网络直播间弹幕文本数据挖掘毕业论文
2020-04-10 16:13:00
摘 要
针对网络直播工作者主播得到用户的信息来源为弹幕及礼物信息,本研究设计了一套对弹幕的文本及礼物的情况分析系统,对用户进行数据分析及聚类。
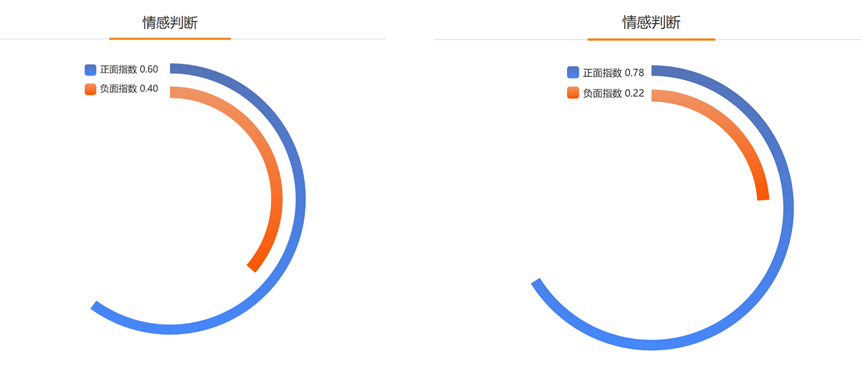
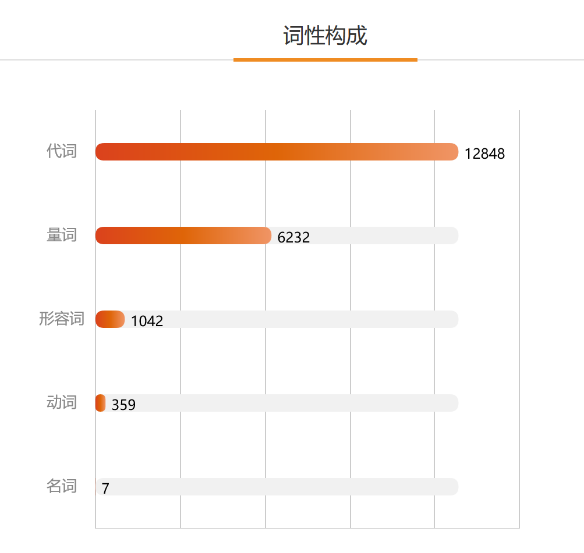
在利用网络爬虫进行直播间弹幕的文本爬取的基础上,利用数据分析工具SPSS Modeler及新浪微舆情对文本进行挖掘分析。对采集到的数据进行处理,通过文本分词、神经网络、C5算法及K-Means聚类算法得到等级、头衔、弹幕长度及礼物输出之间的相互关系及弹幕文本的情感判断、词性分类等结果。实现直播间信息价值化的程序化处理,整理付费用户的兴趣点及个性化分析。
本设计包含直播间弹幕的文本采集、礼物信息采集、文本预处理、文本分析、聚类分析与算法预测等模块。以用户信息、发送弹幕、赠送礼物为数据输入,输出弹幕、礼物、等级、头衔的聚类及预测关系。
关键词:弹幕;文本挖掘;聚类分析;神经预测算法
Abstract
For the webcast worker anchor, the source of the user's information is barrage and gift information. In this study, a system for analyzing the text and gifts of the barrage is designed to perform data analysis and clustering for users.
On the basis of using web crawlers to crawl text on the screen of the live room, the data analysis tools SPSS Modeler and Sina microblog are used to mine the text. The collected data is processed, and the relationship between rank, title, barrage length and gift output, and the emotional judgment and part-of-speech classification of the barrage text are obtained by text segmentation, neural network, C5 algorithm and K-Means clustering algorithm. Wait for the result. Realize the programmatic processing of the information value of the live studio, organize the interest points and personalized analysis of the paying users.
The design includes modules for text acquisition, gift information collection, text preprocessing, text analysis, cluster analysis, and algorithm prediction in the live-room barrage. Take user information, send barrage, give gifts as data input, output barrage, gifts, rank, title clustering and forecasting relationship.
Key Words:Barrage; text mining; cluster analysis; Neural Prediction Algorithm
目 录
第1章 绪论 1
1.1研究背景 1
1.1.1电子竞技和网络直播的兴起 1
1.1.2直播平台 1
1.2国内外研究现状 2
1.2.1文本分析研究现状 2
1.2.2文本聚类概述及研究现状 3
1.3研究内容及方法 4
第2章 直播间信息采集与内容提取 6
2.1直播间弹幕信息采集方法设计 6
2.2利用API实时爬取斗鱼弹幕 6
2.2.1运行环境 6
2.2.2实例分析 6
第3章 文本预处理及分词 10
3.1文本预处理 10
3.1.1分词 10
3.1.2停用词处理 10
3.2聚类处理 11
3.2.1K-Means算法 11
3.2.2K-Means算法的优缺点 11
3.2.3K-Means算法实现 12
3.3预测分析 12
3.3.1 BP神经网络算法 12
3.3.2 C5.0算法 12
3.3.3预测算法实现 13
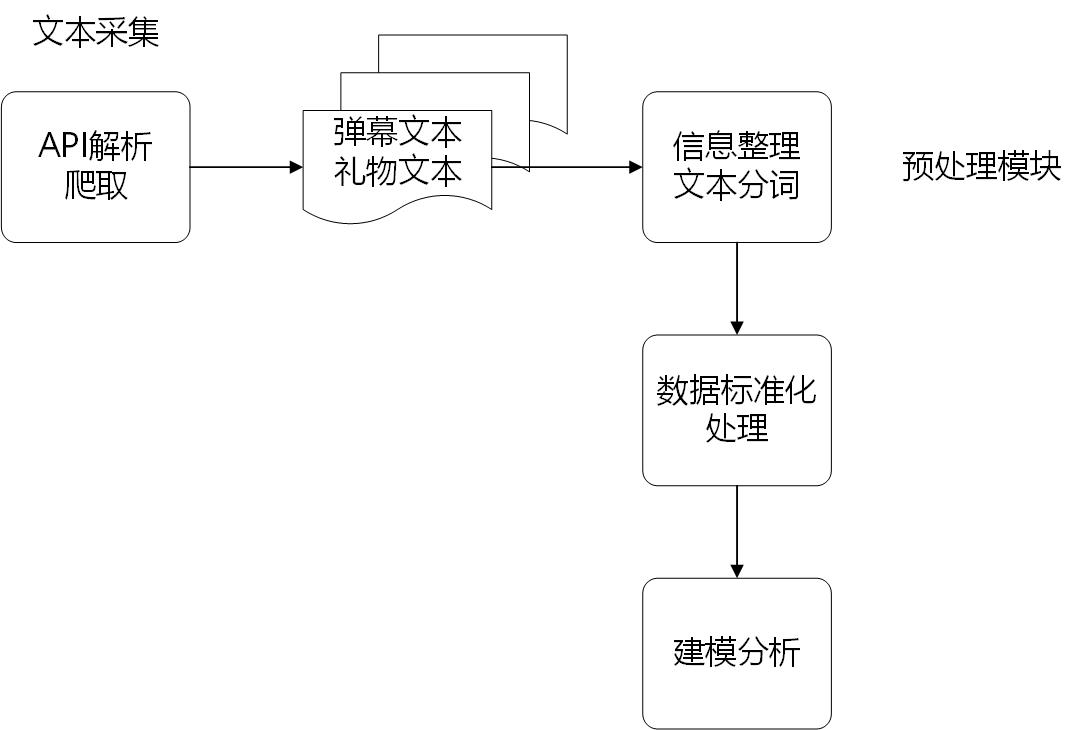
第4章总体框架设计 14
4.1 文本采集 14
4.2 预处理模块 14
4.2.1弹幕信息及礼物信息预处理 14
4.2.2弹幕文本内容预处理 15
4.3 数据标准化处理 15
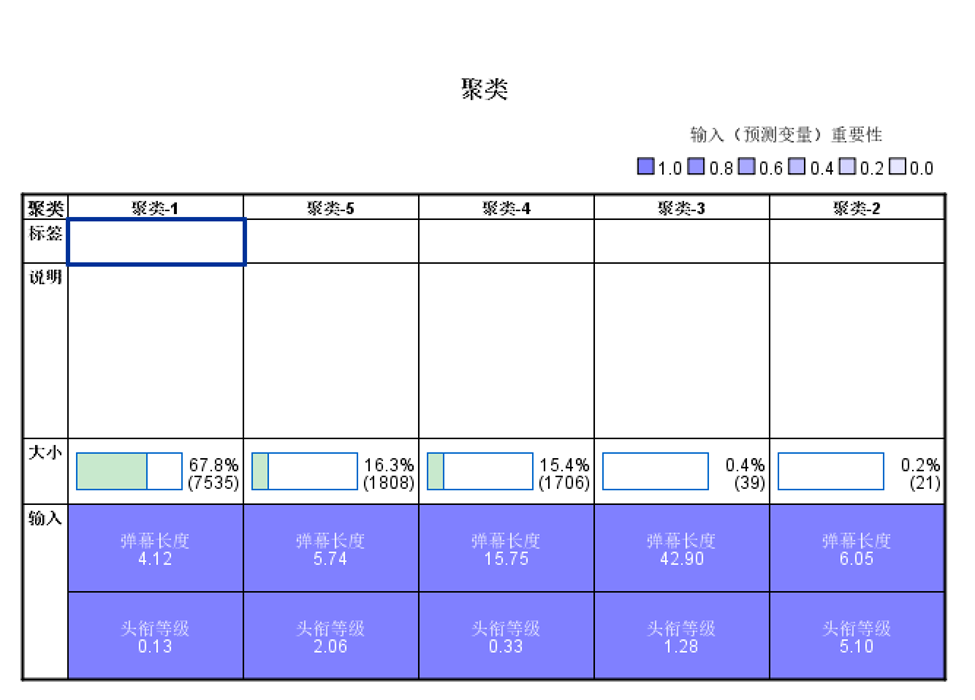
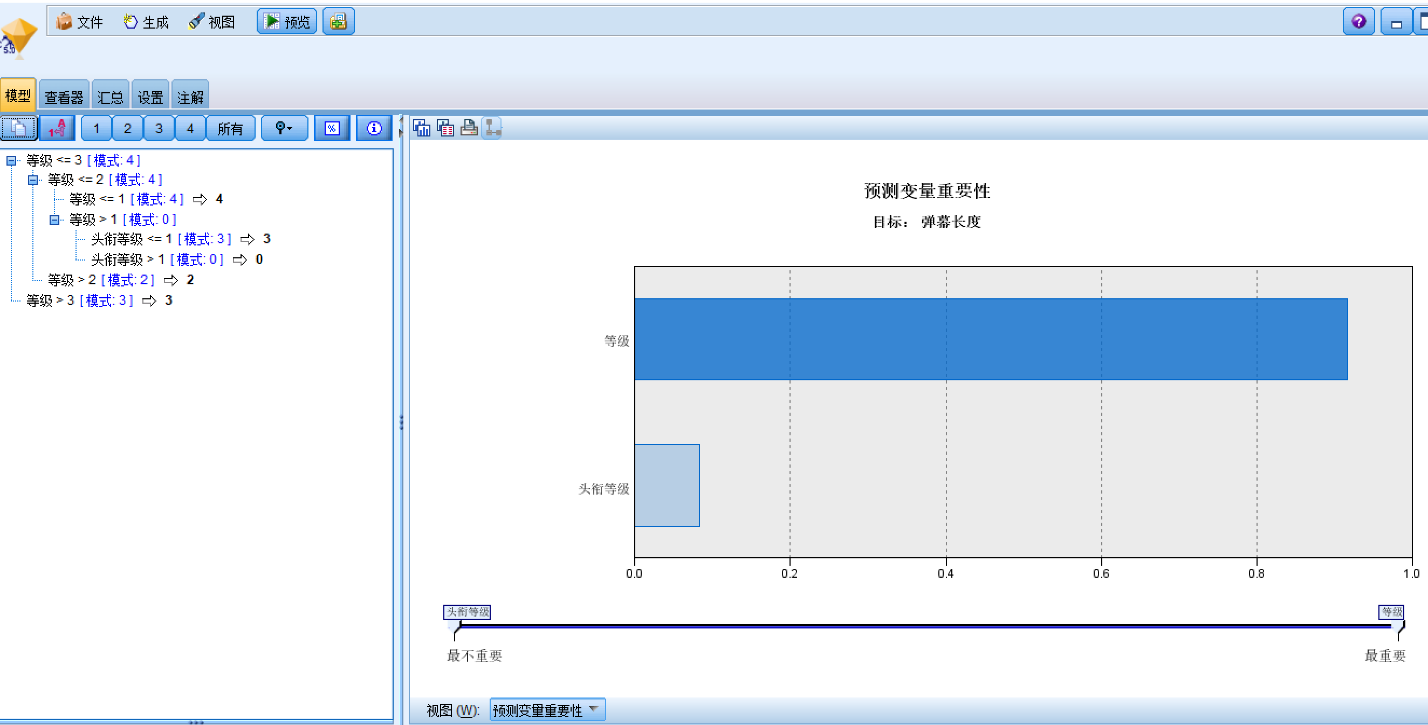
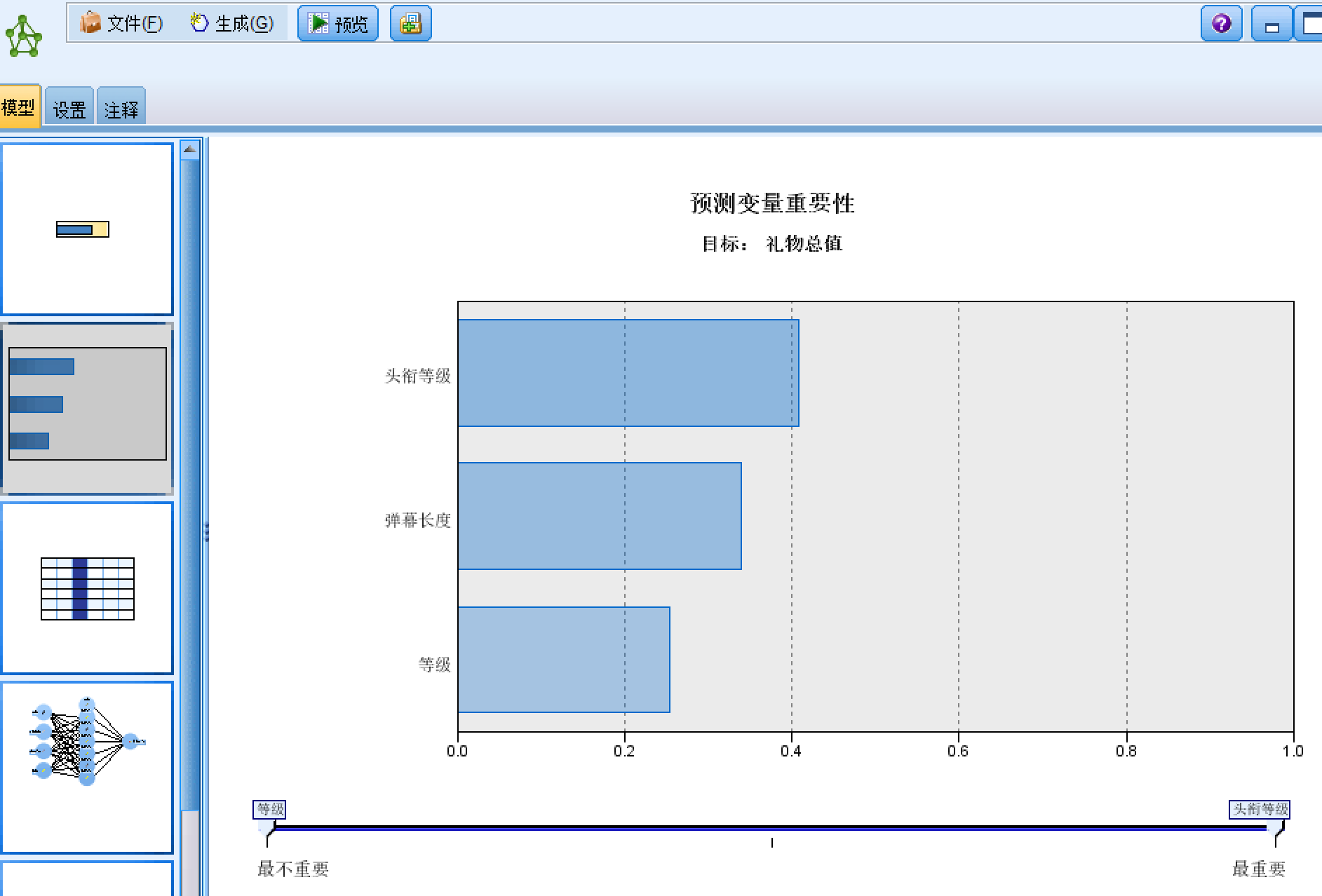
4.4 数据建模 16
4.4.1弹幕信息建模 16
4.4.2礼物与弹幕信息建模 19
4.5 文本分析 20
4.5.1弹幕内容分析 20
4.4.1弹幕内容分析总结 24
第5章 结论 25
参考文献 27
致谢 28
第1章 绪论
1.1 研究背景
1.1.1 电子竞技和网络直播的兴起
由于互联网的普及和网络游戏等各种网络娱乐的方式持续火热,网络直播平台迅速发展并在互联网世界占据了一定的地位。对于网络娱乐和电子竞技来说,直播平台的出现既是一种机遇,也带来了足够的挑战。电子竞技的发展其实已经受到了社会的广泛认可,国家体育总局早在2003年就提出将电子竞技作为中国的第99项体育运动。在第18届亚洲运动会上,由腾讯电竞负责的《皇室战争》、《英雄联盟》和《王者荣耀(国际版)》将作为电子体育比赛项目正式亮相雅加达亚运会的赛场。电子竞技的影响力在这个互联网时代被逐渐放大,这一点不但从电竞被国际奥委会、亚奥理事会承认为体育项目可以看出,而且在电竞开始步入体育行列后很大程度上释放了市场的空间,对于社会的经济利益方面有着极大的正向影响。电竞运动正在走向一条逐步被认可且快速发展的道路,发展潜力巨大。
近几年大热的直播行业因为与电子竞技有着千丝万缕的联系,受到了越来越多的关注。依据CNNCI的数据统计发布的第41次《中国互联网络发展状况统计报告》[[1]],到2017年12月止,我国的网络娱乐用户规模呈现了一个高速增长的态势,这也证明了该行业已经进入了全面繁荣期。网络娱乐应用中网络直播用户规模年增长率最高,达到22.6%,其中游戏直播用户规模增速达53.1%,真人秀直播用户规模增速达51.9%。在这样快速发展的速率之下,网络娱乐的内容规范化进程也在持续进行着,网络娱乐行业以游戏和视频为例,其产生的营业收入也在这股发展的浪潮下快速提升。随着网络娱乐行业营业收入呈现良好的上升趋势,厂商也在逐步加大对行业原创者的支持力度,为网络娱乐在未来能够快速发展打下了坚实的基础。
1.1.2 直播平台
关于目前的网络直播市场,主要有着两大派系,分别为泛娱乐直播和垂直游戏直播。在熊猫、虎牙等热门直播平台中尽管游戏直播吸引了大量的关注度,但实际上其业务范围还是涵盖了户外、体育、二次元等方面,这些都属于泛娱乐直播的范畴。根据国内权威数据机构比达咨询最新的《2018年Q1中国游戏直播市场研究报告》[[2]]显示,在2018年第1季度主要游戏直播APP月均活跃用户数排行中,斗鱼直播月均活跃用户数为2020.2万人,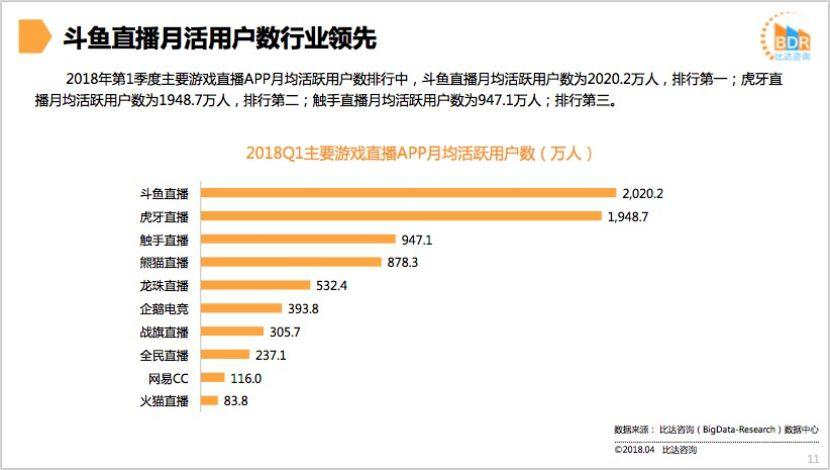 排行第一;
排行第一;
图1.1 比达咨询2018年Q1游戏直播市场研究报告
月活跃用户的数量很大程度上决定了游戏直播平台在直播市场上的地位。本文以斗鱼知名主播大司马的直播间弹幕进行分析为案例,设计一个能系统化分析弹幕信息的算法内容。让游戏主播能够借此了解自己的用户,得知直播吸引用户注意的细节以及用户的付费情况、提高付费转换率的点。
1.2 国内外研究现状
本设计主要涉及两个主要子任务分别是文本分类和弹幕文本挖掘。根据需求并考虑到国内外研究者在该领域的研究现状,本设计将文本分类和聚类模型建立作为本设计的重点研究方向。
1.2.1 文本分析研究现状
在CONSTRUE系统中,人们对事物进行定性分析是采用通过经验和专业知识的方法,即在文本分类中,专业人员手动编写分类规则并进行维护来对文本进行分类。手工方法是有很多缺陷的,比如说,在完成自动分类器时,手工方法必须连接领域专家获取的知识和工程师的知识。如果把这个分类器应用在完全不同的领域时,这些工作必须全部推倒重新构建。
从上个世纪90年代之后,跟随着信息通信技术和信息存储的高速前进,文本信息已经大量地以计算机可读的形式存在,并且每天都有非常庞大的信息库增加。形式所迫之下,在机器自动进化的文本分类方法渐渐地取代了基于知识工程的方法,并成为了现在文本分类的主流技术。
文本分类是计算机学习并监督的过程。在一组被已注释的训练文本基础上找到文本特征中各个类别文本之间的关系模型,然后利用这个关系模型来组成新的文本类别。我们可以使用更正式的方法来描述一个文本分类的过程。假设存在一组文本概念类C、一组训练文本D,两组文本满足一定的概念层次h。那么在客观上,即存在一个目标概念T,它是:
(1.1)
T将文本实例,训练文本D映射到另一个类C。对于D里面的文本内容d而言,T(d)是客观存在且已知的。再经过监督文本集的训练,可以得到一个近似于T的模型H:
(1.2)
对于新的文本集dn,我们采用H(dn)表示其分类结果。我们为了寻找得到和T最相近似的H,建立一个分类系统。用函数表示即为,给定一个评估函数,目标应使T和H满足以下公式:
(1.3)
1.2.2 文本聚类概述及研究现状
将文本对象集合分组成多个由相似文本组成的类的过程称为文本聚类。文本聚类是一种无监督的学习过程。处于同一个集群里的文本彼此都存在较大相似度,而不同集群里的文本则相似度较低。在经过多年关于基于距离基础上的聚类进行研究之后,得到许多成狗的方法,如K-means,K-medoids等。在很多统计分析的软件中都有添加,如S-plus,SPSS,SAS等。在现在的信息时代之中,机器自主学习的文本聚类方法大受欢迎,包括基于密度的方法、基于网格的方法、平面分割方法、聚合方法、基于SOM的方法、模糊聚类方法等已被广泛使用。
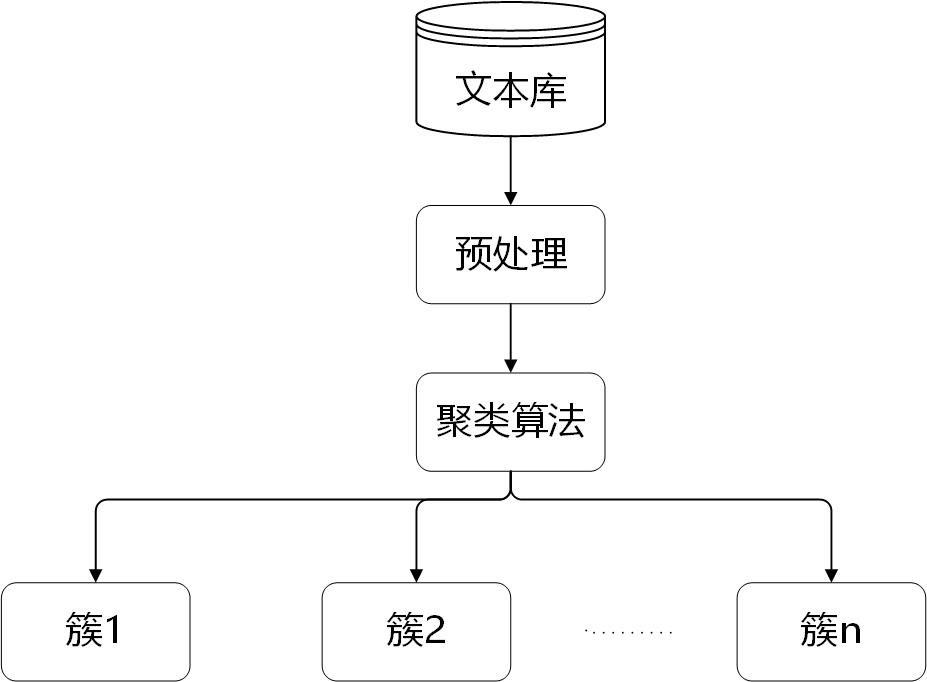 图1.2 文本聚类模型
图1.2 文本聚类模型
图1.2显示了一个典型的文本聚类模型。在文本聚类时,第一步要对库里的文本内容进行预处理,得到文本表示,第二步使用各种聚类算法对文本表示进行分析,第三步通过算法把文本表示聚类为聚类。聚类的原则是:追求更高的类内相似度及更低的类间相似度。
文本聚类在许多地方得到了广泛的应用,如信息检索系统提高了信息检索的效率,组织搜索引擎返回的结果,帮助用户浏览大规模的文本数据,生成Web文本分类树,并帮助用户管理和组织个人电子邮件,电子文档等。
在当前的情况下,文本聚类是一个非常艰巨与困难的问题。一方面是因为它没有任何预测信息,所以要分类的类别信息也是未知的,难以处理未知的信息。而另一方面,亟待解决的问题跟聚类的算法选择是密切相关的。也就是说,存在许多具体问题,会有一些为此目的而开发的聚类算法。因此,很难对不同的聚类算法进行客观,公正,科学的评估。根据近期的文本聚类研究趋向,人们希望能够摆脱基于语法级别的相似聚类,并获得可以相对应理解文本里的内容的聚类方法。最新研究有很多该想法的例子,例:基于概念的文本聚类和基于语义和语用层次的文本聚类。
1.3 研究内容及方法
本设计以关键技术的介绍开始,结合对直播间网页URL爬取和弹幕、礼物文本的预处理,使用聚类分析及文本分类,词性分析等方法对文本进行挖掘,做出用户发弹幕行为及礼物赠送情况的预测,文章在最后对本文的研究内容就行了总结与展望。
设计与关键技术路线如下:
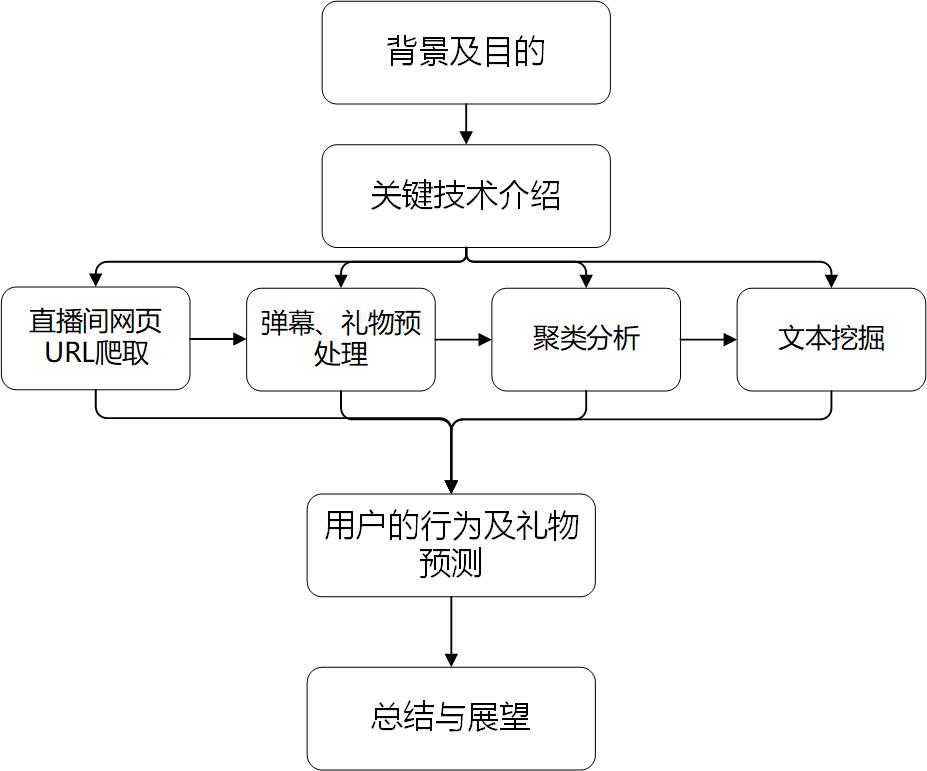 图1.3 设计与关键技术路线图
图1.3 设计与关键技术路线图
第2章 直播间信息采集与内容提取
2.1 直播间弹幕信息采集方法设计
直播平台的迅速崛起导致直播间里弹幕以及礼物信息的短文本信息呈爆炸式增长,如何帮助用户有效地利用直播间的短文本信息资源是本设计研究的动力和目标。文本挖掘就是一个文本获取与有效利用的过程,以网上的数据作为研究对象,从中挖掘有用的信息,并对这些信息进行有效地智能化管理,以提供给用户更直接与数据分析化的内容服务。本设计首先要解决的就是数据源,即从直播间把弹幕文本采集,构成数据库,再对此数据库进行分析。文本采集的过程主要是:查看官方开发文档、分析协议组成、完成登陆授权、获取弹幕信息、保存登录状态、把接受到的byte转换我们识别的编码保存到txt文档中、把txt中的内容导入到Excel中进行数据预处理。
2.2 利用API实时爬取斗鱼弹幕
2.2.1 运行环境
- IDE:Pycharm
- Python3.6
2.2.2实例分析
第一步:查看斗鱼官方的开发文档。

图2.1 斗鱼第三方开发平台API文档部分内容
协议组成:因为要受到TPC最大传输单元(MTU)限制及连包机制影响,斗鱼在应用层协议中需要自己设计协议头,来确保不同消息的隔离性和完整性。
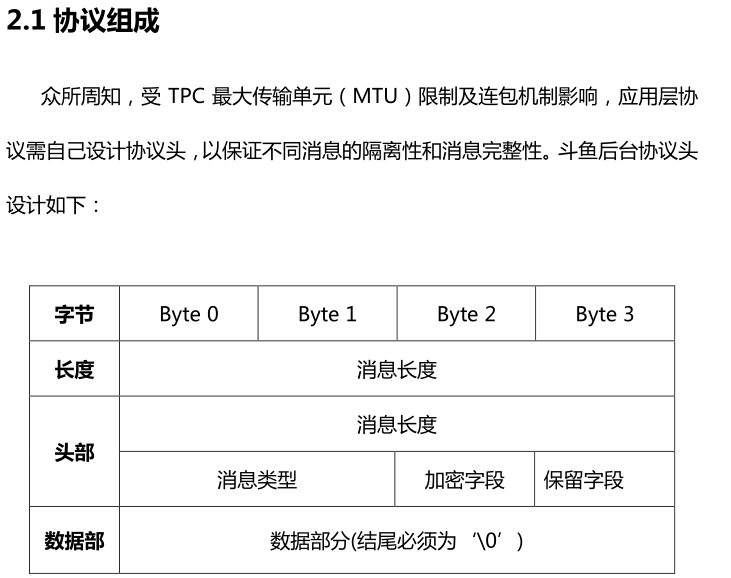
图2.2 斗鱼应用层协议协议头
第二步:登录请求,之后把这个传递给sendmsg即可发送请求:登陆请求消息用于完成登陆授权,完整的数据部分应包含的字段如下:type@loginreq/roomid@=301712/

图2.3 登陆请求字段
第三步:获取弹幕信息type@=chatmsg/rid@=301712/gid@=-9999/uid@=123456/nn@=test/txt@666/level@=1/
表2.1 字段及其说明
字段名 | 字段说明 |
tpye | 表示为“弹幕”消息,固定为chatmsg |
gid | 弹幕组id |
rid | 房间id |
uid | 发送者id |
nn | 发送者昵称 |
txt | 弹幕文本内容 |
cid | 弹幕唯一id |
level | 用户等级 |
gt | 礼物头衔:默认值为0(表示没有头衔) |
第四步:保存登录状态

图2.4 保存登陆状态代码
第五步:转换接受得到的byte为可识别的编码,另存到monggodb或者到txt文档之中。
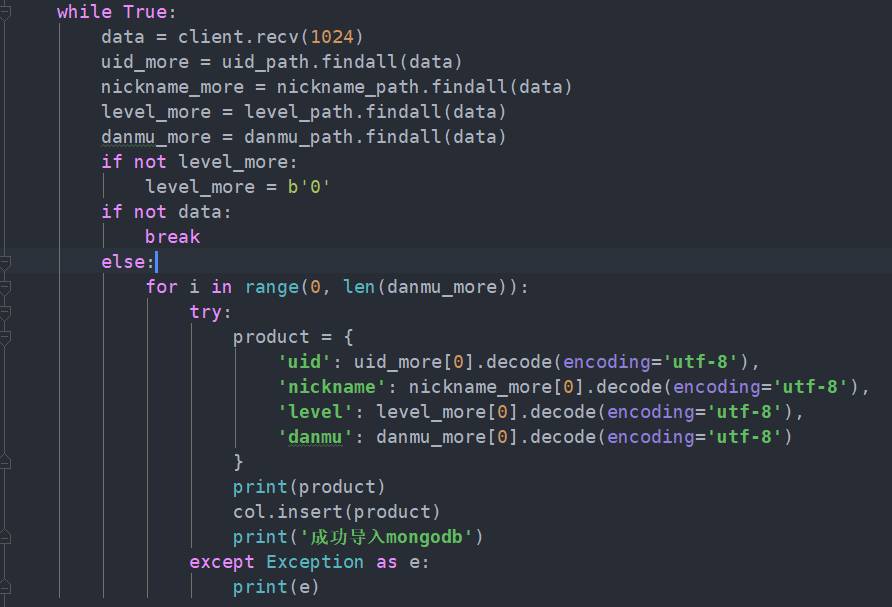
图2.5 爬取并导出代码
 我们通过API从网络上自动地获取页面信息,并且把弹幕及礼物信息逐个存储在txt文件里面。下图为18年5月7日在斗鱼知名主播大司马中提取的弹幕信息。
我们通过API从网络上自动地获取页面信息,并且把弹幕及礼物信息逐个存储在txt文件里面。下图为18年5月7日在斗鱼知名主播大司马中提取的弹幕信息。
图2.6 爬取得到的文本
第3章 文本预处理及分词
3.1 文本预处理
3.1.1 分词
在传统的分词上,一般要分为关键词,去除停用词和英文单词转换三个过程。然而,与英语不同的是,中文汉字之间没有空格符,而且汉语的深度往往导致一个句子中分离出许多不同的术语组合。由此可见,中文的分词难度比英文要大得多。
在中文分词开始时,首先要加载中文词典,并且该词典是通过学习语料库来获得的。将获得的文本格式化,分词算法将用于分词。这里的分词算法主要是对一段文本进行分割,将其分割成单独的句子,按照基本词库划分句子,生成一个由相邻链表表示的单词映射。基于这个词映射,使用动态编程算法,生成分段最佳路径。在此之后,进行一些固有名词的识别,例如:中文地名、人名等。也就是说,所谓的未登录单词同步识别和更新字典。基于更新的字典,可以重新计算最佳分割路径,并且可以保存分词结果。中文分词算法主要有三种类别。
- 基于字符串匹配的分词算法:将准备用于分析的词与事先准备的机器词典中的词相匹配,寻找该字符串,若找到了该字符串,则为匹配成功。
- 基于语义的分词算法:在分析词汇的时候进行语义及句法的分析,并使用语义和句法的信息进行歧义现象的处理。
- 基于统计原理的分词算法:词的置信度由词与词之间相邻的共现频率反映,并且计算与现有文本数据相邻的每个单词组合的频率,统计他们相邻出现的概率。
一般情况下,上述的三种算法可以进行集成和应用,通过综合使用的方法,能够识别新词,并增加歧义排除率。但在实际使用的系统中,我们为了提高切分词的准确率还需要使用一些其他信息。
本设计处理的文本为弹幕,不规范网络用语的短文本。在处理上需要进行分词的词语种类不是很多,故使用新浪微舆情网址的文本挖掘工具进行分词。采用了正向迭代最大粒度切分算法,即多个基本词组合起来切成一个词,进而组成语义相对明确的实体(新词)。该工具使用细粒度和核心智能分词在模式之间切换,并实现了简单的分词歧义消除算法,但不能自动检测词典更新。
3.1.2 停用词处理
在进行文本分类后,文本变成了一个词集,词集之中一般都有许多虚词起到结构性的作用,并没有实际含义,例:介词、副词等。还有另外有一些词在所有文本之中出现的频率都非常高,而且每个文档中出现频率大致相等,这些词对分类的影响也很小,我们统称为停用词。所以,我们为了节省计算机的存储空间,提高系统的运行效率和处理精度,应把这些词从特征集之中去除。为此,在选用停用词的方法上非常重要,其能影响到整个获取的词集的大小及分类结果的准确性。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: