基于深度学习的方言识别系统实现毕业论文
2020-04-12 08:48:11
摘 要
在过去的2017年,人工智能已成为科技前沿技术,深度学习也逐渐成为一个热门话题,长期以来,我们在语音识别领域声学模型的建模通常都是使用GMM-HMM模型,该模型具有可靠的精度,并且有成熟的算法来进行参数训练,但因为GMM模型属于浅层模型,随着数据量增加它的建模能力明显不足。而深度神经网络(DNN)因其对复杂数据有更好的建模与学习能力,成为语音识别领域研究的热点。中国话将普通话作为官方语言, 但是各地区、各民族的方言种类众多,国内对于语音识别技术已日趋成熟,但是方言识别还甚少研究,针对方言的独特发音特点和其声学特征的明显差异,本设计拟研究一种基于深度学习的方言识别技术。本文深入研究了基于深度学习的语音识别,分析两个模型的优点以及不足,主要进行了以下工作:
- 对基于隐马尔科夫模型(HMM)的语音识别算法进行深入研究,并使用MATLAB实现语音识别,对语音库存放的语音信号进行训练得到语言模型和声学模型。实验解码结果表明,在小词汇量汉语语音识别中,可以对语音信号进行正确识别。
- 针对HMM模型的不足,对深度神经网络DNN深入研究,实现了大词方言词汇语音识别系统的构建,对方言语音进行DNN声学模型训练,DNN模型在小词汇量语音识别系统中具有比较好好的识别效果。
- 噪声干扰一直是语音识别的难点,在进行声学模型训练的过程中,通过在训练和测试语音加入白噪声、汽车背景噪声、自助餐背景噪声进行DNN训练,并与多种模型对比,可以用于提高恢复噪声损坏的输入。
关键词:语音识别 方言识别 深度学习 DNN
Abstract
In the past 2017, artificial intelligence has become a cutting-edge technology, and deep learning has gradually become a hot topic. For a long time, the modeling of acoustic models in the field of speech recognition has always used the GMM-HMM model, which is reliable. Accuracy, and there are mature algorithms for parameter training, but because the GMM model is a shallow model, its modeling ability is obviously insufficient with increasing data volume. Deep neural network (DNN) has become a hot spot in the field of speech recognition because of its better modeling and learning ability for complex data. Mandarin speaks Putonghua as the official language. However, there are many kinds of dialects in different regions and nationalities. Voice recognition technology has matured in China. However, dialect recognition is rarely researched. The differences between the distinctive pronunciation characteristics of dialects and their acoustic characteristics are obvious. This design plans to study a dialect recognition technology based on deep learning. This paper deeply studies the speech recognition based on deep learning, analyzes the advantages and disadvantages of the two models, and mainly performs the following work:
(1) In-depth research on speech recognition algorithms based on Hidden Markov Models (HMM), and using MATLAB to achieve speech recognition, the voice signals placed in the voice inventory are trained to obtain language models and acoustic models. The experimental decoding results show that in the small vocabulary Chinese speech recognition, the speech signal can be correctly identified.
(2) According to the deficiency of the HMM model, the deep neural network DNN is deeply studied, and the construction of the vocabulary speech recognition system of the big vocabulary is realized. The DNN acoustic model is trained on the dialect speech, and the DNN model is compared in the small vocabulary speech recognition system. Good recognition effect.
(3) Noise disturbance has always been a difficult point in speech recognition. In the process of acoustic model training, DNN training is performed by adding white noise, car background noise, buffet background noise in training and test speech, and compared with various models. Used to improve the recovery of noise damage input.
Keywords: speech recognition dialect recognition deep learning DNN
目 录
摘要 I
Abstract II
第1章 绪论 1
1.1 研究课题背景及研究的目的和意义 1
1.2 国内外的研究现状 2
1.3 论文组织结构 3
第2章 语音识别的基本原理 4
2.1 语音信号的预处理 4
2.1.1 预加重 5
2.1.2 分帧 6
2.1.3 加窗 6
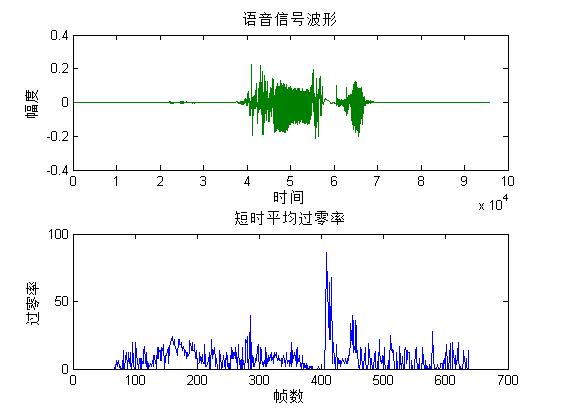
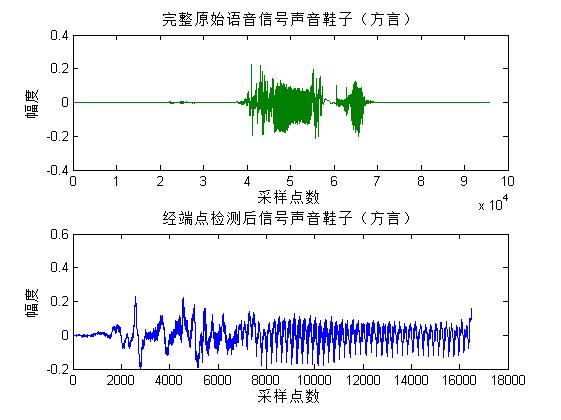
2.1.4 端点检测 7
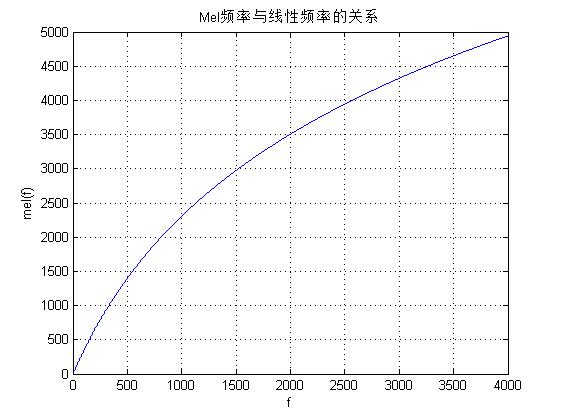
2.2 语音的特征提取 9
2.3 本章小结 10
第3章 识别方法 11
3.1 动态时间规整 11
3.1.1 DTW概述 11
3.1.2 动态时间规整DTW 13
3.1.3 DTW在语音中的运用 14
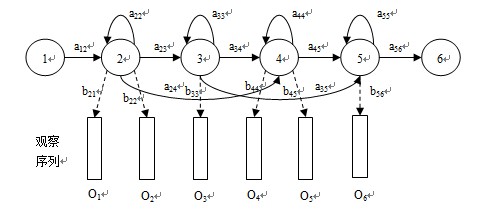
3.2 隐马尔科夫模型 14
3.2.1 HMM基本概念 14
3.2.2 HMM的三个基本问题和解决方案 16
3.2.3 基于HMM的孤立词语音识别系统 17
3.3 深度学习理论 18
3.3.1 深度神经网络声学模型 18
3.3.2 声学模型网络结构 19
3.4 前馈全连接深度神经网络介绍-DNN训练算法 19
3.5 各方法性能比较分析 19
3.6 本章小结 20
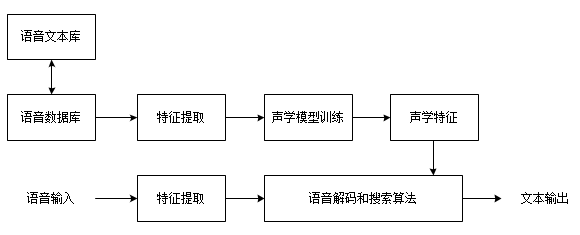
第4章 基于深度学习的方言识别系统设计 21
4.1 系统需求分析 21
4.2 开发环境 21
4.3 方法集成与功能实现 21
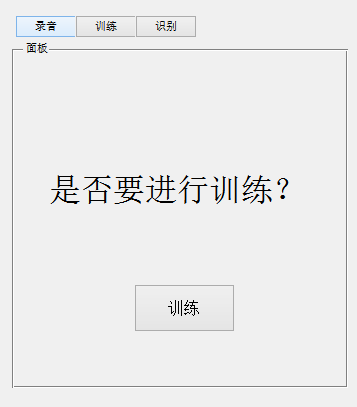
4.4 系统测试 23
4.5 本章小结 25
第5章 总结与展望 26
5.1 课题工作总结 26
5.2 展望 26
参考文献 27
附录A 28
附录B 31
致 谢 33
第1章 绪论
1.1 研究课题背景及研究的目的和意义
日常生活中,人们彼此之间交流通话传递信息的最直接、最便捷和最高效的方式就是语音信号的传递。让计算机能够像人一样智能起来听懂人类的语言,是人类自计算机发明出现以的梦想。随着计算机硬件越来越简洁、越来越向便携化方向发展,而软件的功能也慢慢复杂起来,语音输人这样便于使用的输人方式越来越受到广大群众的欢迎。语音与人类文明进步、人类智力的发展息息相关[1],语音就在我们周围每一天、每一个人。它是人类的智慧产物,不同的国家有着不同的语言语音,而不同的语言有着不同的发音音标,所以说语音具有很高的最大的信息容量和智能水平。从第一台计算机的出世开始,人工智能的就是人类发展一直孜孜追寻的目标[2]。传统的人机交互都是通过鼠标和键盘进行的。机器只是根据指令去执行人类的命令。而人工智能的最终目标是让机器也能像人一样拥有智慧,根据不同的输入做出不同的反馈,能听、会说、可以思考。基于硬件的人机交互相比于人类的语音交互效率比较低,而且也显得不是很自然、识别错误率高、效率低。所以将人与人之间的语音交互扩展到机器的智能领域一直以来都是一个高难度的同时也是广泛受到关注目标。它包含了各种各样领域的知识,决不是一个单纯的难题,例如通信领域的信号与信息处理、生理学领域的信号的产生与感知、音乐美学领域的语言韵律学、语言学领域的自然语言、计算机领域的机器翻译理解等。语音识别是完成机器翻译的前提,而至于自然语言理解又是更深一个层次的研究课题了,他们都是实现智能的人机交互的重点难题。
大家平常说话可能没有太大的体会,但人类的语音信号的产生过程是一个复杂而难以分析的过程,大致可以分成三个阶段:语音的产生、传递、接收。在语音的产生阶段,最为复杂,为什么呢?一段语音的产生经过了人的过各种器官(声带、喉、口、鼻、牙、舌、唇),每个人的每个器官都有或多或少的差异,产生的同一语音信号有各种不同的发音。再谈语音的传递过程,然而语音的是以声波的形式通过空气、各种遮挡等媒介传播的。不同的温度、天气、周围环境条件,声音的传播信道不同,收到的干扰不同。最后就是语音的感知,语音的感知则是由接收方耳朵、耳膜、大脑皮层构成的复杂的听觉系统完成。大脑可以感知的语音信号所含有的各种复杂信息,例如音高、音色、音强、音长、语调等,从这些信息中听话者能准确地判断说话人的意思、情感、说话的对象等。因而,语音识别是一门涉及面很广的交叉学科,包含各种学科,因此语音交互这对于我们来说最自然普通的交流方式对于只能机器识别来说就显得特别困难。
与人听觉系统非凡的感知能力比较,目前的语音识别和说话人识别等机器系统还存在许多问题,尤其是在不利的噪声环境下,系统性能急剧下降。语音识别和说话人识别系统中特征提取过程就是抽[3]取保持语音最重要特征,并消除与语音无关信号的干扰,其性能对识别系统的性能有直接影响。寻找具有良好性能的特征及其提取算法是提高识别系统性能的根本途径之一。目前,常用的语音特征包括基于声道的 LPCC、基于临界带的 MFCC 以及基于临界带和等响度曲线的 PLP,考虑语音动态特性的一阶和二阶差分倒谱,还有其他基于听觉模型的特征。语音识别系统按照被识别的对象来分,一般被分为三大类。一是孤立字、词识别。这是本章研究的重点。二则是连续语音的识别。三是语音理解及会话语音识别。这个识别对比于第二种连续语音识别更为困难,英文很多人都不能做到理解语意的含义,并且在会话中出现的省略、倒置等各种各样的语言语法,属于更高一级的语音识别。
1.2 国内外的研究现状
实际上人工神经网络并不是一个新科技,从2010年开始,深层结构的神经网络对语音识别产生重要影响。如果按声学建模基元的大小来分类[4],小到音素识别、或者声韵母识别。大到孤立词识别,深度学习理论都能成功的处理他们。当然,基于深度学习的语音识别的功能不止于此,他还能对大词汇量连续语音识别,现在最流行的语音识别技术是DNN-HMM,深度学习在语音识别这一领域应用最为广泛。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: