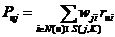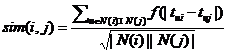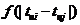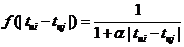基于机器学习的智能图书推荐系统研究与实现毕业论文
2020-02-16 21:23:53
摘 要
在信息过载的时代,要从海量数据中快速准确地寻找对自己有用的信息,推荐系统是必不可少的。为了对推荐这一领域进行初步的入门和了解以及将其基础的理论知识和算法结合到实际应用中并解决实际问题,本文研究和实现了基于机器学习的智能图书推荐系统。本系统基于python3.7开发环境,Django Web框架和基于物品的协同过滤机器学习算法,不是单独地实现推荐功能,而是将推荐系统嵌入在图书售卖网站上作为子功能来实现,使其有可视化,可理解的数据来源以及更明显的实际意义。本文所设计的图书推荐系统能够提供简洁美观的界面和灵活方便的用户操作,能够根据实际需求,将推荐算法进行合理的运用,修改和融合,实现了根据用户的基本信息和对于图书的行为实时向用户推荐最可能合乎用户兴趣的图书,并对每一项推荐结果给出合理的解释的主要功能。
关键词:机器学习;推荐系统;图书;智能
Abstract
In an era of informational overload, in order to find quickly and correctly what you need from mass data, the recommendation system is indispensable.for preliminarily initiating into and understand this domain as well as combining basic speculative knowledge and algorithm with practical application to solve practical problems, I have studied and realized in this paper a intellectual recommendation system of books based on machine learning.The system above, based on python 3.7 exploitation environment, Django Web framework and machine learning algorithm of item cf, haven’t actualized merely the recommendation function but a online bookstore with the recommendation system as a subfunction, which provides visual and comprehensible source of data and practical meaning.The recommendation system of books designed in this paper provides simple and beautiful interface with user operations which are flexible and convenient, utilizes, modifies and combines recommendation algorithm according to practical requirements, thereby realizes the function of recommending in time the books which may interest most the users on the basis of users’ personal information and their behaviours and giving reasonable explains for each recommendation results.
Key Words:machine learning;recommendation system;book;intelligence
目 录
第1章 绪论 1
1.1 研究背景、目的和意义 1
1.2 国内外研究现状 2
1.3 课题研究内容与预期目标 2
第2章 智能图书推荐系统关键方法研究 4
2.1 数据获取方法 4
2.1.1 图书信息数据 4
2.1.2 用户信息数据 4
2.1.3 两类数据的获取方法 5
2.2 算法选择与描述 6
2.3 冷启动问题解决方式 7
2.4 异步数据传输方法 8
第3章 智能图书推荐系统设计与实现 10
3.1 登录与注册 10
3.1.1 登录功能设计与实现 10
3.1.2 注册功能设计与实现 10
3.2 图书展示 11
3.2.1 图书分类模块的设计与实现 11
3.2.2 图书详情页面的设计与实现 12
3.3 用户个人中心设计与实现 13
3.4 推荐模块设计与实现 13
3.4.1 推荐模块的输入 13
3.4.2 推荐算法的实现细节 15
3.4.3 推荐模块的输出 20
第4章 结果分析和讨论 21
4.1 推荐系统的常用评测指标 21
4.1.1 系统评测实验方法 21
4.1.2 系统评测指标 21
4.2 图书推荐系统测试及指标分析情况 22
4.2.1 用户满意度,新颖性,惊喜度,信任度和实时性 23
4.2.2 预测准确度,覆盖率和多样性 24
4.3 图书推荐系统的不足 24
第5章 结束语 25
5.1 全文总结 25
5.2 工作展望 25
参考文献 27
致谢 28
第1章 绪论
机器学习是现在极其热门且前沿的一个科学领域,而推荐系统是机器学习的一个重要分支。如今互联网市场上对于推荐系统的需求只增不减,作为推荐技术一种的图书推荐更是成为了每个图书应用都不可缺少的功能之一。本章将从图书推荐系统的研究背景、目的及意义,国内外研究现状和课题研究内容与预期目标这三个方面进行描述,作为本文的开端。
1.1 研究背景、目的和意义
近年来,互联网技术得到了快速的发展和普及,同时智能手机也逐渐走进千家万户。信息产业的蓬勃发展为社会创造了极大数量的信息和数据,标志着我们进入了一个“信息过载”的时代[1]。这种信息和数据的过载有利也有弊。一方面,它使得任何普通人都可以轻松方便地获取大量的资源和资料,在很大程度上有利于人们学习、工作、生活和了解社会。但是,正如过多的选择会带来选择困难,信息的过载往往会导致人们徘徊于大量相关资料之间,却很难精准地找到那些自己真正感兴趣的,对自己真正有用有价值的信息。同时,大数据的发展为人工智能的发展奠定了基础。人类自己无法解决的问题往往可以使用人工智能的相关技术来找到突破口。
那么,如何在大量的数据中快速而准确地找到自己感兴趣的信息呢?
个性化推荐系统就是在这种背景下诞生的。个性化推荐系统是通过建立用户与信息产品之间的二元关系,利用已有的选择过程或相似性关系,挖掘每个用户潜在感兴趣的对象,进而进行个性化推荐[2]。推荐系统的出现不仅有利于用户快速找到自己想要和需要的物品,更好地利用互联网和信息发展带来的好处,对于互联网上的商家也是一大提升营业额的利器。众所周知的电子商务大亨亚马逊,其销售额至少有20%来自它的推荐模块。最后,对于一些在互联网上冷门的物品(长尾物品),由于曝光度少,很难被用户发现,也就难以发挥其真正的作用和价值。而这也是推荐系统要解决的主要问题之一。推荐系统通过充分分析用户的行为,挖掘用户的兴趣,向用户推荐最合适的物品,这个过程一般会优先考虑长尾物品,也就提高了所有资源(不仅仅是热门资源)的利用效率。
作为推荐系统中技术已经比较成熟的一类,图书推荐系统的广泛应用和为互联网上不同的角色带来的效益显而易见。图书推荐网站的个性化服务技术按照服务的方式可分为两种类型:检索和推荐[3]。检索针对的是用户具有明确需求的情况,向用户返回精准的图书信息,而推荐是在用户没有明确想法的时候根据其潜在兴趣提供其可能感兴趣的图书。前者是精准,后者是惊喜。正是这两种功能的结合,才真正满足了用户不同类型,不同时段的需求,真正做到为用户考虑。由此可见,图书推荐和图书检索一样,都是图书系统中必不可少的一个功能。
1.2 国内外研究现状
纵观推荐系统的发展历程,大致可以将推荐系统的研究分为3个阶段。第一阶段是推荐系统形成的初期阶段。第二阶段是推荐系统商业应用的出现。第三阶段是研究大爆发,新型算法不断涌现的阶段[4]。随着大数据,数据挖掘,人工智能等前沿技术及与之相关联的各个领域的迅速发展,得益于这些技术,推荐系统领域不断产生了新的实现思路和解决方法,而不再仅限于那些传统的和已被广泛应用的经典算法,如协同过滤。这使得推荐算法有了更好的准确度和更高的效率,能够更好地适应各种实际需求。
虽然现在的推荐技术已经比较成熟,也在市场取得了很大的成功,但其仍存在很多不足和问题需要改善和解决。首先,推荐系统现在的应用主要集中在网上购物方面,将其运用到其他行业和领域还有待于扩展。推荐技术的应用范围绝不仅限于商业领域,在未来,它应当能够在科学,教育,医学等多个领域发挥作用。其次,推荐算法还存在准确度和性能欠佳和难以很好地解决冷启动等问题的技术缺陷。随着各领域技术和应用的发展,这在未来一定会有更好的解决方法。再者,推荐系统取得用户的信任还不够。一方面,用户的个人信息被推荐系统滥用和泄露,这使得用户对推荐系统基本道德水准和规范难以信任。另一方面,推荐结果的准确性难以证实,且可能出现恶意推荐的情况。这使得推荐结果难以取得用户的信任[5]。
和任何一个正在发展的领域一样,推荐系统领域在方方面面都有值得改进和斟酌之处。这也是我们和后人需要钻研和解决的问题。
1.3 课题研究内容与预期目标
课题的研究内容主要为基于机器学习算法实现一个可以根据用户的偏好等信息有效、准确地推荐相关图书的实例系统。结合老师给定的要求,联系实际,我预期制作一个具备基本功能的网上图书售卖网站,而推荐系统作为该网站的一个子功能来实现。该网站应当包括用户登录,用户注册,图书展示与查询,图书详情查看,用户个人中心,推荐模块等功能模块。推荐算法选择基于用户的协同过滤算法,算法的数据来源是在该网站中注册的用户的基本信息和行为。系统中的用户分为两类,一类是已经在网站中有一定数量(足以产生推荐结果)的行为数据的用户,另一类是还未在图书网站中产生任何行为数据或者产生的数据过少尚不能产生推荐结果的用户。针对这两类不同的用户,算法具有不同的处理方式。对于前一种用户,使用传统的推荐算法产生推荐结果,对于后一种用户,使用与解决冷启动问题类似的方法来生成推荐结果。
我的预期目标不仅仅是简单地实现一个推荐算法就够了,而是希望其能够与实际系统应用结合起来,真正满足用户的需求。另外,每一个算法产生的推荐结果应当给出令人信服的解释。
- 智能图书推荐系统关键方法研究
确认了研究内容和目标之后,就要思考应当使用什么样的方法和技术方案来实现这个图书推荐系统。这些方法不仅仅是实现推荐功能的核心算法,还包括推荐系统运作的基础--数据的获取方法以及解决系统实现难点的方法。本章详细地描述了数据获取方法,核心推荐算法,冷启动解决方法和异步数据传输方法这四种推荐系统实现的关键方法。
2.1 数据获取方法
图书推荐系统中主要的数据来源分为两大类,一类是图书信息数据,另一类是用户信息数据。不同类型数据的获取方法是不同的。
2.1.1 图书信息数据
图书信息数据指的是系统中图书的基本信息,这是用户了解和选择图书最直接和根本的途径(间接的途径包括其他用户的评分、评论,销量和业界专家的认可度等)。现今主流的在线图书商店为用户提供的图书信息结构基本类似,比如在国内几乎是最热门的当当图书网站,它所收录的每本书的数据主要有书名,作者,出版社,出版时间,评论数,价格,图片,所属分类,商品评论,产品特色,编辑推荐,内容简介,目录等。当然,当当是一个大型的商业网站,它和我所要实现的系统的定位和关注点是不同的。在本系统中,只选取那些更基本、更常用的图书信息,至于商品评论、目录这些在实际购书过程中比较重要但与本系统实现关系不大的信息则省去。最后设计出来的图书数据表的数据字段包括书名,出版社,出版时间,作者,价格,图片url,内容简介,编辑推荐,好评率,大类别和小类别。
2.1.2 用户信息数据
用户数据又分为用户基本信息和用户行为数据。用户基本信息指的是与用户自身属性和特征相关的信息。用户行为数据是指用户在系统中所产生的动作被记录下来所产生的数据。一个人的基本信息种类非常多,这里只选取最重要和最能体现用户特点的信息。比如说年龄,它是用户很显著的一个特征,而且用户会喜欢的图书类型和他的年龄关系是很大的,故用户的基本信息中包含年龄是合理的。行业同理。而对于那些和本系统的实现关联不大的信息,如婚姻状况,毕业学校等,就不予以考虑。
用户的基本信息绝不是越多越好,关键在于选择那些对自己的目标有用的。目前设计出的用户基本数据表包含以下字段:用户名,密码,生日,国籍,性别,行业和阅读兴趣。用户的行为数据包括收藏记录,购买记录和评分记录三类。
2.1.3 两类数据的获取方法
对于不同种类的数据,其获取方法也是不同的。用户信息数据由于难以从互联网上直接获取(即使有,也难以和本系统的数据内容和数据格式联系起来),故只能采用手动添加的方式。将用户基本信息和用户行为信息分开考虑,虽然它们都是手动生成的,但生成的时刻也是有区别的。用户基本信息由用户在注册时提供,而用户行为数据由已注册且已登陆的用户在系统中对图书进行各种操作而产生。
图书信息数据,显然是无法通过自行编造产生的,唯一的获取方法是从互联网上其他图书网站中爬取。这里采用的是基于python3的爬虫技术,从苏宁图书网站上获取图书数据。基于python的爬虫比其他语言实现的爬虫要简单和方便很多,而在实际应用中追求的就是简单有效。至于数据源网站,我原先选择的是当当,但是当当由于在网页结构编排上的特点,使得爬虫编写的难度变大了,而苏宁的网页结构明显要简单很多。但是这种选择也是有利有弊的,苏宁图书网站上的信息错误率很高,所以使用代码爬取之后又不得不再进行人工检查和修正。
需要指出的是,在图书信息数据表中,好评率和大类别,小类别是不参与数据爬取的。好评率由推荐系统中所有用户行为计算得出,大类别和小类别是系统已经确定的。系统参考了苏宁网站上的图书分类方法,从中选择比较热门的文学艺术,人文社科,经管励志,健康生活,考试教育,科技这几个大类和每个大类下的若干个小类作为本系统中图书的类别框架。也就是说,系统的图书分类是有限的,这样限制了系统数据量的规模,但是使得数据更加规整。如果不限制分类,会导致获取的图书数据类别太杂乱,数量级也太大。限定了类别之后,爬取的算法就比较简单了:针对图书的每一个小类,找到图书网站中的对应网址,爬取一定数量的该类别的图书,然后从中挑选一部分图书作为该分类下的最终图书列表。选择图书的标准有两个,一是所有的图书要有一定的代表性,即它确实能够很好地代表这个类别的特征,二是这些图书要有一定差异性和丰富性。
本系统所使用的爬虫和常规的爬虫在需求上的区别是,以前编写的爬虫要求全面地爬取符合要求的所有数据,而该爬虫仅需要获取一部分数据即可。
由于苏宁图书网站上每种类别图书的网页结构相似,每本书的详细信息展示页面的结构也有规律可循,故我在此选用了简单轻量的beautifulSoap模块进行爬取。
2.2 算法选择与描述
基于协同过滤方法的推荐系统是最早被提出且已被广泛应用的推荐系统。这种系统最大的优点是对推荐对象没有特殊的要求,能够处理难以用文本结构进行表示的对象,如音乐,电影等。协同过滤算法的原理是根据已有的用户行为信息,计算出物品或用户之间的相似度,基于相似度去预测某用户对某物品的评分或者感兴趣程度,然后依据预测的结果来决定是否向用户推荐该物品[6]。由于协同过滤算法能够处理图书这样的非文本结构对象,实现方法简明易理解,效果较好,且很容易同时给出推荐依据(这是非常重要的一点,如果不给出推荐理由,用户就无法信任推荐结果),在本系统中,我选择了这个算法。
协同过滤算法又可以分为基于用户的协同过滤算法和基于物品的协同过滤算法,基于用户的协同过滤算法由于其在准确度和稀疏性上的欠缺性,其实用性远没有基于物品的协同过滤要好,故我选择的是基于物品的协同过滤算法。基于物品的协同过滤,就是根据用户对不同物品的行为集合来计算物品之间的相似性,然后基于物品之间的相似性矩阵得到用户对每本图书的兴趣值或可能评分,根据这些预测结果进行推荐。简单总结就是:给用户推荐和他之前喜欢的物品相似的物品[7](这种相似性并不是指物品实际属性的相似性,而是作用于其上的用户行为的相似性)。
对于基于物品的协同过滤算法的逻辑解释和具体实现方法,我参考的是项亮的《推荐系统实战》。我找了非常多的关于该算法的视频和文章,但只有《推荐系统实战》中给出了从原理解释,步骤分析到伪代码实现的完整流程。通过仔细研读,我发现这个算法不仅能给出推荐解释,其思路亦有理可循,清晰易懂(有很多算法,如隐语义模型,虽然实现的效果尚可,但实现过程实在让人难以理解和信服)。
基于物品的协同过滤算法的第一步是要计算物品与物品之间的相似度矩阵。物品i和j之间的相似度wij定义如下:
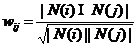 (2.1)
(2.1)
在公式(2.1)中,N(i)表示喜欢物品i的用户数量,N(j)表示喜欢物品j的用户数量,|N(i)∩N(j)|为同时喜欢物品i和物品j的用户数。
得到物品之间的相似度矩阵后,第二步是计算每位用户对于每本图书的兴趣值,用户u对物品j的兴趣值计算方式如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: