面向主题搜索的城市垃圾危机网络爬虫软件设计毕业论文
2020-04-08 12:37:06
摘 要
我国城市化的迅速发展带来了生活便利的同时,也在很大程度上造成了城市垃圾危机、邻避危机等问题,如何系统化、科学化的解决城市垃圾危机成为我国正在面临的难题。当下城市垃圾治理缺乏权威的数据作为支撑,没有系统化的决策支持平台,导致决策的不科学性。本设计创造性的应用现代技术,构建具有数学统计意义的城市垃圾危机知识库,并为治理决策提供一定意义上的研究基础。
本设计基于Python技术开发数据采集、处理、分析系统,完成对城市垃圾危机知识库的构建,并开发案例搜索演示网站,划分案例类别,为进一步研究提供基础。本设计综合运用网络爬虫、语义识别、文本挖掘、文本聚类、相似度计算等技术,实现城市垃圾危机相关数据获取、处理,并引用“名利”空间模型,确定案例的名利关系。本设计获取的高可用性城市垃圾危机数据将能够为城市垃圾危机治理决策提供较为权威的数据基础,此外,通过案例匹配寻找共性的研究方法也将对城市垃圾危机转化研究提供一定的指导意义。
关键词:城市垃圾危机;网络爬虫;文本聚类;案例匹配;名利关系
Abstract
The rapid development of urbanization in our country brings convenient life at the same time, also to a great extent, the city garbage crisis, adjacent to avoid crisis and other issues, how to the solution of the systematic and scientific city garbage crisis become a problem of our country is facing. At present, there is no authoritative data to support urban garbage management and no systematic decision-making support platform, which leads to the unscientific decision-making. This design creatively applies modern technology, constructs the knowledge base of urban garbage crisis with mathematical statistics significance, and provides a certain research foundation for the governance decision.
This design is based on the Python data acquisition, processing, analysis on the development of technology system, construction of urban garbage crisis knowledge base and the development case search demonstration sites, case classification, provide the basis for further study. This design integrated use of web crawler, semantic recognition, text mining, text clustering, similarity calculation, such as technology, realize the city garbage crisis related data acquisition, processing, and cited "fame" space model, determine the case of fame and fortune. This design to obtain the high availability of city garbage crisis data will be able to provide urban garbage crisis governance decisions more authoritative data base, in addition, through the study of case matching to find common method will also provide a certain amount of research on transformation of city garbage crisis.
Key Words:Urban garbage crisis;Web crawler; Text clustering; Case matching; Fame and fortune relationship
目 录
第1章 绪论 1
1.1设计的目的及意义 1
1.2国内外研究文献综述 2
1.3设计内容 3
第2章 相关技术及模型 4
2.1网络爬虫的应用及发展 4
2.2文本挖掘与词表构建 4
2.2.1文本挖掘 4
2.2.2词表构建 5
2.3危机转化“名利”空间模型 6
第3章 系统分析 8
3.1系统目标分析 8
3.2系统流程分析 8
3.3功能模块分析 9
第4章 系统详细设计 10
4.1智能抓取网络爬虫 10
4.1.1爬取策略 10
4.1.2 Scrapy爬虫框架应用 11
4.1.3二重筛选算法 11
4.2数据清洗和预处理 11
4.2.1正文提取 11
4.2.2关键词分析 13
4.2.3词义相似替换 14
4.3数据分析 15
4.3.1数据矢量化 15
4.3.2 K均值聚类 15
4.3.3案例相似度计算 16
第5章 系统实现 17
5.1采用的技术方案及措施 17
5.2开发环境说明 18
5.3功能模块实现 20
5.3.1网络爬虫模块 20
5.3.2数据处理模块 22
5.3.3数据分析模块 27
5.3.4案例搜索模块 32
第6章 全文总结与研究展望 35
6.1全文总结 35
6.2设计创新点 35
6.3研究展望 36
参考文献 37
致 谢 38
- 绪论
1.1设计的目的及意义
1.1.1设计目的
面向主题搜索的城市垃圾危机网络爬虫软件主要是通过网络爬虫建立城市垃圾危机网络知识库,并实现案例搜索分析及模型比对,进而为城市垃圾危机治理者提供决策指导的程序系统。
本设计的主要目的是通过网络搜索引擎技术和专家指导的方法,采集与城市垃圾危机相关的新闻数据、部门数据以及技术数据。此外,根据“名利”空间模型,通过案例向量化实现相似度计算,进而达成指导现实的目的。
1.1.2设计意义
(1)理论价值
当下我国对城市垃圾危机的治理决策普遍停留在经验治理层面,缺乏系统化的治理决策方法,在城市垃圾危机治理过程中缺乏权威的数据支撑,常导致治理手段不科学、不合理的现象,造成城市垃圾危机转化成果不佳等现象。本设计正是针对这种现象,创造性的应用数据挖掘与分析技术,实现对城市垃圾危机案例的特征分析,从而为进一步研究城市垃圾危机转化路径提供研究基础。
本设计采用网络爬虫技术,获取网络上城市垃圾危机相关数据,通过文本挖掘技术、文本聚类等技术构建城市垃圾危机知识库,获取城市垃圾危机转化的研究数据基础,并通过案例匹配技术实现相似典型案例查找,从而获取现实治理中城市垃圾危机的共性特征,进而探究危机转化对策。本设计中采用的由共性寻找个性的研究思路,分析具体城市垃圾危机事件的特征,对于设计城市垃圾危机转化与决策系统有一定的理论意义,可以提供一种可行的思路参考。
(2)实践指导意义
城市垃圾危机管理研究需要庞大的数据基础,而城市垃圾危机相关数据库极为少见,需要从多个数据库和信息系统中提取数据,涉及的数据量大、来源分散、数据异构性强、数据形式多样,对城市垃圾危机管理研究造成了极大的麻烦。因而,建立以城市垃圾处理和管理为核心,具有数据结构化、信息分类、筛选冗余、动态抓取等功能的城市垃圾危机网络爬虫软件,能够高效便捷获取城市垃圾危机相应的主题信息,将对城市垃圾危机管理研究提供极大的数据支撑,具有一定的现实意义。
面向主题搜索的城市垃圾危机网络爬虫软件的设计是建立城市垃圾危机决策系统的必要支撑部分,通过爬虫抓取网络上城市垃圾危机信息,并对数据信息进行筛选后形成的数据库是城市垃圾危机网络的重要知识库,在一定意义上为现实中的治理案例提供参考。此外,面向主题搜索的案例分析功能,根据名利关系模型,利用案例向量化方法,通过相似度比对得出最相似的名利关系模型,这将为治理者分析决策提供更加科学权威的理论和数据支撑。
1.2国内外研究文献综述
垃圾处理是任何一个国家都绕不开的问题,人口密度越大,垃圾问题越严峻。2014年5月,“余杭事件”再次将垃圾焚烧这个既传统又现代的问题,推向了风口浪尖。自2014年以来,杭州超过10%的垃圾年均增长率,没有合适的土地再建垃圾填埋场,超负荷运转的垃圾焚烧厂等都是我们正在面临的难题。“垃圾围城”不只是一个杭州城市的难题,全国2/3的城市都面临着类似危机和垃圾处理困局。
显然,我国的城市垃圾危机已经成为严重的社会问题。赵岚, 关玉转认为随着我国城市化进程的加快,城市规模不断扩大,城市生活垃圾的产生量也急剧增加,垃圾围城已经逐渐演变成为垃圾危机,越来越威胁到人们的生存环境,并成为严重的社会问题。城市垃圾要如何处理,采用何种方式处理,不仅是政府面临的一大难题,也成为社会民资源化的一些对策及建议。[1]
但是我国的应对垃圾危机的治理手段仍停留在政府治理层面,缺乏科学的预防与治理系统。对于城市垃圾危机中邻避问题的处理,当下我们需要完善的地方还很多,常亮认为对邻避冲突问题的治理,需要从制度建设、机制建设、社会治理能力建设、社区自治能力培养、风险意识培育五个方面思考,探究化解邻避冲突的路径。[2]刘洁认为要采用理论研究、模型建立算法设计、实例分析等方法,建立了城市生活垃圾收运系统优化模型,通过模型应用以期兼顾社会环境各因素的同时实现收运系统经济、高效、稳定运行,为优化收运设施选址、制定垃圾物流分配方案和收运路线计划提供科学依据。[3] 穆罕默德·马斯理认为应运用系统工程中的灰色预测模型对武汉市今后五年的城市垃圾产生量进行预测,并对武汉市的垃圾物流在产生源与各处理设施之间的分配进行研究,确定不同垃圾处理方式(包括焚烧、发电、堆肥、回收利用、填埋)所占比重,从而为优化武汉市城市生活垃圾管理系统,促进生活垃圾减量化、资源化、无害化的进程提供决策依据。[4]
目前,城市垃圾危机管理的研究在国内外取得了一定的发展,但是仍存在一定的不足。其主要思路是寻求城市垃圾危机管理达到危害最小化的策略与路径,但是这种思路存在一定的局限性,不利于真正达到转化危机的目的,缺乏从危机转化视角进行的研究。[5]此外,现阶段的研究大部分停留在理论方法上,缺乏严谨的数据支撑,未能建立专业的城市垃圾危机管理的数据库,倘若能够结合数据挖掘与分析技术,将对实现深度探索、问题揭示、原因剖析等方面大有帮助,并能有效的为危机解决方案提供可靠的数据和知识支撑。因此,建立一个城市垃圾危机网络爬虫软件,将为城市垃圾危机转化管理提供数据和智力支撑。
1.3设计内容
面向主题搜索的城市垃圾危机网络爬虫软件设计的基本内容主要分为两个方面,一方面是建立城市垃圾危机知识库,另一方面是提供面向主题搜索的案例决策支持。
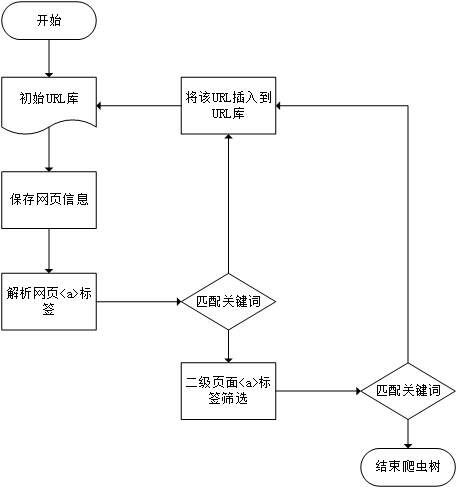
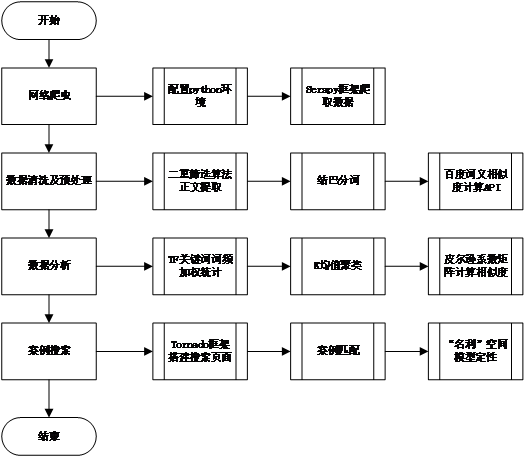
城市垃圾危机知识库的建立主要通过网络爬虫的方式来实现,结合人工辅助分析,通过网页正文提取,关键词分析,词义相似度计算三个步骤,得到可用于进一步数据分析的高可用度数据。具体设计内容如下:
(1)爬取数据。利用网络爬虫,并设计抓取模型的要素和框架,自动抓取万维网信息的程序或者脚本,实现城市垃圾危机知识的获取;
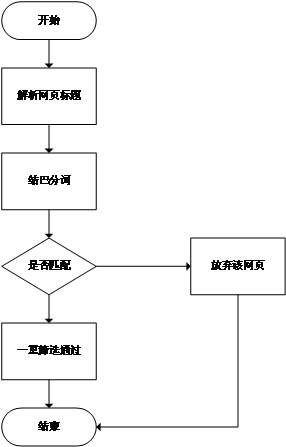
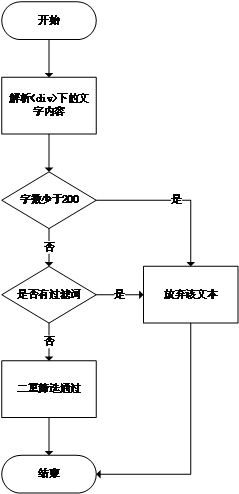
(2)数据清洗。基于机器学习算法,使用先进的分词工具,对标题进行分词处理,去掉标题中不含“城市垃圾危机”关键词的文章;对网页内容进行结构筛选,去掉长度过短的正文,去掉不含关键词的正文,从而获得“城市垃圾危机”事件相关的事件。
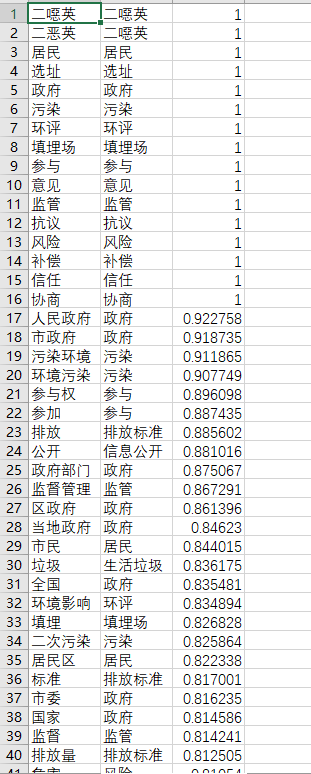
(3)词表构建。使用中文分词系统对文章进行分词,通过高效的词法分析技术,分析得出所有文献的高频词。并通过人工辅助,确定“城市垃圾危机”事件的20个关键词表。
(4)语义判断。确定关键词表后,对文章进行分词,使用百度提供的AI智能接口,计算文中所有词语和关键词的相似度,并使用词义替换算法判断词语和关键词是否可替换,对所有可替换的词语进行关键词替换。
(5)案例矢量化。将案例数据按照关键词表和对应的权重进行矢量化,使得文本数据具有数学和统计意义;
(6)文本聚类。根据矢量化数据,将案例聚类综合为4类,并得出4种类别的关键词权重数据。分析得出了四种具有典型代表“城市垃圾危机”事件;
(7)相似度计算。计算各案例与4种聚类的相似度,得出各案例的最匹配聚类,并获取4种聚类的最相似案例作为典型案例。
提供面向主题搜索的案例决策支持,基于“名利”空间模型,通过案例相似性比对,给予案例近似的名利空间,进而为决策提供支持。具体内容如下:
(1)“名利”模型。运用“名利”空间模型指导城市垃圾危机治理决策;
(2)案例匹配。匹配与被搜索案例最相似的聚类,并展示典型案例,确定“名利”空间象限。
- 相关技术及模型
2.1网络爬虫的应用及发展
随着互联网网络的不断革新,网络爬虫逐渐发展壮起来,万维网因其承载着大量信息,网络爬虫的使命成为如何有效提取和提取这些信息。网络爬虫的定义是一种为达到用户获取网络信息的目的,按照一定的规则自动地抓取万维网信息的程序或者脚本。[6]网络爬虫被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。不仅如此,它还可以通过自动采集页面内容的供搜索引擎做进一步处理的方式,使得使用者能更快的获取到他们需要的信息。简单来说,网络爬虫就像是一个机器人,能够帮助使用者把别人网站的信息弄到自己的电脑上,它可以实现自动访问互联网并将网站内容下载下来,再进行一些过滤,筛选,归纳,整理,排序等操作。
网络爬虫有一个很生动的英文名叫做web spider,显然我们把互联网当成一个蜘蛛网,而爬虫脚本就是在网上爬来爬去的蜘蛛了。就像蜘蛛一样,网络爬虫首先是通过网页的URL来寻找网页,由网站的一个特定页面开始爬取网页的内容,并查找在网页中的其它链接地址,接着根据这些链接地址获取下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。[7]根据这种原理,爬取整个网络也不是难事。只要把整个互联网当成一个网站,爬虫就可以用把网络上所有的网页都爬取下来。
网络爬虫爬取之初需要定义一个统一资源地址,我们简称为“种子”,其实就是一串URL列表。网络爬虫会首先访问统一资源地址,获取种子,它会辨别改网页上所有的URL,并通过待访列表储存这些URL,也就是即将爬取的“爬行疆域”。[8]之后网络爬虫会按照一种特定的方法循环,访问该列表。网络爬虫再爬取过程中通常会下载被爬取网页上的信息,通过这种方式来存贮网页数据,以给用户查看,也可以通过保存“快照”的方式,实现对网站上实时信息的查看。由于当今互联网庞大的数据量,网络爬虫仍具有一定局限性,它只能在有限的时间内访问一定量网页,因而在设计爬虫时需要考虑访问优先项,优先下载更重要的信息。此外,网络爬虫需要遵循网络规范和国家法律法规,不能任意爬取网络上的资源,对于一些设置爬取协议的网站要严格遵守,一些重大的网站也通常会设置较为严谨的反爬机制。
2.2文本挖掘与词表构建
2.2.1文本挖掘
文本分类是指对大量的文本信息按照一定的分类规则,根据文本的内容将其划分到一个或多个预定义的类别的方法,属于一个有指导的学习过程。将文本分类技术应用到网络舆情挖掘中,在信息的获取阶段,专业搜索引擎可以通过基于主题的爬取策略来判断信息是否和领域相关;在信息分析阶段,可以针对不同需求实施不同的分类需要。文本分类主要包括文本的表示方法、特征的选择和提取、分类器的选择与训练、分类结果的评价等过程。
文本挖掘(Text Mining)是指从文本数据中抽取有价值的信息和知识的计算机处理技术。文本挖掘区别于一般数据挖掘的特点在于其以使用自然语言的文本为挖掘对象,重点处理非结构化信息。典型的文本挖掘应用过程如图2-1所示。其中,在文本预处理过程中基于语义的中间文本库是依赖于领域知识的,而仅仅基于词语的中间文本库可以与领域知识无关。建立和导入领域知识,以及对文本进行合理的初步筛选,对于提升文本挖掘的精度和效率至关重要。文本挖掘核心算法则包括文本特征抽取、分类、聚类、关联分析、趋势分析等,在实际应用中需要合理选择和设计数据处理过程方案。
中文分词
特征提取
向量表示
分类模型
分类统计
训练文本
训练文本
训练文本
图2-1 文本挖掘流程图
2.2.2词表构建
词表是自然语言处理的基础,大多数知识和规则依赖于词表而建立。词表按照内容可以分为通用词表、专名词表和领域词表。一般静态词表的结构见表2-1。动态词表则包含了词间关系,主要是同义、上下位和相关关系。
表2-1 静态词表的一般结构
序号 | 词 | 频率 | 词性 |
1 | 生活垃圾 | 名词 | |
3 | 补偿 | 名词/动词 | |
12 | 冲突 | 名词/动词 | |
…… | …… | …… | …… |
领域词表可以用于中文分词系统。文本挖掘的基础是自然语言处理。因为字符、书写习惯、语音和语法方面的特殊性,中文自然语言处理存在很多难点。比如,印欧语系采用空格作为词汇间的分隔符,而书面汉语不实行分词连写,词汇长度不一,所以要对汉语进行信息处理,第一步就是自动切词(分词)。分词问题已成为当前中文信息处理的瓶颈。分词系统是以词表为依据的。要让计算机做自动分词,首先要构造词表。通用词表对特定或专业性强的领域分词效果差。所以针对特定领域的文本挖掘,在通用词表的基础上还需要特定领域的词表。
领域词表可以用于文本挖掘的特征选取和权重确定,常用方法有TF−IDF、World Net。对于城市垃圾危机领域来说尚无法通过基于语义的方法获得数据,本研究则开发了初级的城市垃圾危机领域词表。领域词表的构建,有利于实现文本挖掘的特征选取、权重确定、有效分词。
2.3危机转化“名利”空间模型
危机转化“名利”空间模型是由武汉理工大学危机转化专家杨青教授提出的危机转化模型。[9]“危机转化名利”空间模型将危机事件转化的方向创造性的提炼为名誉和利益两个方向,并通过象限模型模拟名誉和利益的关系,将危机事件可能演变的方向划分为四个种类,分别是“名利双收”、“得名失利”、“失名失利”、“失名得利”四种类别,也分别对应“名利”空间模型中得四个象限,具体模型结构如下图2-2所示:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: