面向市场问卷调研的英文短文本相似度计算方法研究毕业论文
2020-04-04 10:49:35
摘 要
随着计算机技术和互联网应用的快速发展,大量以文本形式呈现的数据充斥着网络平台,如何挖掘文本中的有用信息,成为计算机领域亟需解决的问题, 因此,如何利用计算机自动化挖掘出短文本中有用的信息已成为自然语言处理乃至机器学习领域研究的难点和热点。短文本的相似度计算是自然语言处理中一个重要任务,它既可以当成一个单独任务,又可以作为其它自然语言处理应用的基础。
针对以上问题,本文在研究和总结前人工作的基础上,完成如下工作:
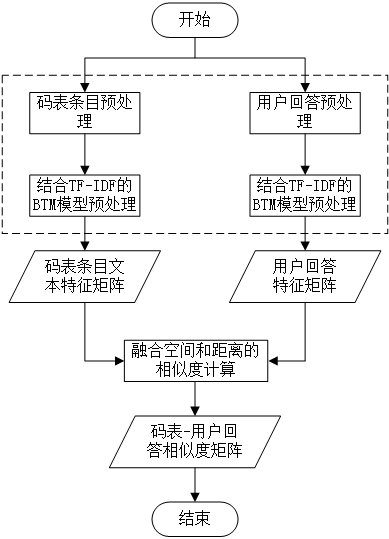
1、提出了结合TF-IDF算法与BTM模型的短文本特征提取方法。该方法通过TF-IDF算法计算文本中词的频率特征,利用文本词频率特征与BTM模型提取的语义特征相混合,进而得到综合考虑频率与语义的文本特征。利用文本的频率特征对语义特征进行补充,强化文本的特征项、弱化噪声。实验结果表明,该方法具有有效性。
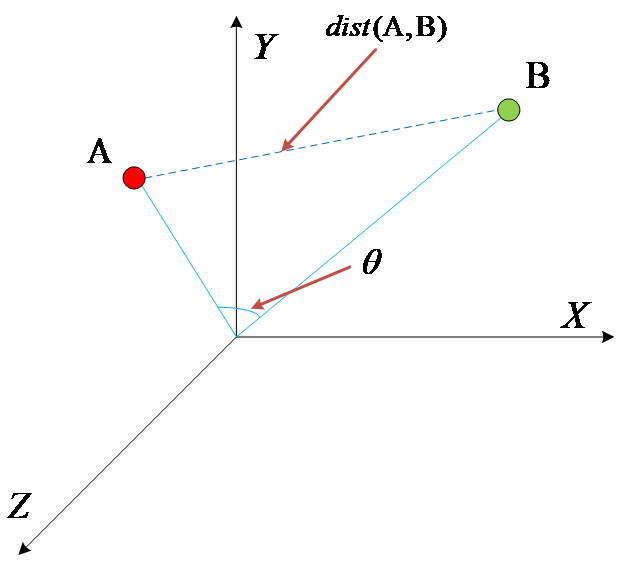
2、在相似度计算方法中,余弦相似度度量向量在方向上的差异,欧氏距离度量向量在距离上的差异,两者都有不足之处。本文提出了一种混合余弦相似度和欧式距离相似度的计算方法,综合考虑空间和距离两方面的差异,取得较好结果。
3、针对某著名市场研究公司问卷调查数据的短文本化特点,将以上研究成果进行应用,设计并实现了该公司人工智能编码平台中的自动编码功能,实现了市场调研数据的自动化处理,实际应用结果证明了该方法的实用性。
关键词:短文本;语义相似度;TF-IDF算法;BTM模型;混合相似度计算;
Abstract
With the rapid development of computer technology and Internet applications, a large number of data presented in the form of text full of network platform, mining the useful information of text has become an urgent problem of the computer industry, so how to make use of computer to dig out the useful information in short texts has become a difficult and hot research in the field of Natural Language Processing and machine learning. Short text similarity calculation is an important task in Natural Language Processing, it not only can be used as a separate task, but also can be used as the basis for other Natural Language Processing applications. To solve these problems, in this article summarizes the basic research and previous work on the completion of the following work:
1. In this article,one model which combine BTM and TF-IDF is proposed to extract features for short text.TF-IDF calculates the frequency characteristics of the words in the text and BTM captures the semantic features of the text. This article uses the frequency features of the text to supplement the semantic features, strengthen the features of the text, and weaken the noise. Experimental results show that this method has the effectiveness;
2. Cosine similarity reflects the difference in direction, euclidean metric reflects the numerical differences, both have shortcomings. This article combines Cosine similarity and euclidean metric to get a new method that comprehensively consider the difference between direction and value. This method achieves better results.
3. Aiming at the characteristics of the short text of the questionnaire survey data of a famous market research company, the above research results were applied, and the automatic coding subsystem is designed and implemented based on the above research results. The actual application results prove the practicability of the method.
Keywords: Short text; semantic similarity; TF-IDF; BTM; Mixed similarity calculation
目录
摘 要
Abstract
第1章 绪论 1
1.1 研究背景及意义 1
1.1.1 研究意义 1
1.1.2 研究背景 1
1.2 国内外研究现状 2
1.3 本文研究内容 3
1.4 本文组织结构 4
第2章 结合TF-IDF的BTM模型优化方法研究 5
2.1 相关技术 5
2.1.1 空间向量模型 5
2.1.2 TF-IDF算法 5
2.1.3 BTM主题模型 6
2.2 市场调研数据特点分析 7
2.3 结合TF-IDF的BTM优化模型构建 8
2.3.1 基于TF-IDF的频率特征权重计算算法 9
2.3.2 语义特征的提取 9
2.3.3 获取特征矩阵 11
2.4 本章小结 12
第3章 英文短文本相似度计算方法及实验验证 14
3.1 相似度计算方法概述 14
3.2 改进的余弦相似度和标准化欧式距离 15
3.3 融合空间和距离的短文本相似度计算方法 16
3.4 实验验证及分析 16
3.4.1 实验平台及实验数据 16
3.4.2 实验结果评价指标 18
3.4.3 实验方案 18
3.5 本章小结 22
第4章 面向市场调研的英文短文本相似度计算方法应用 24
4.1 应用背景与需求分析 24
4.2 面向市场调研的英文短文本相似度计算方法应用设计 25
4.2.1 总体功能结构 25
4.2.2 功能模块设计 26
4.2.3 数据库设计 28
4.3 面向市场调研的英文短文本相似度计算方法应用实现 29
4.3.1 环境配置 29
4.3.2 系统实现 30
4.4 应用结果与分析 32
4.4.1 应用结果 32
4.4.2 结果分析 33
4.5 本章小结 34
第5章 总结及展望 35
5.1 主要工作 35
5.2 下一步工作 35
参考文献 36
致 谢 38
绪论
研究背景及意义
研究意义
近年来,SNS、Facebook、微博等交互式网站的快速发展使得用户可以自由编辑这些网站的内容,这些编辑的内容通常是以短文本的形式存在,比如社交网站的评论、电子商务网站的用户反馈信息等等[1]。研究表明,每天数十亿的的推文会在社交网络上公开发布,几乎每一条推文的字数都有至多三十个单词构成[2]。相较于长文本,短文本更加频繁地出现在互联网时代的人们的沟通交流之中。短文本相较于长文本,更好体现了用户的思想、喜好、情绪等信息。面对海量的短文本数据如何获取其背后的潜在信息,进而提高产品用户体验,成为当前文本挖掘的重要问题。
文本相似度计算是自然语言处理应用的重要方向之一,采用相似度计算能够挖掘文本潜在信息,有助于对这些文本信息的整体认识和管理。但是对于短文本来说, 短文本不仅长度短、信息含量少,而且数量庞大,导致提取的短文本特征具有比较严重的空间高维性和数据稀疏性的特点,这使得短文本很难准确的抽取有效的文档特征。短文本数据中通常包含着明显的个人感情色彩或个人意图,因此极易在当前短文本的主题中生成新的主题,产生主题交叉或漂移现象,从而导致机器对短文本主题的错误理解。基于上述观点短文本的相似度计算研究存在极大的挑战。
研究背景
语义相似度计算在诸多领域有着广泛的应用。本文研究的重点在短文本的语义相似度,以下分述短文本相似度计算在不同应用场景下的研究意义:
(1)机器翻译
翻译是突破语言障碍的重要方式,已经成为生产活动中一项重要的工具。传统翻译手段是利用人工进行返利,虽然可以提供高质量的翻译结果,但是人工翻译效率低下且成本高昂,无法满足大量的需求。随着自然语言处理技术的发展,机器翻译逐渐成为翻译领域一项重要的工具。文本相似度计算研究可以有效提高机器翻译的准确度。
(2)自动问答系统
自动问答系统通过对用户问题的语义理解,为用户提供精确的回答。问答系统不同于搜索引擎,会根据用户回答返回精确的回答,能给更好的表达用户的信息需求,因此在特定场景下,问答系统比搜索引擎更加便捷、高效。目前最常见一种是基于常用问题集(FAQ)知识库的自动问答系统。文本相似度是FAQ自动问答系统的核心[3]。
(3)文本分类和聚类
面对海量的信息,如何快速有效提取这些信息中潜在的有价值信息是当今信息科学与技术领域面临的一大难题。文本分类是处理大量文本的关键性技术,能够有效地解决信息杂乱现象。文本分类是在确定的分类体系下,为整个数据集中的每个文档确定一个类别。文本分类是文本数据挖掘的重要组成部分,在信息检索、信息过滤、数字化图书馆等领域有着广泛的应用前景。在文本分类的实现过程中,文本间相似度是文本分类的重要依据。
(4)情感分析
情感分析又称为倾向性分析或意见挖掘,是对带有情感色彩的主管性文本进行分析、处理、归纳和推理的过程,其中情感分析还可以细分为情感极性(倾向)分析,情感程度分析,主客观分析等。通过分析文本相似度来归纳评价文本所具有的感情色彩,将大量的文本数据转化为用户情感倾向,进一步帮助用户进行决策等应用。
国内外研究现状
目前语义相似度计算主要为两大类方法:基于知识库词典的方法和基于大规模语料库的方法[3]。基于知识库词典的方法利用现有知识库中词之间的层次关系,通过计算两者之间的距离作为相似度;基于大规模语料库的方法是通过利用统计的方法对大规模的语料库进行训练获取特征项,再利用词向量之间的距离来进行相似度的计算。
自1985年开始,普林斯顿大学的部分学者开始进行一部基于认知语言学的词典数据库的开发,该词典数据库就是WordNet。WordNet不同于传统意义上的词典,它根据词条的意义将其分组,每个具有相同意义的词条被称为一个同义词集合[12]。在WordNet中,名词、动词、形容词、副词和虚词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且集合之间也通过各种关系连接。同义词集合为自顶向下的树状结构,越靠近根结点的词包含的意义越宽泛。相似的数据库还有很多不同语言的版本,适用于中文的版本有HowNet,不同于WordNet,HowNet是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库[4]。一般基于知识库的语义相似度计算方法实质上是依据知识库词典中词与词之间的路径长度或关联程度进行对文本进行分析。
基于语料库的语义相似度计算模型一般是通过大规模的语料库,运用统计方法计算语义相似度。计算方法通常基于假设:如果词语的意义相近,他们的上下文也应该相似。因此模型借助于大规模的文本语料,参考输入单词的上下文串口文本作为该单词相似度计算的依据,利用统计学的方法对词语的相似性进行科学的数学计算。在基于语料库的语义近似度计算方法中,Salton提出的向量空间模型对后来的研究起到了重要的作用,通过一下假设对模型进行简化:一个文档可以看着一组单词构成的集合,不考虑其中语法及词序关系,每个词语都是相互独立的[21]。向量空间模型依据文本所包含的词语,用统计学的方法将文本转换为向量之后就可以通过余弦相似度或者欧式距离表示两者的相似度。在实际应用过程中,向量空间模型因为具有超高纬度、特征冗余等特点,且其关于词与词之间相互独立的假设在实际情况中很难满足,所以会对计算的结果有影响。在向量空间模型的基础上,为了解决上述问题,研究者也提出了多种改进方案[22]。S.T. Dumais等提出的潜在语义分析(Latent Semantic Analysis,LSA)模型使用统计计算的方法对大量的文本进行分析,提出词与词之间潜在的语义结构,并用这种潜在的语义结构表示文本,将系数的高维词汇空间映射到低维的向量空间,消除词之间的相关性并简化文本[23]。
主题模型(TM)领域,潜在狄利克雷分布(LDA)通过引入潜在主题层的方式省略了潜在语义分布(LSA)中复杂的奇异值分解(SVD)计算过程,同时通过引入两个狄利克雷(Dirichlet)分布的超参的方式解决了概率潜在语义分析(PLSA)中必须确定文本编号才能进行随机抽样的缺点[24]。因此,LDA模型参数空间的规模与文本集合的大小无关,不会因为语料库的增大而产生过拟合的问题,目前在长文本领域中已经得到非常广泛的应用。BTM相比于LDA模型,利用词共现模式加强主题模型的学习,从而能够更深层次地获取短文本的特征[5]。
深度学习方面,Bengio等人在2001年提出了神经网络语言模型(NNLM) [6],该模型利用四层的神经网络对文本进行建模,并通过给定的上下文环境预测当前词语生成的概率。Hinton等人根据NNLM提出了受限玻耳兹曼机(RBM) [7],该网络是一种二层神经网络,其隐藏层节点与可见层节点全连接,相同层的节点之间彼此独立。Socher等人使用递归神经网络(RNN)构建了一种结构化的预测模型[8],该模型可以有效地分析文本的语句结构,在特征提取上为神经网络与自然语言处理的结合提供了一种新思路。Mikolov等人通过改进循环神经网络(Recurrent neural network,RNN)提了的循环神经网络语言模型(Recurrent neural network based language model,RNNLM)[9],在此基础上Google于2013年末发布了基于深度学习方法打造的Word2Vec工具[9]。Word2Vec共有两种模型:CBOW模型(Continuous Bag-of-Words Model)和Skip-Gram模型(Continuous Skip-Gram Model),两者都属于神经网络概率模型,通过学习训练语料来获取词向量和概率密度函数[15]。
本文研究内容
本文针对短文本数据,主要从特征提取和相似度计算方法两方面进行研究,提出适合短文相似度计算的改进模型。
本文主要工作如下:
1)完成了对文本集的预处理:包括对文本集中的文本去停用词、去低频单词、拼写纠错、词形还原等操作。
3)针对基本的BTM模型进行了拓展,将传统的IF-IDF方法与BTM模型相结合。以TF-IDF得出的特征矩阵作为BTM模型获取特征矩阵的权重,起到增强文本特征,弱化噪声的效果。
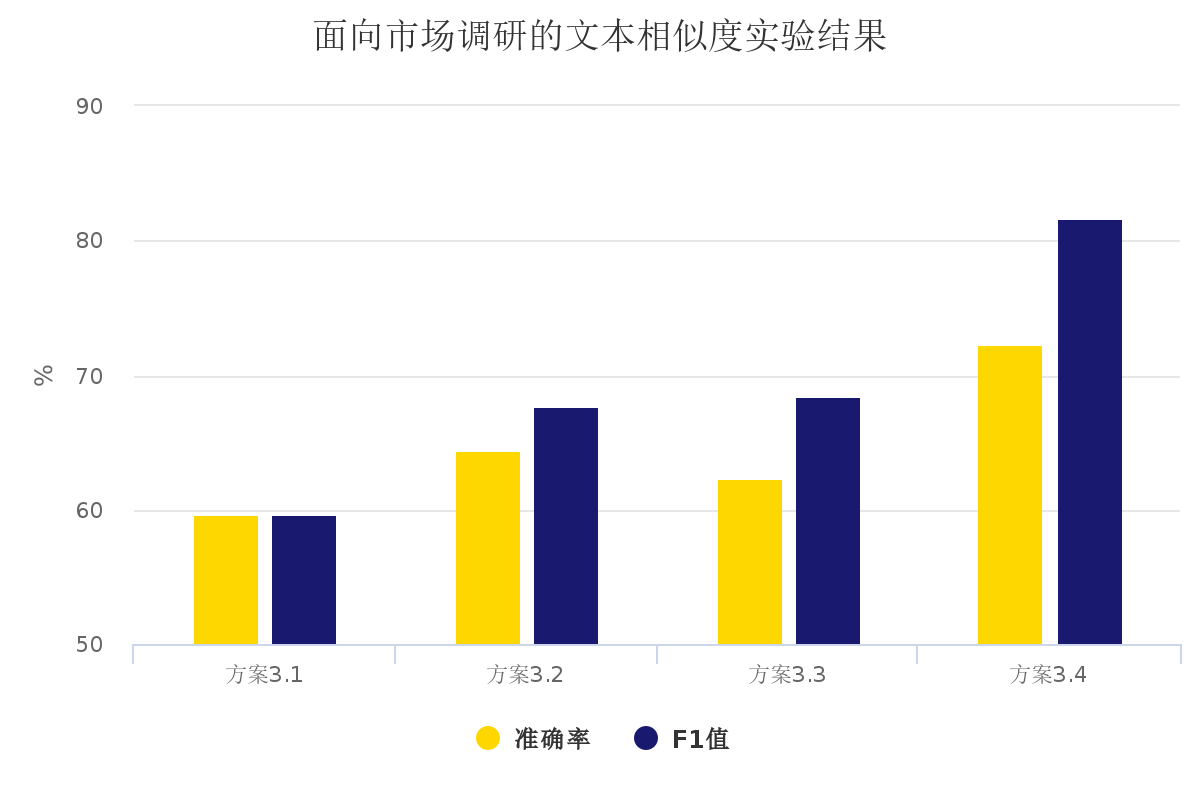
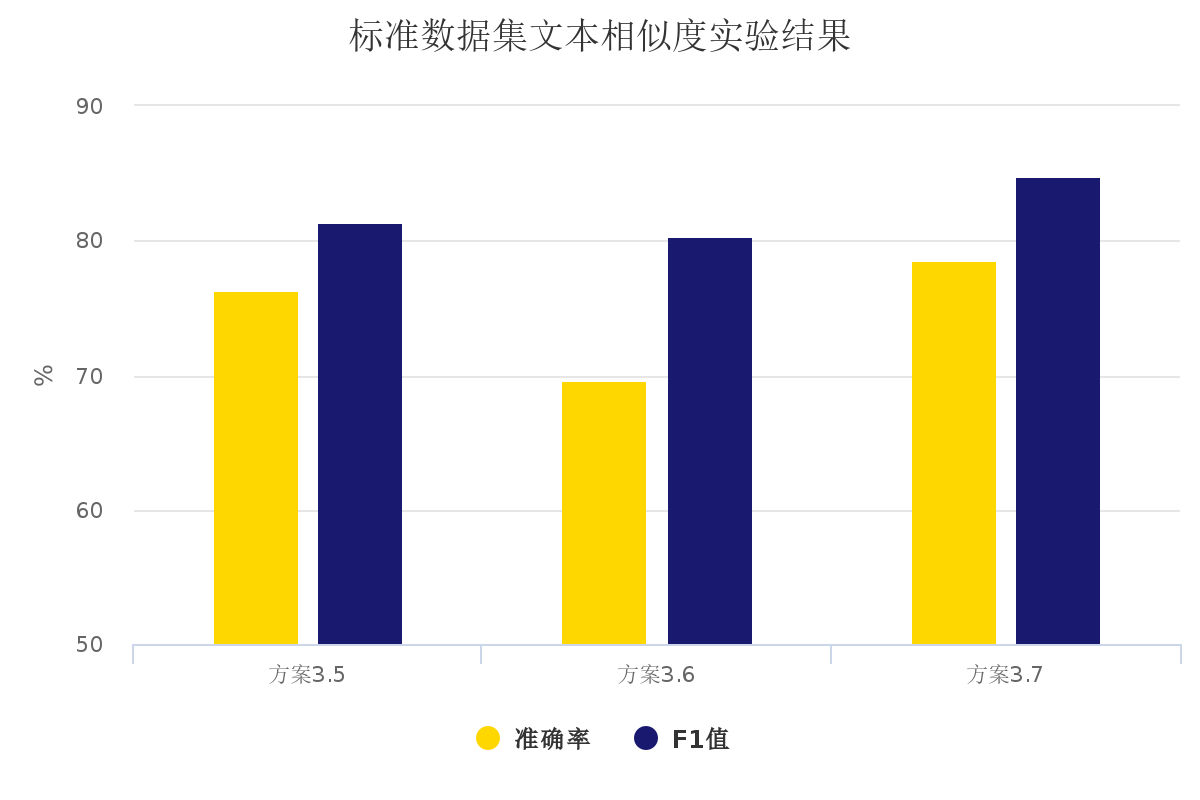
2)相似度计算方法的比较分析与改进:本文比较了余弦相似度算法和欧氏距离相似度的区别与不足之处,提出了一种融合空间和距离的相似度计算算法,并分别使用了余弦相似度算法、欧式距离相似度和本文提出的混合算法进行实验分析,结果表明本文提出的混合算法优于余弦相似度、欧氏距离相似度计算算法。
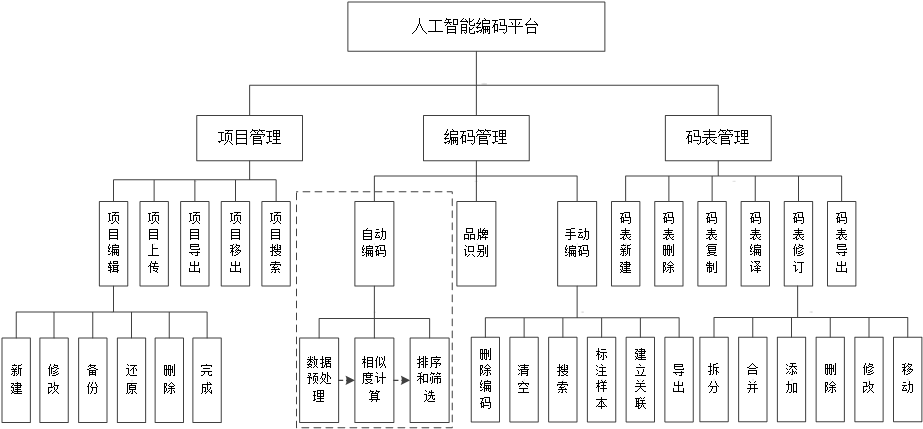
4)结合实际应用,将本文研究成果应用到某知名市场研究公司开发的“人工智能编码平台”中,获得良好效果。
本文组织结构
本论文总共分为五章,具体章节安排如下:
第一章为绪论部分,本章简单介绍计算机自动化处理短文本信息的研究背景及意义,总结文本特征提取、融合和相似度计算等方面的国内外研究现状,对其中存在的问题进行分析并给出相应的解决方案,阐述本文的主要研究内容和论文组织结构。
第二章介绍了本文所需相关技术——空间向量模型、TF-IDF算法、BTM主题模型,并介绍了本文所针对市场调研数据的相关特点。重点说明了本文所提出的结合TF-IDF的BTM优化模型的特征提取方法。
第三章介绍了两种传统的相似度计算方法——余弦相似度和欧式距离相似度计算方法,分析了两种相似度方法的不足,针对两种方法做出改进。在改进后的余弦相似度和欧氏距离相似度的基础上提出了一种融合空间和距离的相似度计算方法。在本章节中,结合第二章提出的特征提取方法和本章提出的相似度计算方法设计了相关实验,并分析了实验结果。
第四章是本文所提出相似度计算方法的集成应用。本章首先简要介绍了应用系统的相关背景,然后详细介绍了本文算法在该系统中完成的功能,并给出了应用的结果。
第五章总结了本文的主要内容,提出了研究的不足及下一步工作方向。
结合TF-IDF的BTM模型优化方法研究
相关技术
空间向量模型
Salton等人于1960提出了一种文本建模的方法——空间向量模型(VSM:Vector Space Model),并成功地应用于著名的SMART文本检索系统[10]。向量空间模型可以将文本信息转化为空间向量进行表示,并通过计算向量的距离来表示文本的相似度。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: