基于双向循环神经网络与CRF模型下的NER研究毕业论文
2020-02-17 22:00:14
摘 要
命名实体(Named Entity,NE)是包含人员、组织和位置等名称的短语。自然语言处理比较重要的众多基本任务之一,就是识别出这些短语以及这些短语间的联系,通常称之为命名实体识别。近年来,机器学习领域的成熟使神经网络应用在命名实体识别领域成为可能,让命名实体识别任务脱离传统规则的束缚。
本文正是对基于循环神经网络以及条件随机场模型下命名实体识别任务进行了初步探究。本文研究的基于神经网络的方法将特征提取的任务交给计算机来完成,有效的利用了计算机的计算能力,同时也可以充分利用文本信息中的特征。
本文使用的模型继承了深度学习的优点,无需大量人工特征,采用半监督的学习方法,使用双向循环网络语言模型,可以加强对于NE的识别能力,充分使用语料,并搭建起双向语言模型、双向循环神经网络和条件随机场的序列标注模型,以完成命名实体识别任务的初步了解与探究。
关键词:命名实体识别、循环神经网络、条件随机场、语言模型、自然语言处理
Abstract
Named Entity is a phrase that contains names such as people, organization, and location. One of the fundamental task natural language processing to identify these phrases and the cone- ctions between them. We usually call them named entity recognition. In recent years, the matur- ity of the machine learning field has made it possible for neural network applications to be used in the field of named entity recognition, allowing named entities to recognize tasks from the con- straints of traditional rules.
This paper is a preliminary exploration of the task of named entity recognition based on cy- clic neural network and conditional random field model. The neural network-based research me- thod assigns the task of feature extraction to the computer, effectively utilizes the computing po- wer of the computer, and can also make full use of the features in the text information.
The model used in this paper inherits the advantages of deep learning without a large num- ber of artificial features, adopts the semi-supervised learning method, and uses the bidirectional cyclic network language model, which can strengthen the ability of NER, make full use of corp- us, and set up the bidirectional language model, bidirectional cyclic neural network and conditi- onnal random field sequence labeling model, so as to complete the preliminary understanding and exploration of named entity identification task.
Keywords: Named Entity Recognition, Recurrent Neural Network, Condition Random Field, Language Model, Natural Language Processing
目录
摘要 I
Abstract II
第一章 绪论 1
1.1 课题研究背景及意义 1
1.2 国内外研究现状 3
1.3 论文内容安排 5
第二章 NER实现原理 6
2.1 基于规则的方法 6
2.2 基于统计的方法 7
2.2.1 概率判别模型 7
2.2.2 概率生成模型 8
2.2.3 条件随机场 9
2.3 循环神经网络 11
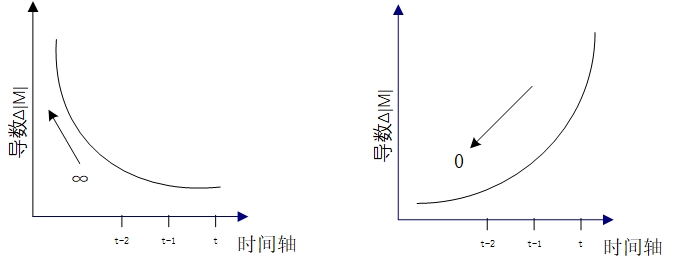
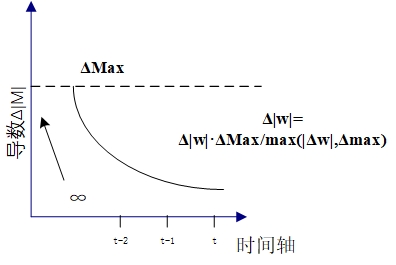
2.3.1 梯度爆炸与梯度消失 12
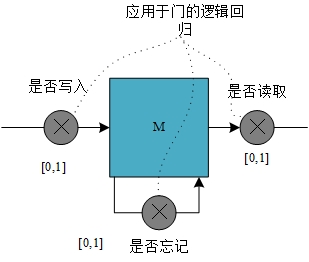
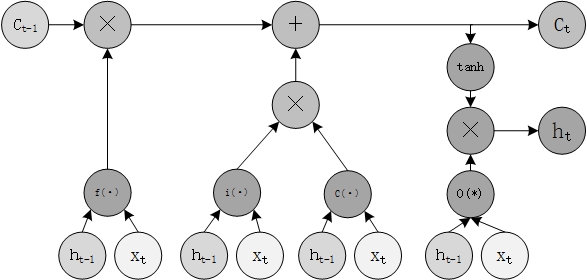
2.3.2 长短时记忆网络 13
2.3.3 门控循环单元 14
2.3.4 RNN应用领域简介 15
2.4 本章小结 16
第三章 NER模型搭建及训练 17
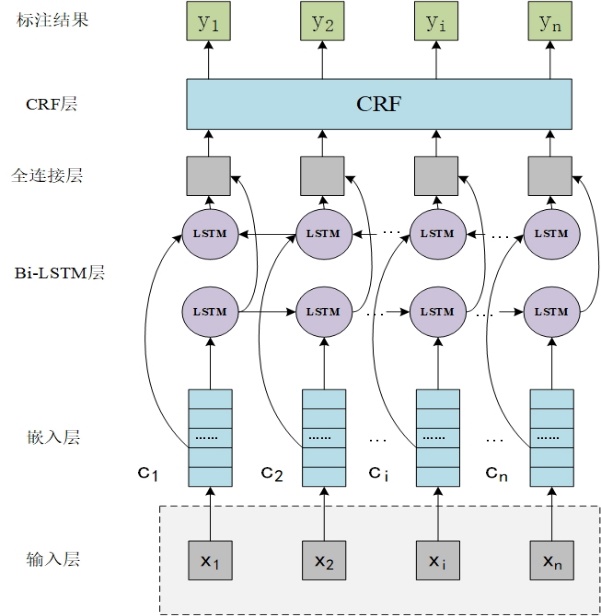
3.1 基于Bi-LSTM的NER模型 17
3.2 CRF标注模型 17
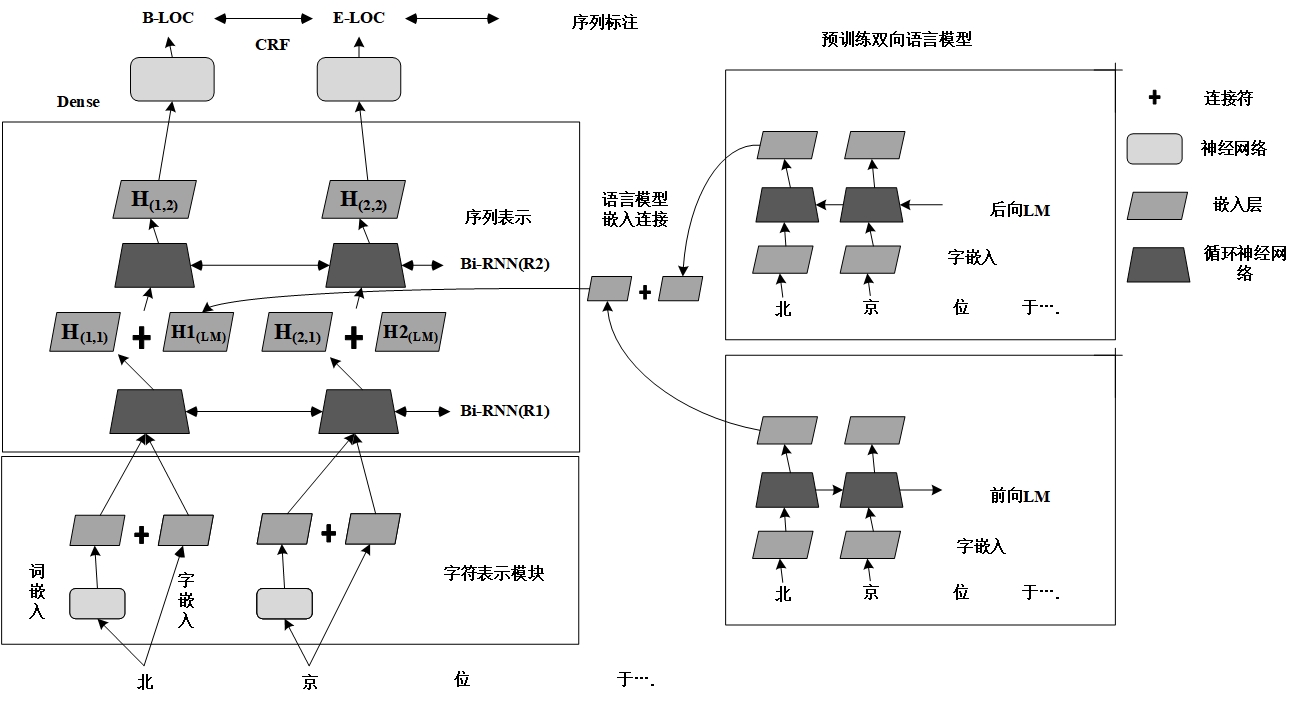
3.3 加入语言模型的改进模型 19
3.3.1基于神经网络的语言模型 19
3.3.2 将LM融入序列标注模型 20
3.4 实验与分析 21
3.4.1 实验数据、实验环境及评测方法 21
3.4.2 基线模型的训练 22
3.4.3 增强模型的训练 24
3.5 本章小结 26
第四章 总结及展望 27
参考文献 28
致谢 30
第一章 绪论
1.1 课题研究背景及意义
计算机硬件十年来的迅速升级与转型,让计算机视觉与通信的发展脚步越来越快,相应的互联网领域的革新也随之而来,这使得电子网络信息量呈现出一种前所未有的爆炸性增长的趋势,并且在今后的时间里会继续保持这种指数级的增长趋势。在这样的时代背景下,当务之急是要怎么样从非结构化的海量文本内容中迅速而又准确的搜寻到需要的信息,提取这些信息、并使用有效数据构建知识库。抽取信息的主要任务,就是研究的课题—命名实体识别。
NE识别作为NLP中的着重研究方向,其研究的进展,为信息提取、文本分类这些序列化数据处理任务打下了坚实基础,也为语言处理相关任务奠定了基石。因此,它也是NLP中的一个最基础的任务,但同时也是最为困难的任务。
机器学习的着重研究和应用方向之一就是自然语言处理任务。NLP技术为人与计算机之间的交互提供更加快捷、有效、方便的途径。简单的来说,就是要通过自然语言的运用,建立起各种处理它的计算机应用系统软件,如前面提到的相关技术。
NE识别是众多NLP技术的重要基石,凡是关于基础语言分析研究,都或多或少的收到命名实体识别的影响。由此可见,NE识别的研究意义不言而喻。接下来对上文提到的相关研究技术进行简单介绍。
(1)信息提取。提取文本中的某一类信息,通过特定的手段和算法,将其形成结构化的数据,称之为信息提取,其首要任务,就是我们研究的课题—命名实体识别。例如,当需要提取文本中事件发生的额时间、地点、任务等相关信息时,命名实体识别实现信息提取做出了第一步,提供了极大的帮助。
(2)机器翻译。众所周知机器翻译的难点,是对于专有名词,例如如地点名称、人物名称、组织或者机构名的精准翻译,需要正确、有效的抽取取和辨识出文本中的命名实体。
(3)信息检索。命名实体就是文本信息的基本单位。对文本中的命名实体提取并分析,能更有效的定位到相关的文档,为信息检索提供更加快速且正确的答案。
(4)问答系统,当使用者向系统提出一个问题:“腾讯的创办者是谁?”时,且在某篇文章中包含有“腾讯的创办者是谁”的信息,系统要能够根据问题,从这篇文档中提取出足够的信息并对其进行分析,然后做出相应的正确回应。从根本上来讲,要达到这个目的,最最基本的,得识别出文本中的NE,对例子中的问题来说,就是问答系统要能准确识别所有人名,这是最基础的能力,只有在此基础上才有发展系统的可能性。
命名实体识别作为自然语言处理中一个相当有挑战性的问题,首先需要的,是一套行之有效的并且可供世界范围内参考的处理标准。近年来,关于命名实体识别研究的热度不减反增,国内国外许多团体及会议都关注着命名实体识别的研究进展。
MUC (Message Understanding Conference,MUC),就是信息理解会议。在上个世纪,这个会议曾是推动了NLP研究发展的主要力量。在第六届MUC上,作为NLP一个评测任务,NER被首次提出来的。上世纪九十年代中期举行得第六届信息理解会议上,“命名实体”首次出现在大型会议上。随后英文NE识别的评测任务就被提出了。在这之后的一系列关于NLP的会议中,NE识别都被作为其中的一项指定任务收到广泛关注。
在2004年度NER评测大纲中,“命名实体、时间表达式和数字表达式,就是NER任务主要的三个子任务。命名实体、时间及数量即为标注的表达式”这一NER识别任务科学定义被国家863命名实体识别评测小组所提出。
2000年12月,美国国家标准技术研究所组织提出了自动内容提取(Automatic Content Extraction,ACE)评测会议,这一会议把实体识别作为其两大评测任务之一。NE是实体的一个子集,而命名实体识别也可看作为实体识别工作的子任务。他的任务相对于其它评测会议而言难度大得多,评测工作一般只有少数组织能够完成。
命名实体识别是否正确的,取决于实体边界的识别和实体的类型识别。
汉语实体与英文实体大为不同,其识别任务要更艰巨,更复杂。NE识别发展至今,不可否认已经取得了较大的成功,然而值得注意的是,由于中文自身的特殊性以及NE的灵活性、多变性和发展性,导致中文的NE识别的研究进展相较于英文而言缓慢许多,其中主要困难包括:
(1)NE类型多多种多样样,数量就更不必多说,新的命名实体每分每秒都在生成,如新的人名、地点名等,且旧的命名实体随着时代的改变可能会发生变化。
(2)命名实体结构复杂,某些类型的实体词没有定长限制。
(3)在一篇文档中,标点、拼写和文本格式等都会对NE识别产生影响。
(4)写法的多种多样性。一般在文本中,如果命名实体首次出现后,以后的出现常以缩写形式代替。这往往导致与其他普通词混淆,最终遗漏识别。举两个例子,“北京大学”的缩写为“北大”,“武汉理工大学”的缩写为“武理”
(6)歧义现象。有些相同的命名实体,在不同的语境中或者说不同的上下文中代表的意思也是不同的。比如,“高峰”不仅可以代表一个旅游景点,同样可以是一个普通词。
除去这些常见的问题,还有许多影响因素未被列出,这些因素的存在加大了实体识别的难度系数,让当前的中文命名实体识别工作的科研水平远远落后于英文的工作进度。因此,需要做的工作还很多。
1.2 国内外研究现状
由于预训练词向量的简单以及有效性,使其几乎无处不在的活跃在NLP系统中。Mikolov等人的工作表明,它们捕获了有用的语义和句法信息[1];Collobert等人的工作表明,包含预训练词向量的NLP系统被证明对于下游任务有非常巨大的帮助[2]。
然而,对于许多NLP任务来说,词语的语义表示和词语在文本中的上下文关系同样重要。杨,Ma和Hovy,以及Lample和Hashimoto的工作提供了一种基于双向LSTM以及条件随机场的序列标注模型,使得当前的序列标注模型普遍使用一种双向循环神经网络[3]。在对token进行预测之前,把token序列编码成上下文敏感表示形式。尽管使用预训练词嵌入来初始化token表示,但通常仅仅在标注数据上学习双向RNN的模型参数。之前的工作探索了使用来自其他任务的补充标注数据联合学习双向RNN的方法。除此之外,Santos、Guimaraes研究的基于字符向量的增强命名实体识别,使用了DNN作为基本架构,对于自动学习特征有很大的影响[4];Peters、Ammar和Bhagavatula对于语言模型在NER中的运用解释十分详细[5];周俊生等人设计了一种层叠的条件随机场模型,对于大规模语料的开放测试中达到了88.12%准确率[6];王、樊二人研究了专门针对短文本中实体识别的紧缺任务,提供了一种快速有效的识别方法[7];李、郭对于医学领域的命名实体识别进行探究,提出一种基于卷积网络和长短时记忆网络的模型,使用卷积网络提取特征并用于序列标注任务,取得了89.09%的较好结果[8];张海楠、伍大勇等人提出基于深度神经网络的中文命名实体识别,在1998年人民日报语料上加入字、词特征的测试结果F值高达96.8%(单指人名)[9];朱、杨等人提出一种基于汉字级别的循环神经网络的方法,面对机构识别困难的问题,重定义机构名的输入输出,在机构名的预测方向效果明显[10];张、李二人提出另一种基于Bi-LSTM模型的分词方法,好的分词方法可以很好的提高识别效果[11];张、任等人比较了不同识别特征对于识别效果的提升效果[12];王与Josh的研究向我们展示了命名实体识别的具体应用[13];孙、王等人的NER综述总结了近年来中文命名实体识别的发展情况以及展望了未来几年的发展趋势[14];王、沈的融合迁移学习的中文实体识别解决了识别模型可移植性差、跨域识别能力差的问题,同时降低了标注任务的工作量,取得了不错的成果[15];YANG和William的工作做的也是迁移学习方面的工作,他们主要完成了基于分级循环神经网络的序列标注模型的搭建[16];郭、王等人研究半监督学习方面的内容,他们使用重访特征向量的方法,提出一种分布式的原型,更好的利用词的特征向量,以取得更好的结果[17];黄、郑等人结合当下时代背景提出针对产品的识别方法,引入半监督的学习方法,用较少的手工标记数据实现了目的[18];黄、余等人提出双向长短时记忆及条件随机场模型,完成序列标注任务,他们的模型相对于之前的而言具有强健性且对词向量的依赖较小[19];Yoram Bachrach和 Sam Coope的工作,提出了一种基于并行循环神经网络的实体识别方法,减少了参数量,达到了比较好的训练效果[20]。
本文探索了一种不同的半监督方法,它不需要额外的标注数据,在原语料基础就可以提高识别效果。本文使用神经语言模型(Language Model,LM),在大规模未标记语料库上进行预训练,以计算序列中每个位置的上下文编码,并在监督序列标注模型中使用它。由于LM向量用于表示神经语言模型中未来单词的概率,因此它可可在上下文中编码单词的语义和句法特征。
本文旨在为命名实体识别的研究任务提供一种思路,之前的NER系统大多都依赖于手工特征和像词性标注以及文本分块等NLP处理结果,在这种背景下的NER任务,他们期望从较少的监督学习的语料中得到有效的域内知识,从而完成识别任务。可以了解到,传统的NER识别效果,与手工特征以及大量有效的标签语料息息相关;但事与愿违,前者耗时耗力且迁移能力较差,只在特定领域取得较好的效果,而一旦将模型运用到其他相关性较差领域,结果往往不尽人意;而后者也是如此,大量标签语料往往是研究中最为缺失的材料。
对人工设计特征过于依赖,是传统实体识别方法的主要弊端,面对爆炸性的文本文件的识别会有许多不足。而人工智能的不断革新,许多新的模型的提出,使得人工神经网络在命名实体识别任务中的地位越来越高,其应用也愈发普遍。直接跳过人工设计特征步骤,是深度学习在实体识别应用带来的主要收获,与此同时顺带解决稀缺注释数据以及造成词向量稀疏表示带来的的维数灾难的问题。在这种大趋势下,发掘新模型、改进模型、分析对比模型是NER研究的首要任务,也是本文的关注点所在。
1.3 论文内容安排
第一章:绪论,对NLP和NE识别的研究情况以及进展进行了简单介绍,进一步解释实体识别技术的影响力以及研究意义。随后总结国内外研究进展,在此基础上整理并确定近年来命名实体识别的研究发展方向。
第二章:命名实体识别方法介绍,围绕目标任务,介绍了解决实体识别任务常用方法并分析了各自的优劣。然后,进行了循环神经网络基本结构、基本记忆单元工作原理、长短时记忆网络和门控循环单元的介绍。
第三章:介绍基线模型——基于Bi-LSTM以及条件随机场的标注模型以及设计方法。引入一种半监督学习的方法,构建Bi-LM和Bi-LSTM-CRF模型。在这一章,介绍了循环神经网络语言模型在序列处理中的建模方法。随后,将语言模型与基线模型结合,构建最终模型。在后半节,对实验数据和评价方法介绍,具体实验流程,训练模型与预训练模型,分析数据集以及常见问题,以及相关问题的介绍。
第四章:结语,对本文的探究进行总结。
第二章 NER实现原理
NE识别是NLP下的一个任务,因此也会不可避免的受其影响。NER任务的完成有两条路径:建立规则完成识别或者直接将任务交予统计学原理,总结起来,一是基于规则,二则是基于统计。
一般来说,规则一般由语言学专家主持设计,因此它更加接近人的思维方式一些,优点是便于理解;同时缺陷也十分明显,规则的编写常常依赖于具体的语言和领域,同时其迁移能力较差,编写规则的流程相当麻烦,这其中需要专业领域的专家费时费力才能完成。相较于编写规则的方法,依靠统计学基本原理的方法要灵活许多,这种方法最大的特点就是客观性,对于人工特征以及领域知识的依赖性远远低于前者。
2.1 基于规则的方法
也被称为基于传统经验的方法,在一切开始的时候,研究者认为要使计算机正确完成自然语言相关的处理工作,就必须像人的大脑一样去工作,再此基础上,由人类语言学家牵头,开始对人类的自然语言的规则进行总结、分解、构析,最终完成自然语言的规则编写,并将其应用在计算机系统中,作为自然语言处理的基准法则。
基于传统经验的方法中,除了使用各种命名实体的构成规则外,NE识别还会使用实体本身与上下文的关系以及用词情况。在这里举一个简单的例子:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: