基于Python的用户评论数据分析毕业论文
2020-04-08 13:20:40
摘 要
随着互联网电子商务的迅速发展,淘宝、京东、亚马逊等在线购物网站成为了人们日常生活中购买商品的重要渠道。在网上购物时,买家往往通过这三个途径来获取商品的信息:图片、产品参数、用户评论。与实体购物相比,不能买家清楚地感受实物的各个方面,也不能及时地进行多商品比较,从而使消费者选择自己心仪的商品变得异常困难。因此,用户评论的易读性和丰富性使得评论数据成为了买家是否会购买该商品的重要凭据和标尺。然而,现在网上商城中的商品种类繁多,并且商品对应的评论数量非常大,如果用户需要较为全面地了解商品,那么需花费非常长的时间用于阅读大量评论。虽然各大网上商城都为用户提供了评论分类功能,但仍然无法为用户提供比较直观且全面的信息。
为解决商品评论数量过多造成的问题,本文通过对商品评论进行基于python技术的数据分析,从这些评论中尽可能地挖掘出对消费者和商家有用的信息。本文主要研究的内容如下:1、python爬虫获取大量产品信息和评论数据,将有效信息存储在MySQL数据表中。2、利用pandas和matplotlib中的数据分析及画图工具对其中手机的基础信息进行统计分析并绘制图表。3、通过python中的结巴分词工具,根据词性来将评论内容自动分成一些能表示产品特点的关键词。4、通过python中的词云工具,将筛选出的评价关键词生成词云形式展示出来。5、对统计结果进行分析,进行交叉比对,为之后的消费者提供购买策略,以及为商家卖家提供生产供货等建议。
关键词:Python爬虫;评论;数据分析;可视化
Abstract
With the rapid development of Internet e-commerce, Taobao, Jingdong, Amazon and other online shopping sites have become an important channel for people to buy goods in their daily lives. When shopping online, buyers often use these three methods to obtain product information: pictures, product parameters, and user reviews. Compared with physical shopping, buyers can't clearly perceive all aspects of physical goods, making it extremely difficult for consumers to choose their favorite products. Therefore, the readability and richness of user reviews make review data an important credential and benchmark for buyers to purchase the product. However, there are a wide variety of products in online shopping malls, and the number of reviews corresponding to products is very large. Although the major online shopping malls provide users with comment classification, they still cannot provide users with intuitive and comprehensive information.
In order to solve the problems caused by the excessive number of product reviews, this article analyzes the product reviews based on Python technology and uses these reviews to dig out useful information for consumers and businesses as much as possible. The main research contents of this article are as follows: 1. The python web spider obtains product data and stores these data into MySQL. 2. Use data analysis and drawing tools in pandas and matplotlib to statistically analyze and chart the basic information. 3. Use the Python word segmentation tool, according to part of speech to automatically divide the content of the comment into a number of keywords. 4. Use wordcloud tool to make the evaluation keywords generated word cloud form. 5. Analyze the statistical results and conduct cross comparisons to provide consumers with purchasing strategies and suggestions for merchant sellers.
Key Words:Python web spider;review;data analysis;virtualization
目 录
第1章 绪论 1
1.1 研究背景与研究意义 1
1.2 国内外研究现状 2
1.2.1 国外研究现状 2
1.2.2 国内研究现状 3
1.3 课题研究内容 4
1.4 论文组织结构 5
第2章 相关技术及算法 6
2.1 Python爬虫技术 6
2.1.1 网络爬虫 6
2.1.2 Requests库 6
2.1.3 正则表达式和Json模块 7
2.1.4 抗“反爬虫”策略 7
2.2 Python数据处理工具 8
2.2.1 Pandas 8
2.2.2 Matplotlib 8
2.3 MySQL数据库 8
2.4 结巴分词(jieba)工具 9
2.4.1 TF-IDF算法 9
2.4.2 TextRank算法 10
2.5 词云(wordcloud)工具 10
第3章 需求分析及总体设计 11
3.1 需求分析 11
3.1.1 研究对象依据 11
3.1.2 数据细分 13
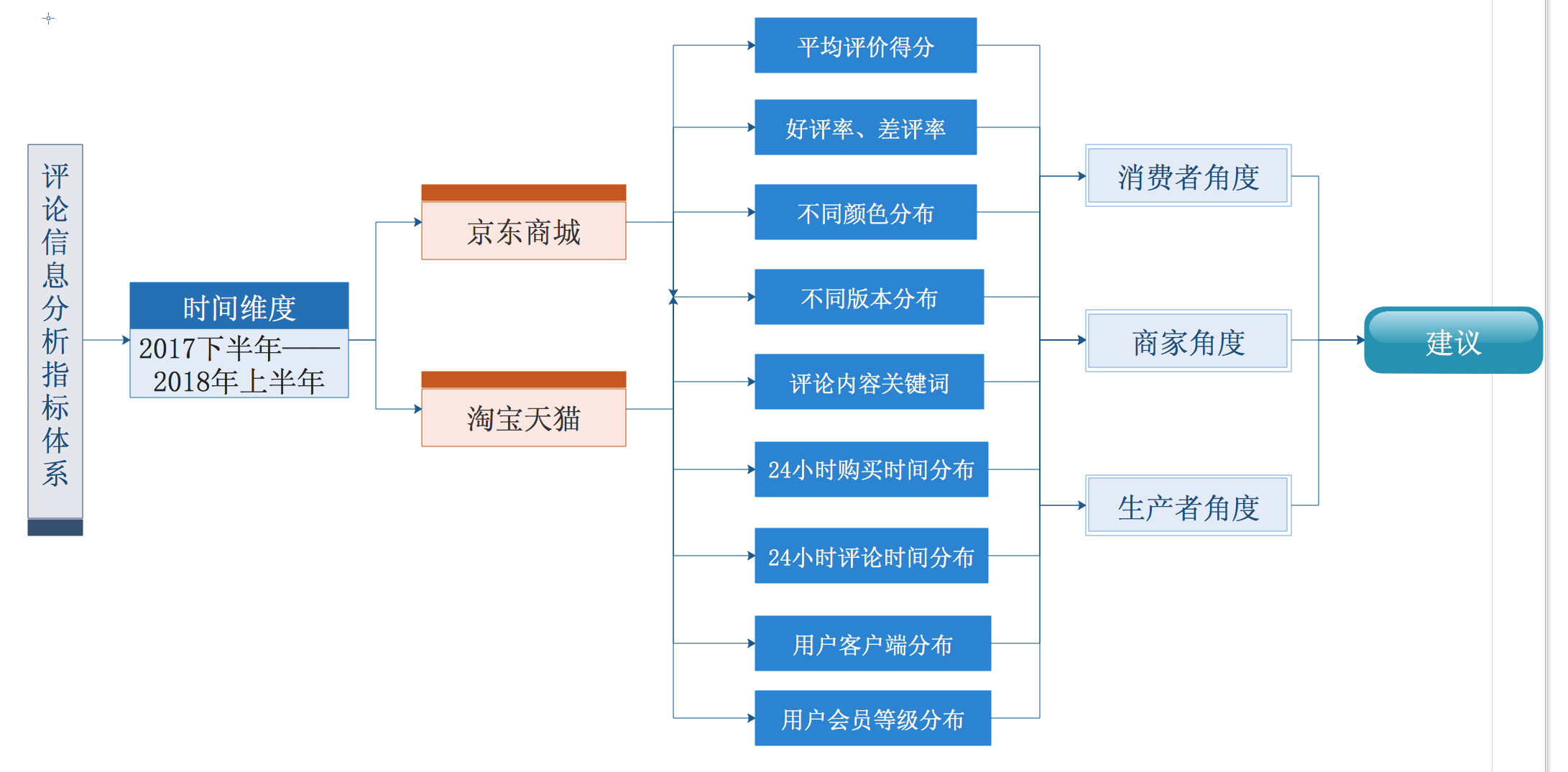
3.1.3 数据分析指标体系 15
3.2 可行性分析 16
3.2.1 数据来源的可靠性 16
3.2.2 数据内容的真实性 17
3.2.3 数据分析结果的准确性 17
3.3 数据库设计 18
3.3.1 手机总体概述表 18
3.3.2 手机评论信息表 19
3.3.3 用户词典和停用词表 19
3.4 软件架构与开发平台 20
第4章 数据处理——以小米Mix2手机为例 21
4.1 数据的获取 21
4.1.1 查找评论数据链接 21
4.1.2 爬取评论数据 22
4.1.3 评论数据存储 23
4.1.4 抗“反爬虫”操作 25
4.2 手机相关属性统计 26
4.3 评论内容关键词提取 35
4.3.1 结巴分词工具的分词功能 35
4.3.2 基于TF-IDF算法的关键词抽取 36
4.3.3 基于TextRank算法的关键词抽取 37
4.4 其他说明 38
第5章 可视化结果分析 39
5.1 总体情况分析 39
5.2 手机相关属性分析 40
5.3 评论内容分析 47
5.3.1 名词性关键词 47
5.3.2 形容词性关键词 48
第6章 结论与展望 50
6.1 数据分析结论 50
6.1.1 对消费者的建议 50
6.1.2 对生产者的建议 51
6.1.3 对商家的建议 51
6.2 课题研究的总结 52
6.3 对未来的展望 52
第1章 绪论
1.1 研究背景与研究意义
随着互联网电子商务的迅速发展,在线支付功能的便捷性和安全性不断提高,物流快递行业的迅速兴起,淘宝、天猫、京东、亚马逊等在线购物网站成为了人们日常生活中购买商品的重要渠道,人们可以买到几乎任何想要买到的东西,例如不易存储和运输的生鲜水果、复杂精密的电子产品、大型厚重的家居用品,甚至各类服务如代购、翻译外文、修改文稿等等,这些现在都可以通过网上购买的方式来获取。
据中商产业研究院统计数据显示,截至2017年12月,我国网络购物用户规模达到5.33亿,较2016年增长14.3%,占网民总体的69.1%。2011-2017年网络购物用户规模快速发展,2011-2017年增加了3.4亿人,年均复合增长率为118.4%。随着网上购物人数的迅速增长,可供选择的商品越来越多,如何在网上购买到物美价廉的产品也会被越来越多的人所重视。
在超市、商城等实体店里购买商品时,买家可以零距离地接触商品,对于一些需要上手才能感受到的商品特点来说会更加的直观,如果遇到对一些参数不懂的可以询问导购人员。而在网上购物时,买家往往只能通过这三个途径来获取商品的信息:图片、产品参数、用户评论。与实体购物相比,经过商家美化的图片并不能让买家清楚地感受实物的各个方面,比如手感、质感等,也不能及时地进行多商品比较。产品参数有时候会过于专业化使得大部分普通买家不能真正看懂其意义,从而使消费者选择自己心仪的商品变得异常困难。因此,用户评论的易读性和丰富性使得评论数据成为了买家是否会购买该商品的重要凭据和标尺。
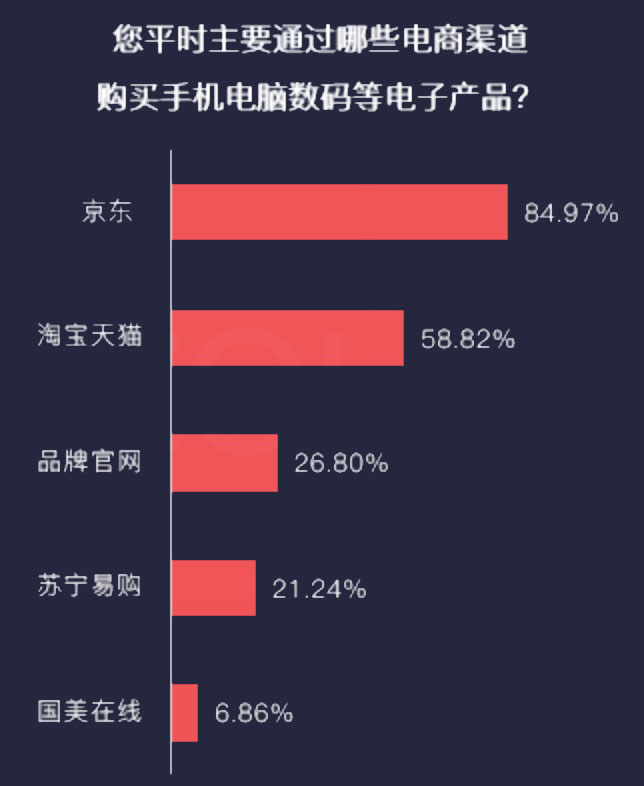
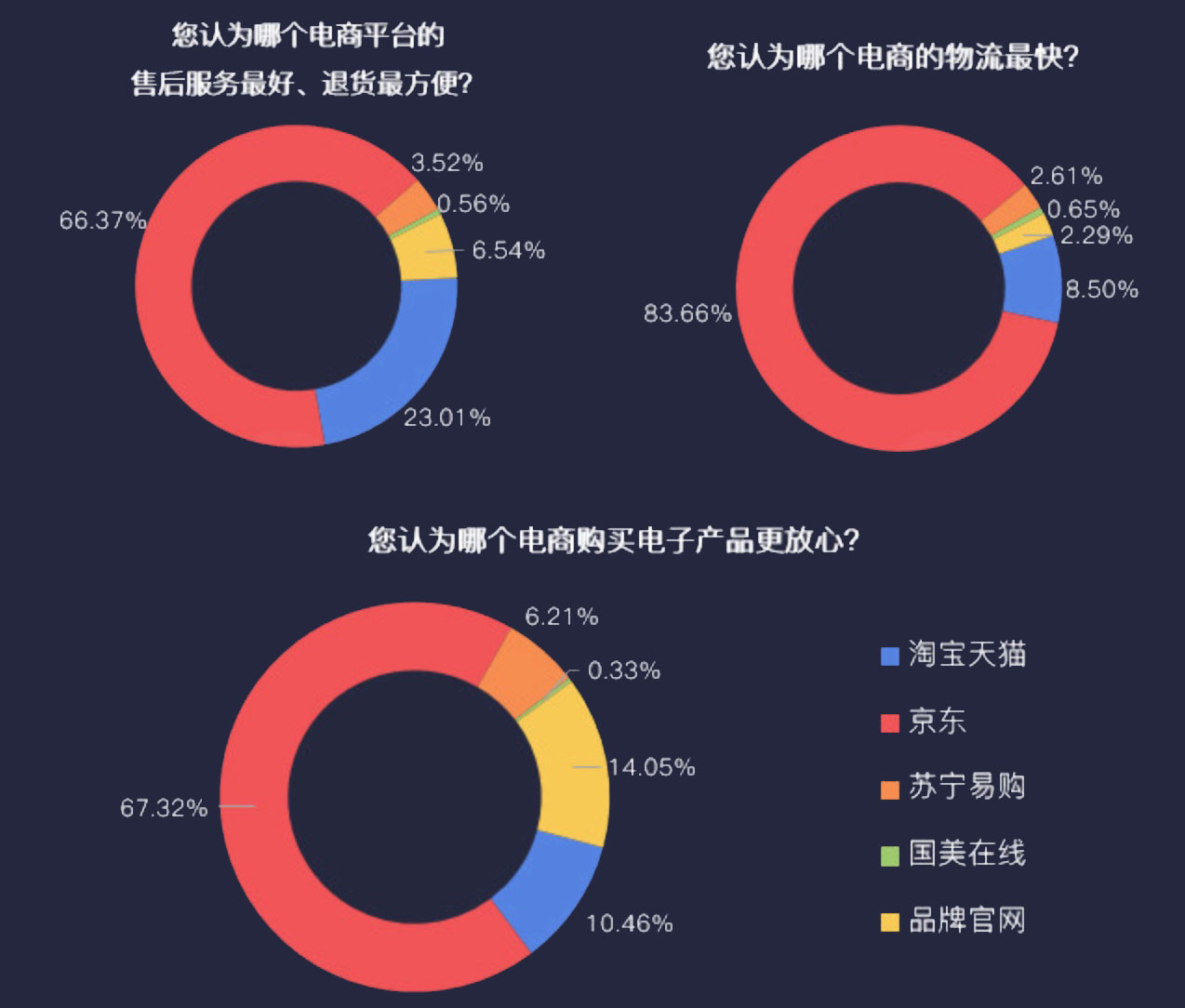
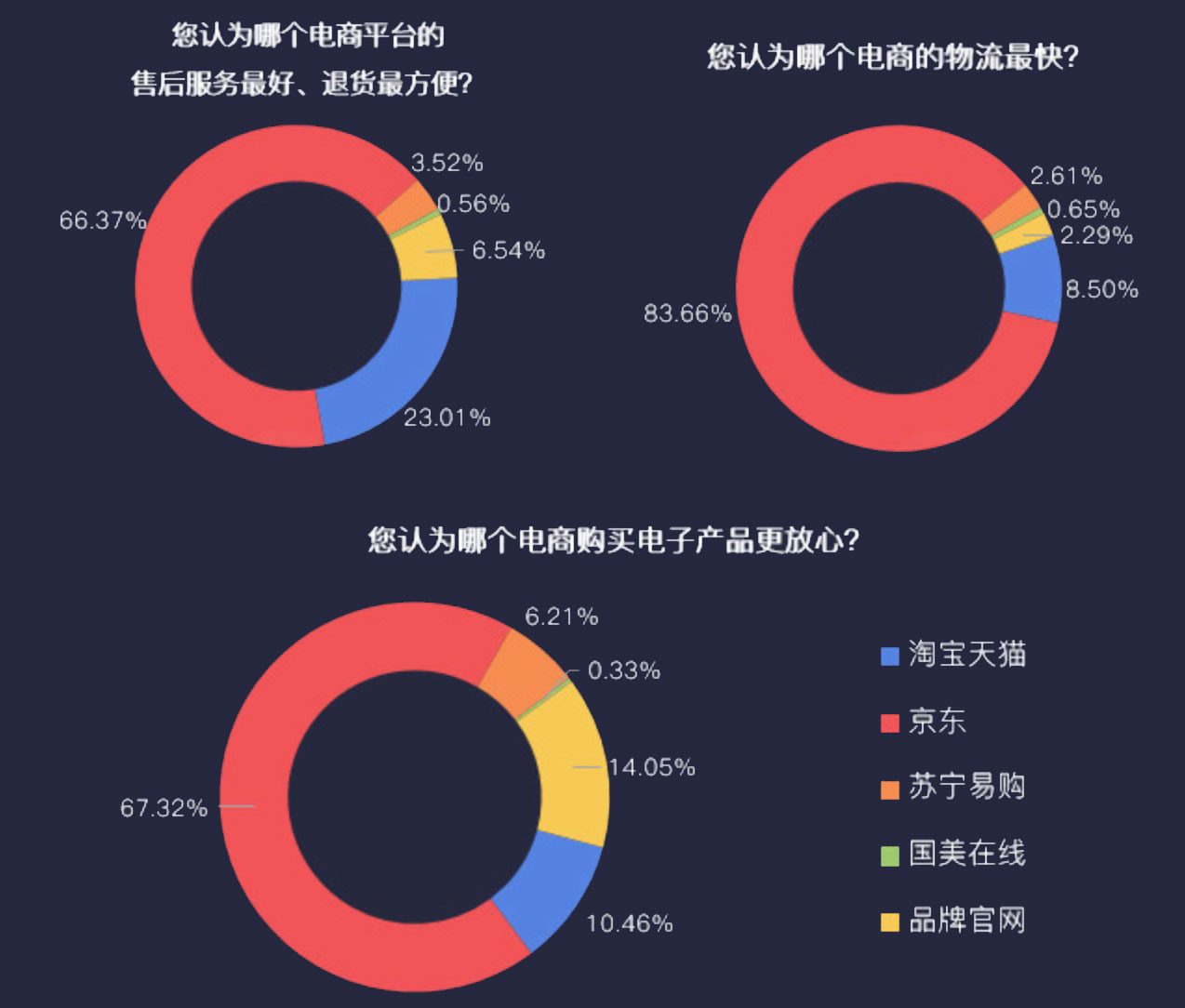
根据中商情报网《2017年用户网购行为调查分析报告》[8]显示,在网购手机、电脑等电子产品时,有超过七成的用户最喜欢通过查看商品评论来了解商品,这说明了电商网站的评论信息对消费者购买决策的影响。另外,在报告中还指出,消费者在网购产品时,最看重的是产品质量、价格、品牌影响力、卖家信用、卖家等级等,这些信息大部分都可以从用户评论数据中客观的表现出来,因此对产品评论数据进行分析是十分重要的。
目前主流的网上商城都为用户提供的商品评论功能,用户可以在网上发表自己对所购买商品的评价,这既可以向网上商城和商品卖家提供购物反馈信息,也可以为其他用户提供更丰富的商品信息。对于消费者,可以从这些评论中借鉴之前用户对该产品的评价,决定自己的购买策略。对于商家,从这些评论中得到用户对产品的反馈,有利于改进自家产品的不足。然而,现在网上商城中的商品种类、数量繁多,并且商品对应的评论数量非常大,这些评论信息以爆炸式的速度在增长,一些热门商品的评论数量可达到几十万条。这里就存在一个很大的问题,如果用户需要较为全面地了解商品,那么需花费非常长的时间用于阅读大量评论,并对其内容进行概括总结。虽然各大网上商城都为用户提供了评论分类功能,即根据用户对商品的评分,将评论划分为好评、中评、差评三种类别,用户可以选择性地查看自己感兴趣类别的评论,但仍然无法为用户提供比较直观且全面的信息。
为解决商品评论数量过多过杂对消费者网购所造成的问题,本文通过对商品评论进行基于Python技术的数据分析,从这些评论中尽可能地挖掘出对消费者、生产者和商家有用的信息,一是为消费者提供购买策略,二是为生产者提供生产供货等建议,三是对京东商城等商家提供平台维护、广告推送等意见。
1.2 国内外研究现状
1.2.1 国外研究现状
国外对评论数据的分析研究以Twitter的情感分析和亚马逊ARA分析工具为例,对国外这方面技术的运用进行阐述。
(1)Twitter的情感分析
在那些提供微博服务的热门网站上,如国外的Twitter、Facebook和国内的微博、人人网等,每天都有数以万计的微博消息产生。这些消息的作者记录自己的生活,分享对不同话题的看法,并讨论当前的问题。消息的内容包括讨论自己使用的产品和服务,或者是表达自己对某一现象的看法,甚至是对不同政治和宗教观点,这些网站上的消息已经成为人们评论与情感信息的宝贵来源,对这些数据进行分析能够有效地用于营销和社交研究。Twitter网站就利用情感分析工具对其推文评论内容进行数据分析,具体的技术案例如下:
Go,Bhayani and Huang(2009)[12],他们将符合检索词的推文划分为正面情绪和负面情绪。他们从Twitter的推文中利用脚本来自动采集数据,以构建训练数据集。为了收集含正面情绪和负面情绪的推文,他们在Twitter中使用表示快乐和悲伤的表情符合进行检索。代表正面情感的:" :)"、" :-) "、" : ) "、" :D "、" =) "等,代表负面情感的:":("、":-("、":("等。
他们尝试了各种特征——一元词串、二元词串、词性,使用了不同的机器学习算法训练分类器——朴素贝叶斯、最大熵模型、可伸缩向量机,并通过统计公共语料库中正面与负面词语的数量,和基准分类器的分类结果进行了比较。他们报告称,词性标注与仅使用二元词串对结果并没有帮助,朴素贝叶斯分类器的效果最好。
Park and Paroubek (2010),Koulompis, Wilson and Moore (2011)[12],他们认为,在推文中有许多非正式且富有创造性的语言,这些独特的语言使面向推文的情感分析任务明显不同于其他情感分析。他们在之前的话题标签和情感分析上的工作构建一种新的分类器,通过爱丁堡的Twitter语料库找出最频繁使用的话题标签,人工地来划分这些标签,并反过来使用这些标签对推文进行分类。除了使用n元词串特征和词性特征,他们还根据现有的MPQA主观词汇和网络俚语字典,创建了一个特征集。他们报告称,结合n元词串特征和词汇特征,模型能够取得最好的结果,然而使用词性特征则会导致模型准确率下降。
(2) 亚马逊ARA分析工具:
亚马逊一直倡导“力争成为全球最以顾客为中心的企业”,正是因为有了这层次念,亚马逊获得越来越多的消费者的承认和相信,亚马逊平台的体量一步步强大,更多的卖家跟着亚马逊的成长而受益。亚马逊已经进入了全新的数据化精细运营时代,谁能够更深一层挖掘数据、更加精准的分析数据,谁就能够信心十足地霸占市场领导者的地位。
Amazon ARA的全称是Amazon Retail Analytics,中文名是亚马逊零售分析,是Amazon自有的销售数据分析工具。通过ARA你可以看到Amazon全网的销售分析数据。通过ARA工具,不仅可以对你现在的销售起到指导作用,例如:分析你的竞争对手,分析购买你产品的用户行为和消费者对你卖的哪些产品更感兴趣。还可以为你将来的发展方向提供帮助,比如:现在什么产品热销,哪里需要改变等。
1.2.2 国内研究现状
随着互联网的普及,很容易在网络上找到关于Python的爬虫以及数据分析的教程,比如coursera上南京大学的《用Python玩转数据》。也有很多专业人士开设博客,撰写相关课程,比如莫烦python,廖雪峰python等,这些丰富的资源使得这门技术变得很容易获取。另外,国内也出现了许多可替代代码实现的工具,如八爪鱼采集器、爬山虎采集器、网络神采等等,这些工具的优点在于学习成本低,使用流程十分简单,纯粹可视化操作,能够根据教程快速地搭建采集系统。采集到的数据还能直接导出CSV、Excel格式文件或者直接导出到MySQL、SQLServer等数据库中。它还提供云采集技术,降低了获取数据的硬件成本。
1.3 课题研究内容
为解决商品评论数量过多过杂对消费者网购所造成的问题,准确地从商品评论数据中提取出有用的信息,分析出合理的结果,为之后的消费者、商家和生产者提供建议,本文以目前几款主流的手机旗舰产品为例,通过Python语言技术和MySQL数据库技术对其产品信息和用户评论内容进行数据分析,主要基于手机产品的相关属性的统计和用户评价内容的分析两项核心工作,最终结果将可视化展示出来,便于更加全面地、形象化地展示出每个产品的客观评价结果。针对以上本课题的研究目的,本文的主要研究内容分为以下几点:
(1)python爬虫获取大量产品信息和评论数据:产品信息和评论数据作为本课题研究的准备工作,获取来源为python爬虫技术。利用python脚本来模拟浏览器行为,浏览相关网页并抓取HTML源代码,利用正则表达式对我们所需要的商品信息进行筛选、截取,将有效信息存储在MySQL数据表中,以备之后的数据分析工作使用。
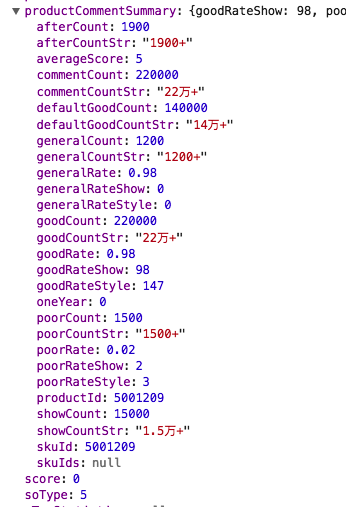
(2)对产品的基本信息统计分析:利用Python中的Pandas数据分析工具数据库中数据,再利用Pandas和Matplotlib中的数据分析及画图工具对其中手机的基础信息进行统计分析并绘制出柱状图、拼图、折线图等图表。具体的分析指标为:颜色、版本、评分、购买时间、买家会员等级以及买家客户端等等。对这些客观的属性分布情况进行统计分析,可视化的展示出来,进而方便接下来分析其对消费者购买的影响。
(3)对评论内容进行分词,提取关键词:将爬取下来的评价内容转换为string格式,方便进行分词处理。这项工作主要通过python中的结巴分词(jieba)工具,根据词性来将评论内容自动分成一些能表示产品特点的关键词,主要是分为了名词和形容词两项,并对其重要程度排序。关键词通过python中的词云(wordcloud)工具,将筛选出的评价关键词生成词云形式展示出来。
(4)可视化结果分析:首先对同一产品的不同颜色、版本等信息的统计结果进行分析,得出该产品的一些特点、结论。然后再将不同手机的同一属性进行交叉比对,分析出不同产品之间的区别,为之后的消费者提供购买策略,为生产者提供生产供货等建议,对京东商城等商家提供平台维护、广告推送等意见。
1.4 论文组织结构
本论文一共分为六个章节完成,具体的内容和结构安排如下:
第一章是绪论部分。主要包括该课题的研究背景和意义,说明了对商品评论数据进行分析的现实意义;国内外相关研究现状的介绍;最后总结了论文的主要研究内容和组织结构、章节安排。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: