Aproiri并行算法的应用研究毕业论文
2020-03-07 09:11:35
摘 要
Apriori算法是一种典型的数据挖掘算法,对于频繁项集的挖掘,主要通过连接步以及剪枝步实现。但在传统的Apriori算法,存在着以下两个重大的问题:(1)在频繁项集的计算过程中需要产生大量的候选项集;(2)需要重复地扫描数据库,每产生一次候选项集都需要扫描一次数据库。
论文主要研究了如何解决传统的Apriori算法存在的(2)问题,目的是通过减少扫描原始事务集数据库的次数,以达到提高算法运行的效率,从而实现处理大数据集的效果。
研究结果表明:与传统的Apriori算法相对比,基于MapReduce并行框架设计的MMR-Apriori不仅仅能够达到处理大数据的效果,而且可以提高并行化的Apriori算法的运行效率。
本文的特色在于:MMR-Apriori算法的优化设计通过产生的1-频繁项集,建立对应的1-频繁项集索引表,根据索引表建立事务压缩映射表。一方面可以达到压缩原始事务集数据库,另一方面通过建立的1-频繁项集索引表以及事务压缩映射表,大大减少了统计迭代产生的k-候选集中每个项目集出现频率的时间。
关键字: 频繁项集;MapReduce并行框架;MMR-Apriori;事务压缩映射表
Abstract
Apriori algorithm is a classical data mining algorithm. For the mining of frequent itemsets, it is mainly achieved through connecting and pruning step. However, in the traditional Apriori algorithm, there are two major problems: (1) A large number of candidate sets need to be generated during the calculation of frequent itemsets (2) The database needs to be scanned repeatedly, and each generation of a candidate itemset requires a database scan.
The thesis mainly studies how to solve second questions mentioned above of the traditional Apriori algorithm. The purpose is to improve the efficiency of the algorithm by reducing the number of times of scanning the original transaction set database, thus achieving the effect of processing large data sets.
The research results show that compared with the traditional Apriori algorithm, the MMR-Apriori based on the MapReduce parallel framework can not only achieve the effect of processing big data, but also improve the running efficiency of the parallelized Apriori algorithm.
The characteristic of this paper lies in: The optimal design of MMR-Apriori algorithm establishes the corresponding 1- frequent itemsets index table by the 1-frequent itemsets generated, and establishes the transaction compression mapping table according to the index table. On the one hand, the original transaction set database can be greatly compressed, and on the other hand, the 1-frequent itemsets index table and the transaction compression mapping table are established, which greatly reduces the statistical time of occurrence of each itemset in the k-candidate set generated by iteration.
KeyWords:frequent itemsets;MapReduce parallel framework;MMR-Apriori;transaction compression mapping table
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 研究的目的及意义 1
1.2.1 目的 1
1.2.2 意义 2
1.3 国内外研究现状 2
1.4 课题研究内容 3
1.5 论文结构安排 3
第2章 Apriori算法 5
2.1 Apriori算法的描述 5
2.1.1 求解频繁项集过程 5
2.1.2 求解频繁项集实现算法 6
2.2 Apriori算法的分析 6
第3章 并行框架分析与Hadoop集群的搭建 7
3.1 并行框架分析 7
3.1.1 各并行框架的性能对比 7
3.1.2 Hadoop MapReduce编程框架 8
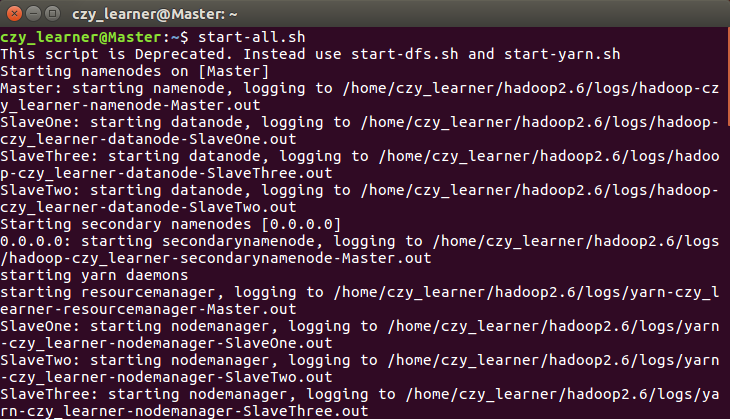
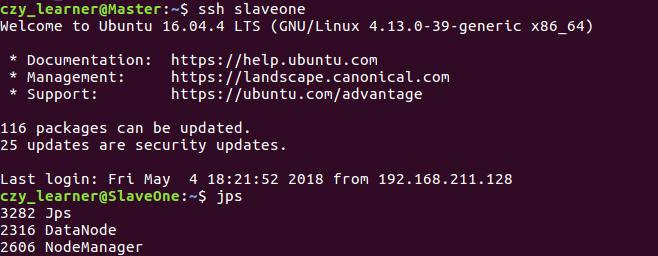
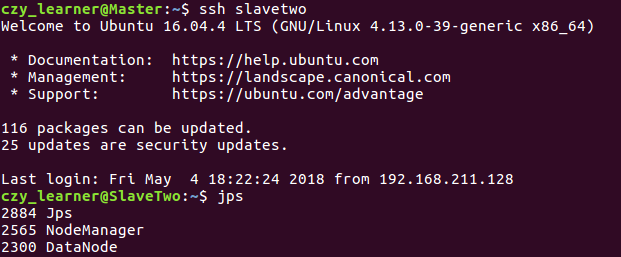
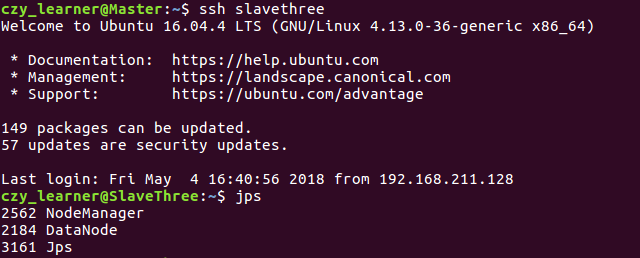
3.2 Hadoop集群的搭建 9
3.2.1 准备阶段 9
3.2.2 集群环境搭建 9
第4章 基于MapReduce框架的MMR-Apriori优化算法 15
4.1 相关定义 15
4.1.1 事务布尔矩阵(T) 15
4.1.2 1-频繁项集映射表 15
4.1.3 基于1-频繁项集事务压缩映射表 15
4.2 MMR-Apriori算法描述 15
4.2.1 产生1-频繁项集映射表 16
4.2.2 产生基于1-频繁项集事务压缩映射表 16
4.2.3 迭代生成k-频繁项集 16
4.3 MMR-Apriori算法实现代码 18
4.3.1 1-频繁项集映射表的实现过程 18
4.3.2 基于1-频繁项集事务压缩映射表的实现过程 20
4.3.3 迭代生成k-频繁项集的实现过程 22
4.4 MMR-Apriori算法实现示例 25
4.4.1产生1-频繁项集映射表示例 26
4.4.2产生基于1-频繁项集事务压缩映射表示例 27
4.4.3 迭代生成k-频繁项集示例 28
第5章 实验分析 30
5.1实验框架 30
5.1.1数据集 30
5.1.2实验方案 30
5.1.3实验环境 30
5.2实验结果分析 31
5.2.1实验算法简介 31
5.2.2结果分析 31
第6章 结语 34
参考文献 35
致谢 37
第1章 绪论
- 研究背景
随着计算机技术的快速发展,各个领域积累的数据量越来越大。而单机串行挖掘由于无法适应大数据的发展,必须寻求一种新的技术手段以适应时代的发展,从而为企业的管理层提供更好的决策服务。
在国外,深受数据分析师和研究学者的偏爱的统计软件—SPSS,其在发展的后期不仅仅融合数据挖掘工具 Clementine而且还增加了智能算法这一模块,使其在操作性和可视性上得到了大幅度的提高,因此迅速得到市场的认可。Angoss公司开发出一款具有快速获取到频繁集合并可以引入外部数据挖掘模型数据等特点的挖掘软件—Knowledge studio,基于其具有响应快、模型简单易懂等优点,一经问世,就受到广泛的欢迎。
在国内,中科院计算所结合免费开源的Hadoop平台,独立自主开发出自己的数据挖掘平台—PDMiner,这个平台是国内最早基于云计算模式的数据挖掘系统,在实际项目中,可以实现挖掘高达 TB 级别的业务数据。百度则通过 Hadoop框架来对人们日常的搜索日志进行数据挖掘并行离线处理网页访问日志。电商巨头阿里巴巴集团使用Hadoop框架进行处理后台的电商交易数据,效率得到了快速的提升[1]。
频繁模式发现算法(Apriori算法)是数据挖掘领域的经典算法之一,应用在各个领域。面对物联网的飞速发展,各领域产生了海量的数据,传统的频繁模式发现算法无法适应海量数据的处理需求,需要对其进行并行化设计,以适应海量数据处理要求。
1.2 研究的目的及意义
1.2.1 目的
传统的关联规则算法Apriori,在运算能力以及并行化效率上,根本无法满足人们的要求,所以如何使用更合适的数据处理模式来减少运算时间、提升对大数据集的处理能力,已经成为了亟待解决的问题。云计算平台Hadoop具备海量数据的存储能力和并行计算能力,可以解决海量数据挖掘的问题,且改进的基于Hadoop并行框架的并行关联规则算法将可以解决传统关联规则算法遇到的难题[2]。本文研究基于MapReduce并行框架的Apriori并行化算法的目的有以下3点:
- 学习并了解数据挖掘的经典算法。
- 基于Hadoop平台下的核心技术—MapReduce编程模型,优化Apriori并行化算法,解决日益增长的大规模数据集的关联规则的分析。
- 将优化的并行化Apriori算法解决生活中的实际问题(购物篮)等问题。
1.2.2 意义
关联规则挖掘算法的并行化以及分布式应用实现的研究是针对当前数据量、数据类型爆炸式增长的一种应对模式。而传统的关联规则算法Apriori无法处理海量的数据集,如何准确、快速地分析海量数据,缩短执行时间是研究频繁模式发现算法并行化的关键。本文研究基于MapReduce并行框架的Apriori并行化算法的意义有以下3点:
- 学习并掌握频繁模式发现算法。
- 学习并掌握Hadoop平台的核心技术—MapReduce分布式编程模型。
- 针对Apriori 算法在挖掘的过程中,出现无法处理海量数据、频繁扫描数据库等弊端的问题,对该算法存在的问题进行优化,并且将优化的算法在并行框架中进行设计实现,以便可以对海量数据进行高效的处理。
1.3 国内外研究现状
在大数据时代下,数据挖掘即数据知识发现,应运而生。数据挖掘[3]是从大量的数据中挖掘出隐含的、未知的、用户可能感兴趣的知识和规则。Agrawal等最初提出关联规则的挖掘的目的主要是用于解决交易数据库中项集之间的关联规则问题。隔年,经过对该算法的进一步研究,Agrawal 等人提出最经典的关联规则挖掘算法—Apriori算法[4]。近年来,针对Apriori算法在计算候选集时产生计算瓶颈的问题国内外研究人员从不同方面提出了多种改进的算法[5]。
张敏等[6]提出VMA算法,该算法基于向量和矩阵,通过扫描数据库将原始事务集数据库转化为布尔向量,利用按支持度大小进行非递减排序的频繁1-项集来建立对应的2-项集支持度矩阵,再由k-频繁项集(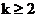 )扩展生成(k 1)-频繁项集。罗丹等[7]提出了一种改进的基于压缩矩阵的Apriori算法,该算法针对已有基于矩阵的Apriori算法所存在的问题,算法进行了以下方面的改进:增加了两个数组,分别用于记录矩阵行与列中1的个数,使得算法在压缩矩阵时减少了扫描矩阵的次数;在压缩矩阵中,把非频繁的项集和不能连接的项集删除,对矩阵进行进一步压缩;改变了删除事务列的条件和算法结束的条件,以减少挖掘结果的误差和算法循环的次数。刘步中[8]提出了一种使用交集策略减少扫描数据库的次数的Inter-Apriori频繁项集挖掘算法,该算法具有较高的效率。崔旭等[9]利用粗糙集的特征属性约简算法对核心属性进行约简,进行构建约简决策表,并在此基础上利用改进的Apriori算法对核心数据进行数据挖掘,最终获取频繁项集[10]。另外,文献[11][12][13]中也提出了许多有效的改进算法。
)扩展生成(k 1)-频繁项集。罗丹等[7]提出了一种改进的基于压缩矩阵的Apriori算法,该算法针对已有基于矩阵的Apriori算法所存在的问题,算法进行了以下方面的改进:增加了两个数组,分别用于记录矩阵行与列中1的个数,使得算法在压缩矩阵时减少了扫描矩阵的次数;在压缩矩阵中,把非频繁的项集和不能连接的项集删除,对矩阵进行进一步压缩;改变了删除事务列的条件和算法结束的条件,以减少挖掘结果的误差和算法循环的次数。刘步中[8]提出了一种使用交集策略减少扫描数据库的次数的Inter-Apriori频繁项集挖掘算法,该算法具有较高的效率。崔旭等[9]利用粗糙集的特征属性约简算法对核心属性进行约简,进行构建约简决策表,并在此基础上利用改进的Apriori算法对核心数据进行数据挖掘,最终获取频繁项集[10]。另外,文献[11][12][13]中也提出了许多有效的改进算法。
本文针对在产生频繁项集出现的多次扫描数据库的问题,结合Apriori算法的重要性质以及MapReduce框架的特性,提出了基于MapReduce并行框架的MMR-Apriori优化算法。
1.4 课题研究内容
本文着眼于解决传统的Apriori算法所存在的重复性扫描数据库的问题。采用前人所做的建立事务布尔矩阵的方法,重点从传统的Apriori算法、并行框架以及Hadoop集群的搭建、基于MapReduce框架的Apriori算法并行化三个方面展开研究工作,以此达到在解决重复性的扫描原始事务集数据库问题的同时,减少后续过程统计k-候选集中的项目集的支持度计数的时间,并采用实验对算法进行验证。本文主要研究的内容有以下3点:
- 传统的Apriori算法的研究
通过对传统的数据挖掘算法Apriori的研究,能充分了解传统的Apriori算法所存在的问题。针对传统的Apriori重复性的扫描原始事务集数据库的问题,本文重点研究建立事务布尔矩阵的方法,以此减少扫描原始数据库的次数。
- 并行框架以及Hadoop集群的搭建的研究
通过对各个并行框架的分析对比,寻找一种合适的并行框架,并通过Hadoop集群环境的搭建,了解分布式编程的思想。同时,通过深入研究Hadoop的核心-MapReduce编程模型,了解MapReduce编程过程。本文基于搭建的伪分布式集群环境以及结合MapReduce编程模型,进行基于MapReduce分布式编程模型的Apriori算法并行化的开发。
- 基于MapReduce分布式编程模型的Apriori算法的并行化研究
海量数据远远超过传统的Apriori算法的处理能力,而基于MapReduce编程模型的Apriori算法可以极大提高传统Apriori算法的处理能力。因此本文研究
基于MapReduce编程模型Apriori算法的并行化处理,在并行编程模型中实现
Apriori并行化算法。
1.5 论文结构安排
本文主要围绕如何解决传统的Apriori算法存在重复性扫描数据库的问题展开研究。
第1章 绪论。本章节首先介绍了国内外的研究背景以及课题研究的意义和目的。深入探讨了论文研究的意义以及目的,其次阐述了目前的国内外学者对于改进传统的Apriori算法所做的一些工作。最后,着重探讨了本文即将开始的研究工作以及对本文的章节结构做了整体的概述。
第2章 Apriori算法。本章节首先重点讲解了传统的Apriori算法求解频繁项集的具体实现过程,并针对传统的Apriori算法所存在的问题给出了具体的分析。
第3章 并行框架分析与Hadoop集群的搭建。本章节首先简要概述了各个并行框架的性能并探讨了选择Hadoop MapReduce并行框架的优势。接着,重点介绍了基于MapReduce分布式框架编程中所用到的接口类,最后,着重介绍了搭建Hadoop伪分布式平台的整个过程。
第4章 基于MapReduce框架的MMR-Apriori优化算法。本章节首先简要介绍了所涉及到的一些相关概念,然后,对MMR-Apriori算法进行了具体的描述,接着,结合所给的具体的描述给出了MMR-Apriori算法具体实现的代码,最后结合具体的数据库示例给出了详细的MMR-Apriori算法过程。
第5章 实验分析。本章节首先对实验的框架进行大致的介绍,接着,详细介绍了用于实验的各个算法的思想,最后,具体分析了采取实验框架中的数据集所得到的实验结果。
第6章 结语。本章节对MMR-Apriori算法进行了具体的分析同时对后续工作的进行了详细的展望。
第2章 Apriori算法
Apriori算法是一种经典的数据挖掘算法,算法过程分为两大部分:一)求解频繁项集;二)通过求解的频繁项集,产生符合设定的最小信任度阀值的关联规则。本文对Apriori算法进行研究,主要是了解Apriori算法的思想以及具体的实现过程,并实现基于MapReduce并行框架的Apriori算法(MR-Apriori)。
2.1 Apriori算法的描述
本文主要对Apriori算法在求解频繁项集所存在的问题展开研究,下面主要讲解求解频繁项集的过程。
2.1.1 求解频繁项集过程
频繁项集的求解分为两个步骤:一)由k-频繁项集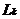 通过连接步生成(k 1)-候选集
通过连接步生成(k 1)-候选集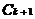 ;二)由生成的(k 1)-候选集通过剪枝步产生(k 1)-频繁项集
;二)由生成的(k 1)-候选集通过剪枝步产生(k 1)-频繁项集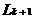 。其中涉及的连接步与剪枝步实现过程如下:
。其中涉及的连接步与剪枝步实现过程如下:
(1)连接步
利用(k-1)-频繁项集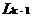 进行自连接操作,得到k-候选集
进行自连接操作,得到k-候选集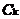 ,然后筛选出不小于设定的最小支持度计数阀值(min_sup)的项目集得到k-频繁项集
,然后筛选出不小于设定的最小支持度计数阀值(min_sup)的项目集得到k-频繁项集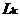 。设
。设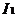 和
和 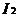 是 中的项目集。记
是 中的项目集。记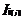 表示
表示 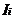 中的第 j个项目。假定项目集中的每个项目均是依照字典序来排列,即(k-1)-频繁项集中的每个项目集,均有
中的第 j个项目。假定项目集中的每个项目均是依照字典序来排列,即(k-1)-频繁项集中的每个项目集,均有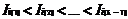 。将与自身连接,如果((
。将与自身连接,如果((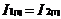 )amp;amp;(
)amp;amp;(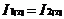 )amp;amp;...amp;amp;(
)amp;amp;...amp;amp;(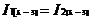 )amp;amp;(
)amp;amp;(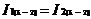 )),那认为
)),那认为 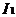 和
和 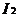 是可连接的。连接和产生的结果是{
是可连接的。连接和产生的结果是{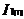 ,
,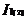 ,...,
,...,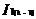 ,
,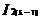 }。
}。
(2)剪枝步
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: