基于中文在线评论的主题识别方法的设计与研究毕业论文
2020-02-17 23:20:57
摘 要
在当今互联网盛行的时代,数据可以说是漫山遍野,对于作为程序员的我们来说,世间万物皆为数据!像一些网络游戏里面的装备,血量等,在非程序员的玩家看来是游戏,是很厉害的心理骄傲,而在我们眼中就是普通的数据!在数据遍山的时代,有时候我们需要捕获某些数据进行一些处理,而经过漫长的编程者们的研究,技术已经渐渐先进起来,功能实现也逐渐变得丰富,爬虫技术应运而生!很多时候有很多客户需要获取某某网站上的数据信息,比如产品名称,价格,用户名称,评论,时间情况等等,这些都是通过爬虫实现的,所以基于爬虫、网站、数据库我们决定开发一个伟大的项目:在线评论的主题识别系统!
在线评论的主题识别系统主要用于分析购物网站上的产品展示页面,利用爬虫脚本技术抓取网站上的在线评论信息,然后对在线评论信息进行获取采集以及对在线评论信息的预处理功能,构建中文版的在线评论资料库。他可以提取所有用户评论信息中的主体信息,然后结合词语语义的特性,采用优化的文本分类方法,将提取的主题信息分类到预先定义的主题关注点容器中集合中,最后按照主题关注度的降序顺序精心排序,从而得到主题热点。
本系统包含对各品牌用户所关注的主题热点精心研究,构建一个主题热点分析体系。通过实现本系统让设计者熟悉和掌握相关技术的使用以及通过编写次论文让设计主熟悉和掌握毕业设计论文相关规范格式。额外说明的是本系统的搭建情况。
本系统是一个Javaweb系统,用到了Javaweb网站搭建进行对系统的详细设计,后台数据库等的增删改查操作运用,设计者通过实现在线评论的主题识别系统,掌握必要的Java基本技术以及关于网站页面的前端展示技术,通过对数据库的操作运用,熟悉并掌握基本的增删改查sql语句和少见的复杂sql语句,比如分组查询,连表查询,分页查询,特殊另类的增删改操作以及熟悉数据库表与表的关联情况的相关操作。
关键词:爬虫抓取信息;主题热点分析;用户评论;JavaWeb网站构建;数据库
ABSTRACT
In today's Internet era, data can be said to be all over the mountains, for us as programmers, everything in the world is data! Like some online games in the equipment, blood, etc., in the eyes of non-programmer players is a game, is a great psychological pride, and in our eyes is the ordinary data! In the era of data mountains, sometimes we need to capture some data for some processing, and after a long period of programmers'research, technology has gradually advanced, function realization has gradually become rich, crawler technology came into being! Many times, many customers need to get data information on a certain website, such as product name, price, user name, comment, time situation and so on. These are achieved by crawlers. So based on crawlers, websites, databases, we decided to develop a great project: online comment theme recognition system!
The theme recognition system of online comment is mainly used to analyze the product display pages on shopping websites, capture online comment information on websites by crawler script technology, then collect online comment information and preprocess online comment information, and construct online comment database of Chinese version. He can extract the subject information of all user comments, then combine the semantic characteristics of words, adopt the optimized text classification method, classify the extracted subject information into the pre-defined set of subject concerns containers, and finally sort it carefully according to the descending order of subject concerns, so as to get the topic hotspots.
This system includes careful research on the theme hot spots concerned by brand users, and constructs a thematic hot spot analysis system. Through the implementation of this system, designers can familiarize themselves with and master the use of related technologies, and through the preparation of this paper, designers can familiarize themselves with and master the relevant standard formats of graduation design papers. Additionally, the construction of the system is explained.
This system is a Java web system. It uses Java web site to build a detailed design of the system, the use of background database and other additions, deletions, modifications and checks. By realizing the theme recognition system of online comments, the designer grasps the necessary Java basic technology and the front-end display technology of website pages. Through the operation and application of the database, he is familiar with and master the basic additions and deletions. Look up SQL statements and rare complex SQL statements, such as grouping queries, linked table queries, paging queries, special and alternative addition and deletion operations, and related operations familiar with the association of database tables and tables.
Key word: Crawler crawling information; Topic hotspot analysis; User reviews; Java Web site construction; Database
目录
1绪论 1
1.1研究背景及意义 1
1.1.1 研究的背景 1
1.1.2 研究的意义 2
1.2研究的具体内容与方法 2
1.2.1 研究的具体内容 2
1.2.2 研究所用到的方法和技术 2
2关于在线评论的主题识别系统 4
2.1 概述 4
2.2 系统分析阶段 4
2.3 特征提取算法介绍 6
2.4 项目编码与设计阶段 7
2.5项目相关技术要点 24
2.6 页面搜索策略 27
2.7 页面分析算法 28
2.8 补充 28
3结论 30
参考文献 31
致谢 32
第1章 绪论
1.1研究背景及意义
1.1.1 研究的背景
在现在数据爆炸的时代,数据分析业界的势头很强,踏入数据分析领域的人增加了。进入这个领域,得到很多数据来支持他们的分析是很重要的,但是如何在互联网上得到有效的信息呢?这加速了“爬虫类”技术的快速发展。网络爬虫类(被称为web蜘蛛的网络机器人在FOAF社区中更频繁地被称为web跟踪者)是根据一定规则自动地掌握web信息的程序或脚本。
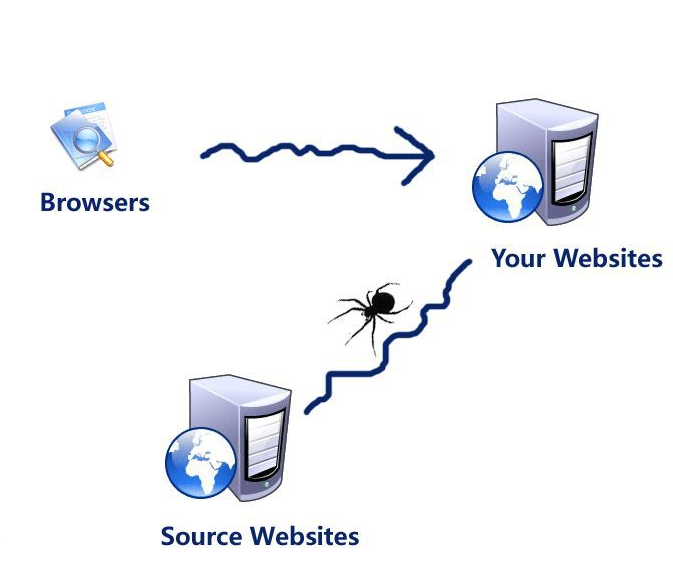 以往的爬虫类从一个或多个初始页面的URL开始,获取初始页面的URL,在捕捉网页的过程中,在满足系统的一定停止条件之前,从当前页面提取新的URL放入队列。要聚焦自由工作流程很复杂,需要基于某个网页解析算法,对与主题无关的链接进行过滤,保持有用的链接,进入等待捕捉的URL列。然后,根据特定的搜索策略,从队列中选择下一步要捕获的网页的URL,重复上述过程,直到达到某一系统的条件。另外,所有爬虫类的页面均由系统保存,进行一定的分析、过滤,然后为搜索和搜索创建索引。
以往的爬虫类从一个或多个初始页面的URL开始,获取初始页面的URL,在捕捉网页的过程中,在满足系统的一定停止条件之前,从当前页面提取新的URL放入队列。要聚焦自由工作流程很复杂,需要基于某个网页解析算法,对与主题无关的链接进行过滤,保持有用的链接,进入等待捕捉的URL列。然后,根据特定的搜索策略,从队列中选择下一步要捕获的网页的URL,重复上述过程,直到达到某一系统的条件。另外,所有爬虫类的页面均由系统保存,进行一定的分析、过滤,然后为搜索和搜索创建索引。
图1.1 网络爬虫示意
1.1.2 研究的意义
搜索引擎的实现可以分为三个步骤:1)从Internet 2)对网页进行爬网。处理网页并建立索引数据库3)查询。因此,无论哪种搜索引擎,都必须有一个设计良好的爬虫来支持。
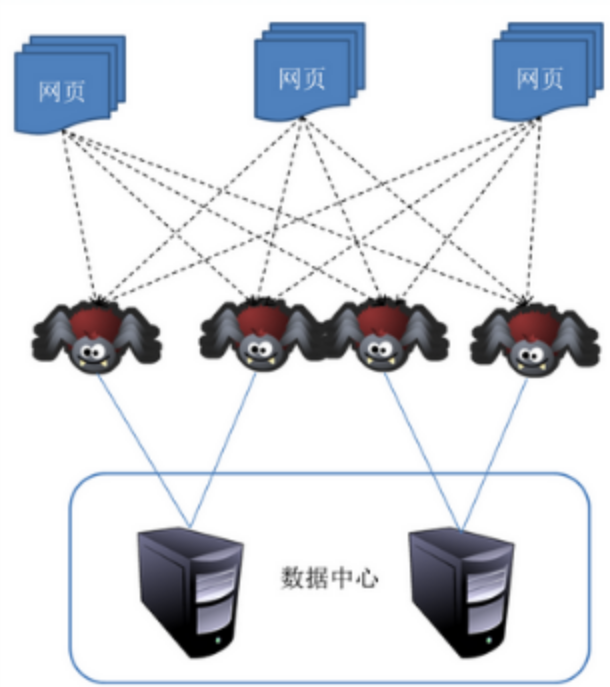 图1.2 爬虫的工作关系
图1.2 爬虫的工作关系
1.2研究的具体内容与方法
1.2.1 研究的具体内容
本系统包含如下内容:
1)爬取各个平台特定的在线评论数据;
2) 从爬取的在线评论信息数据中抽取客户们所关注的信息;
3) 对客户关注的信息数据进行预处理,包括分类,统计等等。并进行数据库保存;
4) 爬取的所有数据,分析信息将通过web来作为定制和页面展示。
1.2.2 研究所用到的方法和技术
Java爬虫:在网络爬行系统中,主过程由三个部分组成:控制器,分析仪,资源,控制器的主要任务是将工作分配到不同的爬行在多个线程中的不同路径。分析工具的主要任务是下载网页,处理页主要处理一些JS脚本的文本标签,CSS代码内容,空间符号,HTML标签和其他元素,主要的爬行动物的工作已经完成。资源图书馆的目的是存储存储下载的网站资源,通常存储在大型数据库,如Oracle,和索引。
Javaweb: 将网络视为一个容器的技术,主要是通过JavaEE技术来实现的。添加不同的中间元素。整个javaWeb阶段的内容已被实践的例子研究,相关的技术知识将被引入会计系统。首先,了解所有技术系统的爪哇,掌握所有的技术知识。
数据库:电子化的文件柜-电子文件储藏所,用户可以重新增加文件数据,更新、删除等操作。
第2章 关于在线评论的主题识别系统
2.1 概述
网络爬虫也被称为网络蜘蛛机器人,最常被称为网络捕猎者,是自动从网络中提取信息的脚本。一些有前途的其他常用的蚂蚁名字自动索引,模拟软件,或蠕虫。随着网络的快速发展,Web已经成为信息的载体。如何有效地提取和利用这些信息已成为一个巨大的挑战。搜索引擎如AltaVista或雅虎!而Google作为一种工具来帮助人们恢复信息,成为用户访问Web的登录和目录。然而,这些搜索引擎也有一些限制,一般搜索引擎返回的结果包含大量的搜索结果,包括来自不同领域、不同背景和不同检索目的的用户数据。用户不关心的页面。
搜索引擎的总体目标是最大限度地覆盖网络,搜索引擎服务资源有限与网络数据资源无限的矛盾将进一步加深。3.3IP®丰富的Web数据格式和不断发展的各种网络技术,如图像,数据库,音频,视频和多媒体显示数量大型BC搜索引擎往往无法发现和获取这些数据的内容密集和特定的结构。大多数一般的搜索引擎都提供关键词检索,这使得基于语义的查询很难支持。
 图2.1中文在线评论抓取流程图
图2.1中文在线评论抓取流程图
2.2 系统分析阶段
我们在系统分析阶段相关的需求分析,项目立项等相关的步骤包括如下几个部分组成:
参考案例分析资源图如下:
图2.2分析资源图
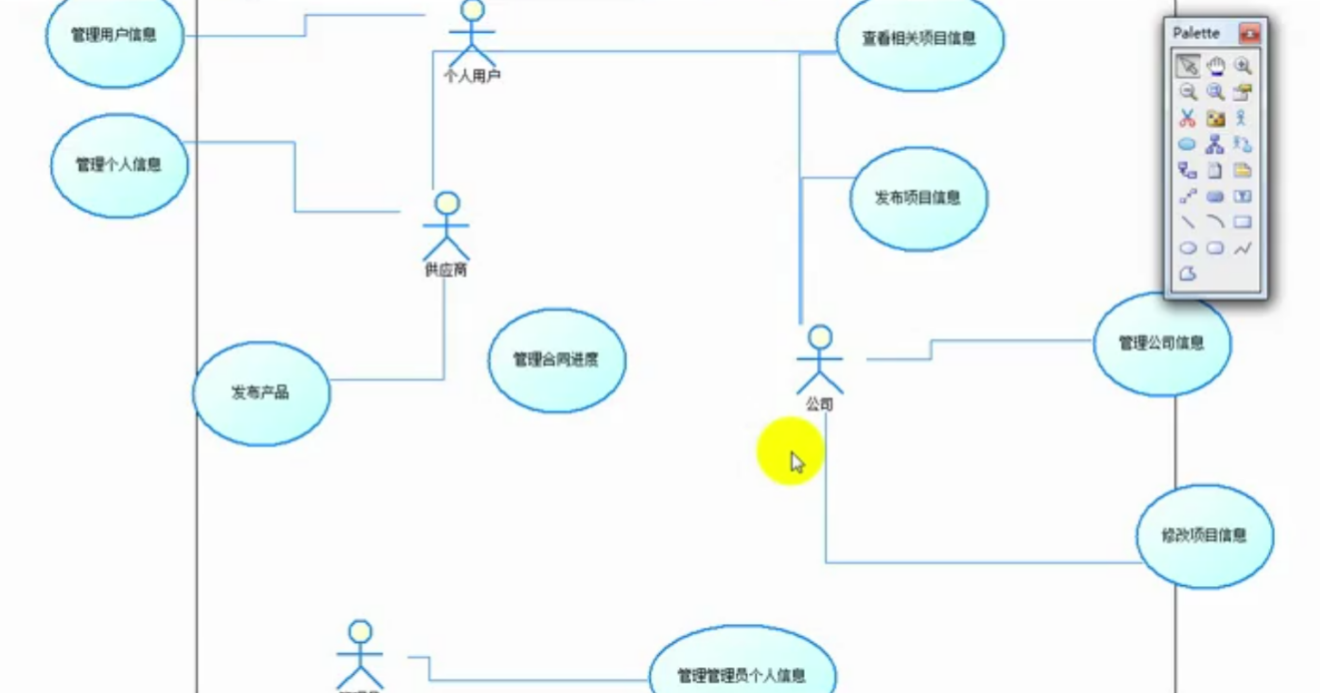
图2.3全局用例图
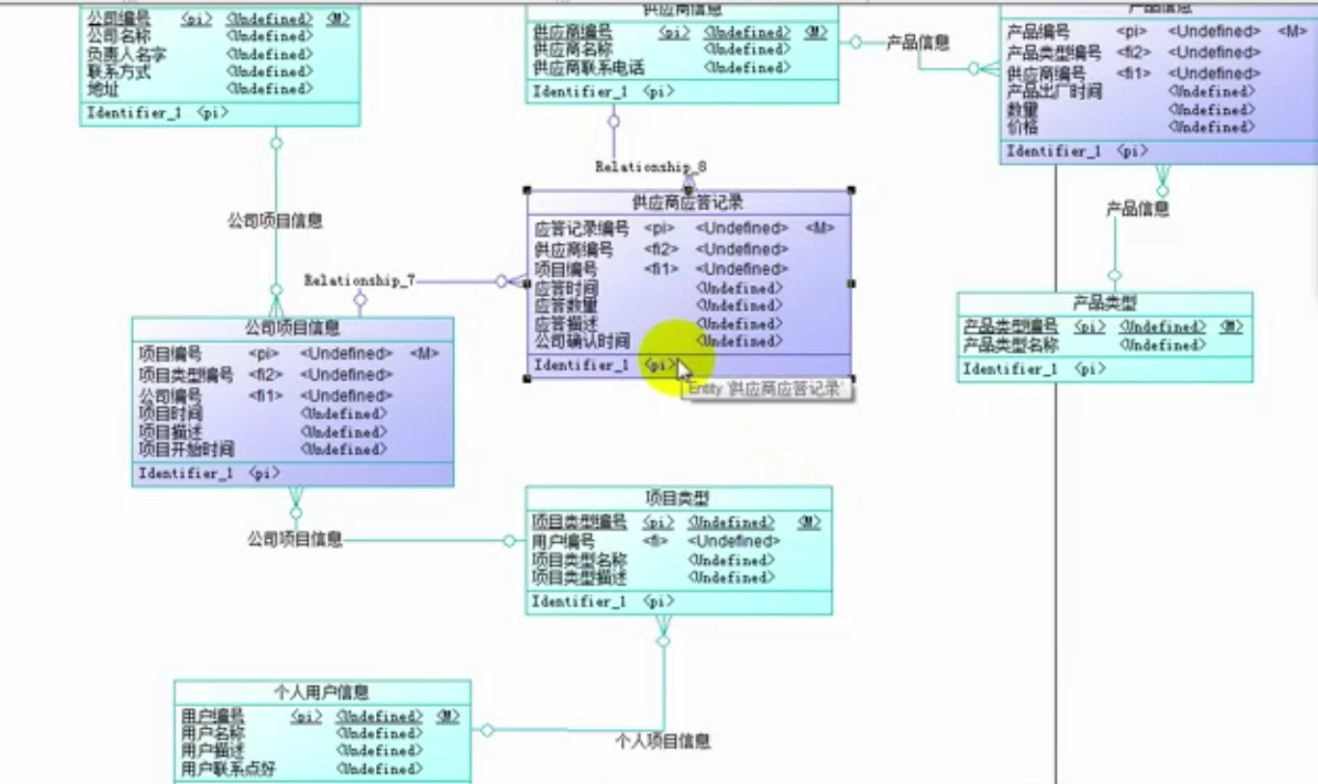
图2.4相关关系参考资源图
论文需求分析阶段文字说明:
本在线评论的主题热点系统主要需求是利用爬虫技术,爬取平台评论信息,对评论数据信息进行一系列的预处理,然后分析保存进数据库,最终显示在前端页面的一个系统。所以项目系统的大体需求明确之后,我们利用一系列的资源图,创建本项目的资源图。
首先需求的收集阶段(项目系统需要哪些具体功能等),我们从原有项目系统中提取了部分需求资源信息,原有项目来自于武汉大学已经毕业学生的原有关于在线评论的主题分析系统;我们从相似的系统中提取信息数据资源,包括百度网上的一些类似的项目资源提取出了宝贵明确的需求资源;我们也有过调查问卷,比如从导师口中获取的需求资源信息,从伙伴们所描述的情况中提取需求资源信息;最后我们也有过头脑风暴,积极充分发挥我们的想象,暴露本系统应该有的功能需求资源信息从而明确下来了本项目系统的前期需求;最后通过一系列整理完善完成前期需求分析阶段。
2.3 特征提取算法介绍
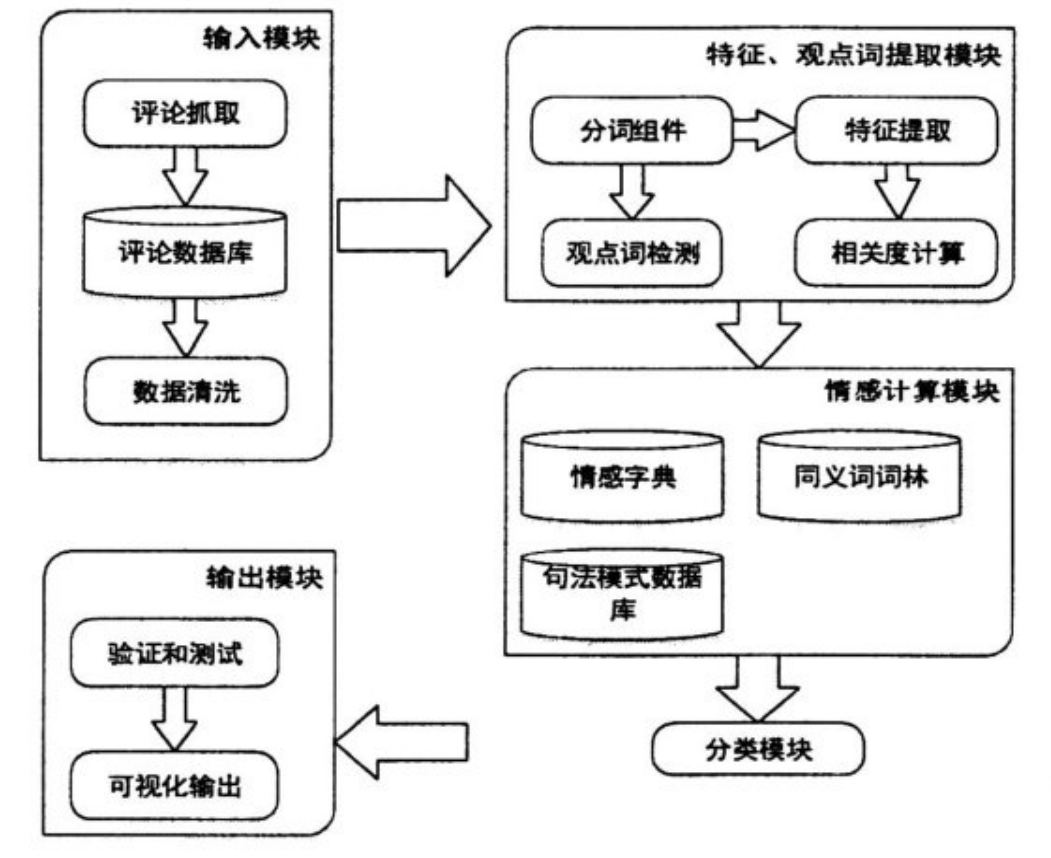
从在线评论中提取产品特征是评论挖掘的目的之一。由于商家在制造商品的出售商品时,并不知道用户对产品的关注情况,因此从用户发布的在线评论里提取特征不仅对商家有益,对于潜在的消费者也是很有必要的。针对中文在线评论特征提取,在GSP(GSP,Generalized Sequential Patterns)算法的基础上,提出一种二次剪枝算法(GSP-TPCW,Gene- ralized Sequence Pattern-Term Pair Co-occurrence Weight)用于提取特征,它汲取了GSP算法获取频繁名词和词组的优点,且通过分析其噪声数据的特点,利用基于统计的方法-词对共现度(TPCW,Term PairCo-occurrence Weight)来计算词语与主题的相关性,进而过滤噪声数据[18]。这里将GSP-TPCW与通用的GSP算法、交叉语言模型、似然比检验等算法进行比较,并分析了它们各自的特点,验证了GSP-TPCW算法的有效性。本文的二次剪枝算法在获得特征后,会进行再次去噪,获得一个比较完整的产品特征集合,为后续的情感分析做铺垫。
GSP-TPCW算法步骤:
Fk表示k-频繁序列的集合,Ck表示所有候选序列的集合;
- 初始存储序列模式的数据库S,形成候选集C1;
- 遍历数据库S,找出满足最小支持度的序列模式,并将其加入集合F1;
- 将元素长度为k的Fk作为种子集,通过连接和剪枝操作,形成长度为k 1的候选集Ck 1,并将新的Ck 1作为种子集;
重复步骤(3),直到没有新的候选序列模式产生,迭代过程结束。
- 对上述结果采用TPCW进行二次剪枝。
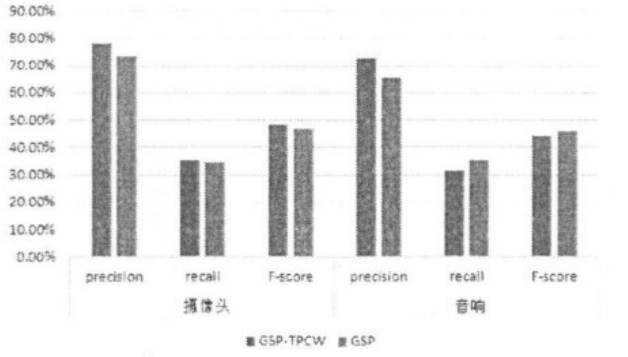 图2.5 GSP算法与GSP-TPCW算法的对比
图2.5 GSP算法与GSP-TPCW算法的对比
2.4 项目编码与设计阶段
项目编码阶段分为前端编码跟后台编码进行,首先阐述前端编码以及前端jsp页面的设计。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: