面向小说《红楼梦》的人物图谱与事件年谱分析毕业论文
2020-02-19 20:10:18
摘 要
自然语言处理作为人工智能领域的重要分支,在现代互联网领域的应用变得越来越广泛。本论文依托《红楼梦》这本名著内容以及从百度百科上爬取的人物百科文本,使用NLP(自然语言处理)技术和Python工具对文本进行分析,抽取书中的人物关系与事件,使用可视化工具Gephi对关键词、人物关系、事件关系进行可视化,并使用neo4j echarts flask python搭建一个可视化展示系统。
关键词:自然语言处理;事件;知识图谱;可视化
Abstract
As an important branch of artificial intelligence, natural language processing has become more and more widely used in the field of modern Internet. This thesis relies on the content of the famous book "Dream of Red Mansions" and the encyclopedia texts crawled from Baidu Encyclopedia. It uses NLP (Natural Language Processing) technology and Python tools to analyze the text, extract the character relationships and events in the book, and use the visualization. The tool Gephi visualizes keywords, character relationships, and event relationships, and uses neo4j echarts flask python to build a visual display system.
Key Words:NLP;Event;Knowledge Graph;Visualization
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.3 主要研究内容 2
第2章 总体设计 3
2.1 语料 3
2.2 工具 3
2.2.1 Python 3
2.2.1 Gephi 3
2.2.1 Neo4j 3
2.2.1 Echarts 3
第3章 关系与事件抽取 4
3.1 分词 4
3.2 关键词抽取 5
3.3 词袋模型 7
3.4 依存句法分析 9
3.5 实体关系抽取 11
3.6 事件抽取 13
第4章 基于Gephi的可视化 15
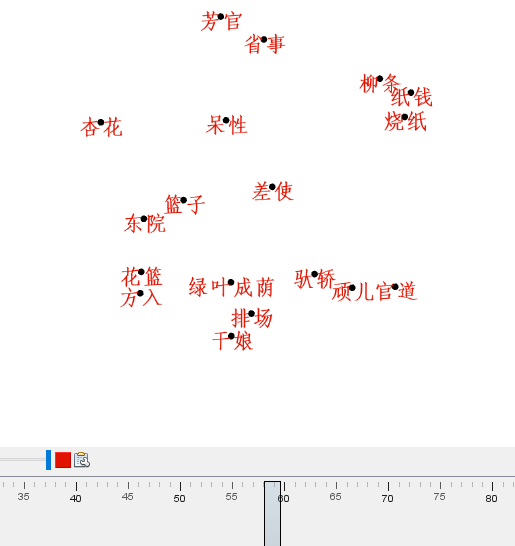
4.1 关键词可视化 15
4.2 人物关系可视化 16
4.3 事件关系可视化 18
第5章 基于neo4j的可视化 22
5.1 搭建方案 22
5.2 系统运行原理 23
第6章 结论与展望 26
参考文献 28
致谢 29
第1章 绪论
1.1研究背景与意义
自然语言处理(NLP)作为人工智能领域的一个重要分支,现在已经发展成为人工智能研究中的热点方向。自然语言处理作为机器学习与语言学、统计学等的综合学科,不仅知识内容多,发展迅速,而且非常依赖于工程能力。目前,统计学以及数据驱动的方法在NLP中占据着统治地位。NLP可以被应用于很多领域,如机器翻译、情感分析、智能问答、文摘生成、文本分析、舆论分析、知识图谱等。在数据爆炸性增长、信息过载问题越来越严重的时代下,面对海量信息,使用人力来分析和驱动的传统方式,已经显得越来越捉襟见肘。这样的情况下,能够自动化处理大规模文本相关的数据的NLP,即将成为未来人工智能发展技术的新趋势和方向。其已构成的知识体系如下:句法语义分析、关键词抽取、文本挖掘、机器翻译、信息检索、问答系统、对话系统等。
随着时代的发展,人工智能技术越来越成熟,并且逐渐成熟的技术开始应用到各个领域:自动驾驶、人脸识别、专家系统、机器人学等,为相关领域带来了巨大的进步与经济效益,应验了“科学技术是第一生产力”这句话。而在人工智能领域内,自然语言处理又是一项重要而成熟的分支,研究能实现计算机、人二者之间进行通信的理论与方法,当计算机能够学习、理解人类的语言时,计算机就真正的成为了人工智能。因此,使用自然语言处理技术处理人类文明的宝藏——书籍,是赋予人工智能人类特征的重要手段。
本次毕业设计基于中国四大名著之一《红楼梦》,使用自然语言处理(NLP)将红楼梦中繁杂的人物关系抽取并图像化,事件顺序图像化,使得读者在未读到此书时,便能知晓书籍中核心人物关系以及事件顺序,节省读者大量的时间成本,并且效率更高。
1.2国内外研究现状
自然语言处理最早源于1949年的机器翻译,60年代,国外开始对机器翻译进行大规模的研究;90年代开始,自然语言处理开始有了巨大的变化,强调“大规模的真实文本”;现代NLP涉及的技术与领域十分广泛,交杂了各类学科,并且形成了一套完整的流程,由于国外的研究起步早,故而有着数量庞大的语料库和工具,如NLTK、Gensim等工具包给自然语言处理工作带来了极大的便捷,国外还经常组织相关竞赛,促进了自然语言处理技术的发展。
在国内,自然语言处理的技术与书籍大多来源于国外,并且完备的理论也来源于国外,但这些理论与书籍都是以国外的语言——英文为基础,在英文领域取得了成功,但应用到中文领域,就会发现没有那么简单,许多中文自然语言处理学习者会发现走上了弯路,浪费了大量时间。同时,在国内并没有大量的符合要求的中文语料,涉及到中文自然语言处理的书籍也相当稀少,这些书籍大多讲述了相关理论知识,却不描述实战,令学习者感到困惑。
随着国内人工智能的兴起,对中文自然语言处理的研究也开始变得热门,许多著名的门户网站提供了数量庞大的语料与开源工具,如搜狗提供的中文语料库,百度提供的接口,还有专门用来处理中文的工具,如哈工大语言云(LTP)、jieba分词,许多源于国外的工具也开始支持中文。
在人工智能大热的时代下,我相信在众多从业人员的研究与努力下,国内的自然语言处理研究会达到新的高度。
1.3主要研究内容
本次毕业设计的主要研究内容是学习NLP的处理技术与流程,分析《红楼梦》的文本内容,将书籍《红楼梦》中的人物关系与事件抽取出来进行,使用可视化软件Gephi将抽取出的相关数据进行可视化,然后再使用python flask echarts neo4j搭建一个可视化展现系统,能够将人物关系图谱展示在web页面上,并且用户可以在搜索页面输入相关信息搜索想要的人物关系,在问答页面输入相关信息搜索出结果。具体说明如下:
第一章:绪论,主要介绍本次毕业设计的背景与意义,阐述了国内外的研究现状。
第二章:总体设计,主要介绍本次毕业设计所使用的语料以及工具等内容。
第三章:关系与事件抽取,主要介绍了本次毕业设计所进行的文本分析工作内容,涉及到自然语言处理的大部分技术与流程。
第四章:基于Gephi的可视化,主要介绍本次毕业设计如何将获取的数据进行加工处理,利用可视化软件Gephi进行可视化。
第五章:基于neo4j的可视化,主要介绍如何在前人的基础上,搭建一个小型可视化系统,实现存储数据、展示图谱、搜索关系、简易问答的基本功能。
第六章:结论与展望,主要内容是通过本次毕业设计所学到的内容与收获。
第2章 总体设计
2.1语料
本次毕业设计使用的语料有《红楼梦》文言文文本、白话文文本,从百度百科爬取的《红楼梦》人物百科资料。
2.2工具
2.2.1 Python
Python是一款高级编程语言,简单易学,适用于文本分析。在自然语言处理中有许多工具包,能够简单便捷地被Python工具使用,便于用户进行自然语言处理。在本次毕业设计中,它将完成自然语言处理工作中的绝大多数内容,包括爬取数据、文本分析等工作,更重要的是,Python拥有庞大的工具库可供使用。
2.2.2 Gephi
Gephi是一款复杂网络分析软件,主要用于交互可视化,应用范围广泛,能够将关系数据绘制成漂亮、简洁的网络图。在本次毕业设计中,它将绘制关键词动态图、人物关系图、事件动态图。
2.2.3 Neo4j
Neo4j是一个高性能的图形数据库,它将数据存储在网络上,具备处理复杂的互相连接的数据能力,拥有传统的RDBMS所没有的特点,解决了传统的RDBMS随着存储数据量增多而产生的性能衰退问题。在本次毕业设计中,它将存储人物关系三元组,作为可视化系统的数据库。
2.2.4 Echarts
Echarts是一个使用JavaScript实现的开源可视化库,提供了丰富的可视化类型,使用时只需要在前端代码中引用即可,只需要传入数据参数,不需要操心其余的事情。总而言之,Echarts提供了已经封装好的实例,配色方案、图型类型等等,用户只需要提供需要展示的数据即可。
第3章 关系与事件抽取
3.1分词
分词大概是自然语言处理中最基本的问题了。在英文中,每一个单词都有其具体的意义,在一个自然句中,它与另一个单词以空格为间隔,而中文则不同,一个自然句往往是多个中文汉字的组合,没有标准的规则、符号来表示一个词的开始与结束,因此在中文自然语言处理中,分词对语义的理解非常重要。例如中文中有一副对联“长长长长长长长,长长长长长长长。”如果不进行合适的分词,它的意义是很难理解的。
分词是自然语言处理中的一项基础工作,本文使用分词工具jieba对原始文本进行分词,jieba支持三种分词模式,分别是:
精确模式:能够将句子精确地分割切开,适合用于文本分析;
全模式:将句子中所有的能够形成词语的词语都分割表示出来,速度快,但显然存在歧义;
搜索引擎模式:在精确模式的基础上,对字数多的长词语进行进一步的切割,适合于搜索引擎。
本文采用精确模式,并为jieba添加自定义词典。自定义词典能够解决词语歧义的问题,例如“结婚的和尚未结婚的”这句话,在没有添加自定义词典的情况下可能被分为以下两种情况:“结婚/的/和尚/未结婚/的”与“结婚/的/和/尚未/结婚/的”。当把“和尚”一词添入自定义词典后,例句会被jieba处理成第一种结果。
自定义词典的格式为一词一行,每一行分三部分,分别是词语、词频、词性,用空格隔开,后两者可以省略,本次毕业设计的自定义词典部分如图3.1所示:
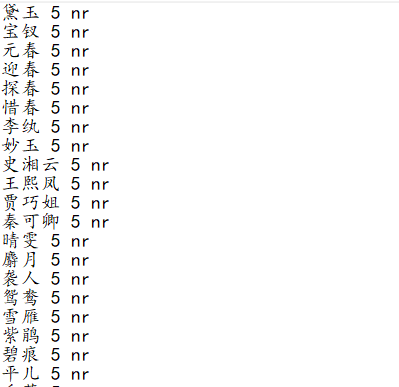
图3.1 词典格式
自定义词典弥补了jieba词库中没有特定文本内容词语的缺陷,例如原句“着贾蓉带领家下人等与贾敬送去”,未添加自定义词典时,分词结果为“着/贾蓉/带领/家下/人/等/与/贾/敬送/去”;添加之后,分词结果为“着/贾蓉/带领/家下/人/等/与/贾敬/送/去”。
在对要分析的文本进行分词后,可以使用停用词表,将文本中没有重要意义的常用助词等词汇消除,节省存储空间,提高运行效率;把文本中一些没有实际含义的词语去除,如符号、英文字符以及频率较高的单汉字,比如“的”,使文本数据变得更加干净,方便做进一步的分析,本次毕业设计对《红楼梦》文言文本的分词结果如图3.2所示,同时也收集了《红楼梦》白话文版本:

图3.2分词结果
3.2关键词抽取
关键词是语句、文本中的重要词汇,能够体现语句、文本的主体思想,例如本次毕业设计的四个关键词,就体现了本次毕业设计的主要工作与内容。因此,关键词抽取是文本处理中的一项重要工作。
关键词抽取是将文本中重要的、关键的、与文本内容关系紧密的一些词语抽取出来,通过关键词可以了解当前文本的相应信息。关键词是文献检索、文本聚类/分类等应用的基础和前提工作,对它们有着重要的作用,当我们使用搜索引擎搜索一些内容时,搜索引擎就会抽取当前文本的关键词与后台服务器内庞大的信息库进行匹配。
在关键词抽取方面,有一些常用的方法:基于TF-IDF算法、基于TextRank算法、基于LDA主题模型进行关键词提取,不同的方法有不同的长短处。
本文使用TF-IDF算法进行关键词提取,它是采用数值统计方式,反映一个词语对于文档的重要性。该算法的主要思路是:如果一个词语在语料中的一篇文档中出现频率高,在其它文档中出现频率低,则认为该词语具有较好的类别区分能力。
TF为该词语的频率,表示词语在文档中出现的频率,计算公式为:
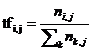 (3.1)
(3.1)
其中分子是该词在文档中出现的次数,分母为所有词语在文档中出现的次数和。
IDF为逆文档频率,表示包含该词语的文档数目的倒数,计算公式为:
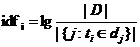 (3.2)
(3.2)
其中分子是预料库中的文档总数,分母为包含该词语的文档数目。
算法TD-IDF在实际中主要是将二者相乘,即TF*IDF。因此该算法能够过滤文档中普通的词语,抽取重要的词语,即关键词。工具jieba已经实现了基于TF-IDF算法的关键词抽取,本次毕业设计使用该工具,抽取原文本中每一章回的关键词,获取每一章回的前25个关键词,并写入txt文件中,同时标注关键词出现的章回。本次毕业设计抽取出的关键词部分如图3.3所示:

图3.3 关键词
从结果可以看到,有一些关键词的意义不明,甚至有些奇怪。例如第五回关键词中的“书云”,乍一看没有意义,但考虑到《红楼梦》是一本文言文小说,会经常使用“此书云”、“那书云”一类的词汇,就不足为奇了。书中还有一些专有名词,如“警幻仙姑”,本次毕业设计并未将“警幻仙姑”加入人物字典中,所以在使用jieba工具时,它将这一名词切割成了“警幻”与“仙姑”两个词。
因此,文本分析需要一个完备的人物表作为字典,有一个用词“清晰”的现代白话文版本《红楼梦》,以求得到更加准确的结果。
2.3词袋模型
自然语言处理的终极目的是为了让计算机能够学习、理解人类的语言,在自然语言处理中,词袋模型将文本看做无序的词汇集合,不考虑语法及单词顺序,它统计出现的每一个单词,计算其频率,将文本数据转换为计算机能够计算的数据,即使计算机能够“理解”文本数据。
本次毕业设计在对原文本进行分词后,去除无意义的停用词,然后将所有的分词放入一个词袋中,取词语的并集并去重,获取特征词。
我们使用Word2Vec将特征词转化为稠密向量,构建词袋向量模型。Word2Vec是大名鼎鼎的谷歌公司于2013年开放的一款工具,它可以将使用者输入的语料库,通过优化的训练模型,快速地把一个词语转化为向量模式,以便于计算机的计算、理解。
在Word2Vec出现前,自然语言处理使用One-Hot Encoder,例如有五个词语【幼儿园、小学、初中、高中、大学】,使用One-Hot对其编码会得到
{
幼儿园-gt;【1,0,0,0,0】
小学-gt;【0,1,0,0,0】
初中-gt;【0,0,1,0,0】
高中-gt;【0,0,0,1,0】
大学-gt;【0,0,0,0,1】
}
但其存在两个问题,向量相互独立隐藏了词语间的关系,词语过多导致向量维度增多,造成维度灾难。解决问题的手段即是使用向量表示。词向量使用某个固定维度的向量来表示词语,词向量技术将One-Hot Encoder降维转化为稠密向量,经过降维后,相似的词语在空间中的距离变得接近。获取特征词并转换为词向量后,就可以输入,进行模型训练。训练完毕后,保存模型,使用时加载。接下来可以使用训练好的模型进行计算一些句子、词语的相似性、最大匹配程度等。
举例判断“宝钗”与“宝玉”的相似度、“黛玉”与“宝玉”的相似度:(model = Word2Vec.load('model') #加载模型
print(model.similarity('宝钗', '宝玉'))
print(model.similarity('宝钗', '黛玉'))),可以得到如图3.4所示结果。
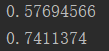
图3.4 输出结果
同样,我们可以获取与【‘黛玉’,‘宝玉’】最为亲密的人物(model = Word2Vec.load('model') #加载模型
print(model.most_similar(positive=['黛玉', '宝玉']))),从图3.5所示结果可以看到二者对应的分别是“紫鹃”、“袭人”,而在《红楼梦》原文本中,这两人分别是他们的侍女,关系亲密。

图3.5 输出结果
显然在相似度的数值上,前者低于后者,即证明在文本中,“黛玉”与“宝玉”的“亲密关系”要高于“宝钗”与“宝玉”,即便后者是夫妻关系,而前者只是恋人关系。这是因为,后者与“宝玉”同时出现的频率要小于前者与“宝玉”同时出现的频率,使得计算机在数据上计算出,前者比后者对“宝玉”具有更高的相似性。
通过词袋向量模型,可以将相似的词汇进行整合,例如当用户输入“贾宝玉的老爸是谁?”时,计算机可以自动将“老爸”这个词“理解”为“父亲”,因为在进行大量的文本训练后,词袋向量模型可以将这两个词判断为高度相似,原本不同的词会导向同一个词意,即“爸爸的爸爸”其实就是“爷爷”。
3.4依存句法分析
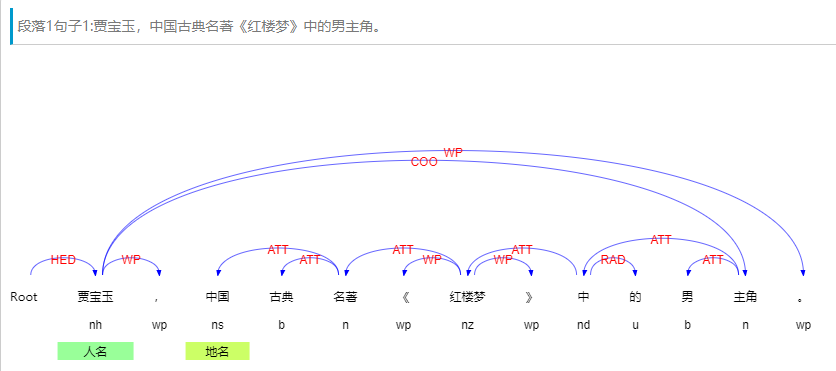
依存句法分析是自然语言处理中的一项关键技术,它将句子分析成一棵依存句法树,显露句子中每个词语间的依存关系,揭示词语间的搭配关系,从而使用户能够得到需要的语句信息。
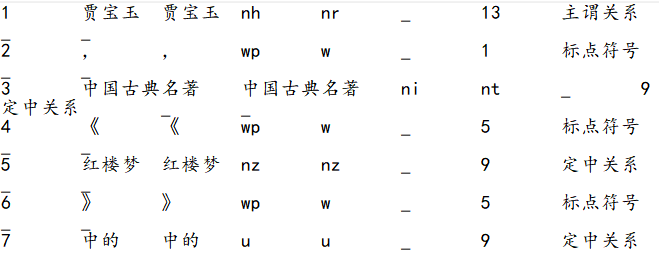
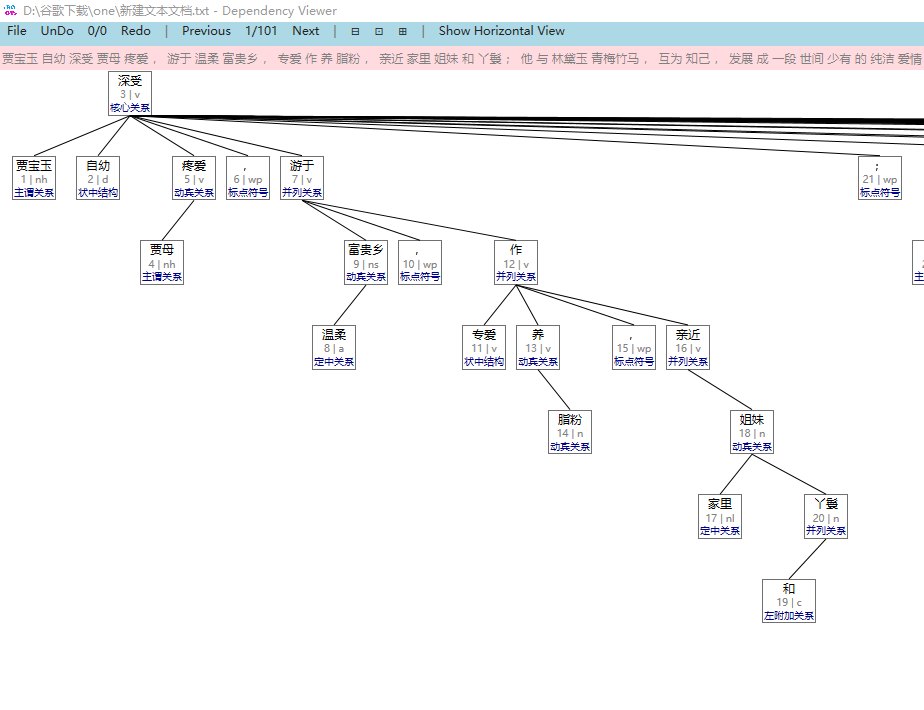
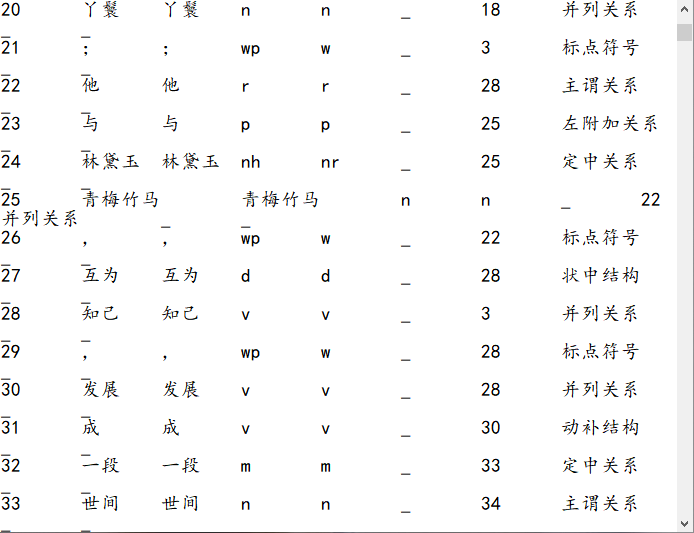
使用哈工大语言云对例句“贾宝玉,中国古典名著《红楼梦》中的男主角。”进行分析,可以得到如图3.6所示的结果:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: