基于卷积神经网络的医疗图像识别系统设计与研究毕业论文
2020-02-17 21:10:57
摘 要
随着医疗图像数据指数式增长,依靠人工分析医疗图像的方式过于主观,这种方式往往依赖的是医生个人的经验与知识,而人的精力与情绪等主观因素不仅影响分析的效率,还会对分析的准确度产生很大的影响。在电子信息技术飞速发展的背景下,利用计算机辅助检测和分析成为当下的研究热点。深度学习是机器学习一个新的领域,传统机器学习在挖掘医疗图像中的特征数据时表现不佳,而深度学习模拟人脑构建分层模型,从数据集中提取从底层到高层的特征,它能够高效的表达特征数据并构建复杂模型。深度学习在图像识别领域优异的表现为医疗图像领域的发展提供了新的思路。
本文先阐述了深度学习的理论基础,然后详细介绍了卷积神经网络相关内容;随后提出白血细胞识别在传统机器学习和深度学习中应用表现,并对其作出对比。
关键字:卷积神经网络,支持向量机,迁移学习,白血细胞,Tensorflow
Abstract
With the exponential growth of medical image data, the way of manual analysis of medical images is too subjective. This method often relies on the individual experience and knowledge, and subjective factors such as energy and emotions that not only affect the efficiency of analysis, but also have great impact on the accuracy of the analysis. In the context of the rapid development of electronic information technology, the use of computer-aided detection and analysis has become a hot research topic. Deep learning is a new field of machine learning. Traditional machine learning does not perform well when excavating feature data in medical images. The deep learning simulates human brain, builds a stratified model and extracts features from the bottom to the top from the dataset. What’s more it can efficiently express feature data and build complex models. The excellent performance of deep learning in the field of image recognition provides new ideas for the development of medical imaging.
This paper first expounds the theoretical basis of deep learning, and then introduces the convolutional neural network related content in detail; It subsequently proposes how white blood cells are recognized in traditional machine learning and deep learning. Last the paper compares the quality of models.
Key Words: CNN, SVM, Transfer learning, Leukocyte, Tensorflow
目 录
摘 要 I
Abstract II
目 录 III
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.2.1医疗图像分析的难点 1
1.2.2医疗图像的深度学习方法 2
第2章 深度学习简介 3
2.1 深度学习的基本思想 3
2.2 DNN反向传播算法 4
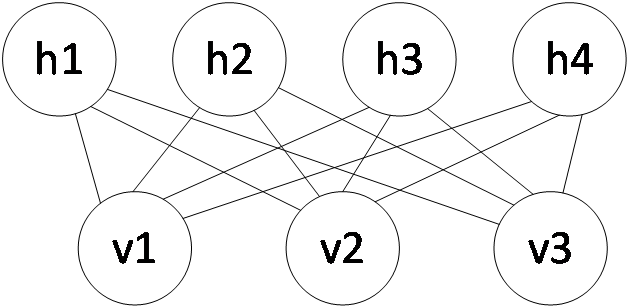
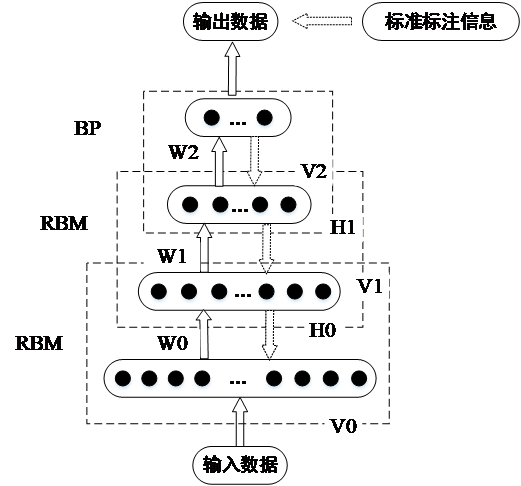
2.3 限制玻尔兹曼机和深信度网络 6
2.4 自动编码机 9
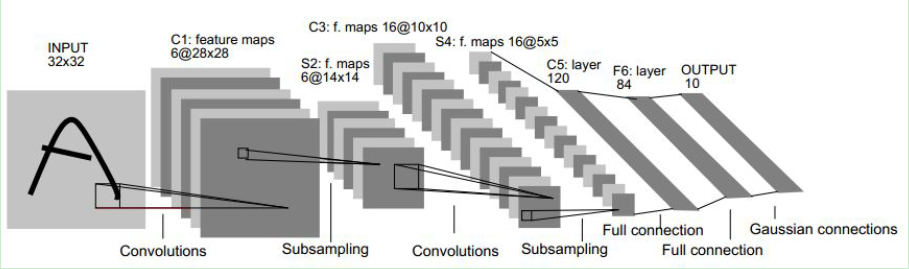
2.5卷积神经网络 10
2.5.1 卷积神经网络的结构 10
2.5.2 卷积神经网络的稀疏连接和权值共享 13
第3章 白血细胞图像的多种识别分类方法 14
3.1 引言 14
3.2 SVM实现白血细胞识别 14
3.2.1 线性分类 15
3.2.2 特征提取 15
3.2.3 SVM在Matlab中的实现 16
3.3 VGG16实现白血细胞识别 16
3.3.1 迁移学习 16
3.3.2 基于VGG16的网络结构 17
第4章 仿真结果分析 20
4.1 样本数据集 20
4.2 仿真平台介绍 21
4.3 仿真评估指标 22
4.4 仿真分析及结论 22
第5章 总结与展望 25
5.1 总结 25
5.2 展望 25
参考文献 26
致 谢 27
第1章 绪论
研究背景及意义
自从可以将医疗图像扫面并加载到计算机上后,研究员开始建立可以自动分析的系统。最初,从二十世纪七十年代到九十年代的医疗图像分析是通过低像素列性处理(边缘线性检测滤波器)和数学模型去构建解决特定问题的复合规则系统来完成的。但这个系统一直被认为是过时的人工智能,经常表现得很脆弱,并且跟规则图像处理系统相似。
在九十年代末,监督技术在医学图像分析中变得越来越流行,例如主动形状模型(Active Shape Models,ASM),阿特拉斯方法(Atlas Methods),特征提取和统计学分类器的概念。我们已经看到了一个从完全由人来设计的系统到一个提取数据集特征的计算机训练完成的系统的转变。计算机算法决定了在高位特征空间的最优决策边界,设计此类系统的关键步骤是从图像中提取判别式特征,这一过程仍然由人类研究员来完成,比如经常提到的Hand Crafted特征系统。通常,下一步是让计算机学习最能代表数据的功能。迄今为止,用于图像分析的最成功的模型类型是卷积神经网络(CNN)。自七十年代末以来已经完成了CNN的工作(Fukushima,1980),并且已经在1995年由Lo等人应用于医学图像分析。尽管取得了这些初步的成功,但在开发各种新技术以有效地训练深度网络和在核心计算系统方面取得了进展前,CNN并未得到有效应用。分水岭是Krizhevsky等人在参加2012年12月的ImageNet挑战赛上作出的贡献。他们所提出的CNN叫AlexNet,以巨大优势获胜。在随后的几年中,Russakovsky等使用与其相关且更深入的架构取得了进一步的进展。在计算机视觉中,深度卷积网络现在已成为首选技术。
国内外研究现状
1.2.1医疗图像分析的难点
近年来,模式识别和机器学习在目标检测、语音识别、图像处理、场景识别等领域已取得了十足的进步,这使得医学图像分析的科研人员进行了深度研究。但目前医学图像领域内还存在许多挑战:
- 医疗图像的维度
随着医学影像技术的飞速发展,医学图像分析已进入大数据时代,大部分医学图像是三维图像,而深度学习大多是对二维的图像进行训练。目前对三维图像的处理办法是把三维的图像进行采样,转化为二维的图像信息,但这样的做法不仅会减少图片的分辨率,还会损失大量的图片信息。于是,为了解决在这方面的不足,Roth等人提出2.5D[1]的采样方法,该方法原理是在二维采样时,将空间上彼此正交的三个切片图像组合成一个RGB图像,而不是分别训练采样的图像,这样可以最大程度保留图像信息。研究员还设计3D深度学习模型来直接分析三维图像,如Brosch[2]、Dou[3]等人。这样做减去了复杂的采样步骤,简化了过程。
- 医疗图像的数据量
目前大量的实验和工作证明,数据集的大小直接影响到深度学习的性能。深度学习从数据集中提取从低层次到高层次的特征,这种方法必然要求使用大量的数据。如果数据集过少,模型很难学习到充分的特征,无法达到理想的识别率。在医学领域,普遍会出现数据量过少的情况,因此,这就需要研究员想办法解决数据量少,样本类间差异小,类内差异大给深度学习带来的难题。
1.2.2医疗图像的深度学习方法
深度学习本身是指多层复杂的神经网络层,包含了许多算法模型,目前对对深度学习的定义是含有两层或两层以上的深度算法结构。目前,在医疗图像分析中,有以下两种深度学习的方法:
- 自训练模型
在医疗图像的分析中,用于深度学习的算法模型包括卷积神经网络、深度玻尔兹曼机、自动编码器、深信度网络等,这些模型都是通过大量的数据来训练,对众多参数进行调优,比如权重衰减系数、学习率、动量系数等。
- 迁移学习与微调
医学领域本身的一些难题,如有标签样本数据的缺乏,使得难以训练出较好的分类模型。近年来,迁移学习引起了广泛的关注和研究。迁移学习是一种新的机器学习方法,它使用现有知识来解决不同但相关领域的问题。它放宽了传统机器学习中的两个基本假设,目的是迁移现有知识以解决目标域中只有少量样本数据集有标签甚至完全没有标签的学习问题。使用该方法是指使用从自然图像数据集(例如CaffeNet[4]、GoogleNet[5]、AlexNet[6]等)训练好的模型,然后从网络层提取特征,并使用它来训练单独的分类器。比如Bar等人[7]将预训练好的卷积网络模型AlexNet作为一个特征提取器,用来对肺结节分类。微调是指通过将在大数据集上训练得到的权重作为特定任务(小数据集)的初始化权重来重新训练该网络。微调又分两种情况,我们可以训练网络所有层,或者我们固定网络前面几层,只微调最后几层。这样做有两个原因:(1)避免有少量数据引起的过度拟合;(2)卷积神经网络的前几层特征包含更多一般特征(如边缘信息和颜色信息)。这对于许多任务非常有用,但后面的特征学习更关注与高级特征。即语义特征。这是针对数据集的并且不同数据集中高层学习的语义特征是完全不同的。
第2章 深度学习简介
2.1 深度学习的基本思想
深度学习来源于人工神经网络,是对人工神经网络的发展。两位神经生理学家David Hubel和Torsten Wiesel于1959年发表论文“猫的纹状皮层中单个神经元的感受野”[8],描述了视觉皮层神经元的核心反应特性以及猫的视觉体验如何塑造其皮质结构。研究人员通过实验发现,初级视觉皮层含有许多简单又复杂的神经元,并且视觉处理总是从特定方向边缘这种简单结构开始的。这是隐藏在深度学习之后的核心准则。
根据两位神经生理学家的研究可以得出“可视皮层是分级的”这一结论。这一发现激发了人们对神经系统的进一步思考,如图2-1,人脑视觉系统的机制从摄入像素开始,然后边缘信息等低级特征提取并传入大脑的V1区域,到达V2区后,进一步抽象得到形状和目标的部分等更高级的特征,最后是V4区,抽象得到整个目标和目标的行为[9]。深度学习采用的正是这种从低级抽象到高级抽象的大脑皮层结构。
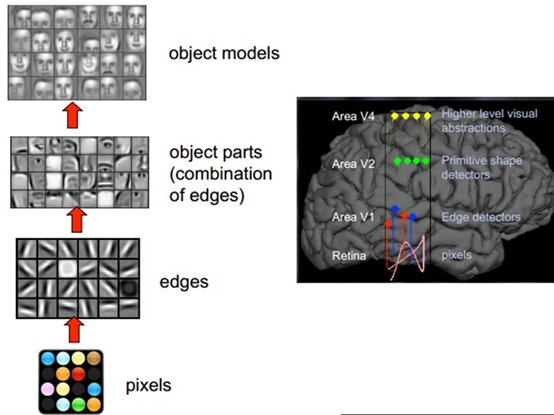
图2-1 人脑视觉机理
对于深度学习来说,每一层的输入可以用公式2-1表示。
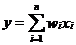
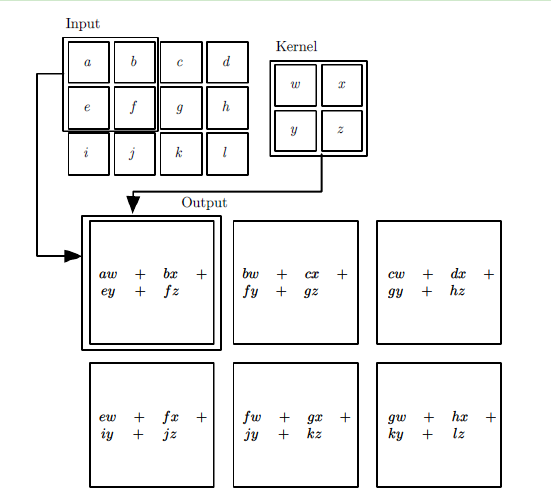
式中表示神经元之间的权重,表示神经元的输入,因此神经元的输出可以用公式2-2表示。
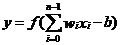
上式中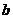 表示偏置项,为实数,
表示偏置项,为实数, 表示激活函数,输出为1或0(根据是否大于阈值来输出1或0),激活函数的非线性建模功能使得能够利用分层非线性映射学习进行深度学习,这是深度神经网络的特殊而又必不可少的部分。
表示激活函数,输出为1或0(根据是否大于阈值来输出1或0),激活函数的非线性建模功能使得能够利用分层非线性映射学习进行深度学习,这是深度神经网络的特殊而又必不可少的部分。
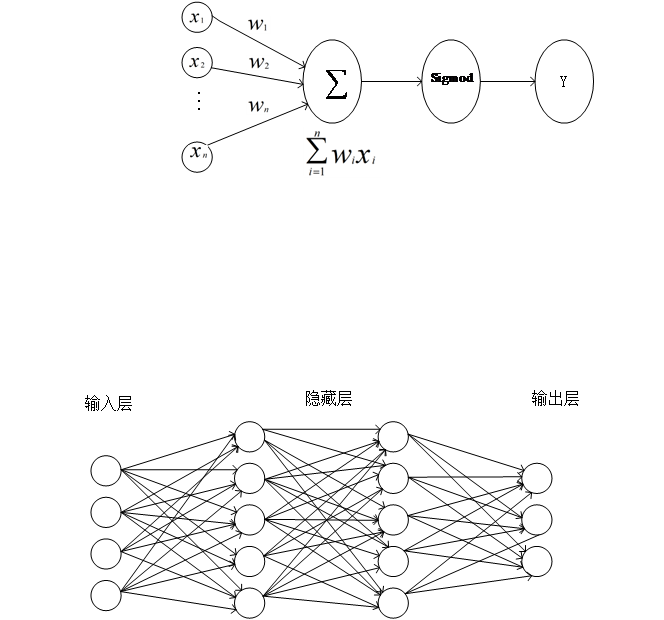
图2-2 神经网络结构
如上图2-2所示,神经网络是由多层连接的神经元组合而成的复杂模型,大致可分为输入层、隐藏层、输出层,如下图2-3,其中隐藏层可以有多层,隐藏层的数目越多,模型也就越复杂。通常,输入层和输出层的神经元数目不改变,并且根据训练的实际情况调整隐藏层的数目,太多的层数会增加训练的难度,我们通常根据链式结构改善隐藏层的层数来调整模型的复杂程度。
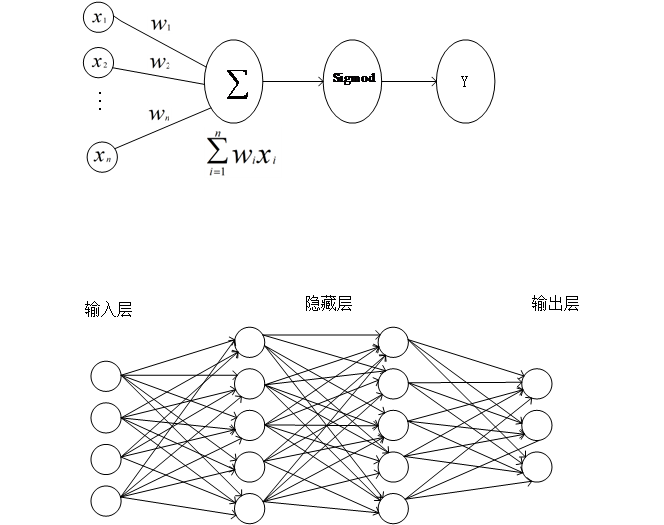
图2-3 神经网络结构
在这里我们应该提到监督学习的一般问题,假设我们有m个训练样本,输入向量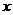 的特征维度为
的特征维度为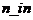 ,输出向量
,输出向量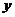 的特征维度为
的特征维度为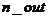 。输入测试样本时,使用这m个样本训练模型,当能预测出输出向量。
。输入测试样本时,使用这m个样本训练模型,当能预测出输出向量。
2.2 DNN反向传播算法
在训练时,我们需要一个函数来测量训练样本预测的输出与真实的训练样本之间的误差,这个称为损失函数。DNN可以选择很多种损失函数,一般来说,我们会使用常见的均方差来测量损失,误差公式如式2-3所示。
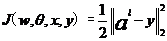
其中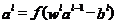 得到L层的输出,跟
得到L层的输出,跟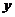 一样,为特征维度为的向量,
一样,为特征维度为的向量,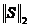 为S的L2范数。在人工神经网络,反向传播算法(Back Propagation,BP算法)通常用于训练,它既可以训练离散的数值,又可以训练连续的数值。它最主要的优点还是结构简单,编程难度不大。
为S的L2范数。在人工神经网络,反向传播算法(Back Propagation,BP算法)通常用于训练,它既可以训练离散的数值,又可以训练连续的数值。它最主要的优点还是结构简单,编程难度不大。
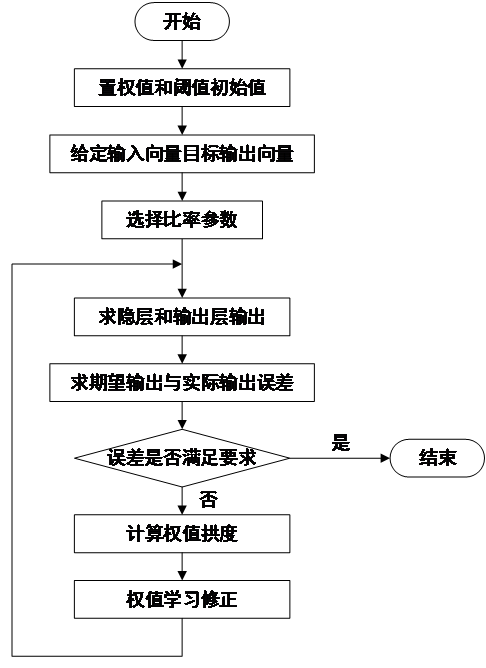
反向传播算法具有很好的鲁棒性,可应用于单层或多层网络。在训练深度神经网络的时候,BP算法都是从最后一层开始训练的,通过计算误差平方,然后将误差反向传入上一层输入,依次更新权重参数即线性关系系数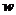 和偏置项
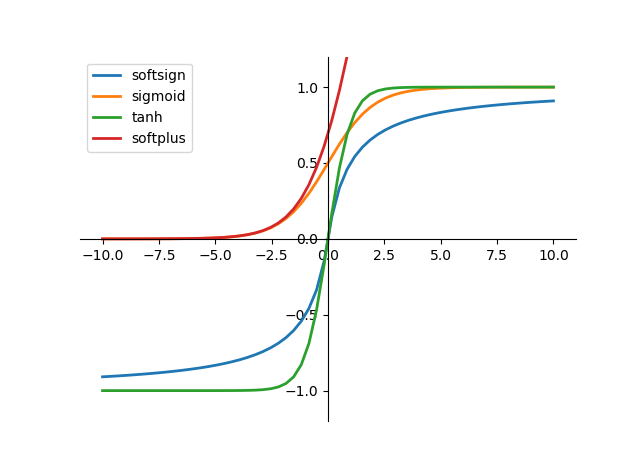
和偏置项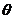 。为了防止模型算法线性化,在每层的输入中加入激活函数,通常选择S型函数,如图2-4所示。
。为了防止模型算法线性化,在每层的输入中加入激活函数,通常选择S型函数,如图2-4所示。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: