支持基于新词发现社科数据的文本分词器设计研究与应用实现毕业论文
2020-02-17 21:46:28
摘 要
在自然语言处理领域,文本分词技术是中文信息处理的基础,良好的文本分词系统可以极大提高信息存储与信息检索的效率。随着中文互联网信息的爆炸式增长,中文文本分词技术越来越受到研究者的重视。
本文利用Java语言构建了一个支持新词发现的中文分词系统。首先,本文介绍了传统的机械分词方法,并通过改进匹配法则构建了基于词典的分词模型;其次,针对未登录词识别问题,以隐马尔可夫模型为基础构建了新词发现模型;接着,借助Java语言完成分词系统的模块化设计,取得了较好的分词效果并成功实现了新词发现;最后,对分词系统的性能进行检验,验证了设计的正确性。
本文的创新性在于,通过建立隐马尔可夫模型,挖掘出了文本的隐藏状态信息,克服了机械分词法无法识别新词的缺陷。设计完成的系统具有推广意义,可推广到词性标注、情感分析等应用场景中。
关键词:自然语言处理;中文分词;隐马尔可夫模型;新词发现
Abstract
In the field of natural language processing, text segmentation technology is the basis of Chinese information processing, and a good text segmentation system can greatly improve the efficiency of information storage and information retrieval. With the explosive growth of Chinese Internet information, Chinese text segmentation technology has been paid more and more attention by researchers.
This paper constructs a Chinese word segmentation system to support neologism discovery using Java language. Firstly, this paper introduces the traditional mechanical word segmentation method, and constructs a lexicographical word segmentation model by improving the matching rule. Secondly, a neologism discovery model is constructed based on the hidden markov model for the recognition of unknown words. Then, with the help of Java language, the modular design of the word segmentation system is completed, which achieves a good word segmentation effect and successfully realizes the discovery of new words. Finally, the performance of the word segmentation system is tested to verify the correctness of the design.
The innovation of this paper lies in that the hidden state information of the text is mined through the establishment of hidden markov model, which overcomes the defect that the mechanical segmentation can't recognize new words. The designed system has the significance of generalization and can be extended to the application scenarios such as part of speech tagging and emotion analysis.
Key Words:Natural language processing; Chinese segmentation; Hidden markov model; New word detection
目 录
第1章 绪论 1
1.1 论文研究背景与意义 1
1.2 论文研究的目的与内容 2
第2章 基于前缀词典的中文分词算法 3
2.1 基于词典的正向最大匹配法 3
2.2 基于Trie树的前缀词典构造 4
2.3 基于有向无环图的分词集合 5
2.4 动态规划求解最大概率路径 6
第3章 基于隐马尔可夫模型的新词发现算法 8
3.1 隐马尔可夫模型概念介绍 8
3.2 新词发现模型的建立 9
3.3 基于Viterbi算法的新词发现模型求解 11
第4章 支持新词发现的分词系统实现与验证 13
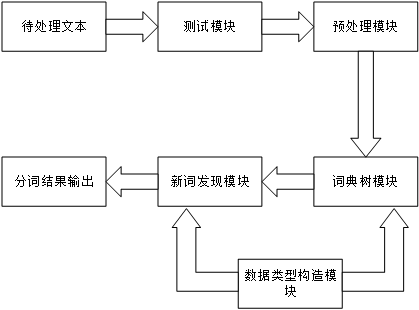
4.1 分词系统综述 13
4.2 预处理模块的设计与实现 14
4.3 数据类型构造模块的设计与实现 15
4.4 词典树模块的设计与实现 16
4.5 新词发现模块的设计与实现 18
4.6 测试模块的设计与实现 20
4.7 分词系统性能检验与结果分析 22
第5章 总结与展望 24
5.1 工作总结 24
5.2 未来工作展望 24
参考文献 25
致谢 26
第1章 绪论
在自然语言处理领域,中文文本分词技术一直是中文信息处理的基础。中文分词是指在完整的中文语句中寻找词的边界并以此将语句切分成连续的词序列的过程。中文分词技术在信息检索、机器翻译等领域有着广阔的应用前景。
1.1 论文研究背景与意义
随着移动互联网的普及,中国互联网用户规模日益增大,伴随而来的是中文网络信息的爆发式增长。互联网上海量的中文信息,一方面对于计算机系统的数据存储提出了挑战,另一方面也提高了信息检索的难度[1]。
硬件技术的更迭、芯片制造工艺的进步以及诸如分布式存储系统等新的存储方式的出现,使得大规模数据存储的问题有了有效的解决方案,但在面对信息检索问题时,仅仅依靠硬件的提升的难以提高信息检索的效率,这也成为了制约搜索引擎技术发展的瓶颈。
当今世界上比较著名的搜索引擎,例如百度、谷歌等,均采用以字为单位的信息检索策略,这样的检索方式可以提高搜索结果的精确度,但从一方面来讲提高了搜索的计算成本与实践成本。因此,从提高信息检索效率的角度出发,可以考虑采用以词为单位的信息检索方式[2]。
以词为单位进行检索,需要搜索引擎分辨出中文信息里的词汇,即分词技术。然而,以中文为代表的亚洲语言文字,包括日文、韩文等,缺少像英文一样以空格为词间间隔的天然分隔符,在文本分词领域的难度要远强于西方的语言文字。
文本分词技术属于自然语言处理的范畴,旨在通过控制机器对人类的语言文字进行认知与应用,是人工智能的重要一环。通过文本分词技术的研究,一方面可以促进人类对语言学习与发展的认知,另一方面构建了计算机技术与复杂的现实世界沟通的桥梁,拓宽了计算机的使用场景,更进一步地可以催生更多产业,方便大众生活,促进国民经济进步与科学技术发展[3]。
自上个世纪八十年代开始,中文分词技术便成为了自然语言处理领域的研究热点。第一个实用的中文分词系统诞生于北京航空航天大学,此后清华大学、哈尔滨工业大学等著名高等院校以及微软、百度、搜狗等商业公司均不断改进并提出新的分词系统。特别是在深度学习被广泛应用以后,中文分词技术迎来新的发展方向[4]。
当然,无论是传统的机械分词方法或是基于深度学习的智能分词方法,当前的分词技术仍然不成熟,特别是在面对未登录词的问题上,对新词的识别能力不强,这也是当前研究亟待解决的问题。
1.2 论文研究的目的与内容
中文分词中两个主要障碍是歧义问题与未登录词问题,这也是分词系统问题研究的方向。歧义问题主要指同样的中文语句,在不同的分词算法下可能存在不同的切分方法,造成文本理解出现歧义。未登录词则是指以新词为主的尚未收录进词典的词[5]。
歧义问题的解决主要包括两种方法,一种是词性标注处理法,利用文本中隐含的词义信息进行词性标注,在遇到歧义切分时,通过处理词性的规则来规避歧义。另一种是利用统计信息,统计歧义切分时各个词的词频,通过全局概率最大化实现歧义消除。
未登录词由于其未被词典收录的特殊性,问题的复杂程度远比歧义问题高,因此成为分词算法研究中最重要的研究对象。
目前,主流的分词方法包括三种:基于字典的匹配法分词、基于人工智能的语义理解分词以及基于统计法的字间凝固度分词,三种方法各有其优缺点,如何发挥各自方法的优点是本文研究的重点[6]。
在三种分词方法中,基于字典的匹配法分词是最常用的方法,通过预先的加载的字典与现有语句进行字符匹配,挖掘出文本中的词序列,这种方法简单、易于实现,但算法效率不高,同时无法应对未登录词的问题。基于人工智能的语义理解分词法可以有效地解决歧义与未登录词问题,但其实现起来十分复杂,且需要大量的语料素材作为训练样本,空间开销大,就目前的实用性来讲不如匹配法分词。基于统计法的字间凝固度分词从概率上提出了一种最大可能的分词方法,其虽然能有效地解决未登录词问题,但在处理日常词汇时开销过大,整体效率不高。
综合来看,本文所研究设计的中文分词系统,应该从准确度与效率两方面入手。从准确度来说,分词系统所分割出的词序列应该较为精准地寻找到词的边界,保证分词后的语义没有发生变化,避免出现歧义切分,对于一些未登录词汇,做到尽可能识别。从效率上来讲,分词系统在时间与空间上的开销应尽可能小,尤其是时间上的开销,在信息检索、机器翻译等应用场景下,过多的时间成本会极大降低产品的用户体验[7]。
本文旨在设计一个兼顾准确度与效率的文本分词器,能够在尽可能小的时空成本下完成对中文文本的分词工作,要求具有较高的分词准确率,同时要能够支持发现新词。设计完成的文本分词器应具有良好的推广性,可以进一步推广至日文、韩文以及英文等外文;具有较好的鲁棒性,能够应对各种异常,面对不同的输入文本依然能输出较好的分词结果;具有一定的可扩展性,允许用户自定义新的功能;具有广泛的应用价值,能够作为模块嵌入规模更大的系统当中。
第2章 基于前缀词典的中文分词算法
中文分词算法的种类有很多,目前最主流的方法便是基于词典的匹配分词法。传统的词典分词法需要预先构建一个词典,通过输入文本与词典里的词条进行比较匹配实现词序列分割。该方法相较于其他方法极大地提升了分词效率,但其仍然存在着切分不精确、未登录词识别率低等问题。
词典匹配分词之所以会产生切分不精确,是因为在不同的匹配法则下存在不同的分词结果。下面首先介绍传统的机械分词法。然后,介绍如何通过改进算法实现分词效果最优化。最后,对基于前缀词典的中文分词算法的整个流程进行描述。
2.1 基于词典的正向最大匹配法
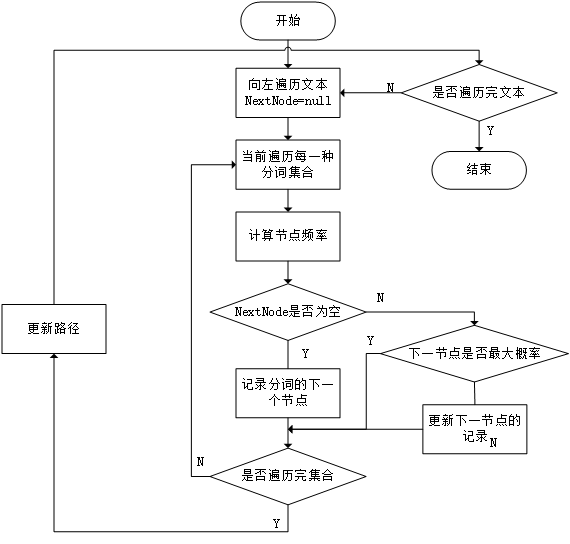
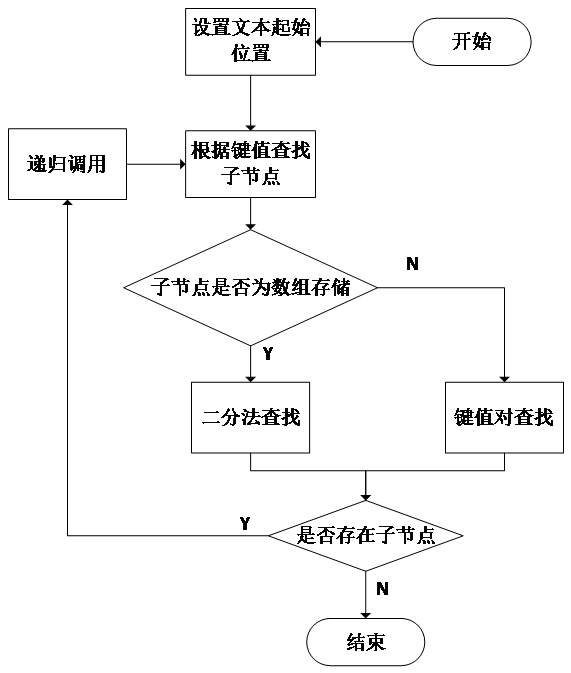
传统的机械分词方法是基于词典的正向最大匹配法,算法的核心是将待分词文本中连续的字符尽可能长的凝结成一个字典中已知的词。其算法的步骤是,首先加载好一个用户词典,然后从左至右将待分词文本中的字符与词典中的词条进行比较,如若匹配,则加入一个待处理序列,直至下一个字符无法匹配成功,此时将待处理序列凝结成一个词[8]。最后,可以得到一个完整的词序列,即分词结果。整个算法的流程图如图2.1所示。
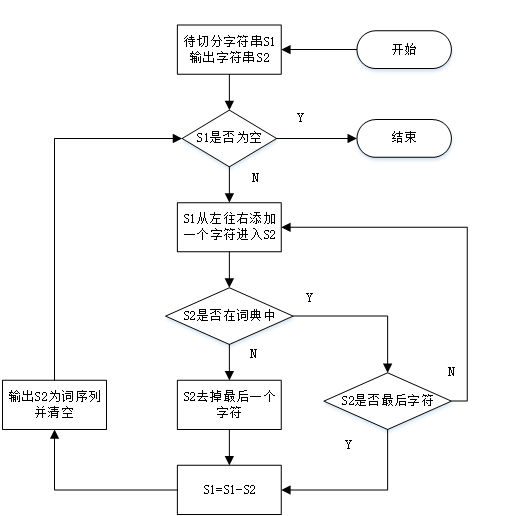
图2.1 正向最大匹配法流程图
通过算法流程分析,正向最大匹配法的利用词的前缀进行匹配,并使匹配出的词尽可能地长。很明显,这种分词方法的优点是结构简单,易于实现,在面对一些较为简单的分词任务时,这种方法能够能够进行快速的词切分。
考虑到分词的现实情况是复杂的中文语境,正向最大匹配法也存在着很多的缺陷。首先,该方法是基于词典进行划分的,在分词时所能切分出的词的长度与内容,完全取决于预先加载的词典,而词典对于词的收录能力是有限的,这就表明分词效果容易受限于加载的词典。其次,该方法的分词依据仅仅是将词的长度最大化,而对于很多中文词汇而言,其前缀往往可以单独成词,最大化切词不够精确,同时由于中文存在的歧义问题,最大化切词结果可能会出现错误切分[9]。最后,正向最大匹配算法在未登录词的处理上效果有限,仅仅能够识别一些未能处理的单字。针对以上问题,本文考虑从词典构造方式、文本存储方式、匹配方法等方面入手,对现有的算法进行改进以克服上述缺点。
2.2 基于Trie树的前缀词典构造
基于词典的分词算法,其预加载词典的优劣直接决定了分词算法性能的好坏。对于一个分词词典来说,首先最重要的是词典容量。词典容量决定了分词算法能否发现待分词文本中存在的词,如果词典容量过小,那么可能存在常见词汇被错误归类为未登录词的情况。当然,如果为了提高分词准确度而刻意扩大词典容量,则会极大降低分词效率,一方面词典容量的扩大直接导致其存储空间增大,提高了存储成本,另一方面过大的词典容量也为增加了检索时长,提高了信息处理的时间成本。因此,一个合格的分词词典应该具有适当的词典容量,能够较为全面地收录常用词汇,可以通过对一些较为知名的语料库进行训练得到。
当然,除了词典容量,最重要的其实是词典在内存中的存储。在计算机系统中,内存的容量还是十分有限的,而一个中文词典收录的词条可能多达百万条,必须找到一种高效的数据结构,同时提高数据的存储效率以及检索效率[10]。
在正向最大匹配法中,词是以从左至右的顺序进行匹配的,而对于不同的词,可能存在相同的前缀,因此考虑通过前缀将不同的词聚合,使拥有相同前缀的词其前缀在内存中只加载一次,可以提高存储以及检索效率。例如,当进行词的匹配时,待检测文本的第一个字符为“文”,那么词典只需要在前缀为“文”的词库里进行搜索。
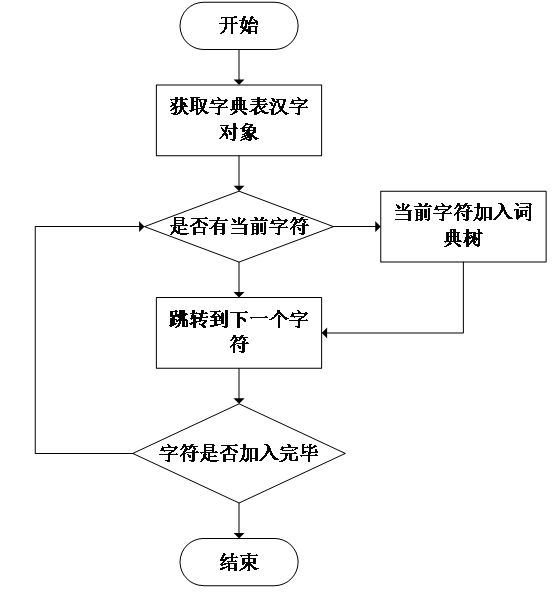
根据以上分析,不难发现词典的存储是树形结构,所有的词拥有一个共同的父节点,每个词的相同的前缀都是一个父节点,从根节点到叶子节点的的路径存储的是一个完整的词汇。在分词算法中,因为存储的对象是字符,同时需要携带词频等统计信息,考虑采用Trie树作为字典的存储结构。Trie树是一种非线性的数据结构,最主要的特点是能够保存键值关系,即字符串和词频之间的关系。在Trie树中,根节点不存储字符,除此以外每一个节点存储一个字符。一个典型的Trie树结构如图2.2所示。
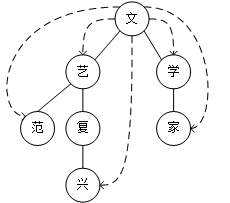
图2.2 Trie树结构存储方式
Trie树利用字符串的公共前缀作为查询的地址,同样的前缀在内存中只需存储一次,降低了存储成本,同时减少了重复的字符串比较时间,其效率比传统的线性词典查询效率要高得多。
2.3 基于有向无环图的分词集合
构造前缀词典是为了对待分词文本进行切分,而在正向最大匹配法则下我们每次仅能得到一种切分组合。很明显,由于词的前缀以及歧义切分等问题,对于同一个待分词文本,存在着多种切分组合,其中最优的组合即是正确的分词。在找到最优组合之前,我们需要将所有的分词集合找到。
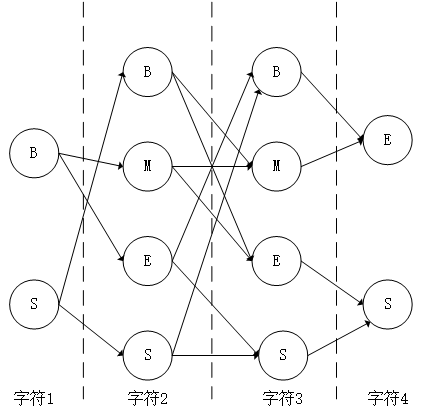
对于待分词文本,将其每个字符视为一个独立的节点,那么文本本身就是一个连续的数据链表。而分词过程即是找到链表中的某一个节点到另一个节点的路径,使得这条路径上的字符连起来能够组成一个完整的词汇。一个完整的分词集合必定存在多种路径,因此这些字符节点应该以图的方式存储,考虑到分词必定是以从左至右的单向方式进行的,选择有向无环图来构成所有可能的分词集合[11]。
有向无环图是一个没有回路的有向图,每个节点存储一个字符,由于待分词文本本身已经具有先后次序,因此该情境下的有向无环图结构十分简单,一个典型的有向无环图如图2.3所示。
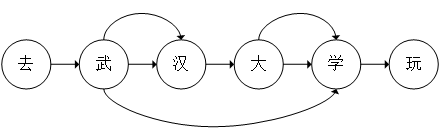
图2.3 有向无环图存储方式
在内存中,以有向无环图的方式存储的分词集合是以其位置信息进行标记记录的,每个词的起始位置作为一个键值,其保存的值是以当前字符为起始的所有可能的分词终点字符的位置信息。以图2.3为例,“去”是一个单字,其起始位置为0,因此所有可能的分词结果为{0:0},“武”既可以作为单字,也可以组成词,其所有可能的分词结果为{1:[1,2,4]},表明其在位置2和4上均可组词,组合出来的词分别是“武汉”和“武汉大学”。
有向无环图为我们提供了待分词文本在当前前缀词典下所有可能的分词结果,从工程的角度讲,只有一种分词结果是最优的,下面我们的任务便是探究如何实现分词结果最优化。
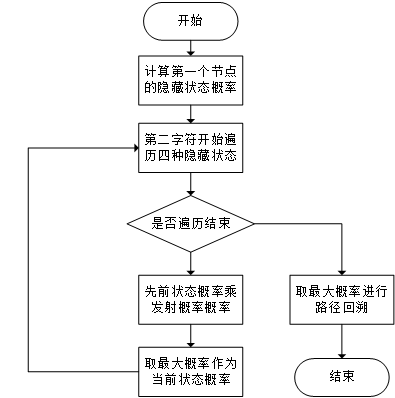
2.4 动态规划求解最大概率路径
在正向最大匹配法中,我们分词的原则是切分出的词汇尽可能的长,显然这种机械的原则往往并不是最优的做法。从人的认知角度出发,最好的分词方式是把那些对于人而言更为常见的词切分出来,这也意味着那些在日常中文信息交流中词频更高的词应该有更高的分词优先级。
在构造前缀词典时,我们已经注意到将各个词的词频信息提取出来,如果对词典所有词的词频进行统计计算,很容易可以得到每个词出现的概率。显然,在待分词文本构造的有向无环图中,我希望切词结果得到的整体概率最大,因此分词最优化问题可以转化为在有向无环图中查找最大概率路径的问题[12]。
最大概率路径需要求解的是全局最优,显然局部的最优往往不一定能够满足条件,因此考虑通过动态规划来求解最大概率路径问题。动态规划求解往往需要问题满足两个条件:重叠子问题以及最优子结构。
重叠子问题指对于不同的决策序列在达到某个共同的决策目标时可能会存在重叠的状态,在当前情境下,意味着在局部不同节点计算概率时是否需要重复计算。在当前有向无环图中,对于任意节点,其后存在节点和,任意通过到达的路径的权重计算公式为:
(2.1)
其中,表示该路径通过的路径权重,表示节点的权重。
对于节点,其分析过程与相似,任意通过到达的路径的权重计算公式为:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: