移动用户行为分析及预测研究——以新浪微博为例毕业论文
2020-02-19 20:10:49
摘 要
用户中心论的提出,和互联网技术的日益发展,促使对用户行为数据的潜在价值进行挖掘和利用备受关注。本文以新浪微博为研究对象,收集相关数据,刻画了用户群体的属性特征,详细分析了微博用户的关注、信息发布和信息交互三种行为,验证了用户行为的幂律分布,并从个体用户、平台管理、企业经营和舆论监控等角度提出了建议和看法。与此同时,以用户转发行为为例,通过文本向量化和信息增益法,从微博文本中提取出特征词,建立了对用户信息交互行为进行预测的KNN算法模型,提出了预测结果评价指标体系,并为算法的改进提出了意见。研究结果表明,多数微博用户为惰性群体,交互行为特征量较小,用户影响力差异较大、关注度差异较小,且用户信息发布行为具有碎片化和阵发性。
关键词:新浪微博;用户行为;幂律分布;文本挖掘;KNN算法
Abstract
With the rise of user-centered theory and the development of Internet technology, the potential value of massive user data has attracted much attention. This paper takes sina weibo as the research object, collects data, depicts the attribute characteristics of user groups, and analyzes the three behaviors of weibo users in detail, including attention, information release and information interaction, verifies the power law distribution of user behaviors, and puts forward suggestions and opinions from the perspectives of individual users, platform management, enterprise management and public opinion monitoring. At the same time, taking the forwarding behavior of users as an example, through text vectorization and information gain method, the characteristic words are extracted from the micro-blog text, the KNN algorithm model for the prediction of user information interaction behavior is established, the result evaluation index system is proposed, and Suggestions for the improvement of the algorithm are proposed.The results show that most weibo users are an inert group, with small amount of interactive behavior characteristics, large difference in user influence and attention, and user information publishing behavior has fragmentation and paroxysmal.
Key Words:Sina weibo ;user behavior ; power law distribution ; text mining ; KNN
目 录
1绪论 1
1.1选题背景 1
1.2研究的目的和意义 1
1.3研究现状 2
1.3.1国内研究现状 3
1.3.2国外研究现状 4
1.4主要研究内容 5
2相关理论综述 6
2.1幂律分布 6
2.2文本处理 6
2.2.1文本向量化 6
2.2.2文本特征选择 7
2.3文本分类算法 7
3微博用户行为分析 9
3.1用户属性特征 9
3.2用户行为定义 10
3.3用户行为特征分析 12
3.3.1数据采集 12
3.3.2关注行为分析 13
3.3.3信息发布行为分析 16
4微博用户信息交互行为分析及预测 19
4.1用户信息交互行为分析 19
4.2用户信息交互行为预测 21
4.3预测结果评价指标 23
4.4数据仿真 24
5总结 27
参考文献 28
致谢 30
绪论
1.1选题背景
随着“用户中心论”的提出,传统商业思维受到了新兴经济理念的冲击。强调互动、平等、开放的互联网新经济思维,把用户至上的理念突显出来,将为顾客创造价值的目标置于首位,更有利于整合各种社会资源,实现企业与客户的共生共赢。与此同时,在社交网络环境下,互联网技术的飞速发展,促使信息共享的效率得到极大提升,用户也从单一的内容消费者逐渐转变为积极的信息创造与分享者。用户通过在社交媒体平台上的各种行为,成为了信息网络中的重要组成节点,越来越多的人们享受到互联网带来的便捷与乐趣。根据中国互联网信息中心(CNNIC)于2019年2月发布的第43次《中国互联网络发展状况统计报告》[1]显示,截至2018年12月,我国网民规模达到8.29亿,全年新增网民5653万,互联网普及率59.6%,手机网民规模为8.17亿,手机上网用户比例达98.6%,台式电脑、笔记本电脑上网用户比例分别为48.0%和35.9%,全年新增手机网民6433万。我国的移动互联网已经进入了高速发展的重要阶段。
在社会各领域推动“互联网 ”的趋势下,社交应用与传统媒体互为补充,融合发展,社交应用商业模式日益成熟,社交网站和各垂直社交应用借助各式各样的功能,满足了用户在不同场景下的沟通、分享、娱乐等需求。新浪微博,作为国内最大的社交媒体平台,已经引起了人们越来越多的关注和重视。据统计[2],截至2018年第四季度,新浪微博月活跃用户(MAUs)增至4.62亿,较上年同期净增约7000万,其中93%为移动端用户。2018年12月平均日活跃用户数(DAUs)较上年同期净增约2800万,达到2亿。以新浪微博为代表的基于用户关系的社交媒体平台,促使用户通过多种移动终端接入,以文字、图片、视频等多媒体形式,简单高效的实现信息的即时分享,再经过裂变式传播,让用户与他人互动并与世界紧密相连。这种“连接一切”的生态平台,促使用户粘性不断增强,产生了海量的用户行为数据。这些数据涵盖了人们生活的方方面面,包含着大量有价值的信息。
1.2研究的目的和意义
人类动力学研究表明,尽管个体行为具有较大的随机性和不可预测性,但在群体层面则具有较强的规则性。用户行为分析,即根据网络中海量的用户群体行为数据进一步探究和挖掘,研究用户群体在不同情景下的行为,分析出用户行为的特点、相关性和影响因素,建立相应模型,从而总结归纳出用户的行为特征及规律。该过程运用了计算机建模和数据挖掘等多种方法,涉及了人类动力学、计算机科学、信息科学及复杂网络等多项理论[3,4,5] 。用户行为预测,则是在用户行为分析的基础之上,通过模型,模拟不同变量因素作用下的结果变化,结合实际情况,对用户可能采取的行为进行预测,为需要采取的应对方案做参考。
自新浪微博诞生至今,已经成为国内重要的信息发布和交流平台之一,坐拥巨大的用户群体。随着日活跃用户量的增长,微博平台每天会产生海量的文字、图片和视频信息,具有巨大的研究价值。微博,作为一项重要的社交媒体渠道,同时也是政府、企业、名人与普通大众进行交流的重要平台,如何营造良好的舆论环境,持续扩大影响力,强化社交资产,深度发展垂直领域,推动商业化发展,维护国家安全和社会稳定;这些都迫切的需要对微博用户的行为进行研究,深入了解用户行为数据的潜在价值。通过研究微博平台中的用户行为数据,进行数据挖掘,分析用户的行为特征,对信息资源进行整合,把信息的传播、用户间的联系和其他有用资源结合起来,将对社会的进步乃至人类的发展产生巨大的价值。
目前,微博用户行为研究领域主要面临四个难题[6]:一,海量动态;由于微博的便捷性,动态用户行为会源源不断的产生数据,而反复处理新增的数据会影响算法的稳健性,提高算法的时间复杂度,降低研究结果的时效性。二,高度稀疏;用户群体过大,且受社会信任、社交影响、兴趣爱好等多重因素干扰,数据密度极小,近乎万分之一甚至百万分之一的级别,使得关联估计误差大,用户画像及微博内容信息刻画难度增大,也给行为预测的准确度带来严峻挑战。三,内容复杂;微博的碎片性限制信息的完整性,文本内容短小且格式杂乱,难以通过一条微博文本了解完整的事件信息,且“僵尸粉”、“高仿号”等不良行为,在污染了网络空间的同时,也产生了大量的噪声数据和垃圾信息,如果不进行科学的判断与处理,则会干扰模型结果的有效性。四,高维异构,用户行为多样,社交网络中,除用户节点外,还有内容信息节点,群组节点等多个复杂网络结构元素,在用户行为建模时难以面面俱到。
本文充分考虑以上难题,从用户行为数据中提取用户特征,立足于多个角度,分析用户行为,完成相关模型建立、验证研究,为用户行为分析及预测研究提供参考,选题具有一定的理论意义和应用前景。
1.3研究现状
近年来,国内外学者们在移动用户行为研究领域不断深入探索,结合信息科学、管理学、经济学等多个领域的相关理论,利用新兴的大数据知识和技术,分析移动用户在特定情景下的形态各异的实践行为,选择合适的影响因素和建模方法,并加以改进,从定性和定量两个角度充分的分析与预测用户的行为意向和特征规律,从而为平台管理、企业经营、政府监控、社会发展等多个领域提供了许多有价值的引导与参考意见。
1.3.1国内研究现状
当前,国内移动用户行为的研究热点主要集中于移动应用和理论研究两个方向。[7]
- 移动应用
在特定环境、特定领域中,用户的行为会根据平台的功能有所不同。苑卫国(2014)[8]针对微博用户发布行为进行了探究,运用逻辑回归,提出了基于社交和兴趣两类影响因素的信息发布模型,并对用户特征量及用户影响力度量进行了简要分析。杨海峰(2017)[9]通过对用户信息需求的动机、触发因素及类型、信息搜索时的两类因素进行探究,构建了搜索模型,探索了用户的搜索行为。盛东方(2018)[10]采集了微博社会化分享数据,并采用多种统计分析方法分析了用户分享行为的特征。
李浩君、冉金亭(2018)[11]针对移动图书馆用户的使用行为,设计了问卷采集数据,并以主成分因子分析法提取了六个潜在变量,对其间路径关系进行验证,提出了优化的用户行为意愿模型。明均仁、张俊(2019)[12]基于任务——技术匹配模型(TTF),参考使用环境,将用户的使用行为及绩效期望联系起来,构建了使用行为模型并加以验证。夏立新等人(2018)[13]利用推拉锚定模型(PPM)对用户迁移行为的影响因素加以区分定义,建立用户转移行为概念模型,收集数据,进行假设检验和模型拟合探究了四个因素对用户行为过程的影响,为音乐类平台发展提出了建设性意见。
用户持续使用行为方面,孟猛、朱庆华(2018)[14]参考扩展的ECM-ISC模型、自我决定理论及习惯进行设计,构建了概念模型,以微信平台为研究对象,收集数据,采用偏最小二乘法分析并验证,得到概念模型路径PLS分析结果,加以评估,为社交媒体平台稳定发展提供了宝贵意见。王飞飞等人(2018)[15]也运用了类似的方法,构建UGC行为模型对微信平台用户生成内容行为进行了探究。
- 理论研究
赵玲,张静(2013)[16]结合经济学中的羊群效应,参考信息瀑布相关理论,对微博用户的参与行为过程进行分析,建立了基于可信度与用户态度等因素的概念模型,揭示了外界影响和自我态度对用户行为的影响。蒋朦(2015)[17]仔细探究了用户行为的三个特性,分别提出了基于社交和时空上下文的信息采纳行为分析模型、迁移学习算法和可疑行为分析及评价指标,全面详尽的分析了用户复杂行为的潜在规律,为社交应用的发展提供了宝贵意见。付江丽(2015)[18]在TAM模型的基础上,引入信息技术理论和动机理论,针对微博用户的采纳、使用及成果三个阶段的行为,进行模型整合,分析了用户不同阶段行为因素间的关系,为微博平台的发展提供了建议。
王鲁飞(2016)[19]建立了基于混合分类器的情感预测模型(HCSPM),通过机器学习,利用SVM分类、朴素贝叶斯等四项技术对微博的情感分类进行了预测。与此同时,解军(2016)[20]提取微博文本特征词,用类别集合代替距离算法对KNN文本聚类算法进行了改进,并参考用户以往的微博互动频率,实现了用户行为的预测。仲兆满(2018)[21]等人研究了推荐系统的冷启动问题,提出了微博用户活跃性判定方法,设计了差异度计算模型,从四个维度计算用户活跃性差异度,对边缘用户加以区分,在一定程度上改善了用户推荐的结果。
罗芳等(2018)[22]参考传统的PageRank算法,考虑用户属性、交互行为和博文内容三种维度因素,提出了一种新的多维度用户影响力度量算法(MDIR)。而黄贤英(2018)[23]等人则从用户属性、活跃性、认证信息和博文质量角度来衡量用户的基本影响力,并引入博文传播率来揭示用户潜在影响力,结合用户好友质量,改进了PageRank算法。两种算法都更加全面、客观的衡量了微博用户的实际影响力。
1.3.2国外研究现状
Barbera(2015)[24]针对Twitter等社交媒体上的政治领域关注用户进行分析,在同态社交网络的假设下,构建了将用户意识作为潜在变量的贝叶斯空间跟随模型,通过考察用户跟随的政客对模型进行评估,探究了意识形态对政治领域网络用户行为的重要性。Atefeh和Khreich(2015)[25]探索了从Twitter流中检测事件的技术,根据事件类型、检测任务和检测方法对这些技术进行了分类,并讨论了常用的特性。Batrinca和Treleaven(2015)[26]通过对社交媒体信息抓取的各种软件进行分类,讨论了社交媒体研究实验计算环境的需求,为各国寻求在其研究或业务中利用社交媒体抓取和分析的学者们提供了一个参考。
EvaLahuerta(2016)[27]等人结合图论和社会影响理论,对Twitter上的影响者进行调查,发现其tweets的特征,为从业者和营销人员提供了洞见,让他们了解如何通过观察tweet的内容来发现谈论自己品牌的影响力人物。K. Tago和Q. Jin (2018)[28]基于Twitter数据,利用情感词汇词典,分析了用户情感对用户关系的影响,对短文本进行挖掘,通过关键词匹配计算情感得分,并运用Brunner-Munzel测试来评估情感行为对用户关系的影响,证明了在特定条件下,积极用户在构建用户关系方面比消极用户更有利。Neha等人(2019)[29]通过情绪变化检测的方法,分析Twitter用户在突发事件影响下的情感倾向,利用改进的的情绪分析和变化点检测技术来处理、发现和推断用户的时空情绪,并通过拉斯维加斯枪击案加以检验,有利于为突发事件下应急响应人员和政府部门提供适当的反馈。
1.4主要研究内容
本文研究重点在于对用户的关注行为、信息发布行为和转发、评论、点赞三种信息交互行为进行分析,并对信息交互行为进行预测,全文组织如下:
第一章,绪论。调研了研究背景,确定了研究目的和意义后,对国内外的研究现状进行了分析与总结。第二章,理论综述。对各种用户行为普遍服从的幂律分布理论进行介绍,并概述了本文应用的文本挖掘和分类算法的理论知识。第三章,用户行为分析。首先,对微博用户群体进行特征画像,分析了主流群体的属性和其的兴趣偏好;其次,对普通用户进行了行为定义;最后,收集相关数据,对用户的关注行为和信息发布行为做了具体的剖析。第四章,用户信息交互行为分析及预测。一方面,对用户信息交互行为的幂律分布进行验证,分析用户行为波动;另一方面,以转发行为为例,对微博文本进行处理,建立KNN算法预测模型,对用户的转发行为进行预测;与此同时,建立结果评价体系,并进行数据仿真。第五章,总结。对全文研究内容进行总结,并为进一步的研究提出指导。
全文架构安排如下图1.1所示。
图1.1 本文架构安排
2相关理论综述
2.1幂律分布
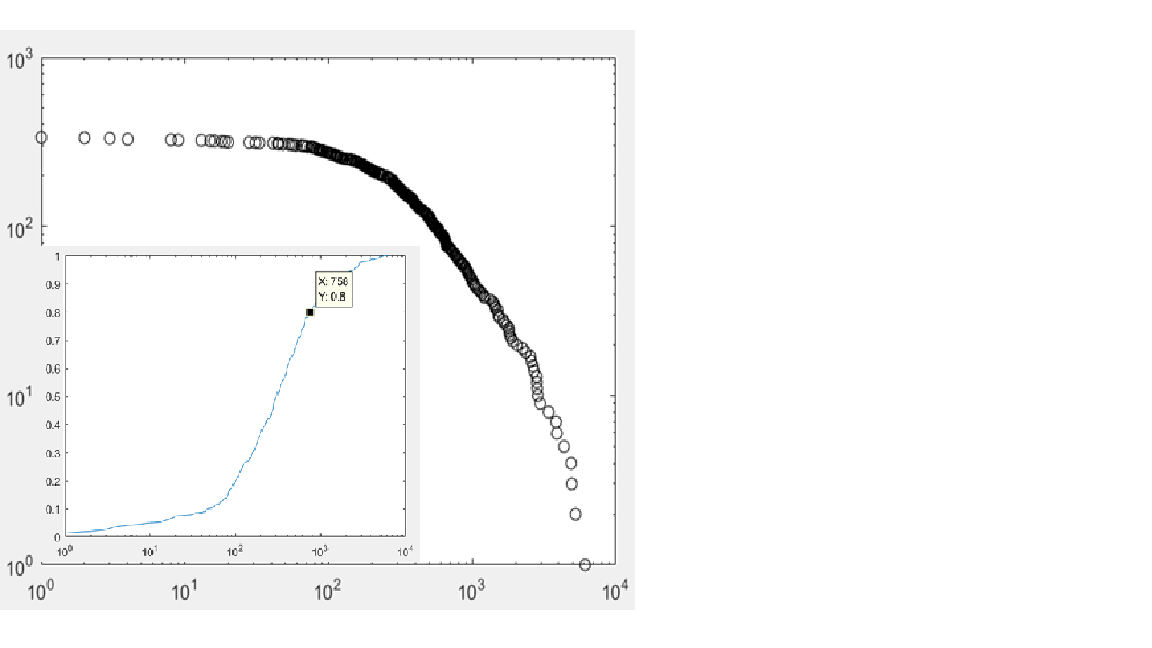
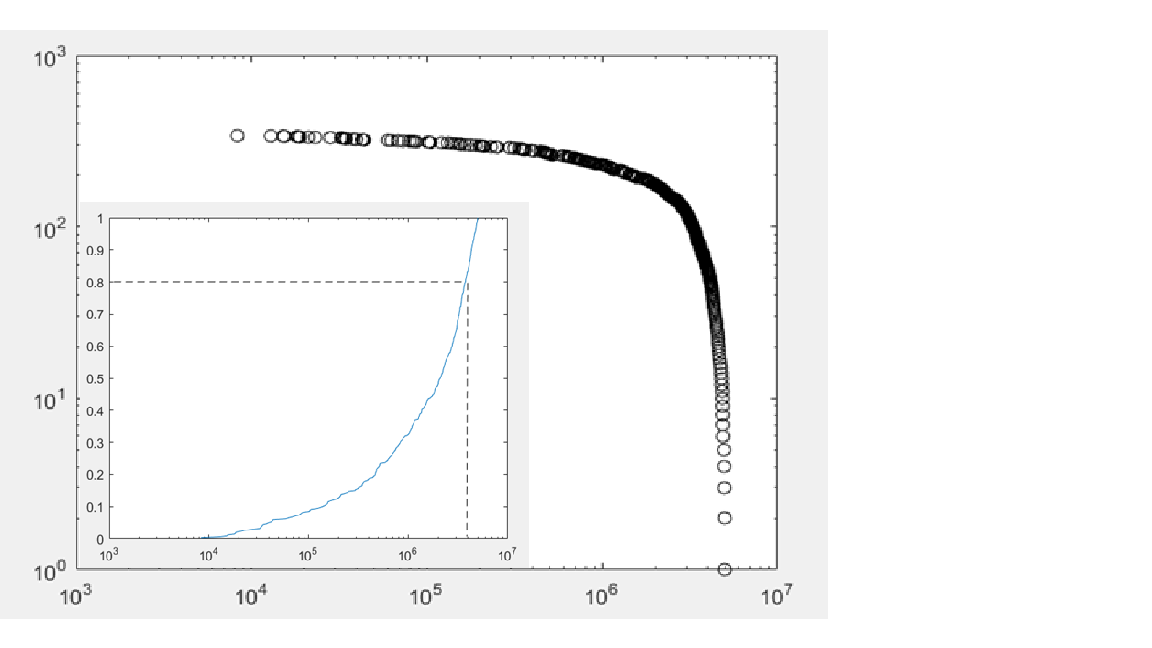
幂律的概念,来源于上个世纪科学家们的一个实验。在实验中,他们统计了英语中各个单词的使用频率,然后发现人们日常生活中真正使用的仅为少量核心词汇,很多单词并不常用,单词的使用频率与它被优先使用的概率保持着一个常数次幂的反比关系。幂律也常被解释为马太效应(富者越富,穷者越穷)或者80/20定律,两个变量的变化存在着相关关系,自变量的相对变化会导致因变量发生相应幂次的比例变化,且与初值无关。在坐标轴中,幂律分布函数的图像右半部分往往是一条无限靠近x轴却不相交的曲线,人们把它称为长尾分布。自然界有很多现象的分布都大致遵循着幂律分布,当样本数据量较多时,变量x的概率密度函数常表示为: ,而验证幂律分布一般使用双对数图,即对自变量和因变量都取对数后作图,遵循幂律分布的样本点在双对数图中呈现为直线。
2.2文本处理
2.2.1文本向量化
在完成文本的清洗、分词等步骤后,需要将被分割的文本表示成为向量矩阵,以便于计算机进行读取和进一步处理。当前文本向量化的表示方法有两种模型[30]:词袋模型和神经网络化模型。词袋模型又可被分为TF-IDF模型和潜语义分析模型。本文采用的是TF-IDF模型。
TF-IDF模型常用于过滤常见字词,保留重要字词。它不仅仅考虑了语料库中所有字词的词频,也衡量了一个字词对一个语料库中一条句子的重要程度。一个词的重要性,会随着它在句子中出现的频率成正比,随着它在语料库中出现的频率成反比。模型中,TF即词频(Term Frequency)的计算公式为:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: