基于深度学习网络的语音信号识别开题报告
2020-02-18 16:20:59
1. 研究目的与意义(文献综述)
人类社会中语言、文字、符号和图表是人们互相传递信息和表达自我的主要途径,其中语言是最为原始的,同时也是当人们在无法使用文字图表等其他方式贴切的表达自身意图与想法时,最自然也是最便于他人理解的方式。随着信息技术的不断发展和对原有的技术屏障的突破,语音信号成为现信息时代背景下的人与人之间思想沟通、感情交流、人机交互等最基本也是最高效的途径,比如人们常用的语音通话和智能家居人机交互等。语音识别发展到现在作为人机交互的重要接口已经在很多方面改变了我们的生活,从智能家居的语音控制系统到车载语音识别系统,语音识别给我们带来了很多方便。
Audrey系统是在上世纪50年代由Davis等人首先提出的,目标是识别指定说话人说的英文数字,其主要思路是将数字元音的共振峰频谱作为数据基础,依据频谱信息进行分析和判断。这意味着人们开始了对自动语音识别系统的研宄。对语音识别的研究随着计算机的计算速度和计算能力的不断增加,涌现出许多突破性的算法,其中沿用至今的算法包括:基于频率域空间线性趋近思路的线性预测编码(Liner Predictive Coding,LPC)、以衡量两个序列之间的相似程度的动态时间规整(Dynamic Time Warping,DTW)算法,它们极大的提升了提取语音特征的精准性,提高了模板之间的匹配性能。同时期提出的经典算法还有矢量量化(VQ)和在后期与深度神经网络混合的隐马尔科夫模型(HMM)、对人类大脑处理信息机理进行模拟的人工神经网络(ANN),其后随着研究人员不断的改进,使得隐马尔科夫模型成为了应用于语音识别领域的主流算法。并且将传统的隐马尔科夫模型与高斯模型进行结合,提出了之前作为语音识别最常用算法的隐马尔科夫模型-混合高斯模型(Hidden Markon Model-Gaussion Mixture Model,HMM-GMM)。在音素识别算法中,研究人员基于HMM-GMM模型的思路,提出了混合隐马尔科夫-人工神经网络模型(Hybrid HMM-artificial Neural Network model,HMM-ANN)。接着有学者使用传统的语音MFCC特征参数,以三音素绑定HMM状态的概念为基础在实验中极大的降低了实际训练的三音素模型。后来随着各式各样的学习模型被提出,人工神经网络逐渐被SVMM等理论简单易理解同时训练难度相对较小的模型取代,在语音识别方面高斯混合模型取代了训练难、同时效果不是很显著的人工神经网络。而在针对扩展、降维的同时增强语音特征的区分性的线性区分分析和异方差线性区分分析等处理并没有为语音识别的准备率带了多少提高。直到2006年,Hinton等人等人将深度学习算法应用于训练多层神经网络,使用非监督贪心逐层训练算法逐层训练多个RBM,组成了深度置信网络(Deep Believe Network,DBN),掀起了一股深度学习的热潮。深度学习最先在图像处理中取得了优异的效果,随后在语音识别中也展现出远超传统算法的强大性能。
因为深度学习提取出的特征有较强的区分性,训练出的模型具有较强的区分能力,研宄人员把深度学习应用到语音识别中,其中多伦多大学Abdel-rahman Mohamed的等人用DBN网络搭建单音素分类器,微软研宄人员通过与合作,将深度信念网(DBN)用作深度神经网络(Deep Neural Network,DNN)的预训练过程,用DNN-HMM混合网络训练的声学模型,在大词汇量语音识别系统中获得巨大成功。国外,IBM、谷歌等公司都对DNN语音识别的研宄投入很大,并且取得了成功,在国内,科大讯飞、中科院自动化所等,也把深度学习用于语音识别。
2. 研究的基本内容与方案
本课题的基本内容:基于深度学习理论的特征学习,使用神经元个数层层递减的深度自编码器网络模型,从优化后的语音原始特征中学习到维数更低,识别率更高的新特征。分别从网络的层数、各层神经元个数等方面设计深度自编码器网络模型。依靠kaldi等语言信号识别工具平台,实现可用的语音识别模型,通过语音识别的解码,证明设计的深度网络学习特征的有效性与可行性。
本课题的目标:设计完成具有深度学习能力的语言信号识别程序,完成软件程序设计并对整个系统进行仿真调试以及功能测试。
本课题的基本技术方案:语音识别是将一段语音信号通过识别转换得到相应的文本信息。语音识别系统主要由提取声学特征、特征后处理、语言模型、声学模型以及解码器等数个功能模块组成。图1描述了连续语音识别的系统框图,语音识别的主要工作可分为三部分:首先需要提取语音数据的特征,使得到的特征能够充分描述原始语音信号;其次需要得到较可靠的声学模型和语言模型,期间使用语音数据库训练声学模型,使用文本数据库训练语言模型;之后对实际的输入语音信号提取特征后,结合声学模型以及语言模型,使用解码器处理得到相应的识别结果。
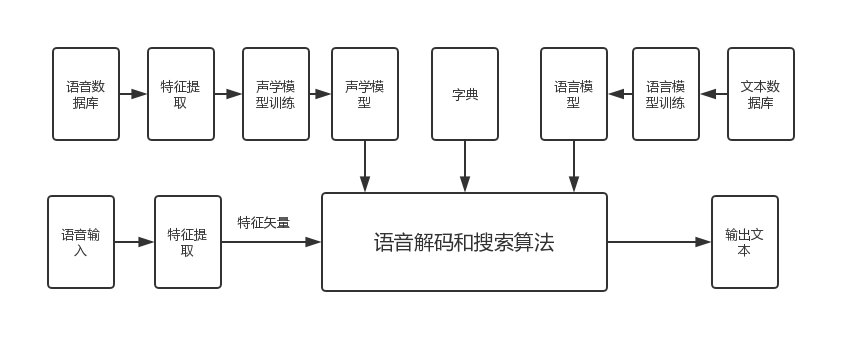
图1 系统结构框图
3. 研究计划与安排
1~3周:查阅相关文献资料,明确研究方向,确定研究内容,完成开题报告;
4~6周:了解掌握关于深度学习网络以及语音识别系统的设计知识;
7~9周:完成语音识别系统所用的深度学习网络的算法设计;
10~11周:完成外文翻译以及中期答辩;
12~13周:对设计的语音识别系统进行仿真以及最终调试;
14~16周:完成毕业设计论文,准备答辩。
4. 参考文献(12篇以上)
[1]鄢志. 声学模型区分性训练及其在自动语音识别中的应用[d].中国科学技术大学,2008.
[2]乔文婷. 基于神经网络的语音情感识别算法研究[d].西安电子科技大学,2018.
[3]张竞丹. 基于深度学习的说话人识别系统[d].西安邮电大学,2018.



