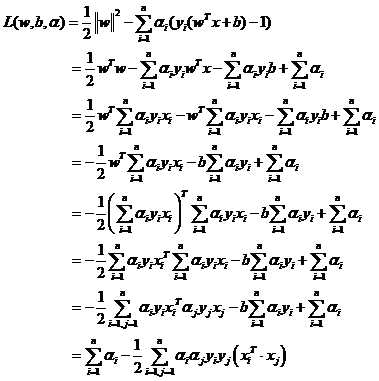SVM分类算法的研究与应用毕业论文
2020-05-21 22:19:22
摘 要
随着计算机网络技术的迅猛发展,采集与传输数据的过程变得较为快捷和便利,信息技术的难点早就不在数据的收集与产生,而在于如何对已知数据有效的处理与利用,挖掘出其中所存在的有用信息,从而促进了数据挖掘的飞速发展。支持向量机(SVM)算法作为一种来解决二分类和回归问题的一个强大工具,具有很多备受瞩目的优点以及较好的实验性能,同时随着数据的特征朝着复杂、高维、多变等方向发展,SVM算法越来越受到关注。
从支持向量机的基本理论知识出发,从线性可分的问题到线性不可分的问题,从最大间隔、最优决策超平面、核函数等方面来掌握SVM算法基本理论,进而对该算法的优点、缺点以及适用条件做出分析。同时为了使研究的算法有实际的意义,将SVM算法应用于网络广告点击欺诈(Click Fraud)检测问题中。首先对网络在线广告、付费方式以及网络广告点击欺诈相关知识进行了概述,点击欺诈问题主要是针对按点击付费模式(CPC)的广告而言的,已经破坏了稳定的网络在线广告系统,有效稳定的点击欺诈检测与防范机制是十分有必要的。之后对搜集到的真实的网络广告点击数据流从用户行为特征做出分析,为了便于预测模型的建立需要对数据进行一系列的预处理过程,如特征构造、特征选择等,最后将数据预处理后的特征数据集作为SVM的输入,进行训练学习得到最终的网络在线广告点击欺诈检测预测分类器。
通过实验最终得到网络广告点击欺诈检测模型,从一些度量指标等方面评估预测分类器模型的性能。实验结果表明,此算法能够有效的对点击欺诈的广告发布商进行检测,所以有一定的价值。
关键词: 支持向量机 按点击付费 点击欺诈 用户行为
The Research and Application of SVM Classification Algorithm
Abstract
With the rapid development of computer technology, data acquisition and data transmission process becomes faster and more convenient. Data acquisition and transmission is no more the difficulty of information technology, but lies on how to deal with the effective data processing and utilization in order to dig out useful information so as to promote the rapid development of data mining. As a powerful tool to solve the problem of binary classification and regression,Support Vector Machine (SVM) algorithm has many advantages and better experimental performance. At the same time with the characteristic data tend to be complex, high-dimensional, varied and so on, SVM algorithm catches more attention.
This article starts from the basic theoretical knowledge of SVM, from Linearly Separable to linear inseparable issues, from functional margin, from the optimal separating hyperplane, from the kernel function and so on to introduce the basic theory of SVM algorithm. Then we can make the analysis of the advantages and disadvantages of this algorithm and its application conditions. Meanwhile, in order to make the algorithm that we research has practical significance, the SVM algorithm is used in online advertising click fraud (Click Fraud) detecting problems. First, we make summary of the way of network ad delivery, payment mode and the relevant knowledge of clicks on online advertising fraud. Click fraud is mainly for ad that is concerned with Cost Per Click (CPC), which has destroying the stabilization of online advertising system. Effective and stable click fraud detection and prevention mechanisms are very necessary. Then we make analysis of the data flow that collected from real network ad from users’ behavior characteristics in order to facilitate the establishment of predictive models to make a series of data preprocessing, such as feature construction, feature selection and so on. Finally we take the preprocessed data as input of SVM, then get the final classified model of online advertising click fraud detection by training and learning.
We finally get online advertising click fraud detection model to assess or predict the performance of Classifier model from the accuracy, efficiency and so on through these experiments. It shows that this model can effectively detect the click fraud publishers so that it has a certain value.
Keywords: support vector machines (SVM); CPC; click fraud; user behavior
目 录
摘 要 I
Abstract II
第一章 绪 论 1
1.1 研究背景和意义 1
1.2 研究现状 2
1.3 系统目标和主要研究内容 3
1.3.1 系统目标 3
1.3.2 主要研究内容 3
1.4 本文组织结构 4
第二章 SVM分类算法 5
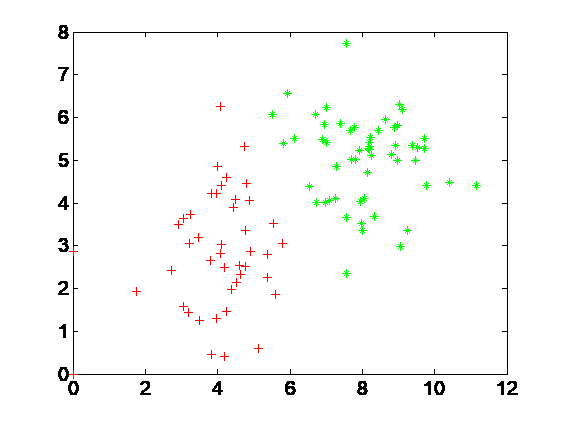
2.1 分类的基本概念 5
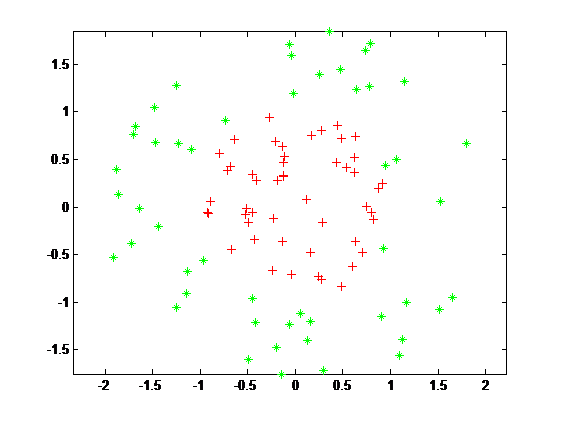
2.2 线性可分问题分类 7
2.2.1 线性分类器 7
2.2.2 最大间隔模型 8
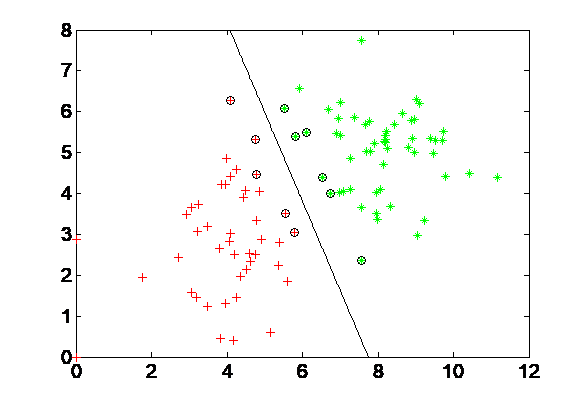
2.2.3 最优分类超平面 11
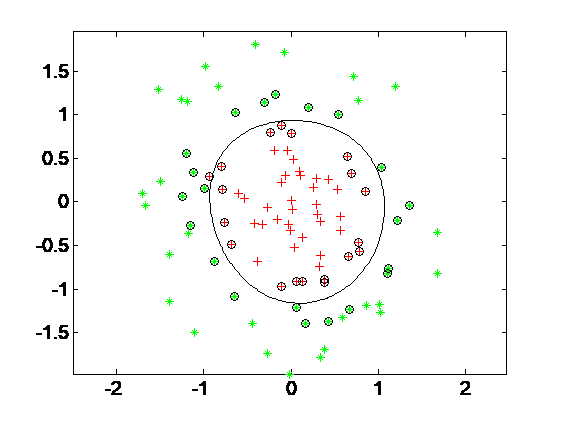
2.3 非线性可分问题分类 13
2.4 SVM分类算法分析 15
2.5 SVM在网络广告点击欺诈检测中的应用 16
2.5.1 网络在线广告 16
2.5.2 网络广告付费模式 17
2.5.3 网络广告点击欺诈 19
2.5.4 SVM应用于网络广告点击欺诈的检测方法 19
2.6 本章小结 21
第三章 数据预处理 22
3.1 点击数据流 22
3.1.1 数据来源 22
3.1.2 点击广告的基本特征 23
3.2 特征构造 25
3.3 数据特征选择 27
3.4 本章小结 29
第四章 基于SVM的网络广告点击欺诈检测系统 30
4.1 用户行为特征构建 30
4.1.1 用户行为数据 30
4.1.2 用户行为分析 30
4.2 点击欺诈检测系统框架 31
4.3 点击欺诈数据的训练和检测 32
4.3.1 点击欺诈数据集 32
4.3.2 SVM训练与预测模块 35
4.4 评估方法与指标 36
4.5 结果与分析 37
4.6 本章小结 41
第五章 总结与展望 42
5.1 总结 42
5.2 展望 42
参考文献 44
附 录 46
致 谢 52
第一章 绪 论
1.1 研究背景和意义
人工智能领域,用计算机模拟人类从以前的数据或者以往的知识中总结出规律的学习能力问题经常被称为机器学习问题。基于数据样本的机器学习任务就是设计某种方法或模型,对先前已知数据学习,找到数据样本隐含的一些联系或规律,进而利用所学习到的关系或规律对搜集到的未知数据进行预测和判断[1][2]。
随着移动互联网技术的迅猛发展,数据采集与数据传输变得较为便利和快捷,信息技术的难点已经不在数据的获取与传输,而在于如何对已知数据有效的处理与利用,挖掘出其中所存在的有用信息,从而促进了数据挖掘的飞速发展[3]。之前在以数据样本趋于无穷的基础上提出了传统的统计理论的一些学习方法,但现实生活应用问题中,我们面对的数据样本即使规模很大但一般都是有限的,之前很多机器学习方法开始表现出不好的推广能力,这称为过学习。为解决出现的这个问题,Vapnik等人不断专研,在20世纪70年代建立了一种在有限样本下统计和学习方法性质的理论,就是统计学习理论(Statistical Learning Theory,简称SLT),能较好的解决非线性、高维数等实际问题[4]。1995年,明确提出了支持向量机(Support Vector Machine,简称SVM)的概念,它是一种预知性学习算法[5],因其具有较好的泛化能力和辨别能力,引起了数据挖掘、模式识别和机器学习领域的关注。
目前,支持向量机算法作为一种来解决二分类和回归问题的一个强大工具,具有很多备受瞩目的优点以及较好的实验性能,同时随着数据的特征朝着复杂、高维、多变等方向发展,SVM算法越来越受到关注。数据维度越高说明数据表示越来越充分,但描述数据的特征增多,也会带来数据高维集上特征个数过多的 “维灾难”问题,由于“维灾难”问题的存在,目前很多分类方法只适合处理低维数据,但并不一定适合处理高维数据,这就使分类预测模型的性能有所下降[6]。而在数据挖掘的领域,SVM算法是比较有效可信的数据分类算法,因其拥有较少的过度拟合,以结构最小化为目标,所求的解是全局最优解,对于特征向量维数灾难影响不明显等优点而被广泛应用。
相关图片展示: