经节点。而每个节点之间的连接,都是对相连函数的运算,其运算使用不同的加权值,称其为权重。一个典型的人工神经网络,由一个输入层(input layer),多个隐藏层(hidden layer)和一个输出层(output layer)构成,可以将其看成是从输入空间到输出空间的一个非线性映射。通过调整权值来“学习”和改变变量之间的关系,从而实现分类[5]。
人工神经网络有着较强的自适应能力,对于样本缺失、分析对象损坏等情况都有一定的容错能力,因此人工神经网络被广泛地应用于各类领域之中,如模式识别,信息处理,决策制定等。
2.1.3 支持向量机
支持向量机(SVM)是对数据进行二元分类的广义线性分类器,它被提出于1964年,并在二十世纪90年代后得到迅速的发展,衍生出了一系列的改进算法。于1995年提出的软边距SVM,被应用于手写数字识别问题。它利用核函数的方法巧妙地实现了复杂的线性变换,将初始特征的非线性问题转换为线性问题。支持向量机中最大分类间隔的准则更是保证了它在模式识别领域中的优异的使用性[6]。
支持向量机能够在样本数量较少并且特征值的维度较高的情况下,保证良好的识别精度,拥有较快的识别速度,因此被广泛的应用于人脸识别、手写数字识别的研究。
2.1.4 BP神经网络算法
BP神经网络是人工神经网络的衍生类型,也是目前应用最为广泛的一种人工神经网络。传统的人工神经网络只能通过输入函数向输出函数的方向来改变权重,但BP神经网络可以逆向的改变权重,从而改变变量之间的关系,因此实现分类[7]。
BP神经网络与一般的人工神经网络相同,都具有一个输入层、多个隐藏层和一个输出层。它是一种按误差逆向传播训练的多层前馈人工神经网络,其具有对任意复杂的模式进行分类的能力,并且拥有优秀的多维函数映射能力,解决了简单感知器不能解决异或的问题。基本的BP神经网络算法包括信号的前向传播和误差的反向传播两个过程。在计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行[8]。
BP神经网络具有极强的非线性数据的处理能力和容错能力,这让其被应用于多种领域中,为人工神经网络注入了新的活力。
2.2 Tesseract-OCR引擎
2.2.1 Tesseract-OCR介绍
Tesseract-OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生。在2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。从2006年到现在,Tesseract都由Google公司开发维护[9]。
Tesseract-OCR作为开源项目,其代码和运行程序均可在GitHub网站上获得。目前,Tesseract-OCR最新版本为4.0版本,已经支持超过100种语言,也可以用其程序来训练其他的语言。Tesseract-OCR支持多种输出格式,包括普通文本、HTML、PDF等。
Tesseract-OCR的主要运行程序为tesseract.exe,采用命令行的方式进行调用。其默认的识别文字为英文,若想进行中文字符识别则需要额外下载简体中文包。Tesseract-OCR支持多种编程语言,可以使用libtesseract的接口来构建相应的程序。
2.2.2 Tesseract-OCR的使用原因
目前国内外,在商业领域的OCR产品已经发展得相对成熟了,其识别的速度和准确率都非常高。但使用商业产品进行二次开发需要花费不少的费用,因此开源的Tesseract-OCR是一个很好的选择。虽然Tesseract-OCR的识别速度和准确率相比而言有所不如,但对于一款小型设计而言却是足够的,它在识别文字方面的功能已经可以满足此项目了。
2.2.3 Tesseract-OCR的识别过程
Tesseract-OCR的识别步骤大致如下[10]:
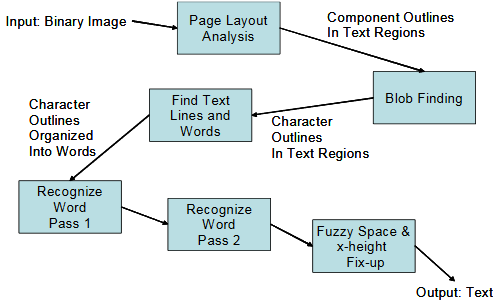
图2.1 Tesseract-OCR的识别步骤
1)连通区域分析,通过对识别图像的像素灰度的连贯性,将图片中文字所在区域分割开来,将所有文字区域集成为块区域。
2)将块区域的文字按照行进行分割得到文本行,对其中的文字进行进一步分割,以矩形框将不同的文字进行区别开。
3)依次对每个文字进行分析,采用自适应分类器。该分类器具有一定的学习能力,可以确保相应字符的准确性。但Tesseract-OCR对于模糊的图片以及比较复杂的字符的识别精度比较低,识别的错误率较高。
4)对于比较含糊的空格区域,采用其他方式,如用笔画高度(x-height)等识别。
第3章 系统分析与总体设计
3.1 需求分析与工作流程
根据设计内容,本系统需要完成把扫描或拍照的图片转换成word或其他文档,因此系统的输入输出如下:
输入:输入一张图片,其格式为jpg或png。
输出:将图片中识别的文字保存在文本文档中。
在识别完成后其结果保存在系统的根目录中,为了便于观察识别的结果,需要将识别图片与识别文档打开。
而识别的具体流程如下图所示:
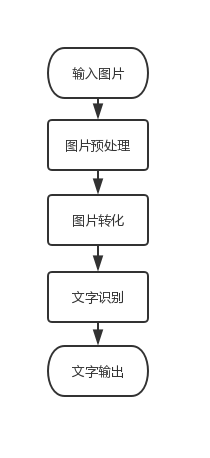
图3.1 工作流程
3.2 系统功能模块设计
3.2.1 图片输入模块
本模块的设计较为简单,在系统中输入文件的地址,系统读取后判断文件是否存在,返回文件参数,读取文件类型,将正确的jpg或png格式统一保存到根目录中。
3.2.2 图片预处理模块
在将图片文件保存在系统后,为了方便图像进行识别,需要对图像进行相应的处理,在此模块中,因包含三个处理——图像灰度化、图像二值化、图像腐蚀。这三个处理可以极大地避免背景颜色和图形对识别结果的影响,可以提高文字识别的识别效率,其具体功能和实现方法请见第4章。
3.2.3 图片转化模块
本模块是对图像预处理功能的一个完善,其主要目的是将得到的处理图片的格式由jpg转换为tif。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: