基于FPGA的语音识别到手势图像显示系统毕业论文
2020-02-17 21:46:13
摘 要
据世界卫生组织(WHO)统计,截至2011年世界患有听力障碍的人数达到3.6亿,而随着近年来智能手机的急速普及,以及对日常生活的渗入日益加深,人们对耳机的使用也日渐频繁,患上听力障碍的风险也越来越高。我国作为人口大国,约有1.5亿人患有听力障碍,60岁以上老年人患听力残疾总数超过2000万,是世界上听力障碍人数最多的国家。考虑到多数言语障碍的人能够通过哑语进行基本交流,哑语手势成为主要的交流方式,本课题意图提供一种语音到手势的转换方法,通过语音识别将手势图像显示出来,给语言无障碍者和有障碍者的交流之间提供便捷辅助。当下,许多企业在语音识别技术的研究上投入了大量资金,意图不止在改进原本的算法,而且在新产品上了逐渐脱离键盘控制,转而利用语音命令作为控制信号,这一理念在车载电子系统、消费电子系统、智能家居等方面得到了广泛应用,具有广阔的发展前景。
本设计的主要目标是实现基于FPGA的语音到手势的转换系统。步骤上,首先需要进行孤立词的语音识别训练,以建立孤立词的声学模型,然后根据《中国手语》提供的手势图像拍摄孤立词对应的手势,并转换成二进制文件,最后通过FPGA平台实现孤立词从录制到识别再到输出显示对应手势图像的转换过程。细节上,采用基于隐马尔可夫模型的语音识别原理进行训练建立声学模型,并将训练好的模型同二进制手势图像存储起来作为匹配模板,然后利用硬件描述语言设计系统的基本逻辑单元,并进行软件编程实现系统控制软件核心,进而实现语音到图像中间的一系列转换工作,例如采集、预处理、识别匹配、调用对应结果图形,并且最终显示到液晶屏幕。
关键词:语音到手势转换,FPGA,HMM
Abstract
According to the World Health Organization (WHO), as of 2011, the number of people with hearing impairment in the world reached 360 million. With the rapid spread of smartphones in recent years and the deepening of daily life, people are increasingly using headphones. Frequently, the risk of hearing impairment is getting higher and higher. As a country with a large population, about 150 million people suffer from hearing impairment. The total number of hearing disabilities in the elderly over 60 years old is more than 20 million. It is the country with the largest number of hearing impairments in the world. Considering that most speech impediments can communicate basicly through dummy language, and mute gestures become the main communication method, this topic intends to provide a speech-to-gesture conversion method, which displays gesture images through speech recognition, and provides language barrier-free and Convenient assistance is provided between the communication of the disabled. Nowadays, many companies have invested a lot of money in the research of speech recognition technology. The intention is not only to improve the original algorithm, but also to gradually remove the keyboard control from the new product and use the voice command as the control signal. Systems, consumer electronics systems, smart homes, etc. have been widely used and have broad prospects for development.
The main goal of this design is to implement an FPGA-based speech-to-gesture conversion system. In the steps, the speech recognition training of isolated words is first needed to establish an acoustic model of isolated words, and then the gesture corresponding to the isolated words is taken according to the gesture image provided by "Chinese Sign Language", and converted into a binary file, and finally isolated by the FPGA platform. The conversion process of the word from the recording to the recognition to the output display corresponding gesture image. In detail, the acoustic recognition model based on the hidden Markov model is used to train the acoustic model, and the trained model and binary gesture image are stored in the SDRAM of the FPGA. Then the Verilog HDL hardware description language is used to design the basic logic of the system. The unit performs the voice-to-image conversion function and performs display on the liquid crystal screen to complete the gesture speech to image conversion.
Keywords: speech to gesture conversion, FPGA, HMM
目 录
摘 要 I
Abstract II
目 录 III
第1章 绪论 1
1.1 研究背景 1
1.2 SOPC 技术 1
1.2.1 SOPC 简介 1
1.2.2 FPGA 简介 2
1.3 主要工作 2
1.4 论文主要内容安排 2
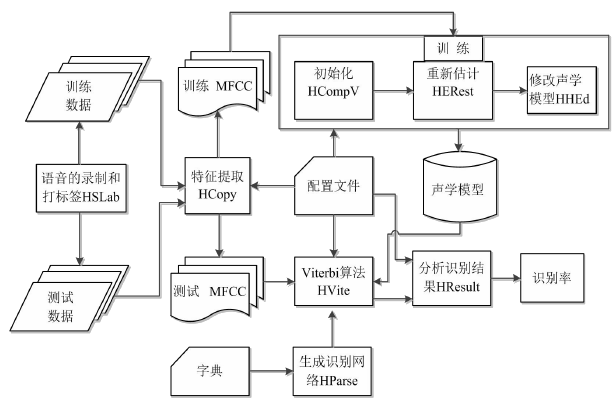
第2章 语音识别原理 4
2.1 基本原理 4
2.2 语音信号的特征提取 5
2.2.1 线性预测分析 5
2.2.2 倒谱分析 6
2.3 模版匹配 7
2.3.1 动态时间规整 7
2.3.2 人工神经网络 7
2.3.3 隐马尔可夫模型 8
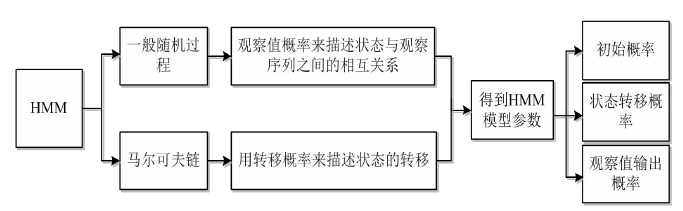
2.4 基于HMM的训练和识别算法 8
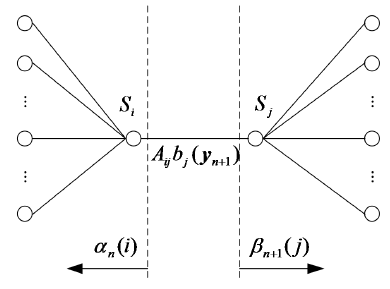
2.4.1 Baum-Welch 算法 8
2.4.2 Viterbi算法 10
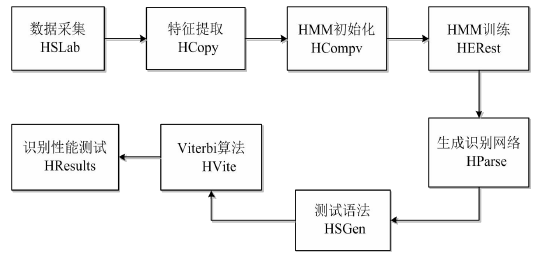
2.5 HTK 工具箱 10
2.5.1 HTK 软件结构 11
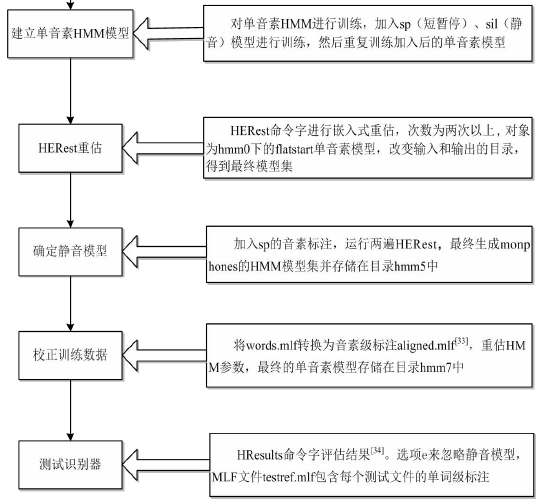
2.5.2 孤立词训练和识别 11
2.6 本章小结 13
第3章 系统整体设计 15
3.1 FPGA设计基础 15
3.1.1 FPGA 简介及开发流程 15
3.1.2 FPGA 硬件开发板简介 17
3.2 系统整体架构设计 18
3.3 FPGA中各功能模块的设计 19
3.3.1 语音采集模块 19
3.3.2 存储系统设计 21
3.3.3 NIOS II 程序控制模块 22
3.3.4 液晶显示模块 25
3.4 本章小结 26
第4章 系统整体实现 27
4.1 系统整体框图 27
4.2 性能分析 28
4.2.1 系统资源利用 28
4.2.2 系统运行速度 29
4.3 系统功能测试 31
4.4 本章小结 33
第5章 总结 34
参考文献 35
致 谢 38
第1章 绪论
1.1 研究背景
据世界卫生组织(WHO)统计,截至2011年世界患有听力障碍的人数达到3.6亿,而随着近年来智能手机的急速普及,以及对日常生活的渗入日益加深,人们对耳机的使用也日渐频繁,患上听力障碍的风险也越来越高。我国作为人口大国,约有1.5亿人患有听力障碍,60岁以上老年人患听力残疾总数超过2000万,是世界上听力障碍人数最多的国家。本课题意图提供一种语音到手势的转换方法,通过语音识别将手势图像显示出来,给语言无障碍者和有障碍者的交流之间提供便捷辅助。
直到70年代,语音识别才进行了大规模实验研究,尤其在小量和孤立词的识别方面取得长足进展。80年代后,研究的重点逐渐由小转大,从特定转向非特定连续语音识别。此时开始将基于统计模型的研究思路代入语音识别的研究,从而使得后面隐马尔科夫模型的发展应用突飞猛进。进入90年代,语音识别在技术应用和产品化方面取得巨大进展,语音识别开始走向大众,普遍走进人们的生活。
我国的语音识别研究起始于1958年,由中国科学院声学所率先进行。虽然早,但是受当时条件的限制,仅仅能使用电子管电路识别区区10个元音。语音识别的研究工作一直在缓慢发展,直到1973年计算机的应用和普及,使得我国在经历计算机发展突飞猛进的同时,语音识别技术的发展也得到蓬勃发展,因为终于有趁手的工具了。在80年代,语音识别技术在国际上又逐渐成为研究的热点。 1986年3月,我国启动了高科技发展计划,语音识别技术正在研究课题之列。国内开始了有组织的研究,并组织起了两年一度的语音识别专题会议,我国的语音识别技术进入了高速发展阶段。
1.2 SOPC 技术
1.2.1 SOPC 简介
可编程片上系统(System on a Programmable Chip,SOPC)最早由Altera公司提出。SOPC是一种特殊的嵌入式系统,它既是由单个芯片完成整个系统的主要逻辑功能的片上系统,又是可编程系统,具有灵活的设计方式,可裁减、可扩充、可升级,并具备软硬件在系统可编程的功能[13]。
1.2.2 FPGA 简介
FPGA(Field-Programmable Gate Arra,现场可编程门阵列)是利用硬件描述语言进行系统设计的基本逻辑单元,它的芯片可以重复编程修改,十分灵活方便,易于进行升级和维护。它具有以下两个主要优势:
(1)研发成本相对较低
可重复编程修改,能进行多次开发,成本显然低于以DSP/ARM为处理器的设计,尤其在有较多逻辑资源调用应用中, FPGA能够通过复用资源节省更多的空间,降低成本。
(2)性能高
FPGA广泛应用于高端数字逻辑电路设计领域。对于语音识别的设计需求,数据采集工作必须在质量、精度和速度上具有优势,同时具有高效准确的识别匹配能力,以期实现识别效果更佳的系统。
1.3 主要工作
步骤上,首先需要进行语音识别训练,以建立孤立词的声学模型,然后拍摄对应的手势,并转换成二进制文件,最后通过FPGA平台实现孤立词从录制到识别再到输出显示对应手势图像的转换过程。细节上,采用基于隐马尔可夫模型的语音识别原理进行训练建立声学模型,并将训练好的模型同二进制手势图像存储起来作为匹配模板,然后利用硬件描述语言设计系统的基本逻辑单元,并进行软件编程实现系统控制软件核心,进而实现语音到图像中间的一系列转换工作,例如采集、预处理、识别匹配、调用对应结果图形,并且最终显示到液晶屏幕。
1.4 论文主要内容安排
文章内容分为五章进行,如下:
第1章,简介语音识别技术的发展历史,并且解释了SOPC技术,阐释本次设计的主要工作内容。
第2章,基于HMM的孤立词语音识别原理。此处对比了部分主流的语音识别中的特征提取和模版匹配算法,得出适用于本次设计的最佳算法。
第3章,系统整体设计。本章介绍了系统各个模块的设计,对它们的原理、结构、功能以及实现方式进行了介绍。
第4章,系统整体实现。本章介绍了系统整体实现的过程,并利用HTK工具箱对软硬件仿真平台进行了识别测试,对系统性能以及测试结果进行了分析和总结。
第5章,对主要工作进行了总结,指出目前存在的不足,提出了下一步改进之处。
第2章 语音识别原理
2.1 基本原理
语音识别就是一种模式识别,识别前需要对输入信号进行处理,这个过程可以分为两个阶段:训练和识别。过程如图2.1所示。
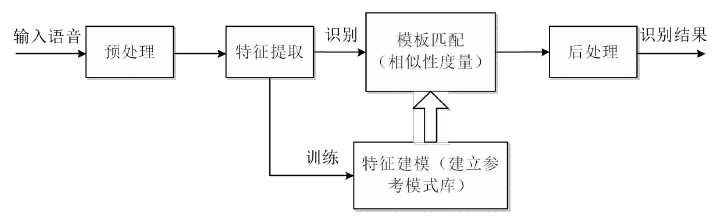
图2.1 语音识别的过程
模型训练阶段中,需要先对输入信号进行预处理,过滤掉目的语音信号外的部分,然后依次完成端点检测、分帧、预加重和加窗操作。预处理过程如图2.2所示。
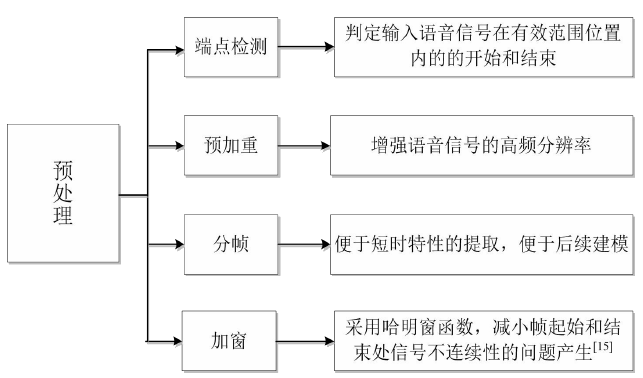
图2.2 预处理过程
采集语音信号后截取其中一个片段,选择一个固定长度的窗函数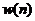 ,对原始语音信号
,对原始语音信号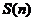 的加窗如下[16]:
的加窗如下[16]:
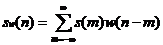 (2.1)
(2.1)
对每帧信号用汉明窗加窗,其表达式为:
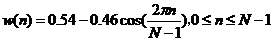 (2.2)
(2.2)
2.2 语音信号的特征提取
特征参数的提取作为模板匹配的前置步骤,其本身必须能够有效反映出语音信号的关键特征,这样才能得到最有效的声学模板,同时提高匹配识别率。语音识别对特征参数有如下要求:
(1)能将语音信号转换为计算机能够处理的语音特征向量
(2)在一定程度上能够增强语音信号、抑制非语音信号
(3)能够符合或类似人耳的听觉感知特性
根据这些要求,下文对多种特征提取方法进行了对比分析。
2.2.1 线性预测分析
线性预测分析(Linear Prediction Coefficients,LPC)是一种拟人类的发声原理,通过分析声道短管级联的模型得到的。它反映了声道的频率响应和原始信号的谱包络之间的关系,信道函数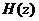 的表达式为:
的表达式为:
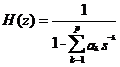 (2.3)
(2.3)
设冲激响应函数为 ,冲激响应函数对应的复倒谱为
,冲激响应函数对应的复倒谱为 。根据复倒谱的定义有:
。根据复倒谱的定义有:
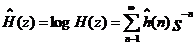 (2.4)
(2.4)
倒谱阶数用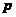 表示,当它的取值在为8-32之间时,是为最佳倒谱阶数。在最佳范围内,如,携带信息量与的取值成正相关,而当取值处于范围外时,过小导致表征效果不足,同时携带信息量不足,很可能导致失真;过大导致运算量急剧增大,信息表征效果反而下降,效率也会下降。
表示,当它的取值在为8-32之间时,是为最佳倒谱阶数。在最佳范围内,如,携带信息量与的取值成正相关,而当取值处于范围外时,过小导致表征效果不足,同时携带信息量不足,很可能导致失真;过大导致运算量急剧增大,信息表征效果反而下降,效率也会下降。
LPC分析的缺点在于过分依赖模型的精度,同时易受误码影响。为了解决这些问题,考虑LPCC系数和MFCC系数:前者是一种合成的参数,并不能体现人耳听觉特性;后者是梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC),它基于人耳听觉特性,频率的尺度值与实际频率的对数分布关系更符合人耳的听觉特性,所以可以使得语音信号有着更好的表示。基于此,本设计采用基于MFCC的特征提取方法。
2.2.2 倒谱分析
特征参数提取流程如图2.3所示:

图2.3 语音采集到特征提取流程图
将采集信号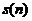 经过预处理后,对对应语音帧的时域信号
经过预处理后,对对应语音帧的时域信号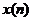 补0成长度N(N=512)的序列,并进行快速傅里叶变换(FFT),得到对应的线性频谱
补0成长度N(N=512)的序列,并进行快速傅里叶变换(FFT),得到对应的线性频谱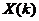 如下:
如下:
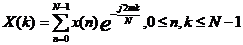 (2.5)
(2.5)
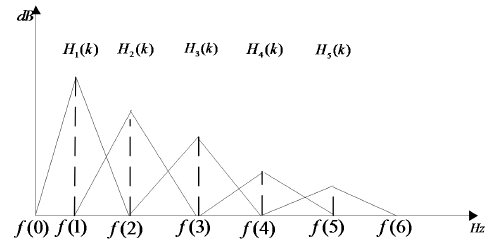
最后取对数,就得到对数频谱 。Mel三角形滤波器组频谱图如图2.4所示。
。Mel三角形滤波器组频谱图如图2.4所示。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: