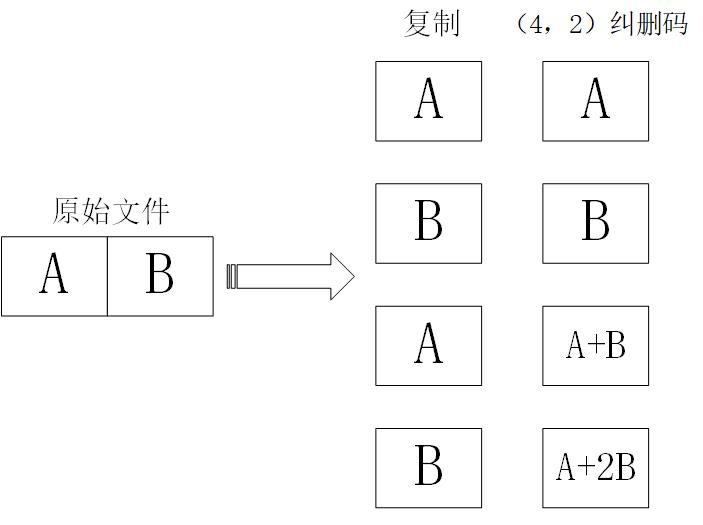
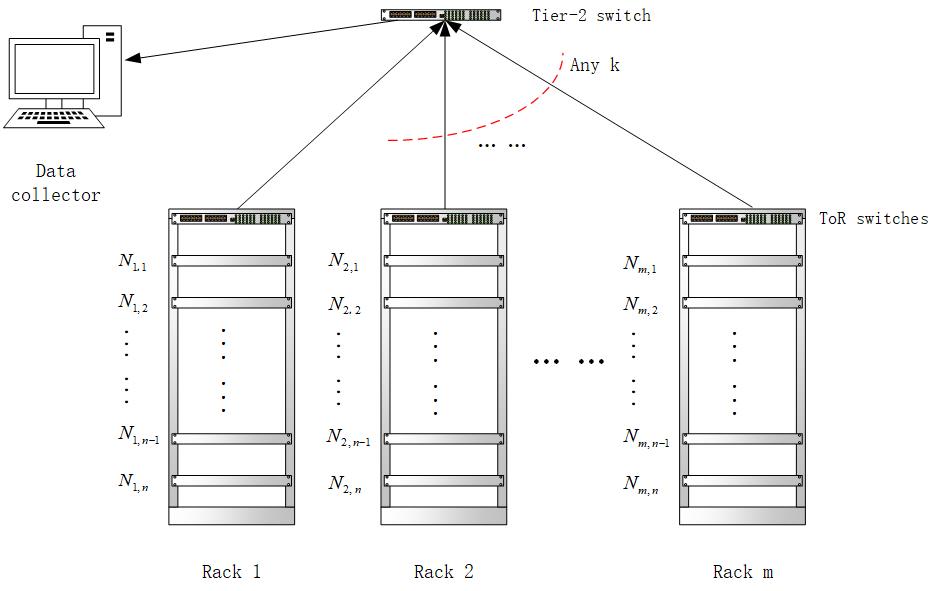
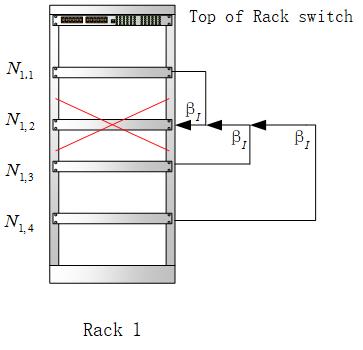
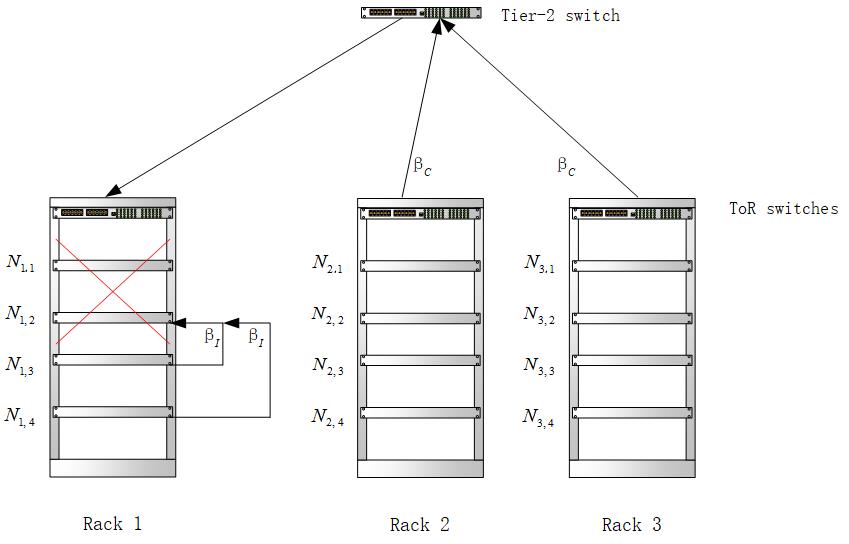
基于Rack模型的分布式存储系统研究毕业论文
2020-02-17 23:04:35
摘 要
信息技术的快速发展导致数据的大规模存储变成很平常的事情,面对社会各界越来越多的数据需要存储的同时,怎样用更低的成本存储更多的数据,并且使得数据的可靠性能够得到保证是一个热门的话题。面对海量数据的存储需求,谷歌、亚马逊、微软等云服务提供商将用户数据存放在位于全球不同位置的数据中心。在每一个数据中心,数据存储往往是基于Rack模型的。在Rack模型中,整个Rack的失效概率远小于存储节点的失效概率,并且位于同一个Rack中的存储节点之间的通信开销远小于位于不同Rack的存储节点之间的通信开销。所以,本文基于Rack模型的这些特性,提出了相应的节点修复机制、Rack修复机制和数据重构机制,使得在保证了数据可靠性的同时,将系统的修复开销尽可能地减小,探讨将基于Rack模型的分布式存储系统用于大规模存储的可能性。
关键词:分布式存储系统;节点修复;Rack修复;数据重构;通信带宽
Abstract
The rapid development of information technology has made large-scale storage of big data a common thing. In the face of more and more data from all walks of life, how to store more data at a lower cost and make the reliability of data available. Guarantee is a hot topic. Faced with the storage requirements of massive data, cloud service providers such as Google, Amazon, and Microsoft store user data in data centers located in different locations around the world. In every data center, data storage is often based on the Rack model. In the Rack model, the failure probability of the entire Rack is much smaller than the failure probability of the storage node, and the communication overhead between the storage nodes in the same Rack is much smaller than the communication overhead between the storage nodes located in different Racks. Therefore, this paper proposes the corresponding node repair mechanism, Rack repair mechanism and data reconstruction mechanism for these characteristics of Rack model, so that the reliability of the data is guaranteed, and the corresponding repair cost of the model is reduced as much as possible. Reflects the possibility of the Rack model's distributed storage system for large-scale storage.
Key words:Distributed storage systems; Node repair; Rack repair; Data reconstruction; Communication bandwidth
目录
第1章 绪论 1
1.1研究背景及意义 1
1.2国内外研究现状及相关技术 2
1.3课题研究内容 4
第2章 基于Rack模型的分布式存储相关技术分析 6
2.1分布式存储的关键技术 6
2.2 分布式存储系统的考虑因素 7
2.3 Rack模型相关知识 8
2.4 本章小结 9
第3章 分布式系统的基本模型设计 10
3.1 基于Rack模型的分布式存储系统整体模型设计 10
3.2 节点故障模型的设计及修复策略 11
3.2.1 单个节点故障情况 11
3.2.2 两个节点同时故障情况 12
3.3 Rack故障模型的设计及修复策略 13
3.4 数据重构策略的设计 14
3.5 本章小结 14
第4章 基于Rack模型的分布式存储系统仿真 15
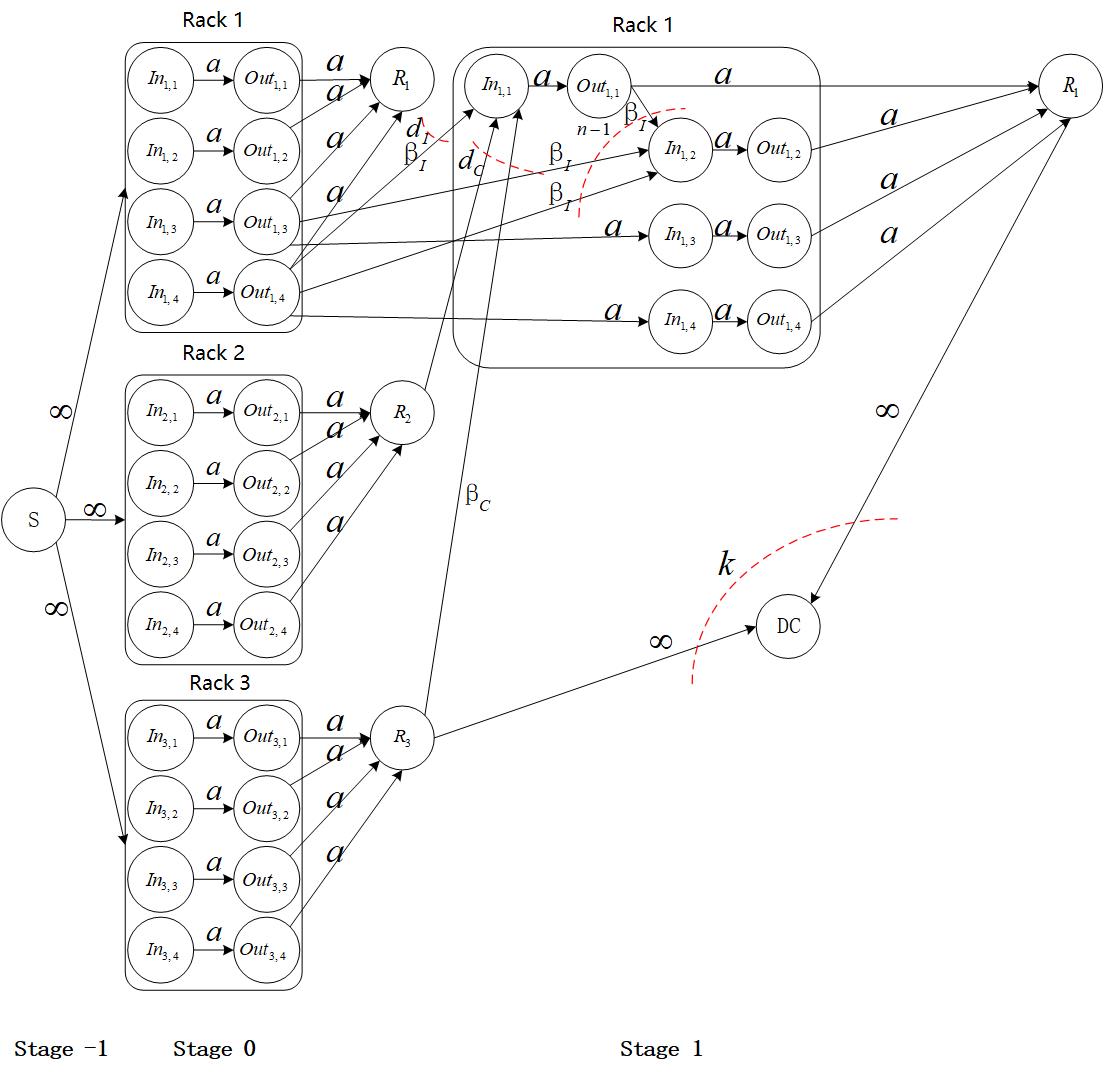
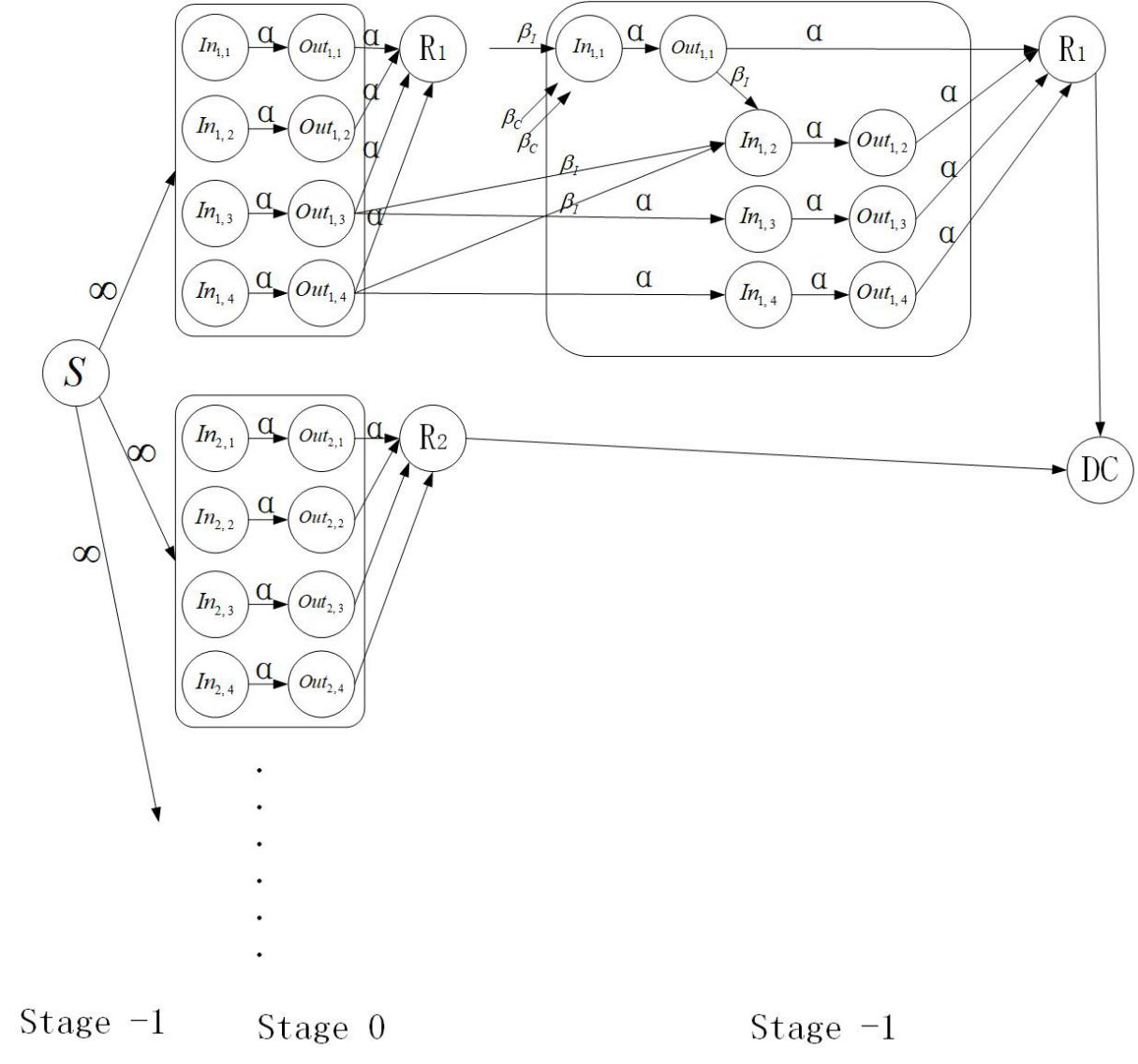
4.1 分布式存储系统信息流图 15
4.2 存储容量与修复带宽权衡 16
4.3 本章小结 19
第5章 总结与展望 20
参考文献 21
致谢 22
第1章 绪论
自摩根定律被提出以来,在硬件成本不断降低的同时,硬件设备的性能也越来越强。由于大规模分布式存储系统具有大量服务器设备,基本上都是以大量相对便宜的机器来用做存储数据的服务器节点,这使得整个分布式系统由于节点故障而脱机成为一个普遍的情况,这就导致存储在故障节点上的数据不可用。当节点出现故障或者整个服务器的机架出现故障的时候,为了保证数据的完整性以及用户使用的良好体验,怎样更好地更便宜地修复故障的节点和机架便是一个比较重点研究领域。
1.1研究背景及意义
近年来,伴随着互联网技术突飞猛进的发展,以及计算机技术在各个领域的普遍应用,社会上每天产生的各种各样的数据呈指数式增长。就好比现在热门的自动驾驶汽车,一辆正常的自动驾驶汽车,它在联网的情况下,仅仅运行8个小时便会产生4TB的数据;我们经常使用的淘宝网,每天产生的数据便可高达50TB。Intel公司首席执行官Brian Krzanich预计,在2020年网络用户平均每天将产生高达1.5GB的数据,根据Smart Insight的数据,目前全球每天都会产生大约50亿次的搜索,其中35亿次来自与谷歌,这占了全球总共搜索量的70%。这相当于每秒处理超过40,000次搜索。而在2000年,谷歌一年全部的搜索量才接近于140亿次。智能手机的普及使用让人们的社交生活越来越接近完全数字化,每天人们在社交网络上花费的时间也变得越来越多,产生的数据量也随之增加。据Facebook统计的数据,它每天会产生大约4PB的数据,其中包含100亿条消息以及1亿小时的视频观看和3.5亿张照片。在Instagram上,用户每天共享9500万次照片和视频,Twitter每天发送的信息数更是高达五亿条。这些增长的数据都对互联网公司以及政府的存储系统提出了挑战,怎样保证能存储这么多的数据以及怎样保证存储的数据的可靠性是一个热点的话题。
图1.1 2010年-2020年全球数据总量(ZB)
如图1.1所示是自2010年到2020年全球数据总量统计生成的柱状图,单位是ZB,其中2019和2020年的数据为预测数据。
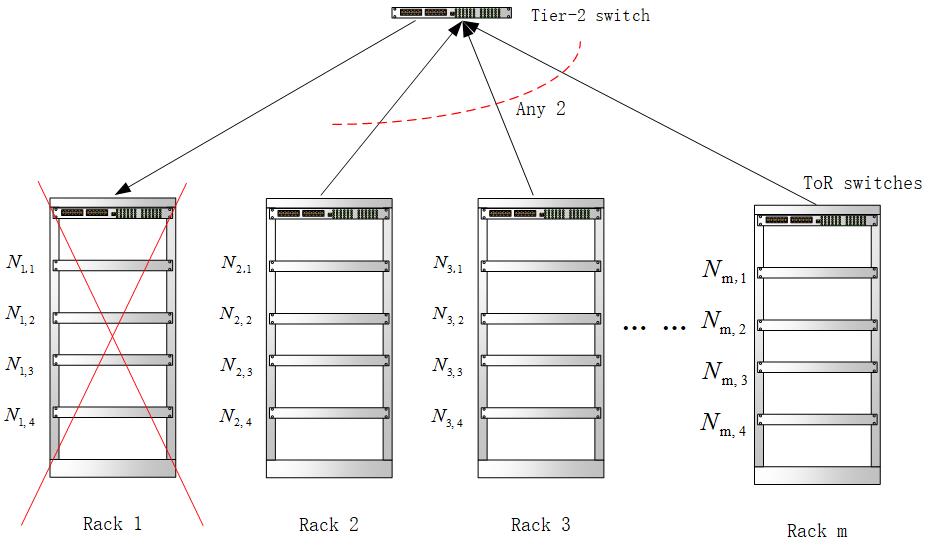
面对这些问题,科学家们提出了一种新型的存储系统-分布式存储系统。分布式存储系统的主要设计原则是将数据分别分配给多个独立的设备。由于传统网络存储系统设计结构的性质,存储服务器会导致系统性能瓶颈。当使用集中存储服务器为所有用户存储数据时,集中存储服务器的设计特性和潜在故障使该存储服务器成为安全性和可靠性的主要焦点,满足不了大规模存储的需求。分布式存储系统采用简化的存储系统,使用多个存储服务器同时共享存储库,并使用站点服务器来存储数据库中的所有资源,这样可以很容易地找到资源,还可以提高系统访问的可靠性,访问权限和有效性,还可以轻松地扩展。但是在面对如此巨大的数据量的存储时,分布式存储系统虽然展示了比较好的性能,但是面对日益增长的数据,怎样优化分布式存储系统也变得越来越急切。于是一种新模型的分布式存储系统被提出来--基于Rack模型的分布式存储系统。
面对海量数据的存储需求,谷歌、亚马逊、微软等云服务提供商将用户数据存放在位于全球不同位置的数据中心。在每一个数据中心,数据存储往往便是基于Rack模型的。基于Rack模型的分布式存储系统能够在降低成本的同时很好的保证数据的可靠性,使得在节点故障和Rack故障的时候,能够利用比较低的通信带宽修复故障,达到系统的性能要求。
1.2国内外研究现状及相关技术
分布式共享存储器(DSM)的概念最早由国内学者李凯于1986年提出。他的第一个分布式存储受到传统虚拟存储的启发。在虚拟存储系统中,访问不存在的页面可能导致页面在系统中中断,操作系统从硬盘检索页面并保存。李凯先生的设计与此过程类似,但区别在于它是从网络中其他设备的存储中获取所需的页面,而不是从实际内存中获取。存储空间不在同一台计算机上,但可以在逻辑上形成一个完整的虚拟空间。
随着计算机相关技术的迅猛发展,分布式存储系统的应用也迅速得到了普及。分布式存储系统的分类根据数据存储模型,分布式存储系统可分为以下类别:
- 分布式文件系统
分布式文件系统又称为网络文件系统,它的物理存储数据不一定是存储在本地节点上,而是通过网络连接,将物理数据与节点相连接。分布式文件系统可以提供多个用户同时访问,但是管理员只有一个。分布式文件系统可以有效的解决数据的存储和管理难题,它将存储节点分布在不同的地方,通过网络把存储节点相连接,让存储节点在网络间进行通信和传输。典型的分布式文件系统如GFS(Google文件系统),如图1.2所示,它是谷歌公司针对于自己公司的需求开发的非开源的分布式文件系统。GFS通过大量廉价的存储设备来当作存储节点,通过更优化的算法来提供容错功能,保证系统的可靠性。
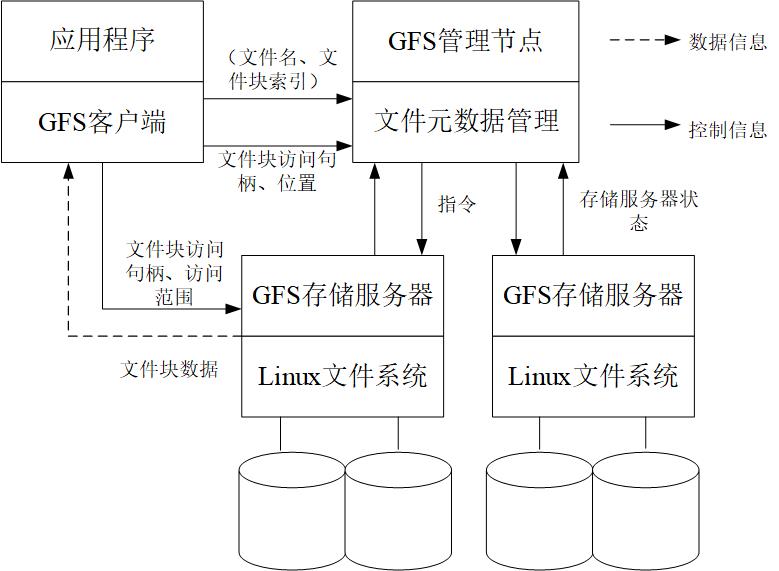
图1.2 GFS示意图
- 存储虚拟化
存储虚拟化是指对硬件存储资源的抽象,即将一个或者多个目标服务或者目标功能与其他附加的功能相集成,然后统一提供全面的全功能服务。存储虚拟化现广泛使用于互联网行业的各个领域,用于将原本复杂的底层技术简单化抽象化。存储虚拟化主要分为三种方法,即基于主机的虚拟存储、基于存储设备的虚拟化以及基于网络的虚拟存储,如图1.3所示。
存储虚拟化自诞生以来,历经了十多年的技术演进与消费市场的考验,现在在云服务市场上大放异彩,它对于云服务提供的好处包括可扩展性、无宕机数据管理以及更低的成本等。在现在,由于数据的不断增长,以及各种云服务的普及,各种操作系统的虚拟化,存储虚拟化必将成为企业降低存储成本以及运营成本的关键技术之一,在大数据存储领域必将迎来研究发展的热潮。
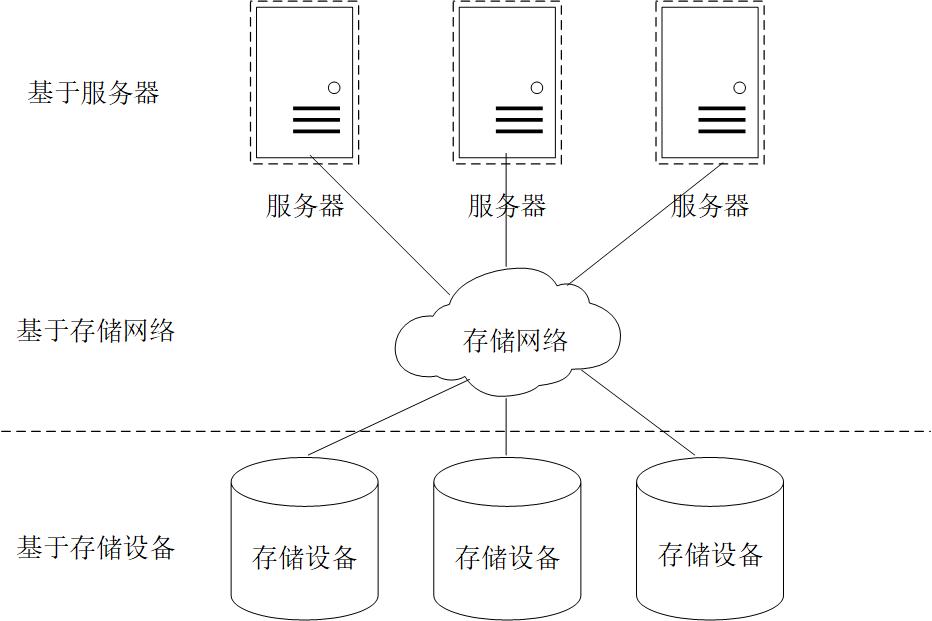
图1.3 基于技术分类的三种虚拟存储
3.分布式对象存储系统
对象存储设备的定义是:①全新的SCSI存储设备;②它的对象可以理解为传统的文件;③对象是自包含的,属性包括元数据、数据等;④存储设备可以确定对象的具体存储位置和数据的分布;⑤对象存储设备可以根据对象的不同,向他们提供不同的对象存储;⑥对象存储设备相比于传统设备而言,它们的智能性更高,而且它们的上层是通过对象的ID进行对于对象的访问,所以不需要知道对象的特定空间分布。
与传统存储模型相比,对象存储模型具有以下变化:①将存储模块被转移到了存储设备上;②将设备的访问接口改变成了对对象访问的接口[1]。
随着社会不断的进步,以及计算机技术的大力发展和大规模的应用,社会对于数据的存储和处理能力的要求越来越高,各类分布式存储系统的性能也越来越好,但是对于分布式存储系统的研究是一个长期的课题,特别是对于Rack模型的研究。
1.3课题研究内容
本课题主要针对于大型的数据存储中心,就失效数据的修复问题,研究基于Rack模型的分布式存储系统的以下几个方面:
(1)在分布式存储系统中,节点故障的概率非常高,所以我们需要设计一种节点修复机制,使得在节点故障时能够很好的修复故障节点,并且尽可能地节约修复带宽,控制成本。
(2)在基于Rack模型设计的分布式存储系统中,整个Rack故障的情况也时有发生。针对整个Rack故障的情况,要设计一种Rack修复机制,使得在整个Rack故障时能够很好地修复故障机架。
(3)由于数据在分布式存储系统中是分块存放的,所以当用户要使用原数据时,我们需要对原数据进行重构。针对用户使用数据的问题,设计数据重构机制,达到还原原数据的目的。
第2章 基于Rack模型的分布式存储相关技术分析
随着社会的快速发展,社会上各行各业数据量的不断增加,各种各样的分布式存储系统不断发展,也有着新一批的分布式存储系统模型被提出。这些模型不断优化,在进一步降低各种成本的同时,也显著地提高了分布式存储系统的可靠性,保证了用户使用的各方面需求。
2.1分布式存储的关键技术
(1)元数据管理
在当前大数据的整体环境下,鉴于元数据的体量是特别大的,所以对于原数据的访问性能就会关系到整个分布式存储系统的整体性能。在存储系统中,对于元数据的管理通常分为集中式的管理结构和分布式的管理结构。集中式的管理结构就是使用单个元数据服务器,这种管理结构相对比较简单,但是会存在单点故障的问题。而分布式的管理结构就是使用多个元数据管理节点,使用多个节点协调管理,分布式管理架构不仅可以避免元数据服务器性能瓶颈的问题,并且对于元数据管理架构的可扩展性起到了很好的优化。此外,某些分布式体系结构不使用元数据服务器,它通过在线算法组织数据,因此不需要专用的元数据服务器,但是该架构对于数据的一致性很难保障,实现也比较复杂,并且会存在文件目录操作效率低下的问题,这种架构还缺乏文件系统全局监控管理功能[2]。
(2)系统弹性扩展技术
在大数据的背景下,数据的大小和复杂性趋于快速增长,并且分布式存储系统的扩展性能要求相对较高。对于实现存储系统的高扩展性,我们必须要解决两个方面的问题,即解决元数据的分配和数据透明迁移的问题。第一,我们可以使用静态子树划分技术的方式来实现元数据的分配;第二,我们可以不断优化数据迁移的算法,通过对算法的优化来实现数据的透明迁移。此外,大数据的存储体系规模是非常庞大的,所以就会存在节点失效率很高的问题,因此我们还需要完成相应的自适应管理的功能,即存储系统会自动根据两个方面-数据量的大小和计算量的大小作为依据,通过这两个方面来自动计算需要调用的节点的数量,实现动态数据的节点迁移,借以来实现负载的均衡。同时,在节点失效的情况下,存储系统必须借助于设置的副本等机制来自动修复失效的节点,并且不能对上层的应用产生影响。
(3)存储层级内的优化技术
在实际设计分布式存储系统的时候,不应该仅仅从系统的可靠性、性能方面考虑,而是更要考虑到构建整个系统的成本因素。从以上两个方面综合考虑来设计分布式存储系统,通常会使用不同性价比的存储设备来构建分布式存储系统的不同功能层,借以更优化的算法来辅助实现系统的高可靠性。主要实现方式为:第一,为了降低构建存储系统的成本,通过对于存储的数据进行分析比较,将用户访问率低,比较冷门的数据存放在比较廉价的服务器节点上,这样可以在小幅度降低系统整体性能的情况下大幅度减小成本;第二,通过对数据的特征比较,将热点比较高的,使用频繁的数据进行缓存或者预取,通过高效的缓存预取算法和合理的缓存容量配比,借此来满足系统的高性能要求。这样不仅保证了系统的性能,还可以大幅度降低系统能耗和构建成本。
(4)针对应用和负载的存储优化技术
对于存储模型而言,为了要适应更多的应用,存储模型的结构必须得更加的通用化。现在,大规模的数据具有高动态以及快速处理的特性,所以就会导致传统存储结构中,对于应用而言比较通用化的模型,在面对数据时却显得不是那么通用,但是很多企业的关注度更高地在于上层应用的性能,忽略了对于数据存储系统的通用性的追求。而这类对于应用和负载的优化技术正好可以解决这一问题。这类技术简单地说,就是数据存储耦合到应用程序上,这样可以简化分布式存储系统的结构,进而扩展分布式存储系统的功能,通过简化或者扩展某一些特定的程序,某些特定的工作负载或者是某些特定的计算模型,就可以将文件存储系统进行定制,将文件系统进行详尽地优化,进而实现系统的最优性能。谷歌、Facebook等大型互联网公司,他们在公司的内部存储系统上采用了这类的优化技术,不仅实现了超过几千万亿字节级别的大数据的管理,还可以实现非常高的性能。
2.2 分布式存储系统的考虑因素
分布式存储系统,是在传统集中式存储系统不满足大规模数据存储的前提下,提出的一种新型架构的存储系统,它对于满足数据的大规模存储,以及存储系统的高扩展性和数据的爆发式增长具有很强的适应性。分布式存储系统主要具有以下几个特性:
(1)易于访问
分布式存储系统是针对海量大数据的存储而设计的,旨在降低存储成本的情况下还能保证系统的容错性和高可靠性。在分布式存储系统中,文件通常被分成不同的类型,不同类型的文件有着特定的存储服务器,如图2.1所示。这样即可以方便文件的管理,还可以针对不同文件类型的服务器选择不同性价比的设备,达到降低建设成本的目的。对于分布式存储系统的用户而言,他们事先存储数据时不需要知道他们的数据存放在什么地方,也不需要知道从哪一台服务器获取数据,只需要提出请求数据的需求,系统会自动根据他们的需求从相应的服务器获取数据供用户使用。
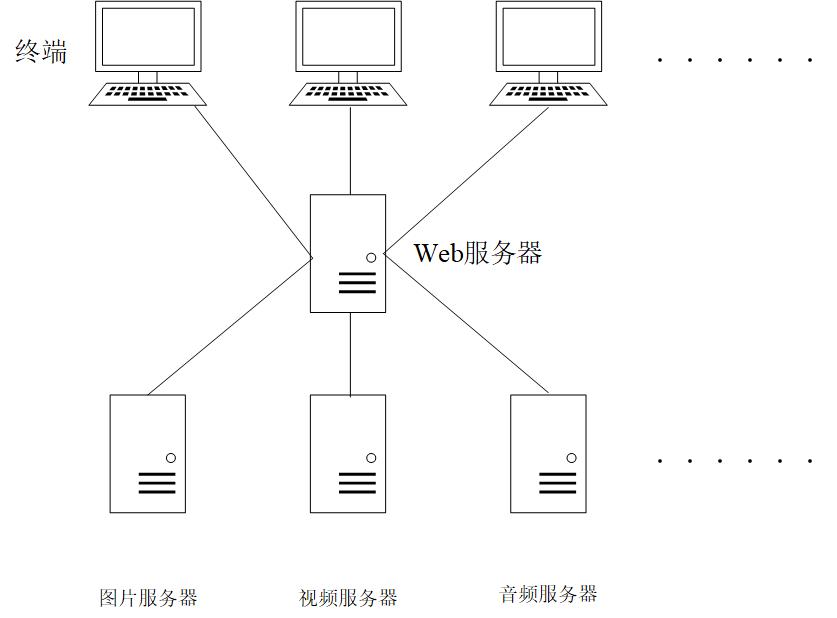
图2.1 特定文件类型服务器模拟图
(2) 安全性和可靠性
对于文件系统而言,由于设备的问题经常会存在某个存储节点发生故障的情况,所以保证系统的安全性和可靠性是一个比较重要的问题。对于分布式存储系统而言,它的文件系统由多个不同的节点构成,存放的文件按照一定的方式分割成大小相等的文件块,每个节点存放一定的文件块。针对于文件损坏或者节点故障的情况,分布式存储系统有一定的副本机制并设置相关的恢复机制,利用不同的存储节点来保证系统的安全性和可靠性。
(3) 可扩展性
针对于越来越多的数据以及越来越大规模的存储,分布式存储系统的提出可以很好的满足时代的需求。分布式存储系统具有很好的动态可伸缩性,当集群中存储的数据越来越多的时候,各个存储节点的磁盘容量就会变得越来越少,高伸缩性可以使得分布式存储系统很方便地进行系统扩展,满足越来越多大的数据存储需求。
(4) 负载平衡
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: