在线购买行为预测的研究毕业论文
2020-04-01 11:01:48
摘 要
随着科技的进步和移动互联网的完善普及,移动电商业务进入飞速发展阶段,移动信息数据急速增长,导致出现信息过载等问题。在竞争激烈的电子商务市场中,各大电商都在探求产品促销的精准定位方案,以达到增加用户粘合度、提升网站竞争力的目的。而个性化推荐系统,通过对在线购买行为预测的研究能够有效解决在电子商务中出现的信息过载等问题。本课题基于2017年天池比赛中提供的2万用户在购物中的完整行为数据以及用户操作的商品信息,从中提取有效的特征数据,探索建立用户对商品及品牌喜好的有效方法,以对用户进行商品购买行为进行预测。通过对原始数据的清洗、过滤以及对用户行为的时间特性进行分析,从中提取了用户特征、商品特征、商品类别特征、用户-商品特征和用户-商品类别特征等5种有效的特征;并构建了XGBOOST机器学习分类模型,对特征进行筛选、对XGBOOST模型参数进行优化,最终对用户的购买行为的预测。并在天池中取得10.28% 的F1成绩和0.09正确率,在参赛的8534个选手中排名33。
关键词:大数据;用户行为预测;特征工程;推荐系统
Abstract
With the advancement of technology and the popularity of the mobile Internet, the mobile e-commerce business has entered a stage of rapid development. The rapid growth of mobile information data has led to problems such as information overload. In the highly competitive e-commerce market, major e-commerce companies are exploring precise solutions for product promotions in order to increase the degree of user-friendliness and enhance the competitiveness of websites. The personalized recommendation system can effectively solve the problem of information overload and other problems in e-commerce by the research on online purchase behavior prediction. This paper is based on the 20,000 users' complete behavior data and millions of product information provided in the 2017 Tianchi Championship, extracts valid feature data, and explores how to establish effective methods for product and brand preferences of the users so as to forecasting commodity purchasing behavior statistical analysis was performed on the user's purchase behavior data, and features such as user characteristics, product characteristics, product category characteristics, user-merchandise characteristics, and user-product category characteristics were extracted, and XGBOOST machine learning was constructed. A classification model to predict the purchase behavior of a product based on the user's product preferences.
Key Words:Big Data; User behavior prediction; Feature Engineering; Recommended system
目 录
第1章 绪论 1
1.1 课题背景 1
1.2 课题研究的目的及意义 2
1.3 国内外研究现状 2
1.4 课题研究内容及预期目标 3
1.4.1 课题研究内容 3
1.4.2 预期目标 3
1.5 论文结构 3
第2章 数据集 4
2.1 背景和原始数据介绍 4
2.2 原始数据处理 6
2.2.1 用户行为数据清洗 6
2.2.2 商品信息数据清洗 8
2.2.3 用户行为的时间特性分析 8
第3章 特征工程 11
3.1 样本划分 11
3.2 用户特征 11
3.3 商品特征 13
3.4 商品类别特征 14
3.5 用户-商品特征 15
3.6 用户-商品类别特征 16
3.7 训练集构建 17
3.8 测试集构建 17
第4章 基于多特征的用户购买行为预测模型 18
4.1 预测 18
4.2 常用的预测模型分析 18
4.3 模型介绍 18
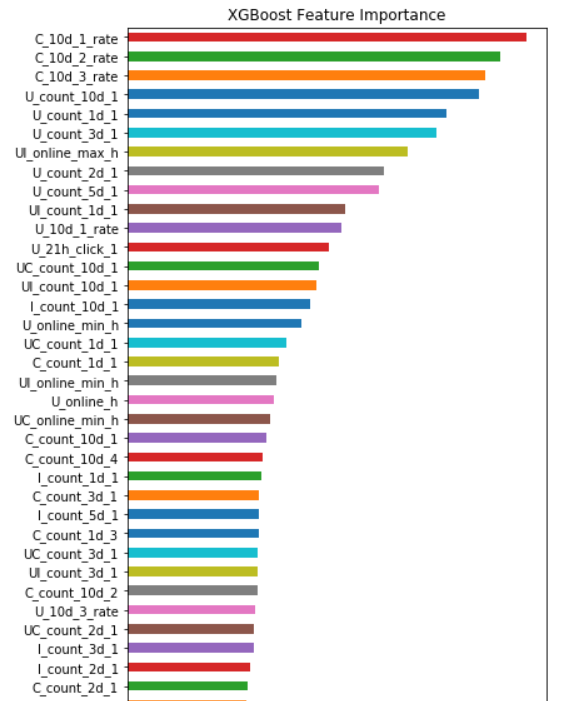
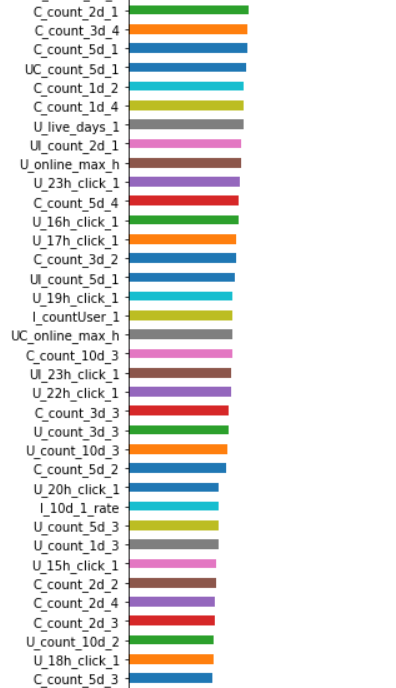
4.4 多特征选取 19
4.5 模型参数调优 21
4.5.1 通用参数 21
4.5.2 booster参数 21
4.5.3 学习目标参数 21
第5章 实验及结果评估 23
5.1 实验目的 23
5.2 实验平台搭建 23
5.3 实验设计 23
5.4 评估方法 25
5.5 研究结果 25
第6章 结论及展望 26
6.1 工作总结 26
6.2 工作展望 26
致谢 27
参考文献 28
绪论
课题背景
随着移动设备的高度普及和完善,移动互联网 的到来使得各行各业都进入了高速发展的历史时期,截至2017年12月,我国网民规模达7.72亿,普及率达到55.8%,超过全球平均水平(51.7%)4.1个百分点,超过亚洲平均水平(46.7%)9.1个百分点[1],其中移动电子商务更是发展迅猛,并且保持着巨大的发展潜力。2017年电子商务、网络游戏、网络广告收入水平增速均在20%以上,发展势头良好,其中,1-11月电子商务平台收入2188亿元,同比增长高达43.4%[1]。然而,面对购物网站提供的过多商品,用户容易产生购物疲劳,也就是信息过载[2]。除了信息过载问题导致用户产生疲劳外,用户花费了大量的时间精力和金钱,却无法从这些过载的信息数据中获取到自己真实想要的信息,降低了效率。
对于信息过载问题以及所导致的效率低下的现象,目前主要通过两种方式解决,即通过主动拉取信息和被动接受信息推送。其中主动拉取信息的方式,现在主要表现在搜索引擎。用户通过搜索引擎搜索所需要的商品,可以过滤掉其他不相干的信息,但是还存在着同类商品种类仍然非常庞大,其次这种主要依靠用户的主动性,忽略了用户隐性的个性化需求,不能为用户提供更多用户可能需要的商品,不能给购物网站带来更多的收益。对于被动接受信息推送,主要表现在通过购物网站主动向用户推送用户可能需要的商品,与传统的通过搜索引擎的方式相比,减少了用户主动去搜索筛选的时间,提高了用户购物效率。推荐系统正是这种方式的重要实现。而筛选出用户可能需要的商品并不容易,如果不断推送一些用户不需要的信息,不仅影响用户使用体验,更加重了用户的购物效率问题。
因此,借助一些技术方案精准预测用户将要发生的购买行为,为用户对商品的购买决定或为购物网站商家的促销营销提供支持,已经成了当前电子商务所面临的重大问题,同时也是数据挖掘领域急需研究的内容。这对于改善用户的购物体验、提高购物网站商家的效益有着非常重要的意义。面临这些问题,比如协同过滤这些推荐技术[3]的发展,并且广泛的应用到各大电子商务网站的商品推荐系统中。这些推荐方案主要是分析用户购买的商品,然后根据这些信息分析,推荐给对应用户与之相似或者与之相关的商品[4]。但是,它们仅仅只关注孤立的购买商品,却忽略了这些购买操作与用户的其他行为(比如在购买前对商品的浏览、收藏、加入购物车等)之间的联系。因此,这些推荐方案一般能够预测出用户会购买哪一种商品,却不能准确预测出用户会购买哪个具体商品。因此,购买行为预测对提高购物网站收益有着重要的意义,如何使用用户购买商品前的各种行为操作来关联描述用户的购买意图,精准预测出用户对商品的购买行为操作是现在需要解决的核心问题。
课题研究的目的及意义
在移动设备高度普及和完善的今天,电子商务市场竞争更加激烈,各大厂商都在探求产品促销的精准定位方案,以达到增加用户粘合度、提升网站竞争力的目的。本课题拟从两万用户购物期间的完整行为数据和百万数量的商品信息,从中提取有效的特征数据并构建在线购买行为预测模型,为电商更精准的个性化推荐奠定基础。更形象的表述为,了解用户,根据用户的历史行为数据去主动预测用户的购买行为,提供更加贴心的服务,提高用户购买效率和用户的购买体验。
在线购买行为的预测,有利于电子商务中的智能推荐系统更加完善,并达到以下效果:
其一,解决了信息过载的问题,在这个严重信息过载的互联网时代,信息过载,不仅导致用户疲劳,而且筛选这些海量数据,浪费大量时间和精力。通过本课题,可以筛选掉大量不必要的信息,直接给用户提供最有效、最重要的信息。节省用户的时间,并提供了高质量的生活体验。
其二,提升了网站的竞争力。随着移动设备的高度普及,中国网民数量的急剧增加,电子商务营业额所占比例越来越多的情况下,众多电商平台间市场竞争激烈。如何增加用户的粘合度极为重要,影响到一个平台的发展与存活。通过本课题,能够给用户提供更加智能的服务,极大提高用户的购物体验,给用户带来方便,获得用户的好感。
其三,为电商带来更多的收益。在电子商务中,用户的购买量直接决定了电商的收益。通过本课题,能过预测到用户的购买行为,在预测到用户的购买行为后,向其推送此商品,直击用户购买欲望,提高用户购买成功率。
其四,能为电商提供产品促销的精准定位方案。通过本课题,在促销前已经预测出用户的购买行为,电商能过通过此结果,能够给用户提供更加个性化的促销方案。
国内外研究现状
国外学者对于信息过载问题做了大量的研究,其中电子商务成为了研究领域的主要对象,其中提出了许多模型来解决这一类问题,比如Pareto/NBD模型、BG/NBD模型、LSD模型等。其中Schmittlein、Morrison和Colombo提出的Pareto/NBD模型[5]可以说是用户购买行为最经典概率模型。同时在国外的很多网站为了解决信息过载问题,采用了很多方法,其中代表性的是雅虎和谷歌,他们分别使用了分类目录和搜索引擎[6]。个性化推荐在电子商务领域应用广泛,其中最为著名的是亚马逊,亚马逊的推荐系统,亚马逊有20%~30%的销售来自他们的推荐系统[6]。除了电子商务,个性化推荐还应用于电影和视屏网站,在国外较为出名的有Netflix网站、YouTube网站等。著名的个性化音乐网络电台Pandora。Vieria等人提出了一个强大的分类器,可以根据大型电子商务网站内的用户行为预测购买意图,他们比较了传统的机器学习技术和最先进的深度学习方法,展示了Deep Belief Networks和Stacked Denoising自动编码器在前期阶段通过从高维数据中提取特征实现了重大改进,这使处理严重的阶级失衡也更为方便[7]。
在国内像淘宝网、天猫网、京东网、知乎以及豆瓣,都有不同程度使用了个性化推荐。这些网站都会根据用户的历史数据,推荐一些其他信息。而在这方面的研究,许多学者也将统计和机器学习应用其中,来提高预测结果。比如雷名龙以阿里巴巴大数据竞赛作为研究,构造了随机森林、逻辑回归和SVM三种机器学习分类模型,对用户的购买行为进行预测,预测结果准确率超过了百分之五[8]。张春生等人研究了同类产品的推荐方案,他们通过主要针对商品名称、价格、购买人数、收货人数、用户评论进行数据建模[9]。还有马月坤和刘鹏飞,通过从购买的交易信息取得知识,并构建知识库,利用构建的知识库对用户的购买意愿进行分析和预测[10]。
课题研究内容及预期目标
课题研究内容
在竞争激烈的电子商务市场中,各大电商都在探求产品促销的精准定位方案,以达到增加用户粘合度、提升网站竞争力的目的,本课题利用数据挖掘和机器学习的理论及方法,以用户在电商平台的行为数据为基础,采用数据挖掘等相关算法,从商品特征、用户购买习惯等多维度建立购买行为预测模型。
预期目标
利用数据挖掘和机器学习领域的理论及方法,构建商品特征、用户特征、商品类等特征,利用XGBOOST构造分类模型,利用用户对商品的行为数据预测出用户是否购买商品。
论文结构
第1章主要介绍了论文选题的背景、课题的研究目标意义以及国内外对于相关内容的研究现状和本课题要研究的内容目标。第2章主要介绍课题研究的原始数据集,利用数据挖掘相关技术对原始数据进行分析、处理,包括用户行为数据清洗、商品信息数据清洗以及用户行为的时间特征分析。第3章主要对特征工程的介绍,其中包括对样本的划分、用户特征构建、商品特征构建、商品类别特征构建用户—商品特征以及用户—商品类别特征的构建。第4章主要介绍了基于第3章获得的多特征用户购买行为预测模型,介绍常用算法以及本课题使用的算法调优。第5章主要介绍了本课题最终的实验结果以及评估。第6章介绍了本课题得出的结论以及对课题的不足进行了总结和展望。
数据集
本课题的原始数据来源于由阿里云主办的“天池新人实战赛之[离线赛][11]。本章主要介绍本次比赛的题目要求、原始数据介绍以及对原始的数据处理,本课题所进行的特征工程和所使用的分类算法都依赖本章对数据的处理。
背景和原始数据介绍
竞赛背景:2014年是阿里巴巴电子商务业务(比如淘宝和天猫)飞速发展的一年,例如2014年的双11促销活动中移动端的成交数量占比达到42.6%,超过240亿元,而对比PC,移动端对网站的访问及操作是随时随地的,同时数据也更为丰富,比如用户操作时的地理位置、用户对网站操作的具体时间等,大赛提供了天猫平台的用户数据、商品数据和用户对商品的行为操作数据,同时提供了用户及商品的位置信息,要求参赛选手能够从这些数据中挖掘出其数据背后的丰富含义[11]。本次比赛的参赛对象主要是全日制高校、研究所的学生、老师和科研人员。
原始数据介绍:本数据集通过大赛官网下载,数据来源是电商提供的11月18日~12月18日内部分用户的所有行为真实数据。为了更方便介绍数据定义以下符号:
U——用户集合,
I——商品全集,
P——商品子集,,
D——用户对商品全集的行为数据集合[11]。
竞赛的目标是利用D中的行为数据来构造U中的用户对P中的商品的推荐模型。表2-1为用户的移动端行为数据D,表2-2为商品子集P。
大赛评估指标使用了精确度(precision)、召回率(recall)和F1值作为评估指标[11]:
(1)
(2)
(3)
大赛排行榜按照评测得分排序,显示排名选取历史最优的成绩展示。
表2-1 用户在商品全集上的移动端行为数据
名称 | 说明 | 含义 |
user_id | 用户id | 经过抽取和脱敏 |
item_id | 商品id | 经过脱敏 |
behavior_type | 操作行为类别 | 1:浏览、2:收藏、3:加购物车、4:购买 |
user_geohash | 用户位置信息,可以为空 | 加密经纬度得到 |
item_category | 商品类别 | 经过脱敏 |
time | 操作时间 | 以小时为最小单位 |
表2-2 商品子集
名称 | 说明 | 含义 |
item_id | 商品id | 经过抽取和脱敏 |
item_ geohash | 用户位置信息,可以为空 | 加密经纬度得到 |
item_category | 商品类别 | 经过脱敏 |
在行为数据中,包含了2万个用户、9557个商品类别、4758484个商品以及2329万多条行为操作记录。在比赛中,评分的数据是这些用户在一个月之后对商品的购买数据。通过这个月的行为数据,去预测一个月之后,用户对商品子集(P)中的购买行为。
原始数据处理
数据预处理即将未加工数据转换成适合分析的形式,包括多数据源的数据融合、数据清洗、维规约等等,数据预处理还没有很好的自动化工程化的方法,所以通常会耗费很多时间和精力,且需要加入人为经验的干预[12]。数据预处理技术可以提高数据挖掘以及预测的准确率,因此需要将比赛提供的原始数据进行预处理。本课题所完成的原始数据的预处理主要包括如下几个方面。
用户行为数据清洗
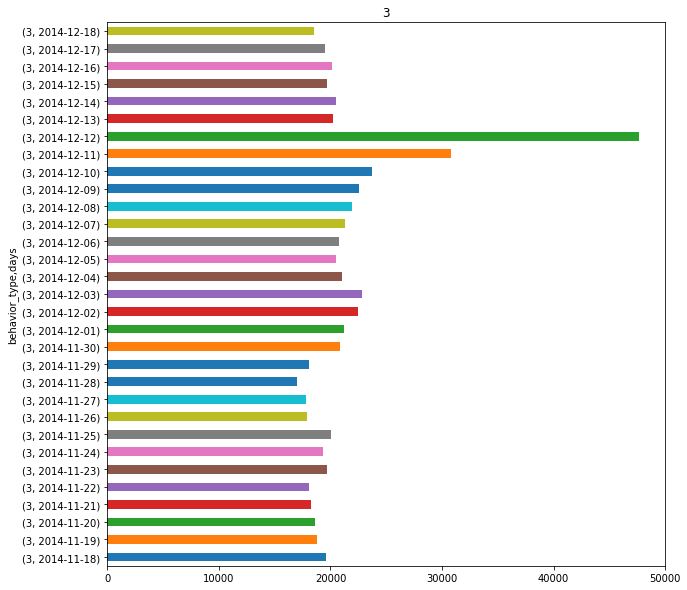
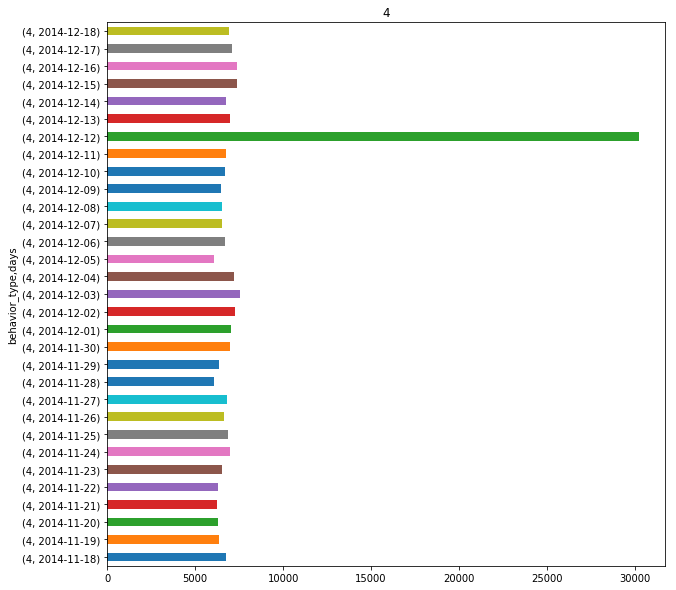
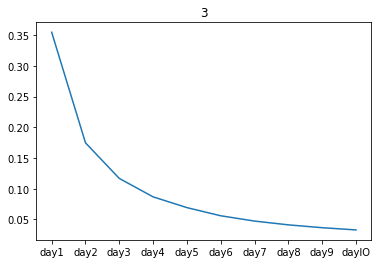
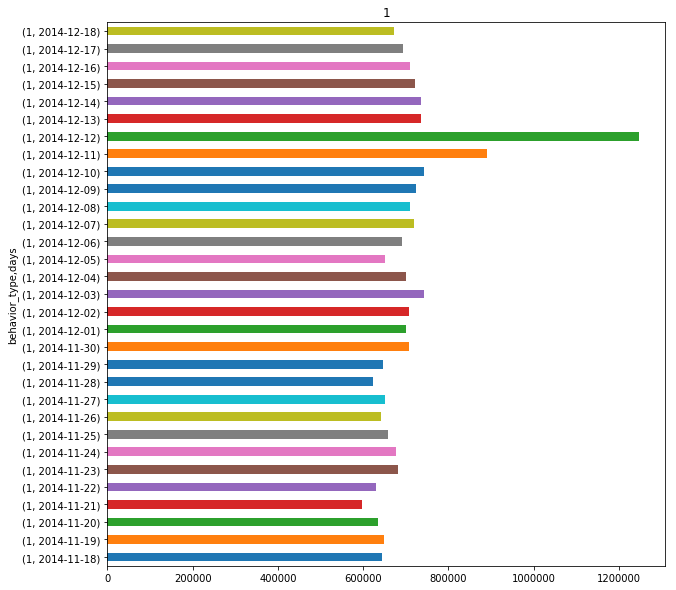
由于数据来源于阿里巴巴淘宝11月18日至12月18日的真实数据,其中包括了淘宝双十二活动,众所周知在12月12日这一天有大力促销活动。通常情况下,人们在促销节当天的购买会和平常不一样,图2-1~图2-4为所有用户的4种行为次数的统计结果。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: