基于python的股票信息的网络爬虫设计与实现毕业论文
2021-12-06 20:49:37
论文总字数:19307字
摘 要
本文主要内容是基于Python的网络股票信息爬虫系统的设计与实现。
在信息爆发的互联网时代,获取信息的成本越来越高,为此针对爬虫技术的研究存在时代的必要性。本课题针对股票信息进行爬取,在技术上,可以将本次爬虫区分为聚焦性爬虫。所谓的聚焦性爬虫是指针对某一类目标信息的爬取程序。在实现过程中主要通过Python的request库进行对目标网站的发送请求,将爬取得到数据通过MySQL数据库、csv文件和txt文件进行保存。对于数据的展示采用了javaFX技术搭配sceneBuild进行快速开发。数据库内的文件采用TableView方式展示,csv文件通过mplfinance进行绘制K线图展示,txt文件则直接显示在程序界面。本课题从实际应用的角度出发,通过设计实现股票爬虫程序展示了聚焦型爬虫的简洁与强大,对初步学习爬虫技术的人群有所帮助
本文最主要的特点是技术实现讲解详细,从具体功能到整体架构的实现技术均一一进行了讲解。
关键词:Python;request;聚焦型爬虫;mplfinance;javaFX;
Abstract
The main purpose of this article is to design and implement the crawling of stock information from the Internet.
In the Internet era where information is erupting, the cost of obtaining information is getting higher and higher. Therefore, research on reptile technology is necessary for the times. This topic crawls stock information. Technically, this crawler can be classified as a focused crawler. The so-called focused crawler refers to a crawling program for a certain type of target information. In the implementation process, the name mainly sends requests to the target website through the Python request library, and the crawled data is saved through the MySQL database, csv file and txt file. For the display of data, javaFX technology is used with sceneBuild for rapid development. The files in the database are displayed in TableView. The csv file is displayed by drawing a K-line diagram through mplfinance, and the txt file is displayed directly on the program interface. From the perspective of practical application, this topic shows the simplicity and power of the focused crawler through the design and implementation of the stock crawler program, which is helpful to the people who initially learn the crawler technology.
The main feature of this article is that the technical implementation is explained in detail, and the implementation technology from the specific functions to the overall architecture is explained one by one.
Key Words:Python;request;focused crawler;mplfinance;java
目录
第一章 绪论1
1.1课题研究背景和意义1
1.2国内外研究现状1
1.3课题研究的思路和注重点2
1.3.1课题研究思路2
1.3.2注重点2
1.4文章结构安排2
第二章 技术综述4
2.1 Python技术综述4
2.1.1 request库4
2.1.2 sqlalchemy库4
2.1.3 mplfinance库4
2.2 java技术综述4
2.2.1 javaFx5
2.2.2 sceneBuild5
2.2.3 java的三层架构(3-tier architecture) 5
2.3 Python爬虫技术综述5
2.4 本章小结7
第三章 系统设计8
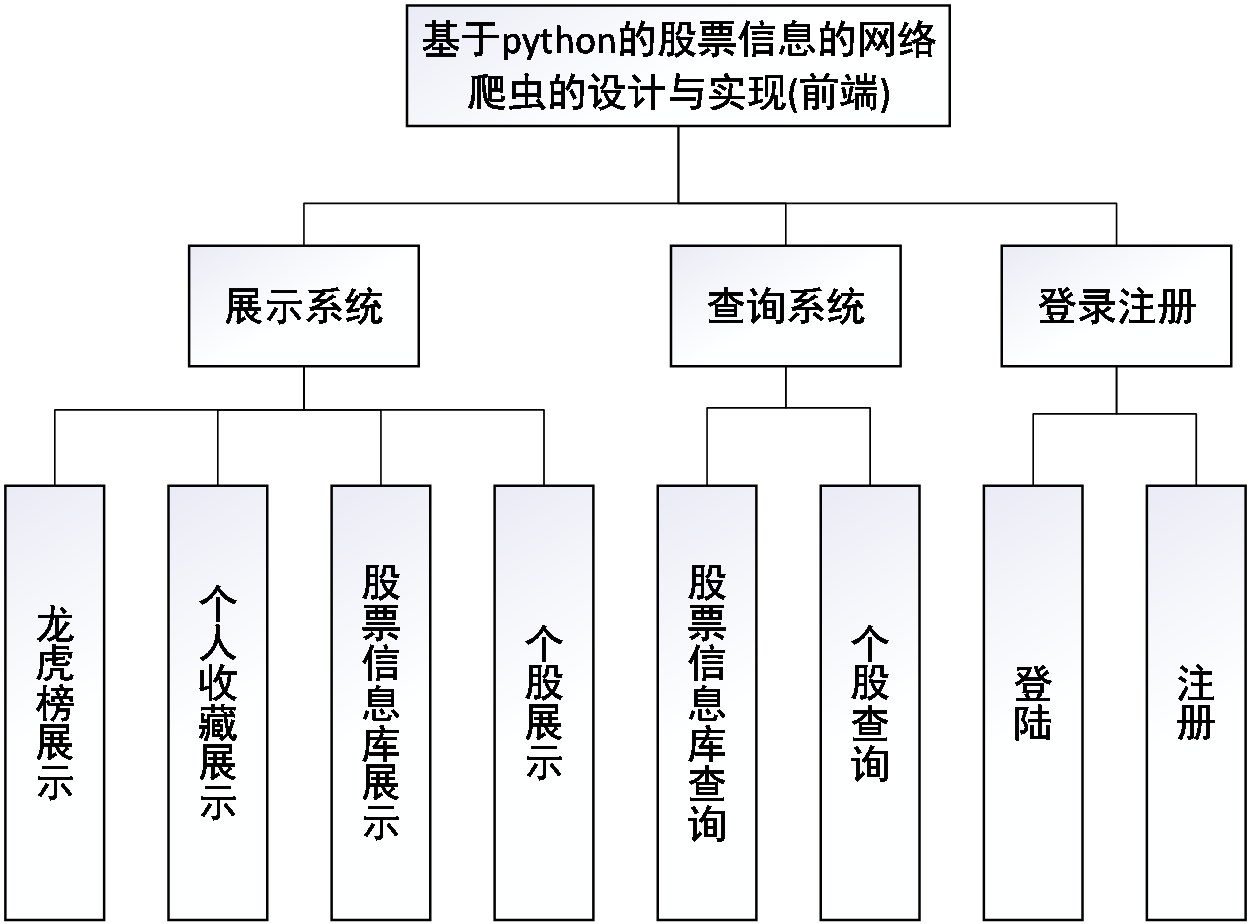
3.1 系统结构设计8
3.2 功能模块设计8
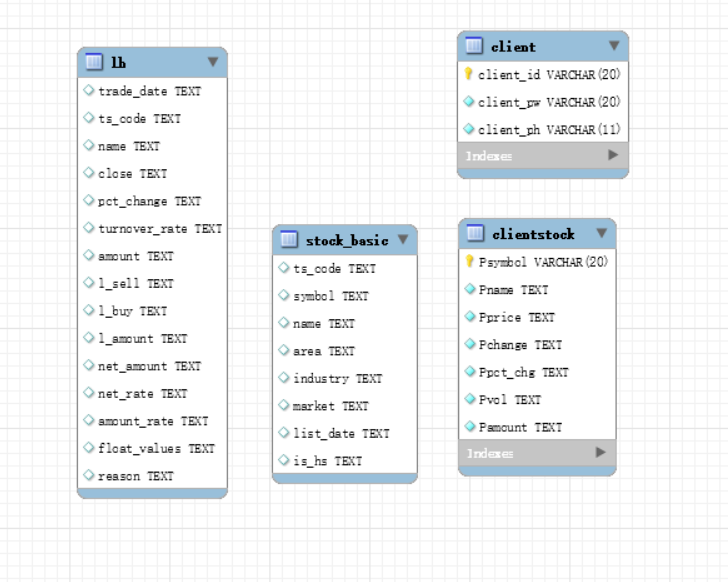
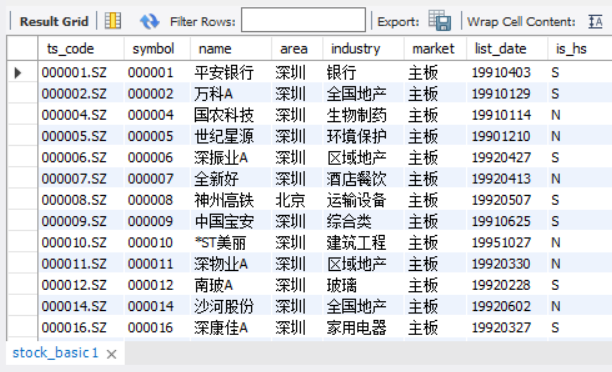
3.3 数据模块设计10
3.4 本章小结14
第四章 详细设计与实现15
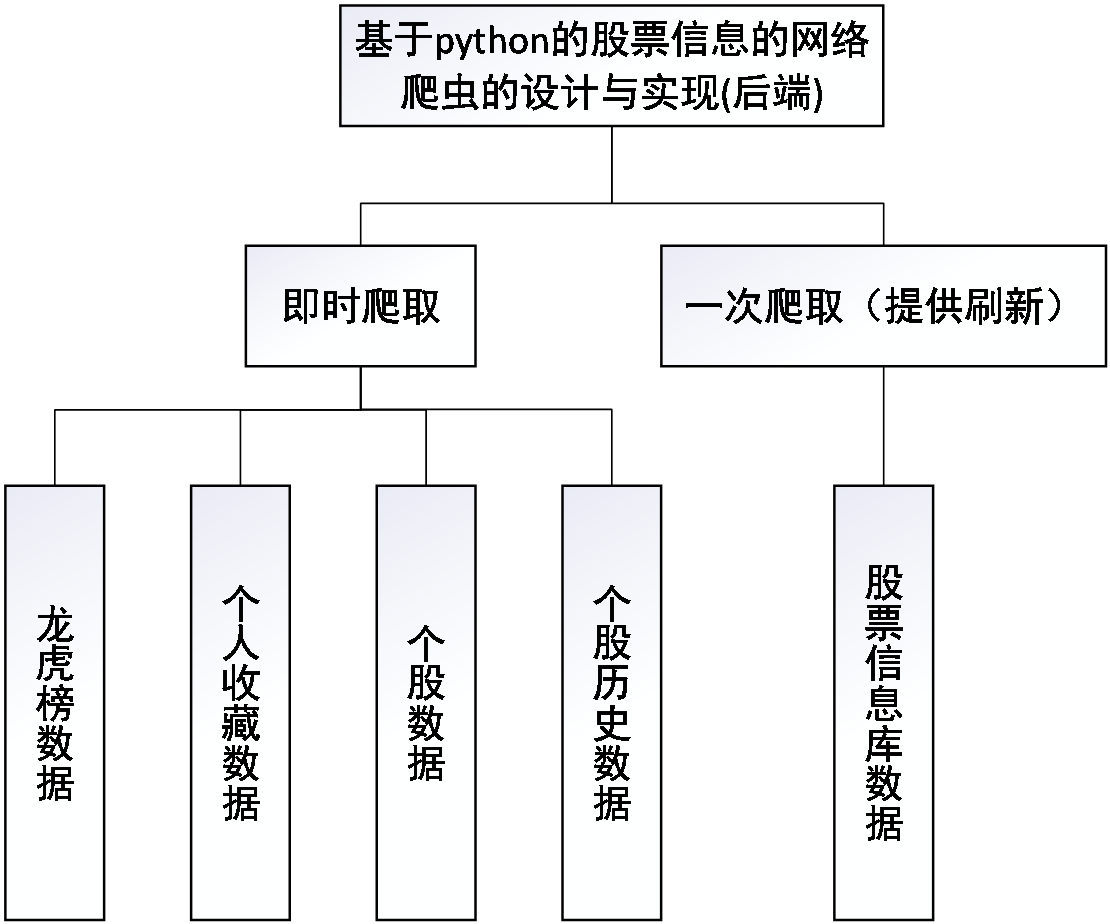
4.1 数据爬取15
4.1.1 数据库格式数据爬取15
4.1.2 .csv、.gif以及.txt格式数据爬取16
4.2 功能的实现17
4.2.1 数据库格式数据展示17
4.2.2 .csv以及.txt文件数据的展示18
4.2.3 数据库查询19
4.2.4 注册登陆20
4.3 本章小结21
第五章 测试22
5.1 注册模块22
5.2 登陆模块24
5.3 查询模块26
5.3.1数据库内查询26
5.3.2 联网实时查询27
5.4 本章小结28
第六章 总结29
参考文献30
致谢31
第1章 绪论
1.1 课题研究背景和意义
从网络诞生之后,信息的交流传播就一直是一个热门问题。TCP/IP协议解决了信息的传输方式,而各种类型的爬虫则提供了信息获取的基本途径。最早的搜索引擎使用的是直接人工收录网站网址,通过在特定网站的信息库中进行信息检索,从而为用户提供获取信息的方法。随后,人们发现使用机器在互联网上收集信息,在用户键入关键词后返回结果的方式更乐于让人接受,这便是早期的网络爬虫。因此网络爬虫在最早期也被称为机器人。
众所周知,科技的发展很大程度上是为了方便使用者,网络爬虫的发展也是顺应了这一目标。从最初的为美国军方提供信息到现在为全球数十亿人口提供信息,互联网始终在不断的发展。不断地发展自然也带来了大量的信息。这对于想要获取特定信息的使用者来说,便成为了一个难题。想要解决信息的指数增长带来的用户获取特定信息的问题,只有依赖于机器。因此各种类型爬虫的发展对于网络,对于全人类来说都具有一个不凡的意义。
1.2 国内外研究现状
1973年,美国Vint Cerf 和Bob Kahn 开发的Transmission Control Protocol(TCP) 和Internet Protocol(IP)定义了信息在网络中的传输方式[1]。1983年作为现代互联网前身的ARPANET放弃Network Control Protocol(NCP)转而使用TCP/IP至今,网络信息流呈现爆发性增长[1]。为了获取用户想要得到的目标信息,网络爬虫(Web Crawler)应运而生。
现常见的网络爬虫类型有:聚焦网络爬虫(Focused Web Crawler)、增量网络爬虫(Incremental Web Crawler)、分布式网络爬虫(Distributed Crawler)、并行式网络爬虫(Parallel Crawler)[2]。当然网络爬虫还可以按照其他标准分成不同的类型,比如通常会将各大搜索引擎的爬虫称呼为通用爬虫(General-purpose Web Crawler)。因为,在搜索引擎领域做的最好的Google,为了解决信息的繁杂多样对于搜索引擎的挑战,Google使用分布式网络,通过在大量的机器运行爬虫,并行处理数据,从而快速返回结果[3],在大多数情况下我们还是称呼其爬虫类型为通用爬虫。现阶段,在国内使用较多的还是聚焦型网络爬虫,通过与大数据人工智能的结合,为用户提供精准的内容投放。本次系统设计也采用聚焦型网络爬虫,所以详细介绍一下:为了解决通用搜索引擎尊在的局限性,解决搜索引擎返回大量用户并不关心的内容、对于信息含量密集且具有一定结构的数据无能为力、基于关键字检索难以根据语义信息提出查询的问题,定向爬取相关网页资源的聚焦爬虫就显得尤为重要,聚焦爬虫是将目标定为抓取与某一主题内容相关的网页,为面向主题的用户查询准备特定的数据资源的一种网络爬虫[4]。
1.3课题研究的思路和注重点
1.3.1 课题研究思路
- 了解python的基本语法;
- 学习并掌握针对一般性爬虫需要使用的python库;
- 了解web相关语言,熟悉数据的接口;
- 通过网络搜索数据来源网站,择优使用;
- 从多个来源爬取信息,确保信息的实用性;
- 通过Mysql保存绝大部分信息,将实时性信息和基本信息隔开获取并存放,最大限度减小数据模块的耦合性;
- 针对爬取的信息采用javafx的桌面程序技术加以展示,确保直观,易于阅读;
1.3.2注重点
- 在程序的设计上采用接近实际工作的前后端分离的技术完成个人程序制作;
- 在数据来源上采用多个数据来源,提高数据获取的可靠性,可以有效避免一处数据来源出问题时,影响其他数据的获取。
- 根据各种数据在获取时的及时性分开存放,可以有效避免一处数据出问题导致其他数据也出现问题。
- 根据数据的更新频,科学合理地采用一次获取本地保存以及及时获取联网爬取两种方案,可以有效的节省资源。
1.4文章结构安排
本文研究了基于python的股票信息的网络爬虫设计与实现,文章的行文结构如下:
第一章:绪论。介绍了课题的研究背景、研究意义、研究现状、研究思路以及在研究过程中发现的值得注意的重点,以便于读者对本文的研究内容的进行初步地了解。
第二章:技术综述。介绍了本课题的项目实现过程中用到的编程技术。
第三章:系统设计。通过介绍系统整体的架构构建来帮助理解本次课题的项目。其中详细介绍了系统总的结构设计思路、功能模块的作用和数据的存储三大方面。
第四章:详细设计与实现。本章从后端数据的获取过程以及前端界面的设计方案两个方面,从代码层面详细介绍了各种数据的获取方式以及界面的实现。
第五章:测试。本章通过设计各种测试用例,详细的检测了程序的不稳定性以及各方面可能出现的问题,来提高程序的正确性与可靠性。
第六章:总结。对本次课题的实现做出总结。
第二章 技术综述
2.1 Python技术综述
Python作为最受欢迎的程序设计语言之一,其发展于早期的ABC语言(一种教学语言,Python创始人Guido参加设计)[5]。作为同一个人设计的语言,两者并没有同样深受人们喜爱,反而是Python后来居上,究其原因在于开放二字,这也是Guido在设计ABC语言之后另起炉灶的原因。在开放的基础上,经过后人的进一步参与,Python的库丰富到编程人员可以极为快速完成某个功能的实现并应用于实际场景当中,同时结合Python的简洁优美的语法可以让使用者的学习成本大大降低。值得一提的是,Python还是一款支持跨平台的编程语言[6]。在使用的场景方面Python主要用于科学计算、人工智能、网络爬虫以及web和Internet的开发。
2.1.1 requests库
用来发送请求,处理URL资源。正如官网的介绍是一款优美简洁的用于Python的HTTP库,为了全人类而开发的。它可以让你特别简单的发出HTTP请求,解析返回数据,并保持活跃,对于HTTP连接池的操作可以100%自动化。
2.1.2 sqlalchemy库
SQLAlchemy作为一个功能强大的Python ORM工具包提供了关于全功能的SQL和ORM操作[7]。对于喜欢使用全程序化的编程人员来说是一件幸事,可以很好地避免人为的错误。在实际项目中,可以牺牲一点点的性能带来更加安全的数据库操作和更为快速的开发过程。
2.1.3 mplfinance库
在github上有详细的mplfinance库的介绍,作为配合matplotlib(Python的数据可视化分析图库[8])的画图库,它提供了多种图表的绘制方案,其中包括本次需要使用的K线图。使用mplfinance的好处是它可以通过matplotlib直接绘制出图形界面,不需要通过借助其他软件来显示图表,在数据方面它接受pandas读取的数据作为基本绘图数据。
2.2 java技术综述
作为当前使用最为广泛的语言之一,java由于其特有的JVM机制[9],通过虚拟机运行class文件,执行编译产生字节码[10],在各大平台都有较好的兼容性。同时,java还具有C 一样强大的功能,并且比C 对编程人员更加友好,剔除了很多C 中学习成本较高的语言特性。在安全性方面,java没有指针,而是使用特别的存储分配模型,这为项目提供了更为安全的环境。在开发过程中java在开发效率、性能和安全性等综合评价中,java都具有很大的优势。
2.2.1 javaFx
在桌面程序的构造中,java提供了一个非常便捷的javaFX技术,从软件工程的角度看,它对于项目的快速开发提供了更为科学合理的思路。能够帮助编程群体(注意是群体,而非个人)更加高效的合作完成同一个项目[11]。在基本项目开发中javaFX提供了多种UI控件,可以满足绝大部分开发需求。
2.2.2 sceneBuild
在实际开发中,通常使用sceneBuild配合javaFX开发桌面程序。sceneBuild提供了可视化的界面,能让界面开发人员以“所见即所得”的方式进行UI设计[12]。对于javaFX的UI控件可以直接拖拽定位,大大提高了桌面开发的效率,有利于开发人员设计用户界面。
2.2.3 java的三层架构(3-tier architecture)
三层架构如下[13]:
- 表现层(UI):即展现给用户观看的界面,是一个用户在使用程序时的所见所得;
- 业务逻辑层(BLL):针对具体功能的实现,即对数据层实现符合程序功能的逻辑操作,处理数据的业务需求;
- 数据访问层(DAL):本层直接操作的对象就是数据,针对数据进行增删改查等操作。
三个架构层次的划分视为了更加符合软件工程的“高内聚,低耦合”思想,在软件体系架构中,这种思想是最常见的,同时也是十分重要的一种结构划分思想。结构图如下:
请支付后下载全文,论文总字数:19307字
相关图片展示: