面向市场问卷调研的英文短文本相似度计算方法研究开题报告
2020-04-10 16:00:22
1. 研究目的与意义(文献综述)
背景资料:
随着互联网应用的快速发展与变革,使得互联网上每天产生的数据量难以估计,并且互联网产生的数据多数是以文本形式或者最终会呈现为文本形式存在,比如twitter和facebook等社交媒体每天产生的大量新数据,比如google每天产生的大量搜索日志,比如一些服务性问答系统的问答日志,这些数据以每天tb量级的增长着,而在大量的文本中,短文本的数量尤为庞大。研究表明,每天数十亿的的推文会在社交网络上公开发布,几乎每一条推文的字数都有至多三十个单词构成[1]。短文本比长文本更能体现人们的思想,消费倾向,情绪等信息。这些短文本涉及着人们生活的各个领域,也逐渐成为人们广泛使用并且公认的交流方式,并且它也改变着人们的生活和沟通习惯。从这些数量庞大的短文本中挖掘其中所蕴含的潜在资源可以方便对它们进行管理、同时也可以用于信息的发现和分析。但是面对如此海量的短文本,人们很难快速的通过人工的办法来获取其中所蕴含的信息资源,所以利用计算机技术来对短文本进行挖掘和分析具有重要的意义。文本聚类是自然语言处理中最基础的技术,采用聚类技术对这些短文本进行分析和组织,能够挖掘文本内部文字之间的联系,进而有助于对这些信息的整体认识和管理。但是对于短文本来说,短文本本身和长文本不一样,它具有独特的特征,如字数少,表达简洁、缺乏丰富的上下文信息,包含的信息量有限,这使得短文本的特征稀疏,很难准确的抽取有效的文档特征,加之传统的文本聚类方法直接在短文本上使用的效果不佳,因此,这对短文本的聚类研究带来了更多的挑战,同时也导致短文本聚类技术的发展相对缓慢。目前,针对短文本的文本聚类的困难基本上有:如何解决短文本的特征稀疏问题,如何改善短文本聚类的质量、以及如何描述聚簇结果[2]。
目的和意义:
2. 研究的基本内容与方案
基本内容与目标:
1)通过阅读相关文献,理解词语相似度、句子相似度、文本相似度、语义的相关概念与计算方法;
2)基于实用性,针对短文本的特点,从词语、句子出发,设计基于语义的短文本相似度计算方法,并利用尼尔森公司英文问卷调研数据,测试其匹配率。
3)基于以上研究成果,实现尼尔森公司英文问卷调研中开放题的自动处理。
技术方案及措施:
大体上分为四个步骤:
1)数据预处理
① 拼写检查更正
② 词形还原
③ 去停用词
2)相似特征度量
参考文献[11,15],决定采用基于语义词典的方法来进行相似度度量。本次设计的做法是将短文本分解成一系列的词,然后基于语义词典计算词与词之间的语义相似度,最后将词与词的语义相似度综合起来得到文本与文本的语义相似度。其中,语义词典起到了十分重要的作用,只有通过它,词与词之间的语义相似度才能够得以计算。
语义词典和一般的词典不同:一般的词典只包含了词以及相应的解释,而语义词典不仅包含了这些内容,还包含了词之间的关系。WordNet(是最流行的英文语义词典,它也可以被看作是一个关于自然语言词条的一个本体。它包含了约10 万个词条,每个词条与一个或多个意思(一词多义)相对应。这次词条自顶而下被组织成分层的树状结构,靠近顶端的词条表示较广泛的概念,较底层次的词条表示较细致的概念。WordNet 主要包含了名词、动词、形容词和副词这4 大类词,词与词之间通过不同的关系相联系。其中最常用的关系是“是什么”关系和“整体-部分”关系。例如,“燕子”和“鸟”属于“是什么”关系,因为燕子是一种鸟;“轮胎”和“汽车”属于“整体-部分”关系,因为轮胎是汽车的一部分。通过这样的一些关系,词与词被联系了起来,不再是孤立的了。[11]
语义词典可以帮助我们计算词与词之间的语义相似度。在WordNet 里面,由于所有的词都被自顶向下组织成了一个树状的结构,所以任意一个词都可以通过树中的某一条路径到达另一个词。一个词跟另一个词的关系可以通过它们之间的路径长度和它们各自的深度信息反映出来。从路径长度方面来看,一个词与另一个词之间的路径越短,那么它们的之间的联系就越紧密,它们的相似度也就越大;反之则越小。从深度方面来看,一个词的深度越大,它所代表的概念就越具体,那么在计算相似度时它的权重就越大;一个词的深度越小,它所代表的概念就越抽象,在计算相似度时的权重也就越小。
本次研究结合词深度和两个词之间最短路径的方法来计算两个词之间的语义相似度。用两个词或概念之间的最短路径来计算相似度的方法的公式为:
![]()
其中,D 表示WordNet 中词的最大深度,length 表示两个词之间的路径长度。用词或概念深度来计算两个词或概念之间的语义相似度的公式为:
![]()
其中,LCS 表示待计算两个词或概念的最小公共祖先节点。将上述两个公式加权得到最终的词之间的语义相似度。有了词之间的语义相似度,我们就可以用它来计算短文本的语义相似度,采取结合待计算的两个短文本(假设为T1 和T2)所包含的词之间的相似度来计算文本的相似度的方法。首先,对于T1 中的的每个词,找出T2 中与之最相似的词,并计算两者之间的相似度;同样对于T2 中的每个词,找出T1中与之最相似的词,计算两者之间的相似度。然后,再把这些词对相似度通过加权、规格化并进行平均得到T1 和T2 之间的相似度。
3)应用
利用以上工作所得的短文本语义相似度计算方法,实现尼尔森公司问卷调研中开放题的自动处理。大概的处理流程如下:用尼尔森公司问卷调研数据作为测试数据,尼尔森公司的调研数据包括问卷中的用户回答和作为被匹配项的短文本,在进行开放题的自动匹配过程中,分别计算每一个用户的回答与被匹配短文本之间的相似度,并设置一定的阈值,使得能将每一个用户回答匹配到相对应的几个被匹配项中。
4)性能评估
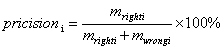 |
在性能评估上,借用分类技术中常用的准确率和召回率及F值来进行评估,设![]() 是正确分到类别
是正确分到类别![]() 中的文本的数量,
中的文本的数量,![]() 是其它类别中的文本被错误的分到类别
是其它类别中的文本被错误的分到类别![]() 中的文本的数量,
中的文本的数量,![]() 是类别
是类别![]() 中实际含有的文本的数量。则类别
中实际含有的文本的数量。则类别![]() 的准确率公式为
的准确率公式为
| |
类别![]() 的召回率公式为
的召回率公式为
采用所有类别的平均准确率(用precision 表示)、平均召回率(用recall表示)和F值作为分类效果优劣的评价指标。
并对比一下其它的相似度计算方法,例如:余弦相似算法关键词重叠算法等的分类效果,以验证该方法的效果。
3. 研究计划与安排
1. 2016/1/11—2018/1/22:查阅参考文献,明确选题;
2. 2016/1/23—2018/3/7:进一步阅读文献,并分析和总结;确定技术路线,完成并提交开题报告;
3. 2018/3/8—2018/4/26:需求分析,算法或系统设计,分析、比较或实现等;
4. 参考文献(12篇以上)
[1] c. de boom, s. van canneyt, s. bohez, t. demeester and b. dhoedt, learning semantic similarity for very short texts,2015 ieee international conference on data mining workshop (icdmw), atlantic city, nj, 2015, pp. 1229-1234.doi: 10.1109/icdmw.2015.86
[2] bouaziz a, dartiguespallez c, pereira c d c, et al. short text classification using semantic random forest[j]. lecture notes in computer science, 2016, 8646:288-299.
[3] yan x, guo j, lan y, et al. a biterm topic model for short texts[j]. 2013:1445-1456.



