基于深度学习的相机影像识别的设计与实现毕业论文
2021-12-06 20:48:35
论文总字数:29190字
摘 要
相机是人们生活中必不可少的用品,获取图像是其主要功能图像。在科技的进步下,人们获取的图像信息也越来越复杂和多样。如何将这些图像信息加以利用,是当今学者们的关注要点。普通的影像识别需要手动确定图片性质,不匹配则效率非常低下。比较理想的解决办法是将深度学习应用于影像识别,经过对部分数据进行分析自动选择图片特征。深层结构是由多层非线性运算构成的,如在具有多个隐含层的神经网络中,或在使用多个子公式的复杂命题公式中。
本文讨论了在影像识别中使用深度学习的一些方法,选择了比较合适的模型来完成任务。研究人员可以数据来训练深度神经网络,使其更符合识别的要求。用户可以上传图片进行影像识别,检测结果是否符合预期。
关键词:深度学习,图像识别,神经网络
DESIGN AND IMPLEMENTATION OF CAMERA IMAGE RECOGNITION BASED ON DEEP LEARNING
ABSTRACT
Camera is an essential thing in people's life, image acquisition is its main function image. With the development of science and technology, people get more and more complex and diverse image information. How to make use of these image information is the focus of scholars. Ordinary image recognition needs to determine the nature of the image manually, and the efficiency of mismatch is very low. The ideal solution is to apply deep learning to image recognition, and automatically select image features after analyzing some data. The deep structure is composed of multi-layer nonlinear operations, such as in the neural network with multiple hidden layers, or in the complex proposition formula with multiple subformulas.
This paper discusses some methods of using deep learning in image recognition, and selects a more appropriate model to complete the task. Researchers can train the deep neural network with data to make it more suitable for recognition. Users can upload images for image recognition, and check whether the results meet the expectations.
Key Words: deep learning, image recognition, neural network
目 录
1 引言 1
1.1 项目背景及意义 1
1.2 国内外研究现状 2
1.3 本文研究的目的和内容 3
2 基础理论和相关技术介绍 4
2.1 深度学习 4
2.2 卷积神经网络 6
2.3 TensorFlow 8
3 需求分析 9
3.1 总体要求 9
3.2 图像识别 10
3.3 图形化界面 10
4系统概要设计 11
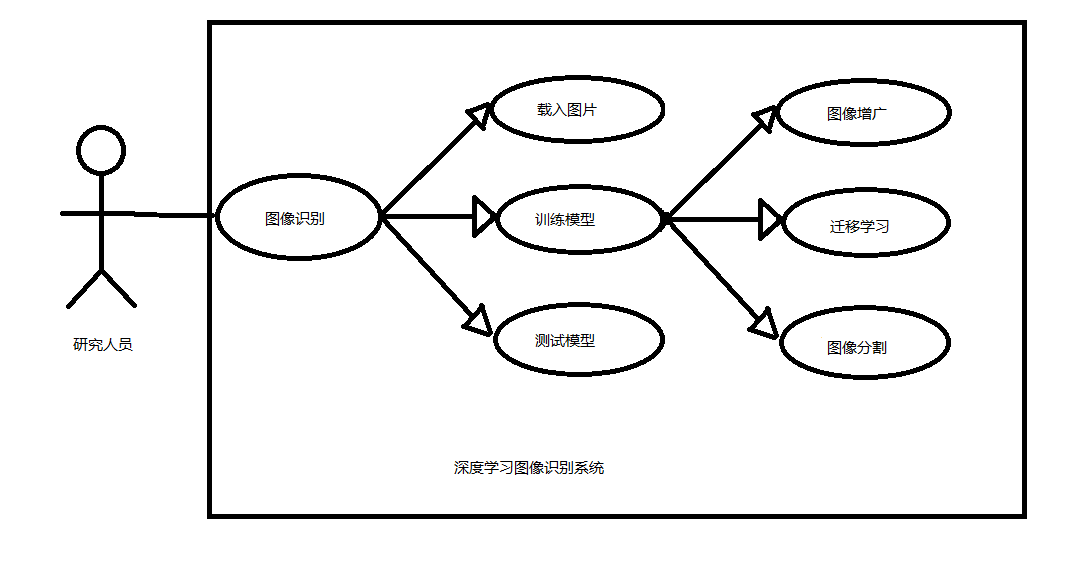
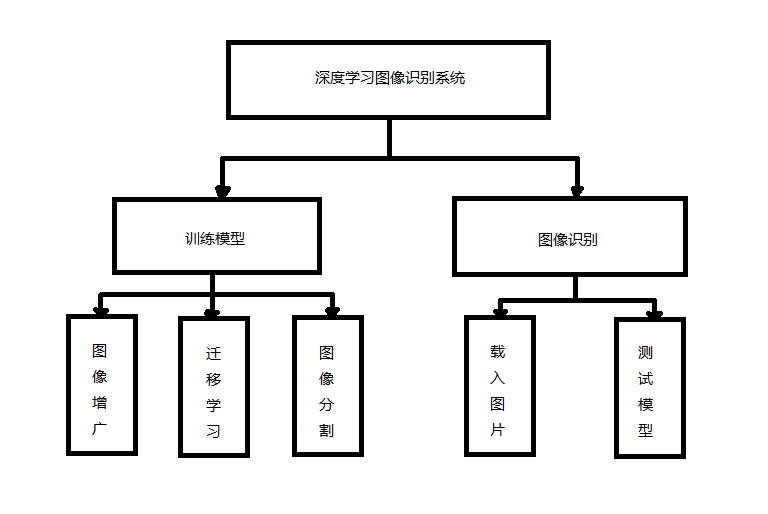
4.1 基本结构 11
4.2 模块概要设计 11
5 系统详细设计 14
6 系统实现过程 16
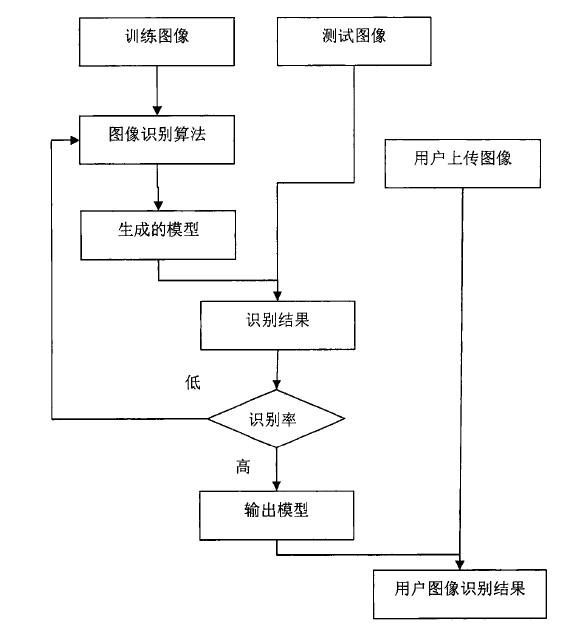
6.1 总体实现 16
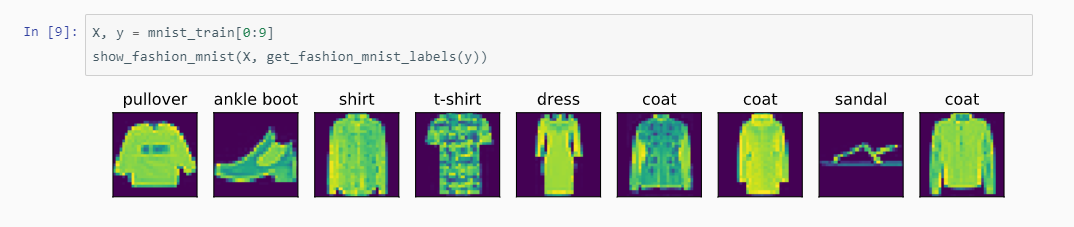
6.2 导入数据实现 16
6.3 训练模型实现 20
6.4 测试模型实现 21
7 系统实现结果 25
8 总结与展望 31
1 引言
项目背景及意义
半个多世纪以来,让计算机充分模拟我们的世界,展示我们所称的智能一直是研究的焦点。要做到这一点,很明显,大量关于我们世界的信息应该以某种方式,显式或隐式地存储在计算机中。由于手动将所有信息形式化似乎令人望而生畏,而计算机可以使用这种形式来回答问题并将其推广到新的上下文中,很多研究人员已经开始学习算法来获取其中的绝大多数信息。在理解和改进学习算法方面已经取得了很大的进展,但是人工智能的挑战仍然存在。我们有分析场景并用自然语言描述它们的算法吗?其实没有,除非设置为完全不能通用的算法。我们有没有算法可以推断出足够多的语义概念,以便能够与使用这些概念的大多数人进行交互?没有。如果我们考虑图像理解,这是人工智能任务中最具体的任务之一,我们马上能意识到,我们还发现不了许多视觉处理和语义概念的学习算法,而这些概念似乎是解释网络上大多数图像所必需的。其他人工智能任务的情况也是类似。
例如,考虑解释输入图像的任务,当人类试图解决一个特定的人工智能任务时,他们经常利用自己的直觉将问题分解为子问题和多个层次的表示。现阶段的计算机视觉领域的最前沿技术是从像素点开始并以线性或核分类器结束的模块序列,中间模块的作用是转换和学习,开始时进行对底层特征的提取和分析,然后对它们进行一系列的变形,然后检测最频繁的模式。从自然图像中提取能为我们所用的信息的一种合理且常见的方法是将原始像素逐渐转换为更抽象的表示,例如,从图像或图像中某个实物轮廓的边缘的开始,检测更复杂但更局部的形状,直到识别与子对象和作为图像一部分的对象相关联的抽象类别,并将所有这些集合在一起以获取对场景的充足理解来回答有关它的问题。
在这里,我们假设表示复杂行为所必需的计算机器需要高度变化的数学函数,即在原始感觉输入方面是高度非线性的数学函数,并在我们感兴趣的领域显示大量变化。我们将学习系统的原始输入视为一个高维实体,由许多观察到的变量组成,这些变量通过未知的复杂的统计关系相互联系。例如,利用空间几何体的三维知识和光照情况,我们可以将底层的物理和几何因素的微小变化与图像中所有像素的强度变化联系起来。我们之所以称这些为变化因素,是因为它们是数据的不同方面,可以单独变化,而且往往是独立变化的。有了这些基础,我们对其所涉及的物理因素的深入了解让人们能够获得这些依赖关系的数学形式以及具有相同的三维对象的一组图像的形状。如果一台机器捕捉到了解释数据统计变化的因素,以及它们如何相互作用以生成我们观察到的数据类型,我们就可以说,机器理解这些变化因素所掩盖的世界的那些方面。不幸的是,一般来说,对于自然图像下的大多数变化因素,我们没有对这些变化因素的分析性理解。因为我们之前没有关于这些图像的相关了解,即使对于一个对我们来说显然非常简单的抽象也是如此。像人类这样的高级抽象具有对应于一组数量非常大的可能图像的特性,从像素强度空间中简单欧氏距离的角度来看,这些图像可能彼此非常不同。这组图像的标签可以在像素空间中适当的形成一个高度卷积的区域,该区域甚至不一定是连接的区域。人类范畴可以看作是对图像空间的高层次抽象。我们在这里所说的抽象可以是一个类别或者一个特征,一个感觉数据的函数,它可以是离散的或者连续的。许多低级和中级的概念对于构造一个人类检测器是有用的。人类部分特定的感知与较低层次的抽象有某种联系,而较高层次的抽象则被我们称为“更抽象”,因为它们与人类的实际感知几乎没有联系,并且通过其他中间层次的抽象实现。
除了帮我们解决中间抽象的困难之外,我们图像识别或语音识别机器能获取的视觉和语义类别的数量尽量大。深度学习的重点是代替我们进行类似的抽象过程,包括最低级别的特征和最高级别的概念。最符合我们预期的情况是,某种学习算法能够在几乎没有人类参与帮助的时候实现这一过程,也就是说,无需手动定义所有必要的抽象,也无需提供大量相关的手工标记示例。如果这些算法能够充分利用网络上大量的文本和图像资源,将有助于将大量的人类知识转化为机器可解释的形式。
国内外研究现状
深度学习这一概念是美国学者Ference Marton和Roger Saljo于1976年首次提出的。近年来深度学习由于计算机技术的迅速发展而变得越来越火热。Rumelhar和Hinton等人于1986年研究了反向传播算法。Hinton于2006年首次提出深度信念网络这一概念。之后深度学习被知识界和应用界广泛关注,国内也有许多学者在此方面做出贡献。
本文研究的目的和内容
本系统为基于深度学习的相机影像像识别系统,管理员可以通过训练数据完善模型进行图像识别,查看识别结果。用户可以上传图片进行图像识别,检测识别结果是否符合自己的预期。
2 基础理论和相关技术介绍
2.1 深度学习
深度学习方法的目的是学习特征层次,较高层次的特征由较低层次的特征组成。自动学习多个抽象层次上的特征让一个系统学习将输入直接映射到数据输出的复杂函数,不完全依赖于人造的特征。这对于更高层次的抽象尤其重要,因为人类通常不知道如何根据原始的感官输入明确地指定抽象。随着机器学习方法的数据量和应用范围的不断增长,自动学习强大功能的能力将变得越来越重要。
结构的深度指在学习的函数中,非线性运算组成的层数。虽然现在的绝大部分学习算法都只能在层数很浅的时候发挥作用,但哺乳动物的大脑组织成一个深层结构(Serre、Kreiman、Kouh、Cadieu、Knoblich和Poggio,2007),将给定的输入感知表达为多个抽象层,每个抽象层对应于大脑皮层的不同区域。人类通常以层次化的方式描述这些概念,具有多个抽象层次。大脑似乎也通过多个阶段的转换和描述来处理信息。这在灵长类动物的视觉系统中尤其明显(Serre等人,2007),其处理阶段的顺序是:边缘检测,形成原始形状,然后逐渐向上变为更复杂的视觉形状。
受到大脑结构化的深度的启发,神经网络研究人员数十年来一直希望训练深层的多层神经网络(Utgoffamp;Stracuzzi,2002;Bengioamp;LeCun,2007),但是在2006年之前没有成功的尝试报道:研究人员报告了典型的两个或三个层次(即一个或两个隐藏层)的积极的实验结果,但是训练更深层的网络总是会产生较差的结果。2006年发生了一些可以被视为突破的事情:Hinton和多伦多大学的合作者引入了深度信念网络或简称DBN(Hinton,Osindero,amp;Teh,2006),通过一次贪婪地训练一层的学习算法,利用每层的无监督学习算法,限制Boltzmann机器(RBM)(Freundamp;Haussler,1994)。不久之后,基于自动编码器的相关算法被提出(Bengio,Lamblin,Popovici,amp;Larochelle,2007;Ranzato,Poultney,Chopra,amp;LeCun,2007),显然利用了相同的原理:使用无监督学习指导中级表示的训练,这可以在每一层局部执行。最近还提出了其他用于深层结构的算法,这些算法既不利用RBMs,也不利用自动编码器,并且利用了相同的原理(Weston,Ratle,amp;Collobert,2008;Mobahi,Collobert,amp;Weston,2009)。
自2006年以来,深度网络不仅成功地应用于分类任务(Bengio等人,2007;Ranzato等人,2007;Larochelle、Erhan、Courville、Bergstra和Bengio,2007;Ranzato、Boureau和LeCun,2008;Vincent、Larochelle、Bengio和Manzagol,2008;Ahmed、Yu、Xu、Gong和Xing,2008;Lee、Grosse、Ranganath和Ng,2009),也成功地应用于回归(Salakhutdinovamp;Hinton,2008)、降维(Hintonamp;Salakhutdinov,2006a;Salakhutdinovamp;Hinton,2007a)、建模纹理(Osinderoamp;Hinton,2008)、建模运动(Taylor,Hinton,amp;Roweis,2007;Tayloramp;Hinton,2009)、对象分割(Levner,2008)、信息检索(Salakhutdinovamp;Hinton,2007b;Ranzatoamp;Szummer,2008;Torralba,Fergus,amp;Weiss,2008),机器人(Hadsell,Erkan,Sermanet,Scoffier,Muller,amp;LeCun,2008),自然语言处理(Collobertamp;Weston,2008;Weston et al.,2008;Mnihamp;Hinton,2009),以及协作过滤(Salakhutdinov,Mnih,amp;Hinton,2007)。尽管自动编码器、RBMs和DBNs可以使用未标记的数据进行训练,但在上述许多应用中,它们已成功地习惯于应用于特定任务的深度监督前馈神经网络的初始化。
由于深层结构可以看作是一系列处理阶段的组合,所以深结架构提出的直接问题是:数据的哪种表示形式应该作为每个阶段的输出(即另一个阶段的输入)?这些阶段之间应该有什么样的接口?最近对深度结构的研究的一个特点是集中在这些中间表示上:深部结构的成功属于RBMs(Hinton等人,2006)、普通自动编码器(Bengio等人,2007)、稀疏自动编码器(Ranzato等人,2007、2008)以无监督方式学习的表示,或去噪自动编码器(Vincent等人,2008)。这些算法可以被视为学习将一种表示(前一阶段的输出)转换为另一种表示,在每一步中,可能更好地分离数据背后的变化因素。正如我们希望的那样,我们一次又一次地观察到,一旦在每一个层次上找到了一个好的表示,它就可以用来初始化和成功地通过基于监督梯度的优化训练一个深神经网络。
人类大脑中的每一个抽象过程都是由许多特征的一小部分的“激活”组成,这些特征通常不是相互排斥的。因为这些特征不是互斥的,所以它们形成了所谓的分布式表示(Hinton,1986;Rumelhart,Hinton,amp;Williams,1986b):信息不局限于特定的神经元,而是分布在许多神经元上。除了分布之外,大脑似乎还使用了一种稀疏的表示法:在给定的时间内,只有大约1-4%的神经元一起活动(Attwellamp;Laughlin,2001;Lennie,2003)。许多现有的机器学习方法在输入空间是局部的:为了获得在数据空间的不同区域表现不同的学习函数,它们需要这些区域的不同可调参数。尽管当可调参数数量较大时,统计效率并不一定很低,但只有在加入某种形式的先验(例如,参数的较小值是首选)时,才能获得良好的泛化效果。当先前的任务不是特定的时,它通常会迫使解决方案非常平滑,与基于局部泛化的学习方法相比,使用分布式表示可以区分的模式总数可能与表示的维数成指数关系(即学习特征的数量)。
在许多机器视觉系统中,学习算法被限制在这样一个处理链的特定部分。其余的设计仍然是劳动密集型的,这可能会限制此类系统的规模。另一方面,我们所认为的智能机器的一个特点是包含了足够多的概念。仅仅认识人是不够的。我们需要能够处理大量此类任务和概念的算法。手动定义许多任务似乎让人望而生畏,学习在这种情况下变得至关重要。此外,不利用这些任务之间以及它们所需要的概念之间的潜在共性似乎是愚蠢的。这一直是多任务学习研究的重点(Caruana,1993;Baxter,1995;Intratoramp;Edelman,1996;Thrun,1996;Baxter,1997)。具有多个层次的体系结构自然地提供了这样的组件的共享和重用:用于检测人的低级视觉特征(如边缘检测器)和中级视觉特征(如对象部件)对于大量其他视觉任务也很有用。深度学习算法是基于学习中间表示的,可以在任务之间共享。因此,他们可以利用来自类似任务(Raina,Battle,Lee,Packer,amp;Ng,2007)的数据和无监督数据,以提高在经常遭受标记数据不足的大型挑战性问题上的性能,如Collobert和Weston(2008)所示,在几个自然语言处理任务中超越了最先进的水平。Ahmed等人在视觉任务中应用了一种用于深层结构的类似的多任务方法。(2008年)。考虑一个多任务设置,其中对于不同的任务有不同的输出,这些输出都是从共享的高级特征池中获得的。这些学习到的特征中有许多是在任务之间共享的,这一事实提供了按比例共享统计强度的能力。现在考虑一下,这些学习到的高级特征本身可以通过组合来自公共池的低级中间特征来表示。同样,统计强度也可以通过类似的方式获得,并且这种策略可以用于深层结构的每个级别。
请支付后下载全文,论文总字数:29190字
相关图片展示: