一种通过self-play掌握国际象棋、将棋的强化学习算法外文翻译资料
2022-12-18 15:41:49

英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
一种通过self-play掌握国际象棋、将棋的强化学习算法
David Silver1,2*dagger;, Thomas Hubert1*, Julian Schrittwieser1*, Ioannis Antonoglou1, Matthew Lai1, Arthur Guez1, Marc Lanctot1, Laurent Sifre1, Dharshan Kumaran1, Thore Graepel1, Timothy Lillicrap1, Karen Simonyan1, Demis Hassabis1dagger;
简介:国际象棋游戏是人工智能历史上研究时间最长的领域。最强大的程序是基于复杂的搜索技术、特定领域的适应和手工制作的评估功能的组合,这些功能已经被人类专家在几十年中改进了。相比之下,最近的AlphaGo Zero程序最近在围棋游戏中通过强化自玩学习来获得超人的表现,在本文中,我们将这种方法推广到一个单一的AlphaZero算法中,该算法可以在许多具有挑战性的游戏中实现超人的性能。从随机游戏开始,除了游戏规则之外,没有任何领域知识,AlphaZero令人信服地击败了国际象棋和日本象棋以及围棋的世界冠军程序。
正文:
对计算机国际象棋的研究和计算机科学本身一样古老。查尔斯·巴贝奇、艾伦·图灵、克劳德·香农和约翰·冯·诺依曼设计了硬件、算法和理论来分析和玩国际象棋。国际象棋后来成为一代人工智能研究人员的重大挑战任务,最终形成了高性能的计算机象棋程序,在超人的水平(1,2)上下棋。然而,这些系统是高度针对他们的领域,不能推广到其他游戏,如果没有大量的人类努力,而一般的游戏系统(3,4)仍然相对薄弱。
人工智能的一个长期目标是创建能够从第一原理中为自己学习的程序(5,6)。最近,AlphaGo Zero算法通过使用深度卷积神经网络(7,8)来表示GO知识,从而实现了围棋游戏中超人的性能。本文介绍了AlphaZero算法,它是AlphaGoZero算法的一个更通用的版本,它不需要特殊的大小写,而是可以容纳更广泛的游戏规则。我们将AlphaZero应用于棋类游戏、将棋游戏和Go游戏中,使用相同的算法和网络架构来处理这三种游戏。我们的结果表明,一个通用的强化学习算法可以学习,表格rasa-没有特定领域的人类知识或数据,正如同一算法成功地在多个领域-超人的性能跨越多个挑战游戏。
在1997年实现人工智能的里程碑,当时深蓝击败了人类世界国际象棋冠军(1)。在接下来的二十年里,计算机国际象棋程序继续稳步地超越人类水平。这些程序通过使用手工制作的功能和精心调整的权重来评估位置,由强大的人类玩家和程序员构建,再加上高性能的alpha-beta搜索,通过使用大量聪明的启发式方法和特定领域的适应性来扩展一个庞大的搜索树。在(10)中,我们描述这些增强,重点是2016年顶级国际象棋引擎锦标赛(TCEC)第九季世界冠军斯托克菲斯(11);其他强大的国际象棋程序,包括深蓝,使用非常相似的架构(1,12)。
就游戏树的复杂性而言,将棋是一种比国际象棋(13,14)要难得多的游戏:它是在一个更大的棋盘上玩的,棋子的种类比较多;任何捕获的对手棋子都会切换,随后可能会被扔到棋盘上的任何最强大的将棋项目,如2017年计算机行业协会(CSA)的世界冠军埃尔莫(Elmo),直到最近才击败了人类冠军(15)。这些程序使用的算法类似于计算机国际象棋程序使用的算法,同样是基于高度优化的alpha;-beta;搜索引擎,具有许多特定领域的适应性。
AlphaZero用深度神经网络、通用强化学习算法和通用树搜索算法取代传统游戏程序中手工知识和特定领域的增强。
AlphaZero使用参数theta;的深度神经网络(p,v)=ftheta;(S),而不是手工构建的评估函数和移动排序启发式算法。该神经网络ftheta;(s)以棋盘位置s为输入,对每个动作a和一个标量值v输出运动概率Pa向量,Pa=Pr(a|s),v从位置s估计博弈的预期结果z,vasymp;E[z|s]。AlphaZero完全从自我游戏中学习这些移动概率和价值估计,然后这些被用来指导它在未来游戏中的搜索。
AlphaZero使用的是通用蒙特卡罗树搜索(Mcts)算法,而不是带有特定领域增强功能的alpha-beta搜索,每个搜索都由一系列模拟的self-play游戏组成,这些游戏从根状态Sroot遍历一棵树,直到达到叶子状态。根据当前的神经网络ftheta;,在每个状态下选择低访问次数(以前不经常探索)、高移动概率和高值(在选择从s的模拟的叶子状态上的平均值)的移动a来进行每个模拟。搜索返回一个向量pi;表示移动的概率分布,pi;a=Pr(a|Sroot)。
图1
图1为培训AlphaZero 700 000步。ELO评分是从不同玩家之间的游戏中计算出来的,每个玩家每移动1s。(A)AlphaZero在国际象棋中的表现与2016年TCEC世界冠军方案Stockfish相比;(B)AlphaZero在Shogi的表现与2017年CSA世界冠军项目Elmo相比。(C)AlphaZero在GO中的性能与AlphaGo Lee和AlphaGo Zero相比(20 blocks over 3 days)。
从随机初始化参数theta;开始,通过自玩游戏中的强化学习来训练AlphaZero深层神经网络的参数theta;。每个游戏的方法是从当前位置Sroot=St,t为变量,依次运行一个MCTS,然后选择一个动作,at~pi;t,按概率(用于勘探)或贪婪地(用于开发)在根状态下的访问计数。在比赛结束时,根据游戏规则计算出终点位置ST来计算游戏输出结果:负1为输球,0为平局,1为胜利。更新神经网络参数theta;,以最小化预测结果vt与博弈结果z之间的误差,并使策略向量Pt与搜索概率pi;t的相似性最大化。特别的,参数theta;是通过损失函数l上的梯度下降来调整的,该函数对均方误差和交叉熵损失之和,其中c是控制L2权值正则化程度的参数。更新后的参数将用于随后的self-play游戏中。
本文描述的AlphaZero算法[见伪码(10)]在几个方面与原AlphaGoZero算法不同。
AlphaGoZero估计并优化了获胜的概率,利用围棋有双赢或输赢的事实。然而,国际象棋和shogi都可能以抽签结果告终;人们认为国际象棋的最佳解决方案是平局(16-18)。AlphaZero则估计并优化预期结果。
GO规则不受旋转和反射的影响。这一事实在AlphaGo和AlphaGo Zero中有两种方法。首先,通过为每个位置生成8个对称来增强培训数据。第二,在MCTS过程中,利用随机选择的旋转或反射变换板位置,然后用神经网络进行评价,从而使蒙特卡罗评价在不同的偏差下进行平均。为了适应更广泛的游戏类别,AlphaZero不具有对称性;国际象棋规则和shogi规则是不对称的(例如,棋子只向前移动,抛在王边和皇后边的棋子是不同的)。AlphaZero不增加训练数据,也不改变MCTS期间的位置。
在AlphaGoZero中,self-play游戏是由以前所有迭代中最好的玩家生成的。在每一次反复训练之后,新玩家的表现都会与最好的玩家进行比较;如果新玩家以55%的差距获胜,那么它就会取代最好的玩家。相反,AlphaZero只是维护一个不断更新的神经网络,而不是等待迭代完成。self-paly游戏总是通过使用这种神经网络的最新参数来生成。
与AlphaGoZero一样,棋盘状态仅根据每个游戏的基本规则由空间平面编码。动作由空间平面或平面向量编码,同样仅基于每个游戏(10)的基本规则。
AlphaGo Zero使用了一种特别适合使用的卷积神经网络结构:游戏规则是平移不变的(与卷积网络的权重分担结构相匹配),并且定义为与板上各点之间的邻接对应的自由(匹配卷积网络的局部结构)。国际象棋规则和shogi规则取决于位置(例如,棋子可以从第二级别向前移动两步,在第八级别上提升),并包括远距离交互作用(例如,女王可以一步地遍历棋盘)。尽管存在这些差异,AlphaZero仍然使用与AlphaGoZero相同的卷积网络体系结构,用于国际象棋、Shogi和Go。
图2
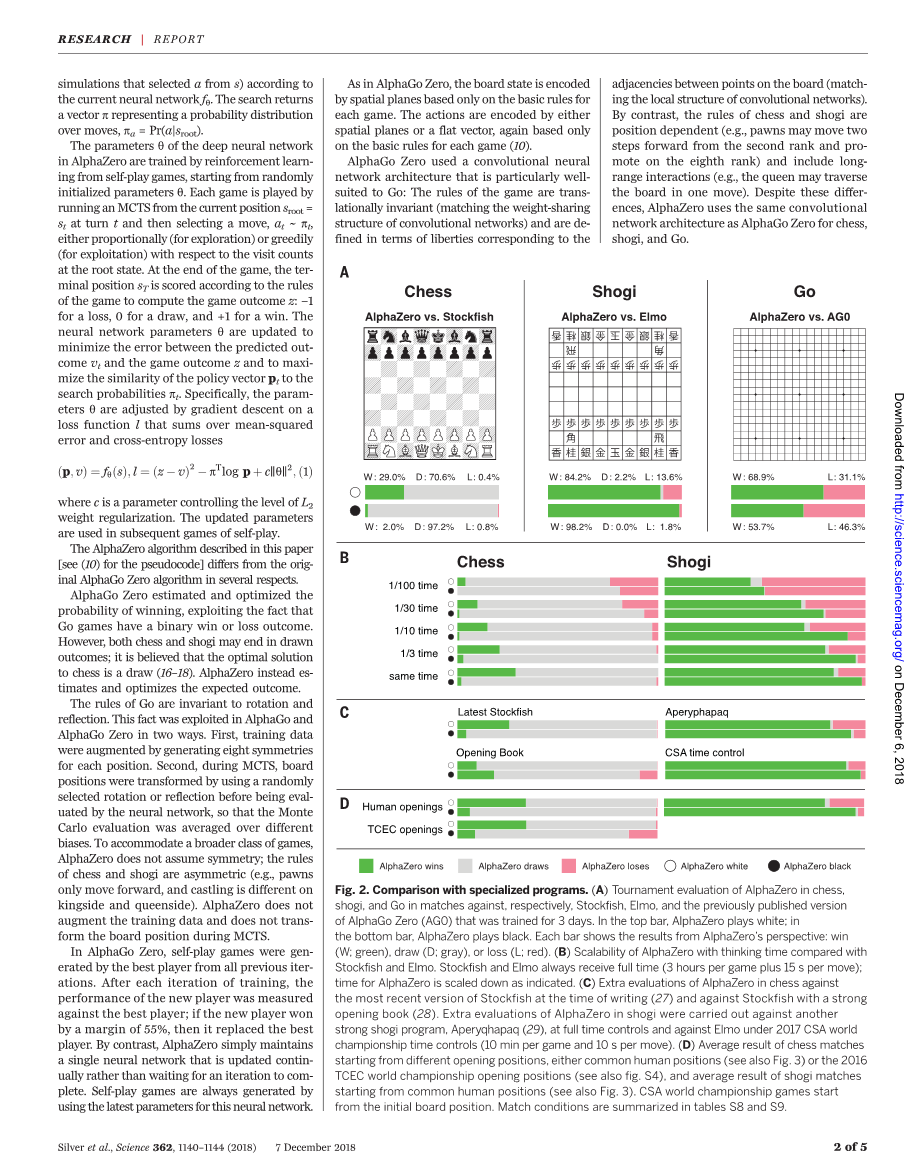
图2.与专门方案的比较。(A)对国际象棋中的AlphaZero、Shogi和Go分别与Stockfish、Elmo和先前公布的AlphaGo Zero(Ag0)版本进行3天训练的比赛评估。在顶部栏中,AlphaZero显示白色;在底部栏中,AlphaZero显示黑色。每个栏都显示了AlphaZero视角的结果:Win(W;绿色)、Pay(D;灰色)或失败(L;红色)。(B)AlphaZero的可伸缩性,与TOKFISH和ELMO相比,与思考时间相比较。TOKFISH和ELMO总是得到所有时间(每次游戏3小时加上每次移动15s);如所示,AlphaZero的时间被缩短了。(C)在编写本报告时,对国际象棋中的AlphaZero的最新版本进行额外的评估(27),并以一本强有力的开本书对Stockfish进行额外的评价(28)。对Shogi中的AlphaZero进行了额外的评估,针对另一个强大的shogi项目Aperyqhapaq(29)、全时间控制和2017年CSA下的Elmo世界锦标赛时间控制(每场比赛10分钟和每次移动10 s)。(D)从不同的开局位置开始的国际象棋比赛的平均结果,无论是普通的人类位置(另见图3)还是2016年TCEC世界锦标赛的开幕位置(另见图S4),以及从人类共同位置开始的平均比赛结果(另见图3)。CSA世界锦标赛比赛从最初的位置开始。表S8和S9总结了匹配条件。
采用贝叶斯优化方法对AlphaGoZero的超参数进行了优化。在AlphaZero中,我们为所有游戏重用相同的超参数、算法设置和网络架构,而不需要特定于游戏的调优。唯一的例外是探索噪声和学习速率时间表[详见(10)]。
我们分别为国际象棋、Shogi和Go训练了AlphaZero的例子。训练进行了70万步(小批量4096个训练),从随机初始化参数开始。仅在训练期间,使用了5000个第一代张量处理单元(TPU)(19)来生成自玩游戏,并使用16个第二代TPU来训练神经网络。国际象棋训练约9小时,Shogi训练12小时,围棋训练13天(见表S3)(20)。培训程序的进一步细节见(10)。
图3
图3.比赛从最受欢迎的人类开场白开始。AlphaZero在国际象棋中与(A) Stockfish和(B)在shogi中与Elmo比赛。在左边的栏中,AlphaZero从给定的位置开始玩白色游戏;在右边的栏中,AlphaZero播放黑色游戏。每个栏都显示了AlphaZero视角的结果:Win(绿色)、Drag(灰色)或Lost(红色)。AlphaZero选择的self-play训练游戏的百分比与训练时间(以小时为单位)成反比。
图1显示了AlphaZero在自我游戏强化学习中的表现,作为训练步骤的函数,在Elo(21)尺度(22)上。在国际象棋中,AlphaZero只需4小时(300,000步)就能首先超过Stockfish;在shogi,AlphaZero在2小时后(110,000步)首先优于Elmo;在围棋中,AlphaZero在30小时后(74,000步)首先优于AlphaGo Lee(9)。该训练算法在所有独立运行中都取得了相似的性能(参见图)。S3),表明AlphaZero训练算法的高性能是可重复的。
我们分别在国际象棋、Shogi和Go中评估了AlphaZero对Stockfish、Elmo和AlphaGoZero的完整训练实例。每个程序都是在设计它的硬件上运行的(23):Stockfish和Elmo使用了44个中央处理器(CPU)核心(就像TCEC世界锦标赛中的那样),而AlphaZero和AlphaGo Zero使用的是一台拥有四个第一代TPU和44个CPU核心(24个)的单机。国际象棋比赛是与2016年TCEC(第九季)世界冠军Stockfish进行的[详见(10)]。将棋比赛是与2017年CSA世界冠军Elmo (10)的比赛进行的。围棋比赛是与先前公布的AlphaGo Zero版本进行的[也训练了700,000步(25)]。所有的比赛都是通过每次比赛3小时的时间控制来进行的,而且每次移动都需要额外的15秒。
在围棋中,AlphaZero击败了AlphaGo Zero(9),赢得了61%的比赛。这表明,一种通用方法可以利用对称性生成8倍数据的算法的性能(见图1)。
在国际象棋中,AlphaZero打败了Stockfish,赢了155场,输掉了1000局中的6局(图2)。为了验证AlphaZero的强大,我们进行了从人类常见开局的额外匹配(图3)。AlphaZero在每次开局中都击败了Stockfish,这意味着AlphaZero已经掌握了广泛的国际象棋游戏。图3中的频率图和图S2中的时间线显示,在self-play游戏训练中,AlphaZero独立发现和经常使用人类常见的开开局。我们还打了一场比赛,从2016年TCEC世界锦标赛的开场位置开始;AlphaZero在这场比赛中也获得了令人信服的胜利(26)(图S4)。我们与最近开发的StockFish(27)版本和使用强有力的开本(28)的Stockfish变体进行了额外的匹配。AlphaZero以很大的优势赢得了所有比赛(图2)。
表S6显示了AlphaZero在与Stockfish的比赛中所玩的20场国际象棋比赛。在几个游戏中,AlphaZero为了长期的战略优势牺牲了棋子,这表明它比以前的国际象棋程序所使用的基于规则的评估具有
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[20180],资料为PDF文档或Word文档,PDF文档可免费转换为Word



