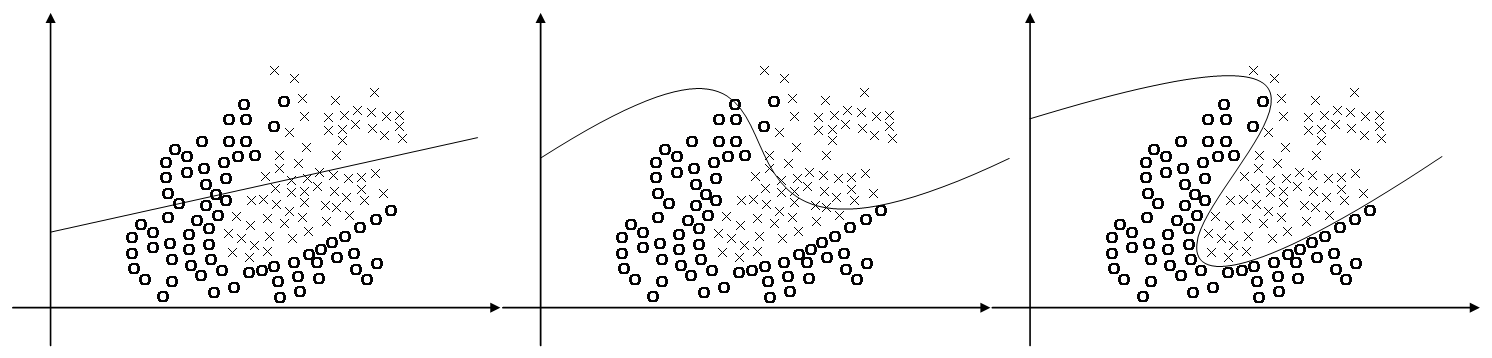基于卷积神经网络的印刷体数字识别毕业论文
2020-02-17 22:09:10
摘 要
印刷体数字识别(Printed Numeral Recognition)是光学字符识别(Optical Character Recognition, OCR)的一个分支,是在光学字符识别的基础上,利用计算机等工具对印刷体阿拉伯数字进行识别的技术,是文字识别的重要组成部分。本设计实现了一套以卷积神经网络为核心,通过对一般输入图像的处理,定位并提取出其中的印刷数字进行预处理,进而达成印刷体数字识别的完整系统。该系统测试识别准确率达到了99.23%。
在卷积神经网络设计部分,本文从神经网络的基本模型与原理出发,通过对卷积神经网络LeNet-5的原理分析,设计出本研究所使用的卷积神经网络模型。利用TensorFlow深度学习框架,自制印刷体数字数据集、搭建并训练神经网络,并使用自制数据集进行测试。测试结果验证了该神经网络在印刷体数字识别上的可行性。
通过图像处理技术与卷积神经网络的结合使用,本研究最终设计并实现了一种具有较高易用度与准确性的印刷体数字识别系统。
关键词:卷积神经网络;印刷体数字识别;数字图像处理;网络模型
Abstract
Printed numeral recognition is a branch of optical character recognition (OCR). Printed numeral recognition is a technology to distinguish printed Arabic numerals by means of computer and other tools on the basis of optical character recognition. It is an important part of character recognition. This design realizes a complete system of recognition of printed numerals, which takes Convolution Neural Network(CNN) as the core, locates and extracts the printed numerals from the input image by processing the general input image, and then achieves the recognition of printed numerals. In the test, the recognition accuracy of the system reaches 99.23%.
In the Part of designing CNN. Based on the basic model and principle of the neural network, this paper designs the convolution neural network model used in this study by analyzing the principle of the convolution neural network LeNet-5.Using the TensorFlow deep learning framework to make a printed numeral digital data set and, build and train the neural networks. By using the data set to test, the test results verify the feasibility of the neural network in printed numeral recognition.
By using image processing technology and CNN, a printed numeral recognition system with ease of use and accuracy is designed and implemented in this study.
Key Words: Convolutional Neural Network; Printed Numeral Recognition; Digital Image Processing; Network model
目 录
第1章 绪论 1
1.1研究目的及意义 1
1.2国内外研究现状 1
1.3研究基本内容 2
第2章 待识别印刷数字的预处理 4
2.1文档透视变换 4
2.2文档透视变换的步骤 5
2.3数字字符分割 6
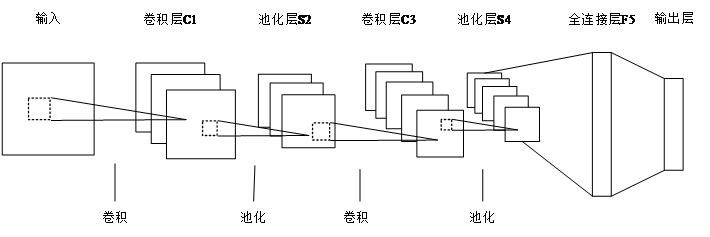
第3章 卷积神经网络 8
3.1神经网络概述 8
3.2神经网络的工作原理 10
3.3卷积神经网络概述 11
3.4卷积神经网络具体结构 15
第4章 卷积神经网络模型的训练与优化 17
4.1舍弃-Dropout 17
4.2 lp-norm正则化 18
4.3滑动平均 19
4.4 线性整流激活函数 19
4.5总结 21
第5章 印刷体数字识别的实现与结果分析 22
5.1印刷体数字数据集 22
5.2训练环境搭建 23
5.3模型训练过程 23
5.4模型优化 24
5.4.1 激活函数优化 24
5.4.2 Dropout优化 25
5.4.3 lp-norm正则化 26
5.4.4 滑动平均 26
5.4.5 优化后结果 27
5.5印刷体数字识别实现 28
第6章 总结 30
参考文献 31
致谢 33
第1章 绪论
1.1研究目的及意义
印刷体数字识别 (Printed Numeral Recognition)是在使用光学字符识别技术 (Optical Character Recognition, OCR)的基础上,使用计算机等工具自动对印刷体阿拉伯数字进行辨别的一种技术,是文字识别的重要组成部分。
印刷体数字识别存在其自身重要的应用场景,其可以用在多种领域,诸如应用在停车场的车牌识别、商业机构的票据数据的录入,印刷材料的电子备份,安检机构的身份证号识别等,涉及到金融、交通、银行、安防、教育和邮政等多个领域。印刷体数字识别它是字符识别的下的细化产物。在当前信息化大潮的发展影响下,对印刷体数字识别技术的需求也开始逐渐增长。研究发展出高准确度与高效率的自动化识别方式有其自身不可忽视的价值。随着深度学习对图像分类的研究兴起,给印刷体数字识别给了许多新的发展思路。卷积神经网络独特的其自身独特的特点诸如特征提取与权值共享等,可以提高识别印刷体数字时的准确度与泛用性,也提高了训练效率。
1.2国内外研究现状
OCR这一技术的概念最早提出于上个世纪30年代。上个世纪50年代左右,世界上有了第一个应用于商业的OCR系统。
60-70年代,由于字符识别所具有的巨大的商业潜力,世界各国都逐渐开始研究字符识别的相关技术。字符识别的范围从最初的数字、字母,逐渐发展扩增到汉字等各类文字字符,甚至于多语言字符的混合识别。虽然中国本土在上个世纪70年代才开始OCR技术的研究,但时至今日,通过数代科研工作者的不断努力,相关的技术产品也在不断推陈出新,在日常生活中也可以见到其广泛用于。
而深度学习技术的出现,为OCR的实现又带来了许多的可能。
深度学习方法的目的是学习特征层次结构,特征层次结构是由较低层次的特征构成的。在多个抽象层次上自动学习特性,允许系统学习将输入映射到直接从数据输出的复杂函数,而不完全依赖于人为设计的特性[1]。这对于更高层次的抽象尤其重要,人类通常不知道如何根据原始感官输入明确地指定抽象。随着数据量和应用程序到机器学习方法的范围不断增加,自动学习强大功能的能力将变得越来越重要。
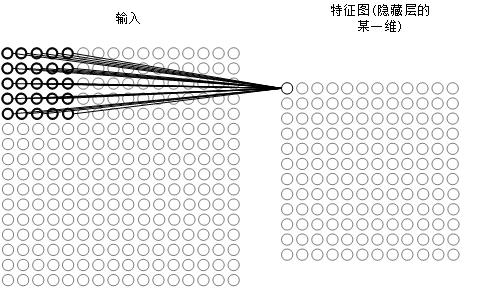
卷积神经网络(Convolutional Neural Networks, CNN)用于处理以多个数组形式出现的数据,例如由一个三通道的RGB色像,其中包含三个R、G、B这三通道中的像素强度。在实际应用场景中,数据通常以多个张量的形式进行描述:一维的信号和序列,包括音频信号;二维的单通道图像或音频频谱;三围的视频或多通道图像。利用自然信号的特性,卷积神经网络背后有四个关键思想:局部连接、权值共享、池化和使用多卷积核[2]。
近年来,卷积神经网络在人工智能及其应用(具体到计算机视觉)的发展中取得了显著的成就。卷积神经网络是一种特殊的多层前馈人工神经网络,它是一种深入学习的技术,广泛应用于计算机视觉、自然语言处理和计算机游戏的开发。卷积神经网络已成为开发商用计算机视觉应用程序的有用工具,用于识别图像对象、识别摄影中的人脸、自动驾驶汽车的路标识别、手写字符识别、视频监控和其他视觉任务[3]。
有许多算法技术已被开发出来,被用于实现卷积神经网络的不同人工智能应用。其中,LeNet-5是用于手写和机器打印字符识别的基础和重要的卷积神经网络体系结构之一[4]。LeCun及其合作者开发了Lenet-5卷积神经网络,推动了卷积神经网络在人工智能领域的发展,特别是图像识别。本文的卷积神经网络即采用这一结构的变体。
1.3研究基本内容
本设计旨在研究卷积神经网络的基本结构和训练等理论,了解其应用背景及研究现状,使用TensorFlow深度学习框架,以实现印刷体数字(包括各种不同字体)的提取与识别方法的设计,达到可以接受的印刷体数字识别的准确率,并在此基础上探究相应的改进方法。
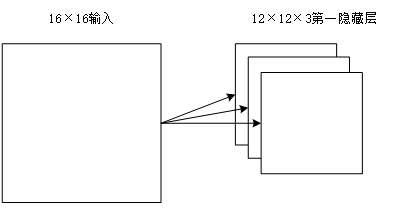
本设计实现对印刷体数字识别的总体流程如图1.1所示。通过数字图像处理的方法,实现对一般输入图像的处理,定位并提取出其中的印刷数字,送入训练好的神经网络进行识别,最终输出识别结果。其具体步骤为:印刷数字区域检测与定位、文字分割与文字提取、文字后处理。

图1.1 印刷体数字识别流程
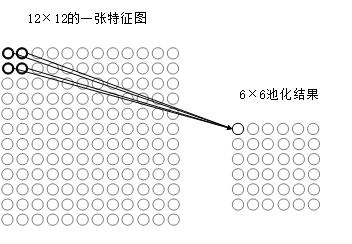
本研究设计的重点在于神经网络的识别部分,即通过研究网络LeNet-5模型结构与各层中的工作原理,确定并推导卷积神经网络训练时使用的前向传播、反向传播及梯度下降算法。对网络模型各层的训练参数以及初始化参数进行设计。利用TensorFlow深度学习框架搭建印刷体数字识别的LeNet-5模型结构,使用自制或现有的印刷体数字样本库训练和测试该网络模型。在此基础上实现基于卷积神经网络LeNet-5模型的印刷体数字识别。其设计框架如图1.2所示。

图1.2 神经网络设计框架
其中,数据集的制作是本研究的一项重要步骤。数据集包括训练集与测试集,前者用于神经网络的参数训练,后者用于测试神经网络的训练效果。最终对印刷数字识别的优良与否,与数据集有着密不可分的关系。
通过图像处理技术与卷积神经网络的结合使用,最终设计并实现一种具有高易用度与准确性的印刷体数字识别系统。
第2章 待识别印刷数字的预处理
为了能更好得定位并提取出待识别的数字,同时也为了便于保存与阅读的需要。首先将印刷有待识别数字的文档从图片中分割出来并加以透视变换以矫正,然后再对矫正后的文档中的印刷数字加以提取并。效果如图2.1所示


(a)原文档图片 (b)透视变换后

(c)提取出的归一化数字
图2.1 预处理示意图
2.1文档透视变换
透视变换(Perspective Transformation)是将图片投影到一个新的视平面(Viewing Plane),也称作投影映射(Projective Mapping)。通用的变换公式为:
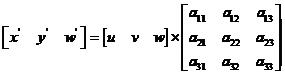 (2.1)
(2.1)
(u,v)为原始图像像素坐标,(x=x’/w’, y=y’/w’)为变换之后的图像像素坐标。透视变换矩阵T为:
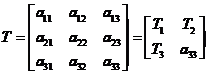 (2.2)
(2.2)
其中T1表示图像的线性变换,T2表示图像透视变换,T3表示图像平移。其中透视变换的数学表达式为:
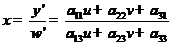 (2.3)
(2.3)
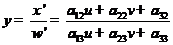 (2.4)
(2.4)
给定透视变换矩阵,即可对图像或像素点坐标完成透视变换;同理,若要解出透视变换矩阵,需要给定透视变换对应的四对像素点坐标。
所以需要完成文档透视变换,最重要的就是找到四组对应的像素点坐标进而求出透视变换矩阵。这里,选取文档的四个角的素点坐标解出透视变换矩阵。
2.2文档透视变换的步骤
解出透视变换的矩阵,首先要找到文档的四个角的素点坐标。提取文档角点一般采用直线检测的方法,即通过找到文档的边缘的直线及其交点,进而找到文档角点的方法。这种方法的检测效果较好,但计算量较大。对于文档角点的检测,本研究采取了一种更简单的方法,即通过寻找轮廓的方法从原始图像中分割出待识别图像并找到图像角点。这种方法的效果与使用直线检测的方法的效果差异不大。
提取文档角点主要分为以下几步:
一、将原始图像转化为灰度图像,并使用Otsu阈值分割转化为二值图像。
二、提取二值图像中的轮廓,并使用Douglas-Peucker算法对轮廓进行近似,即将轮廓形状近似到另外一种由更少点组成的轮廓形状。将由四个点组成的面积最大的近似轮廓判定为待识别文档的轮廓。而该近似轮廓的四点即判定为待识别文档的四个角点。
三、对四个角点进行判定,找出其与经透视变换后的文档角点对应关系,即这四个点分别与文档左上、左下、右上、右下的四个角对应。这里需要指出的是,第三步的先验知识是:文档的比例设定为99:70,即标准A4纸的长宽比。
四、通过步骤三的四组对应点,求出透视变换矩阵,并通过求出的透视变换矩阵,完成原图像的透视,得到待识别文档。
以上步骤的实现依靠OpenCV-Python实现,其中完成轮廓提取与文档近似轮廓判断的关键代码为:

2.3数字字符分割
从已完成透视变换的文档中分割出一个个的数字字符,是进行识别前的最后一步。本文进行数字字符分割的主要步骤为:灰度转换、滤波、二值化、定位分割、归一中心化等,利用OpenCV-Python为工具,具体步骤如下:
一、将读入的图片灰度化,并进行中值滤波。
二、使用固定阈值二值化的方法将灰度图像二值化,并将二值化后的图片颜色反转。
三、使用开运算将粘连在一起的数字分开。
四、提取二值图像中的轮廓,此时每一个轮廓都是一个待识别数字。将每一个轮廓分割后进行归一化处理。
其中,分割数字并归一化的关键代码为:

最终得到的归一化图片就是输入卷积神经网络的待识别图片,如图2.2所示。


(a)分割前文档 (b)分割出的数字

(c)归一化后的数字
图2.2 数字字符分割图像过程
第3章 卷积神经网络
3.1神经网络概述
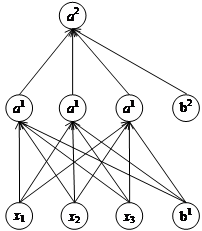
所谓机器学习,即是一种计算机利用已有数据创建模型,并使用这种模型就行预测的统计学方法,而神经网络即是一种非常重要的机器学习模型[5]。一个典型的神经网络如图3.1所示,这种机器所使用的结构模型,实际上是模仿生物的神经网络所搭建而成,其最基本的单位:神经元,也是模仿生物学上的神经元构建而成,如图3.2所示。

图3.1 典型的神经网络结构
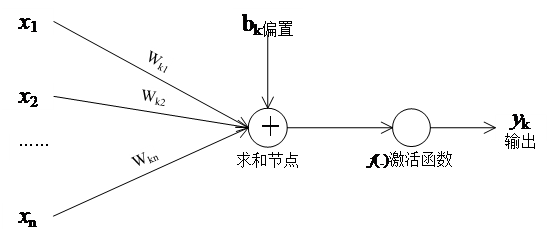
图3.2 神经元结构
神经元模型本质上是一个计算的节点,通过对输入的计算得到输出,而整个神经网络则是由许多个这样的节点按照一定的方式排布组合而成。如图3.2所示,x1~xn是节点的输入,每一个输入在附以对应的权值Wk1~Wk2后,进行求和,通常为了增强模型的表达能力,还会再加上偏置项bk,这一项也可以看作输入。在进行输入求和之后,会通过激活函数f(·)之后输出,yk就是该神经元最终输出结果[6],其表达式为:
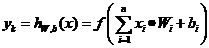 (3.1)
(3.1)
激活函数的目的是为了提升模型的表达能力,解决非线性问题。如果没有通过激活函数,输出yk只是一个线性输出[7],线性输出对于二分类问题的解决完全够用,但对于非线性划分就无法起到比较好的效果甚至于无法分割,如图3.3所示。加入激活函数的神经网络通过不断的训练,可以逐渐接近如图3.3(b)并最终达到的图3.3(c)的效果。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: